

Javaのシーケンスリストとリンクリストを例を交えて詳しく解説

この記事では、java に関する知識を提供します。主にシーケンス テーブルとリンク リストに関する内容を紹介します。シーケンス テーブルは、物理アドレスを連続して格納する配列です。データ要素が順番に並んだ線形構造です。皆さんの参考になれば幸いです。

Java ビデオ チュートリアル 」
#1. 線形テーブル
線形リストは、同じ特性を持つ n データ要素の有限シーケンスです。線形テーブルは、実際に広く使用されているデータ構造です。一般的な線形テーブル: シーケンシャル リスト、リンク リスト、スタック、キュー、文字列...線形テーブルは論理的に線形な構造、つまり、連続した直線です。 。ただし、物理的な構造は必ずしも連続しているわけではなく、線形テーブルを物理的に保存する場合、通常は配列や連結構造の形で保存されます。
#2. シーケンス テーブル # は実際には配列
です。 [追加、削除、確認、修正] では、なぜ配列テーブルを直接作成するのでしょうか?配列を直接使用するだけなのでしょうか。それは違う、クラスに書けば将来オブジェクト指向になれる。
2.1 概念と構造シーケンス テーブルは、連続した物理アドレスを持つストレージ ユニットを使用して格納する線形構造です。データ要素が順番に並べられており、通常は配列ストレージが使用されます。アレイ上のデータの追加、削除、確認、変更を完了します。
シーケンス テーブルは通常、次のように分類できます。
静的シーケンス テーブル: 固定長の配列ストレージを使用します。
- 動的シーケンス テーブル: 動的に開かれた配列ストレージを使用します。
- 静的シーケンス テーブルは、保存する必要があるデータ量がわかっているシナリオに適しています。
動的シーケンス テーブルを実装しましょう。サポートする必要があるインターフェイスは次のとおりです。
ここで、それらを 1 つずつ分解します。public class MyArrayList {
public int[] elem;
public int usedSize;//有效的数据个数
public MyArrayList() {
this.elem = new int[10];
}
// 打印顺序表public void display() {
}
System.out.println();}// 获取顺序表长度public int size() {
return 0;}// 在 pos 位置新增元素public void add(int pos, int data) {}// 判定是否包含某个元素public boolean contains(int toFind) {
return true;}// 查找某个元素对应的位置public int search(int toFind) {
return -1;}// 获取 pos 位置的元素public int getPos(int pos) {
return -1;}// 给 pos 位置的元素设为 valuepublic void setPos(int pos, int value) {}//删除第一次出现的关键字keypublic void remove(int toRemove) {}// 清空顺序表public void clear() {}} これは、シーケンス テーブルの基本構造です。シーケンス テーブルの機能を 1 つずつ分解してみましょう:
これは、シーケンス テーブルの基本構造です。シーケンス テーブルの機能を 1 つずつ分解してみましょう: データ テーブルを出力します:
public void display() {
for (int i = 0; i < this.usedSize; i++) {
System.out.print(this.elem[i] + " ");
}
System.out.println();}シーケンス テーブルの長さを取得します:
public int size() {
return this.usedSize;}pos 位置:
public void add(int pos, int data) {
if(pos < 0 || pos > this.usedSize) {
System.out.println("pos 位置不合法");
return;
}
if(isFull()){
this.elem = Arrays.copyOf(this.elem,2*this.elem.length);
}
for (int i = this.usedSize-1; i >= pos; i--) {
this.elem[i + 1] = this.elem[i];
}
this.elem[pos] = data;
this.usedSize++;}//判断数组元素是否等于有效数据个数public boolean isFull() {
return this.usedSize == this.elem.length;}要素が含まれているかどうかを判断します:
public boolean contains(int toFind) {
for (int i = 0; i < this.usedSize; i++) {
if (this.elem[i] == toFind) {
return true;
}
}
return false;}要素に対応する位置を検索します:
public int search(int toFind) {
for (int i = 0; i < this.usedSize; i++) {
if (this.elem[i] == toFind) {
return i;
}
}
return -1;}pos 位置にある要素を取得します:
public int getPos(int pos) {
if (pos < 0 || pos >= this.usedSize){
System.out.println("pos 位置不合法");
return -1;//所以 这里说明一下,业务上的处理,这里不考虑
}
if(isEmpty()) {
System.out.println("顺序表为空!");
return -1;
}
return this.elem[pos];}//判断数组链表是否为空public boolean isEmpty() {
return this.usedSize == 0;}Give pos 位置の要素を値に設定します:
public void setPos(int pos, int value) {
if(pos < 0 || pos >= this.usedSize) {
System.out.println("pos 位置不合法");
return;
}
if(isEmpty()) {
System.out.println("顺序表为空!");
return;
}
this.elem[pos] = value;}//判断数组链表是否为空public boolean isEmpty() {
return this.usedSize == 0;}キーワード キーの最初の出現を削除します:
public void remove(int toRemove) {
if(isEmpty()) {
System.out.println("顺序表为空!");
return;
}
int index = search(toRemove);//index记录删除元素的位置
if(index == -1) {
System.out.println("没有你要删除的数字!");
}
for (int i = index; i < this.usedSize - 1; i++) {
this.elem[i] = this.elem[i + 1];
}
this.usedSize--;
//this.elem[usedSize] = null;引用数组必须这样做才可以删除}シーケンス リストをクリアします:
public void clear() {
this.usedSize = 0;}数列表の途中/先頭の挿入と削除、計算量はO(N )
容量を拡張するには、新しいスペースを申請し、データをコピーし、古いスペースを解放する必要があります。消費量も多くなるでしょう。
容量拡張は一般的に 2 倍に増加するため、必然的にある程度の無駄なスペースが発生します。たとえば、現在の容量が 100 で、いっぱいになったら容量を 200 に増やします。引き続き 5 つのデータを挿入します。その後データは挿入されないため、95 個のデータ スペースが無駄になります。
- 思考: 上記の問題を解決するにはどうすればよいでしょうか?リンクリストの構造を以下に示します。
#3. リンク リスト
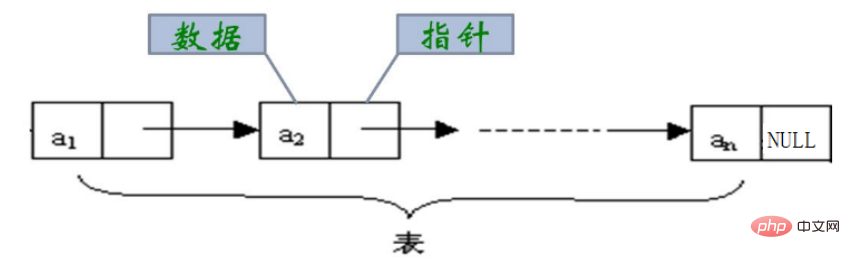
#3.1 リンク リストの概念と構造
Linkedリストは次のタイプです。 物理的なストレージ構造は非連続です ストレージ構造、データ要素の 論理的順序
は、参照リンク リンク リスト内の順序を通じて実現されます。 実際には、リンク リストの構造は非常に多様で、一般的に次の 4 つのタイプがあります。リンク リスト
- 循環リンク リスト
- 双方向循環リンク リスト
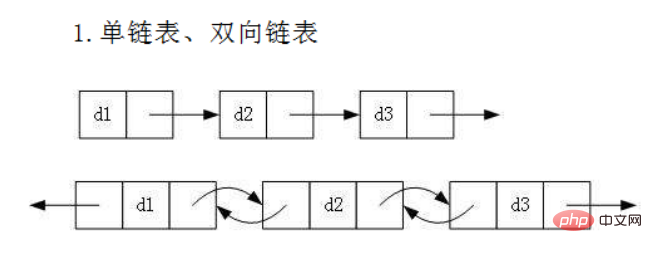
- #細分化すると、次の状況で 8 種類のリンク リスト構造が存在します。 一方向、双方向
主導、主導権を握るのではありません
ループ、非循環
##8 つのタイプは次のとおりです:
- 一方通行の先行サイクル
- #一方向先行ループなし
- 一方向非先行ループ
- 双方向先行ループ ##双方向非先行ループ
#双方向非先行非ループ
双方向非先行非ループ
- # 注: 上記の太字の単語は、学習する必要がある重要なポイントです。 ! !
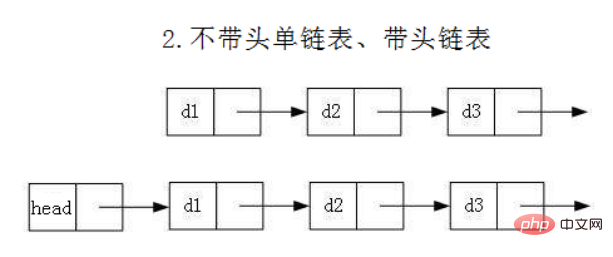
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 无头双向链表:在Java的集合框架库中LinkedList底层实现就是无头双向循环链表。
中间或前面部分的插入删除时间复杂度O(N)
增容的代价比较大。
任意位置插入删除时间复杂度为O(1)
没有增容问题,插入一个开辟一个空间。
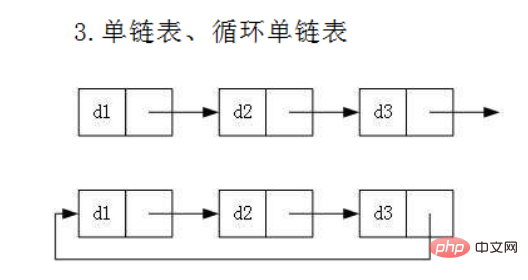
虽然有这么多的链表的结构,但是我们重点掌握两种:
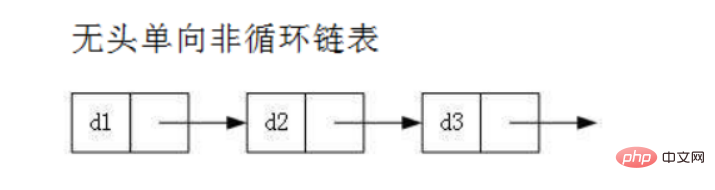
head:里面存储的就是第一个节点(头节点)的地址
head.next:存储的就是下一个节点的地址
尾结点:它的next域是一个null
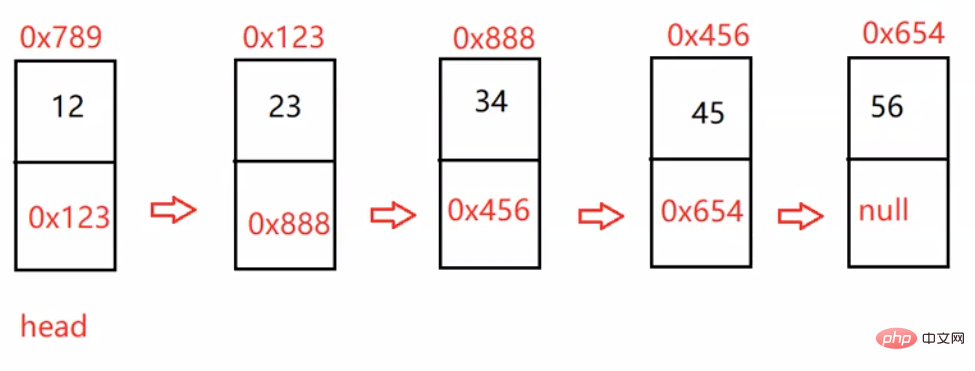
最上面的数字是我们每一个数值自身的地址。
prev:指向前一个元素地址
next:下一个节点地址
data:数据
3.2 链表的实现
3.2.1无头单向非循环链表的实现
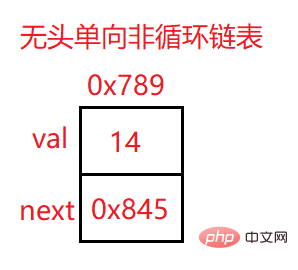
上面地址为改结点元素的地址
val:数据域
next:下一个结点的地址
head:里面存储的就是第一个结点(头结点)的地址
head.next:存储的就是下一个结点的地址
无头单向非循环链表实现:
class ListNode {
public int val;
public ListNode next;//ListNode储存的是结点类型
public ListNode (int val) {
this.val = val;
}}public class MyLinkedList {
public ListNode head;//链表的头引用
public void creatList() {
ListNode listNode1 = new ListNode(12);
ListNode listNode2 = new ListNode(23);
ListNode listNode3 = new ListNode(34);
ListNode listNode4 = new ListNode(45);
ListNode listNode5 = new ListNode(56);
listNode1.next = listNode2;
listNode2.next = listNode3;
listNode3.next = listNode4;
listNode4.next = listNode5;
this.head = listNode1;
}
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key) {
return true;
}
//得到单链表的长度
public int size(){
return -1;
}
//头插法
public void addFirst(int data) {
}
//尾插法
public void addLast(int data) {
}
//任意位置插入,第一个数据节点为0号下标
public boolean addIndex(int index,int data) {
return true;
}
//删除第一次出现关键字为key的节点
public void remove(int key) {
}
//删除所有值为key的节点
public ListNode removeAllKey(int key) {
}
//打印链表中的所有元素
public void display() {
}
//清除链表中所有元素
public void clear() {
}}上面是我们链表的初步结构(未给功能赋相关代码,大家可以复制他们到自己的idea中进行练习,答案在下文中) 这里我们将他们一个一个拿出来实现 并实现!
打印链表中所有元素:
public void display() {
ListNode cur = this.head;
while(cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();}查找是否包含关键字key是否在单链表当中:
public boolean contains(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
return true;
}
cur = cur.next;
}
return false;}得到单链表的长度:
public int size(){
int count = 0;
ListNode cur = this.head;
while (cur != null) {
count++;
cur = cur.next;
}
return count;}头插法(一定要记住 绑定位置时一定要先绑定后面的数据 避免后面数据丢失):
public void addFirst(int data) {
ListNode node = new ListNode(data);
node.next = this.head;
this.head = node;
/*if (this.head == null) {
this.head = node;
} else {
node.next = this.head;
this.head = node;
}*/}尾插法:
public void addLast(int data) {
ListNode node = new ListNode(data);
if (this.head == null) {
this.head = node;
} else {
ListNode cur = this.head;
while (cur.next != null) {
cur = cur.next;
}
cur.next = node;
}}任意位置插入,第一个数据结点为0号下标(插入到index后面一个位置):
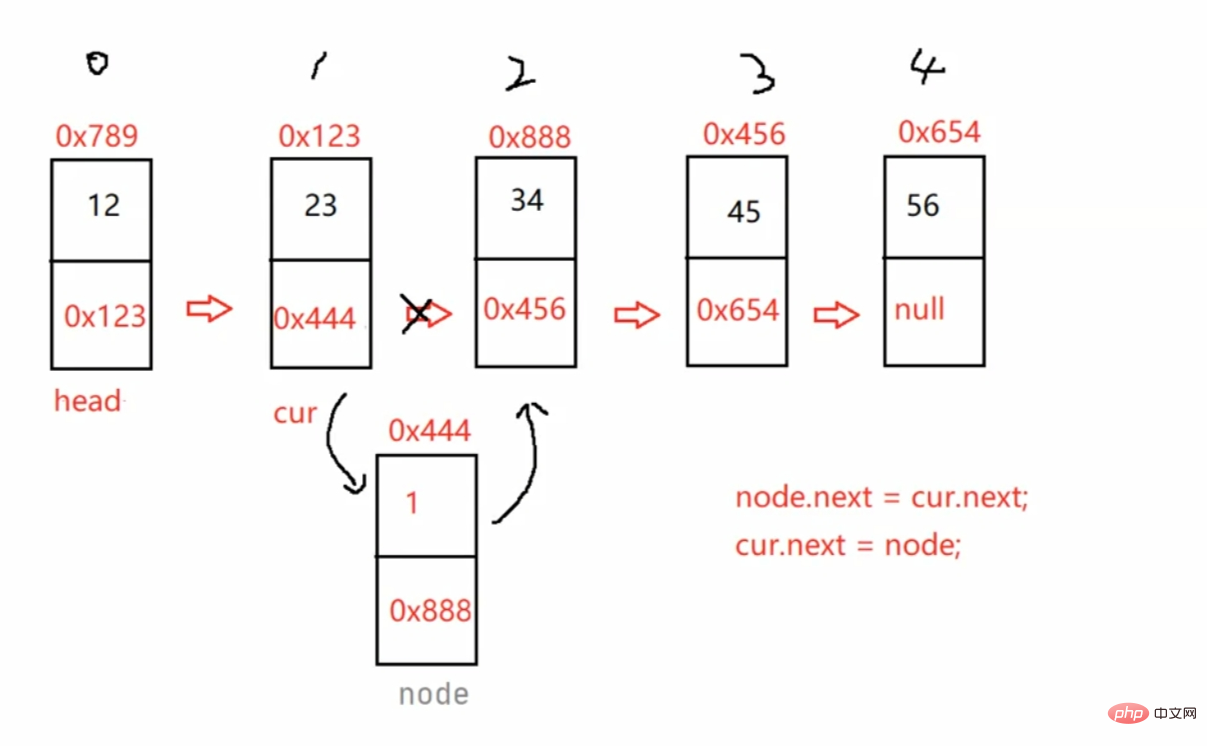
/**
* 找到index - 1位置的节点的地址
* @param index
* @return
*/public ListNode findIndex(int index) {
ListNode cur = this.head;
while (index - 1 != 0) {
cur = cur.next;
index--;
}
return cur;}//任意位置插入,第一个数据节点为0号下标public void addIndex(int index,int data) {
if(index < 0 || index > size()) {
System.out.println("index 位置不合法!");
return;
}
if(index == 0) {
addFirst(data);
return;
}
if(index == size()) {
addLast(data);
return;
}
ListNode cur = findIndex(index);
ListNode node = new ListNode(data);
node.next = cur.next;
cur.next = node;}注意:单向链表找cur时要-1,但双向链表不用 直接返回cur就好
删除第一次出现关键字为key的结点:
/**
* 找到 要删除的关键字key的节点
* @param key
* @return
*/public ListNode searchPerv(int key) {
ListNode cur = this.head;
while(cur.next != null) {
if(cur.next.val == key) {
return cur;
}
cur = cur.next;
}
return null;}//删除第一次出现关键字为key的节点public void remove(int key) {
if(this.head == null) {
System.out.println("单链表为空");
return;
}
if(this.head.val == key) {
this.head = this.head.next;
return;
}
ListNode cur = searchPerv(key);
if(cur == null) {
System.out.println("没有你要删除的节点");
return;
}
ListNode del = cur.next;
cur.next = del.next;}删除所有值为key的结点:
public ListNode removeAllKey(int key) {
if(this.head == null) {
return null;
}
ListNode prev = this.head;
ListNode cur = this.head.next;
while(cur != null) {
if(cur.val == key) {
prev.next = cur.next;
cur = cur.next;
} else {
prev = cur;
cur = cur.next;
}
}
//最后处理头
if(this.head.val == key) {
this.head = this.head.next;
}
return this.head;}清空链表中所有元素:
public void clear() {
while (this.head != null) {
ListNode curNext = head.next;
head.next = null;
head.prev = null;
head = curNext;
}
last = null;}3.2.2无头双向非循环链表实现:
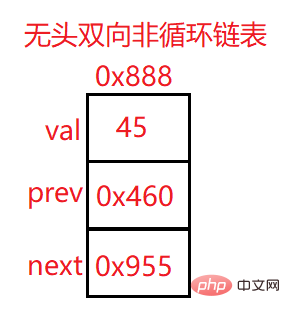
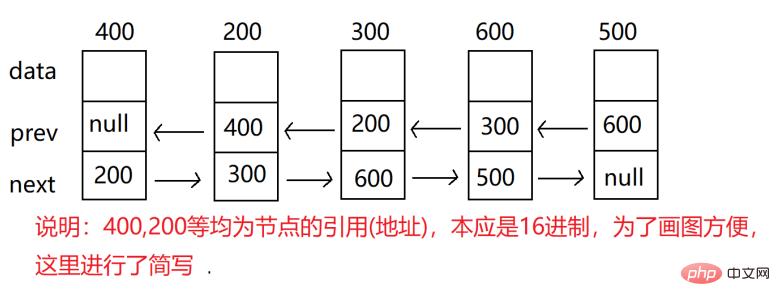
上面的地址0x888为该结点的地址
val:数据域
prev:上一个结点地址
next:下一个结点地址
head:头结点 一般指向链表的第一个结点
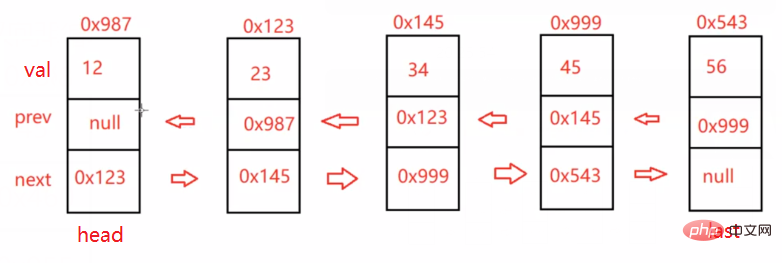
class ListNode {
public int val;
public ListNode prev;
public ListNode next;
public ListNode (int val) {
this.val = val;
}}public class MyLinkedList {
public ListNode head;//指向双向链表的头结点
public ListNode last;//只想双向链表的尾结点
//打印链表
public void display() {
}
//得到单链表的长度
public int size() {
return -1;
}
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key) {
return true;
}
//头插法
public void addFirst(int data) {
}
//尾插法
public void addLast(int data) {
}
//删除第一次出现关键字为key的节点
public void remove(int key) {
}
//删除所有值为key的节点
public void removeAllKey(int key) {
}
//任意位置插入,第一个数据节点为0号下标
public boolean addIndex(int index,int data) {
return true;
}
//清空链表
public void clear() {
}}上面是我们链表的初步结构(未给功能赋相关代码,大家可以复制他们到自己的idea中进行练习,答案在下文中) 这里我们将他们一个一个拿出来实现 并实现!
打印链表:
public void display() {
ListNode cur = this.head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();}得到单链表的长度:
public int size() {
ListNode cur = this.head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;}查找是否包含关键字key是否在单链表当中:
public boolean contains(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
return true;
}
cur = cur.next;
}
return false;}头插法:
public void addFirst(int data) {
ListNode node = new ListNode(data);
if (this.head == null) {
this.head = node;
this.last = node;
} else {
node.next = this.head;
this.head.prev = node;
this.head = node;
}}尾插法:
public void addLast(int data) {
ListNode node = new ListNode(data);
if (this.head == null) {
this.head = node;
this.last = node;
} else {
ListNode lastPrev = this.last;
this.last.next = node;
this.last = this.last.next;
this.last.prev = lastPrev;
/**
* 两种方法均可
* this.last.next = node;
* node.prev = this.last;
* this.last = node;
*/
}}注:第一种方法是先让last等于尾结点 再让他的前驱等于上一个地址 而第二种方法是先使插入的尾结点的前驱等于上一个地址 再使其等于尾结点
删除第一次出现关键字为key的结点:
public void remove(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
if (cur == head) {
head = head.next;
if (head != null) {
head.prev = null;
} else {
last = null;
}
} else if (cur == last) {
last = last.prev;
last.next = null;
} else {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}
return;
}
cur = cur.next;
}}删除所有值为key的结点:
public void removeAllKey(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
if (cur == head) {
head = head.next;
if (head != null) {
head.prev = null;
} else {
last = null;
}
} else if (cur == last) {
last = last.prev;
last.next = null;
} else {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}
//return;
}
cur = cur.next;
}}注:他和remove的区别就是删除完后是不是直接return返回,如果要删除所有的key值则不return,让cur继续往后面走。
任意位置插入,第一个数据节点为0号下标:
public void addIndex(int index,int data) {
if (index < 0 || index > size()) {
System.out.println("index 位置不合法");
}
if (index == 0) {
addFirst(data);
return;
}
if (index == size()) {
addLast(data);
return;
}
ListNode cur = searchIndex(index);
ListNode node = new ListNode(data);
node.next = cur;
cur.prev.next = node;
node.prev = cur.prev;
cur.prev = node;}public ListNode searchIndex(int index) {
ListNode cur = this.head;
while (index != 0) {
cur = cur.next;
index--;
}
return cur;}思路:先判断 在头位置就头插 在尾位置就尾插 在中间就改变四个位置的值。
注意:单向链表找cur时要-1,但双向链表不用 直接返回cur就好
清空链表:
public void clear() {
while (this.head != null) {
ListNode curNext = head.next;
head.next = null;
head.prev = null;
head = curNext;
}
last = null;}3.3 链表面试题
3.3.1反转链表:
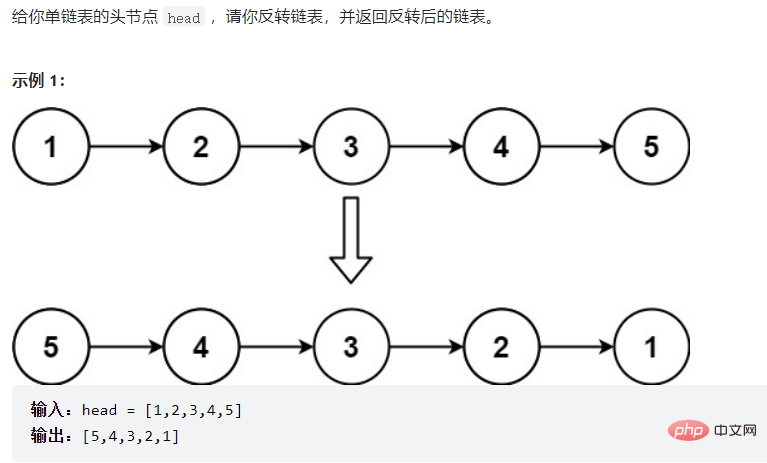

这里的
cur = this.head;
prev = null;
curNext = cur.next;
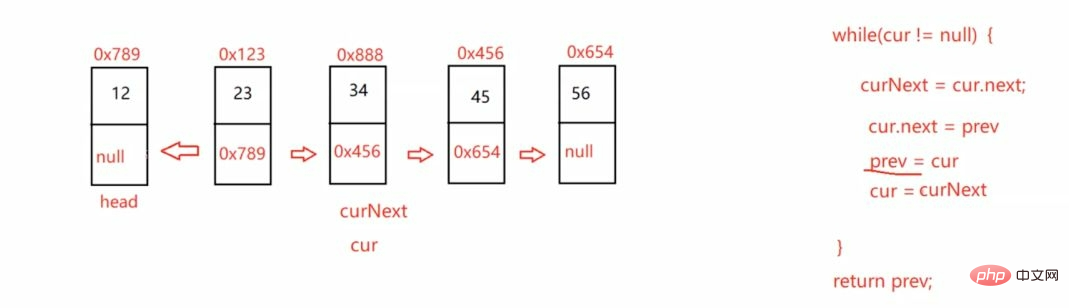
public ListNode reverseList() {
if (this.head == null) {
return null;
}
ListNode cur = this.head;
ListNode prev = null;
while (cur != null) {
ListNode curNext = cur.next;
cur.next = prev;
prev = cur;
cur = curNext;
}
return prev;}3.3.2找到链表的中间结点:


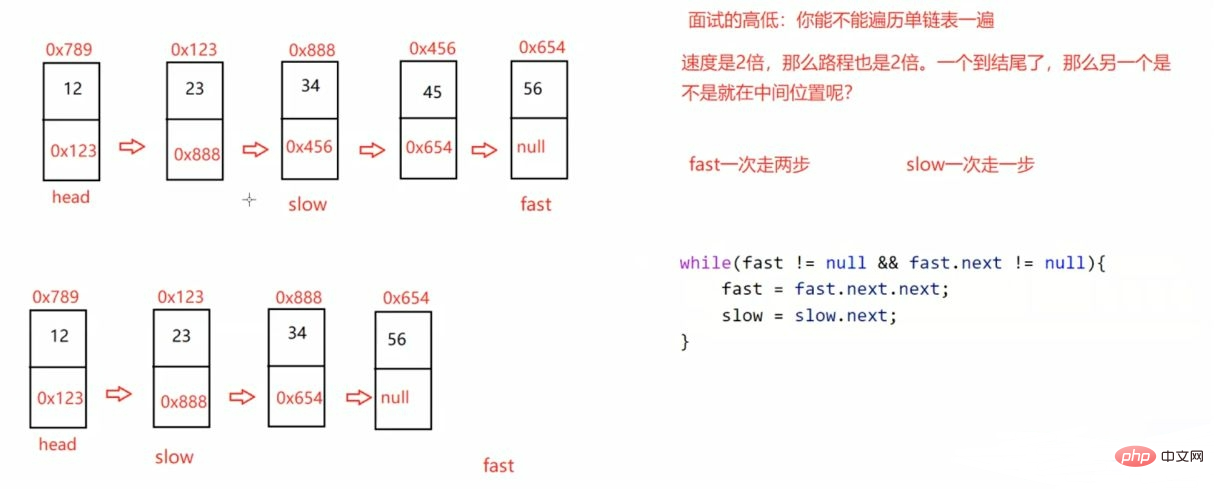
public ListNode middleNode() {
if (head == null) {
return null;
}
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
if (fast == null) {
return slow;
}
slow = slow.next;
}
return slow;}3.3.3输入一个链表 返回该链表中倒数第k个结点

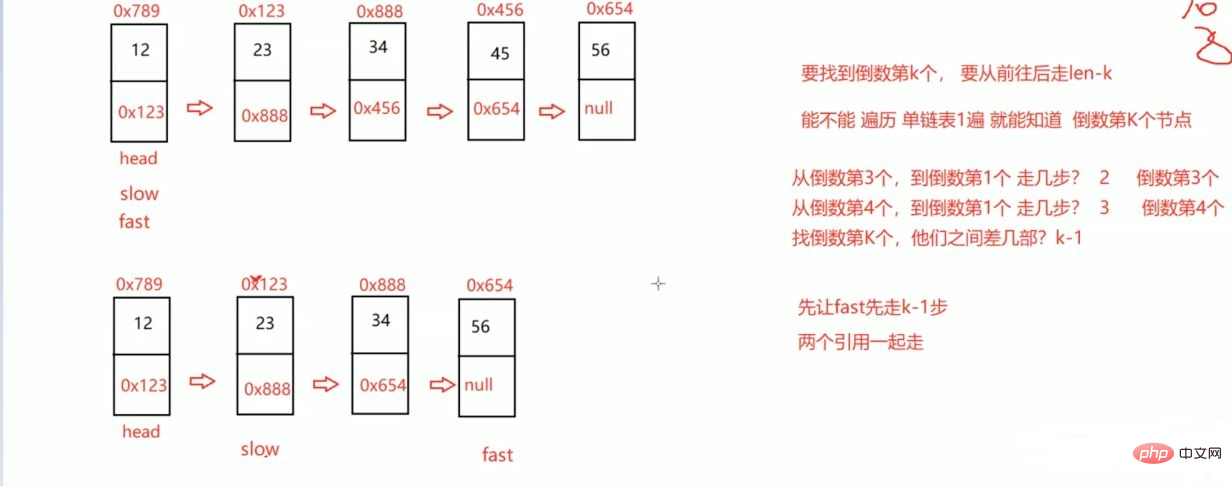
public ListNode findKthToTail(ListNode head,int k) {
if (k <= 0 || head == null) {
return null;
}
ListNode fast = head;
ListNode slow = head;
while (k - 1 != 0) {
fast = fast.next;
if (fast == null) {
return null;
}
k--;
}
while (fast.next != null) {
fast = fast.next;
slow = slow.next;
}
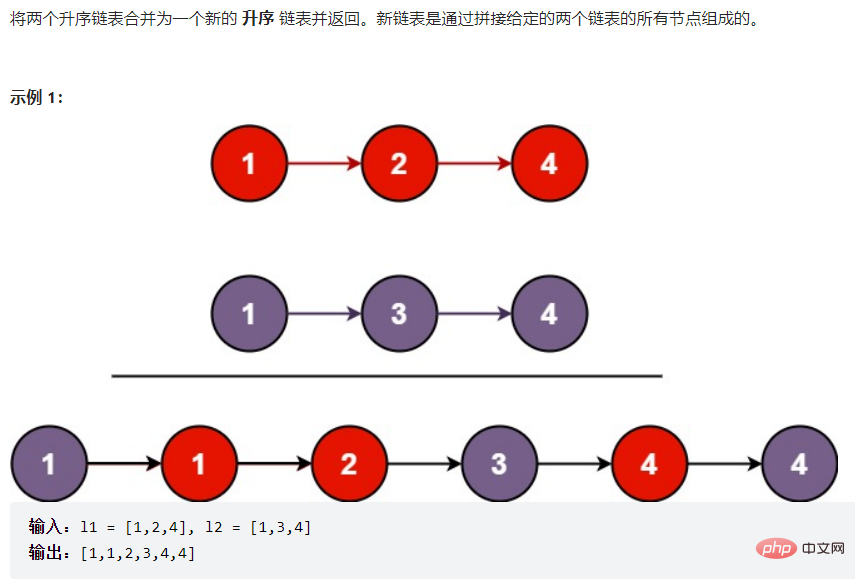
return slow;}3.3.4合并两个链表 并变成有序的

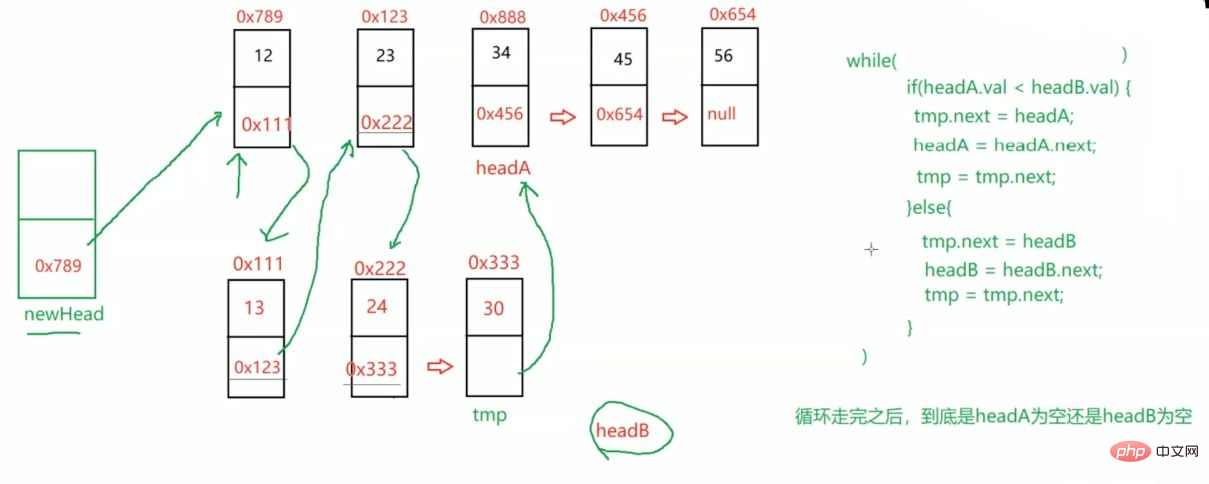
public static ListNode mergeTwoLists(ListNode headA,ListNode headB) {
ListNode newHead = new ListNode(-1);
ListNode tmp = newHead;
while (headA != null && headB != null) {
if(headA.val <headB.val) {
tmp.next = headA;
headA = headA.next;
tmp = tmp.next;
} else {
tmp.next = headB;
headB = headB.next;
tmp = tmp.next;
}
}
if (headA != null) {
tmp.next = headA;
}
if (headB != null) {
tmp.next = headB;
}
return newHead.next;}最后返回的是傀儡结点的下一个 即newHead.next
3.3.5 编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结点之前 。(即将所有小于x的放在x左边,大于x的放在x右边。且他们本身的排序不可以变)

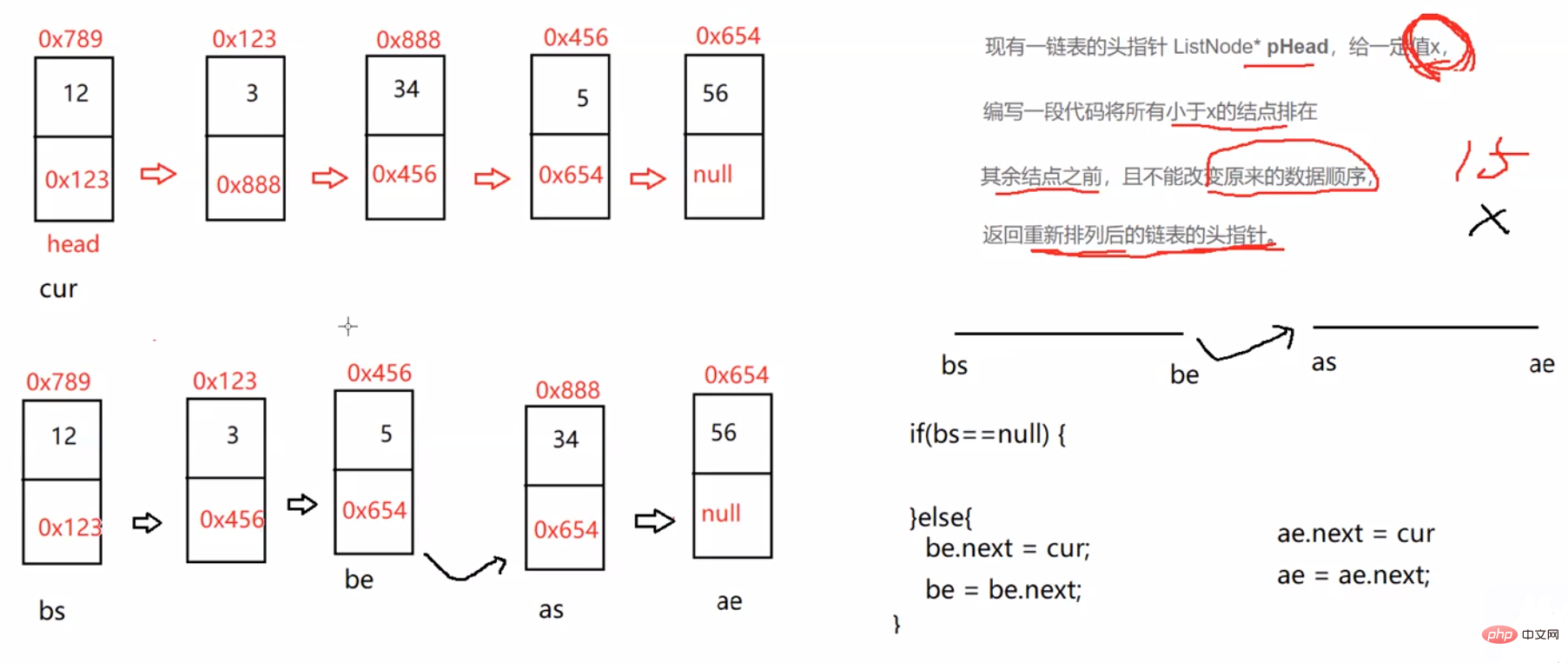
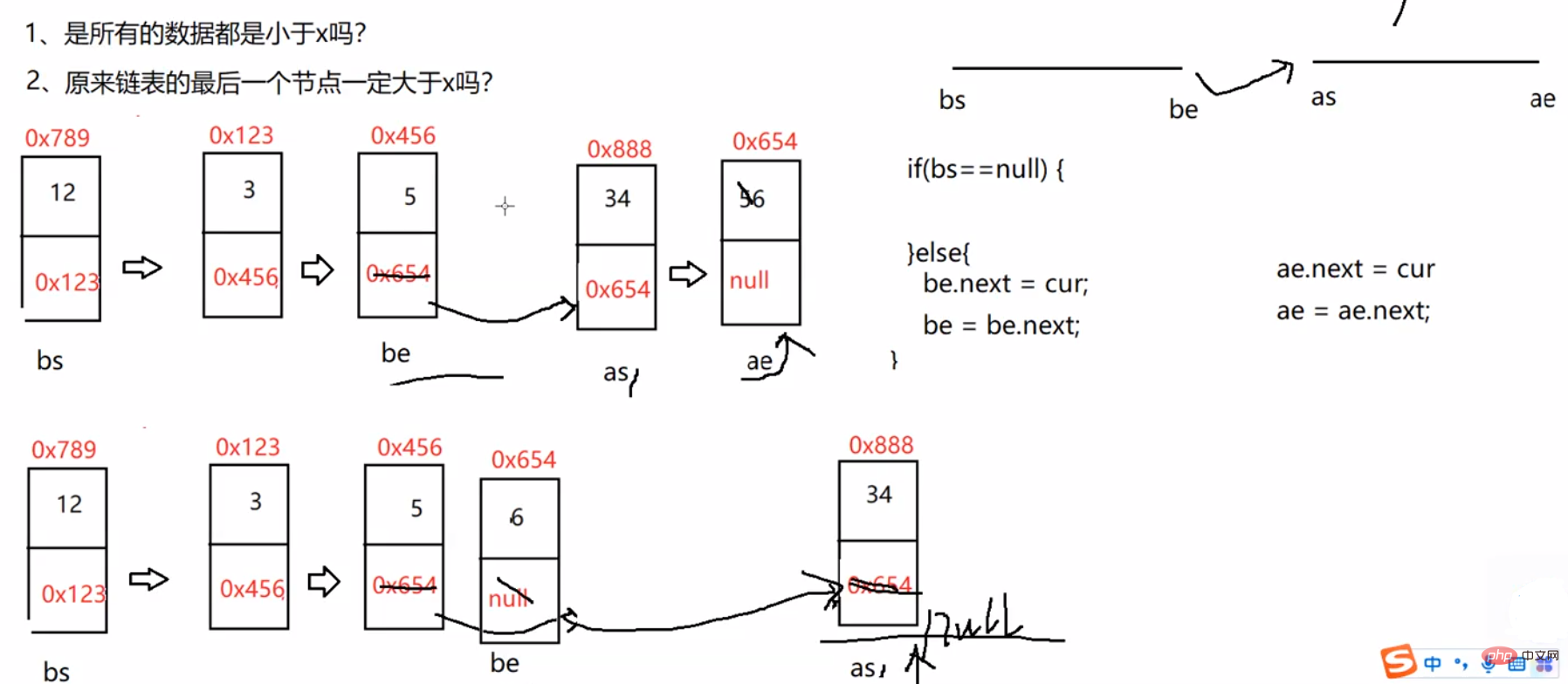
//按照x和链表中元素的大小来分割链表中的元素public ListNode partition(int x) {
ListNode bs = null;
ListNode be = null;
ListNode as = null;
ListNode ae = null;
ListNode cur = head;
while (cur != null) {
if(cur.val < x){
//1、第一次
if (bs == null) {
bs = cur;
be = cur;
} else {
//2、不是第一次
be.next = cur;
be = be.next;
}
} else {
//1、第一次
if (as == null) {
as = cur;
as = cur;
} else {
//2、不是第一次
ae.next = cur;
ae = ae.next;
}
}
cur = cur.next;
}
//预防第1个段为空
if (bs == null) {
return as;
}
be.next = as;
//预防第2个段当中的数据,最后一个节点不是空的。
if (as != null) {
ae.next = null;
}
return be;}3.3.6 在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。(有序的链表中重复的结点一定是紧紧挨在一起的)
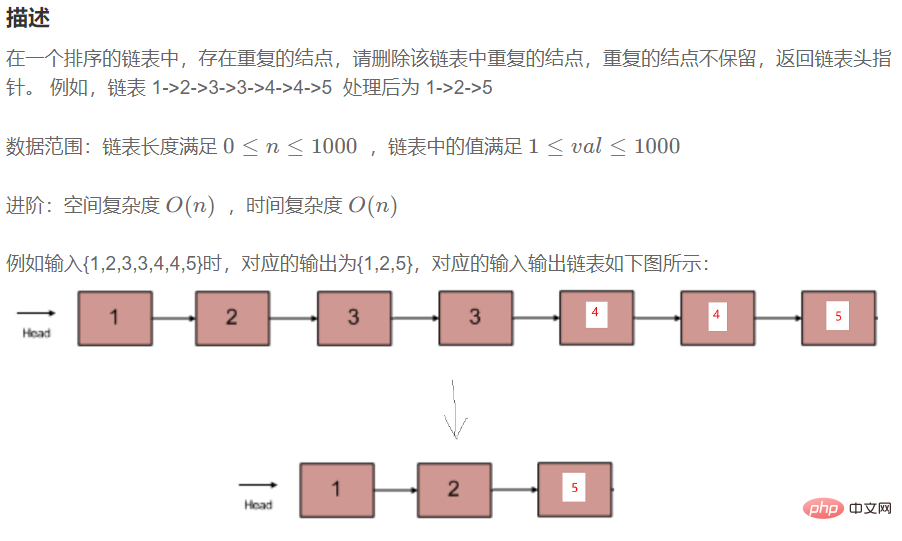

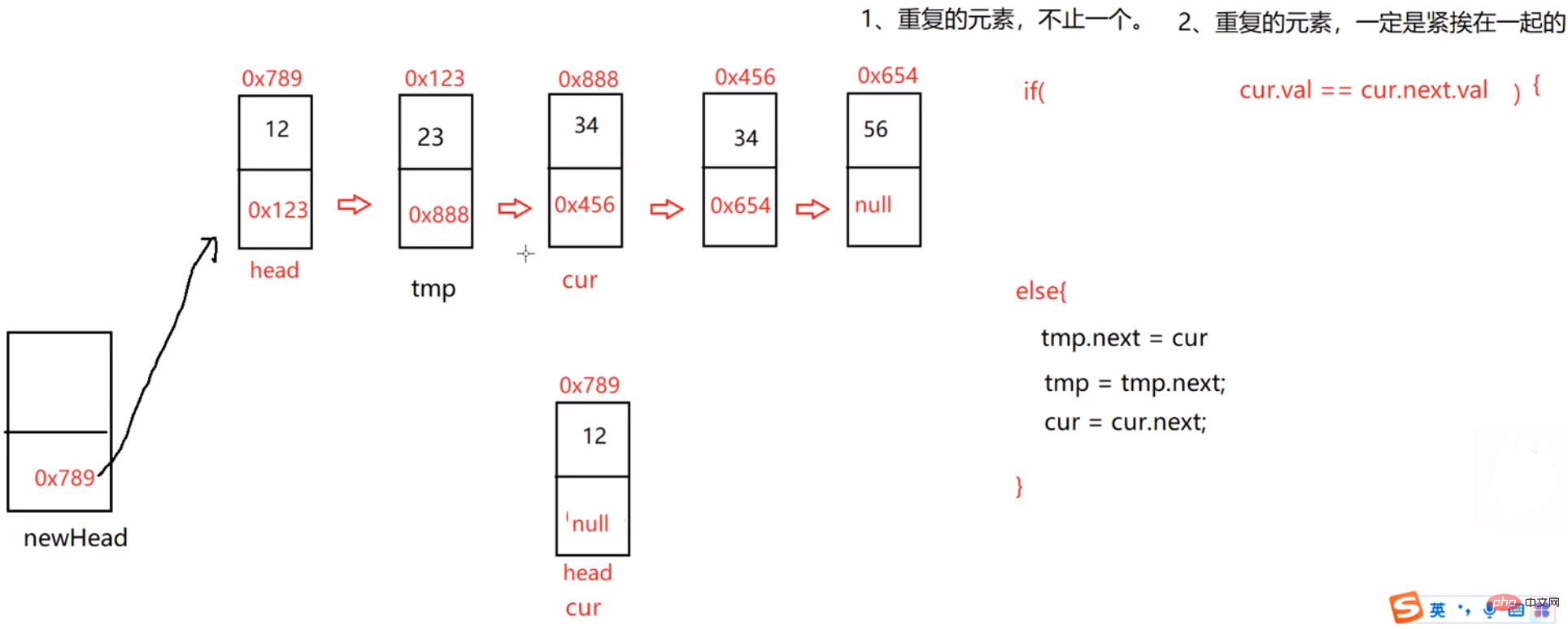
public ListNode deleteDuplication() {
ListNode cur = head;
ListNode newHead = new ListNode(-1);
ListNode tmp = newHead;
while (cur != null) {
if (cur.next != null && cur.val == cur.next.val) {
while (cur.next != null && cur.val == cur.next.val) {
cur = cur.next;
}
//多走一步
cur = cur.next;
} else {
tmp.next = cur;
tmp = tmp.next;
cur = cur.next;
}
}
//防止最后一个结点的值也是重复的
tmp.next = null;
return newHead.next;}3.3.7 链表的回文结构。

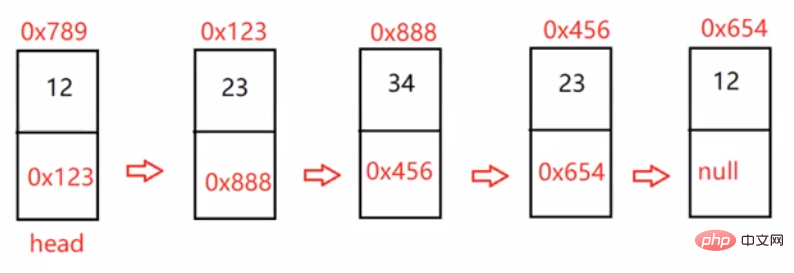
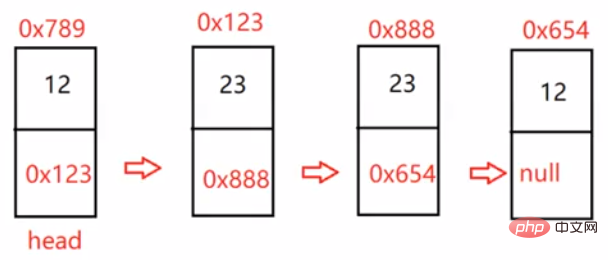
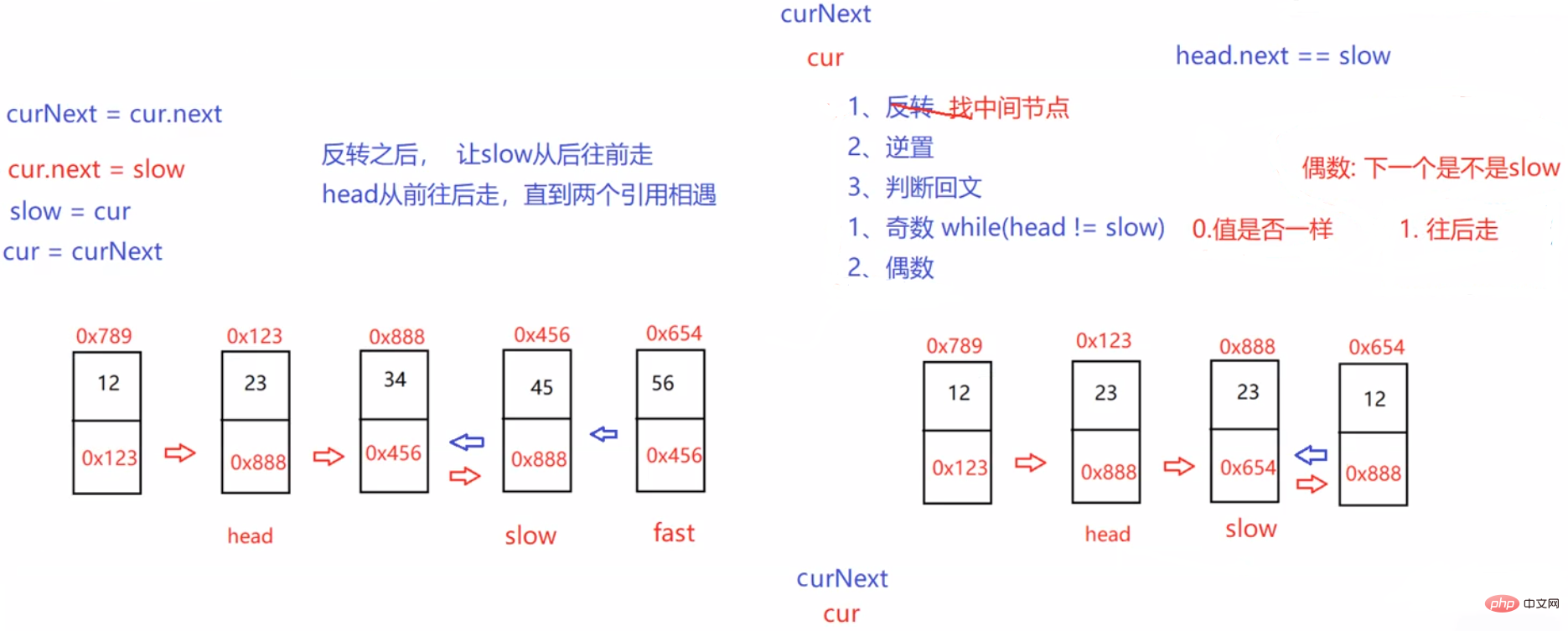
public boolean chkPalindrome(ListNode head) {
if (head == null) {
return true;
}
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
}
//slow走到了中间位置
ListNode cur = slow.next;
while (cur != null) {
ListNode curNext = cur.next;
cur.next = slow;
slow = cur;
cur = curNext;
}
//反转完成
while (head != slow) {
if(head.val != slow.val) {
return false;
} else {
if (head.next == slow) {
return true;
}
head = head.next;
slow = slow.next;
}
return true;
}
return true;}3.3.8 输入两个链表,找出它们的第一个公共结点。
他是一个Y字形
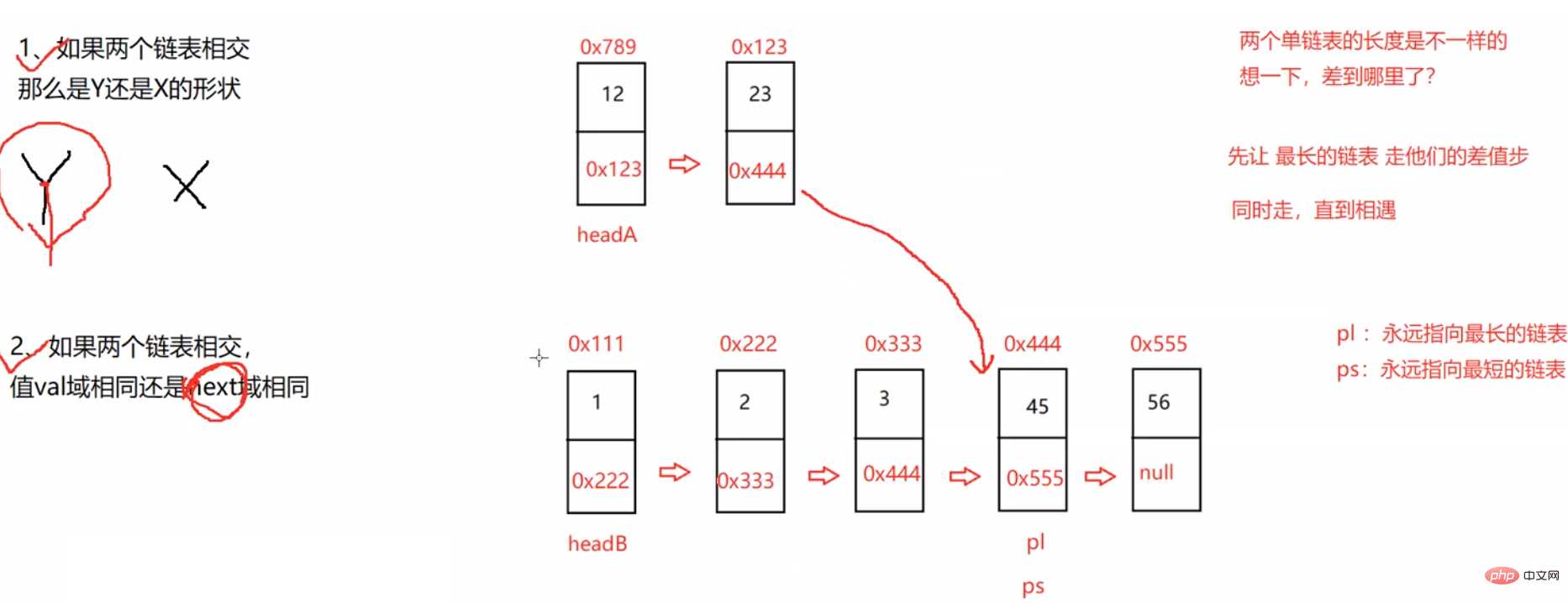

public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
ListNode pl = headA;
ListNode ps = headB;
int lenA = 0;
int lenB = 0;
//求lenA的长度
while (pl != null) {
lenA++;
pl = pl.next;
}
pl = headA;
//求lenB的长度
while (ps != null) {
lenB++;
ps = ps.next;
}
ps = headB;
int len = lenA - lenB;//差值步
if (len < 0) {
pl = headB;
ps = headA;
len = lenB - lenA;
}
//1、pl永远指向了最长的链表,ps永远指向了最短的链表 2、求到了插值len步
//pl走差值len步
while (len != 0) {
pl = pl.next;
len--;
}
//同时走直到相遇
while (pl != ps) {
pl = pl.next;
ps = ps.next;
}
return pl;}3.3.9 给定一个链表,判断链表中是否有环。

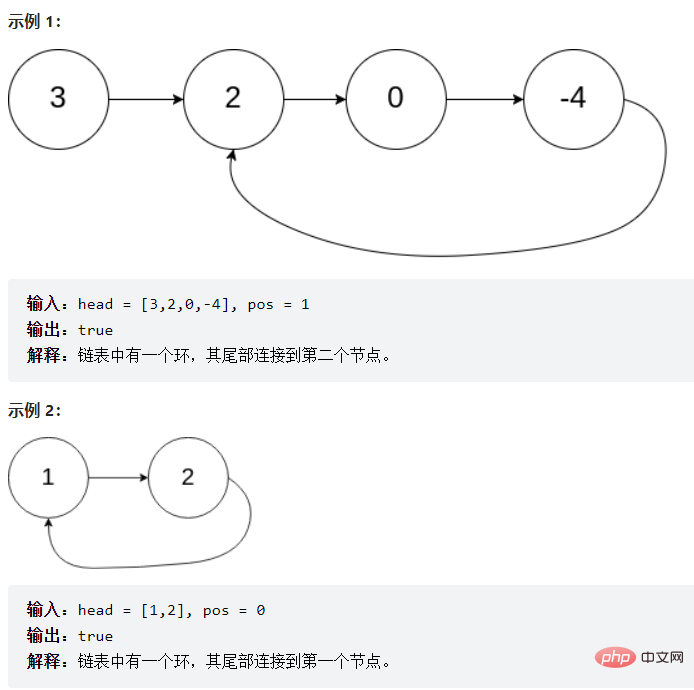

提问:为啥么fast一次走两步,不走三步?
答:如果链表只有两个元素他们则永远相遇不了(如上图的示例2),而且走三步的效率没有走两步的效率高。
public boolean hasCycle(ListNode head) {
if (head == null) {
return false;
}
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) {
return true;
}
}
return false;}3.3.10 给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null

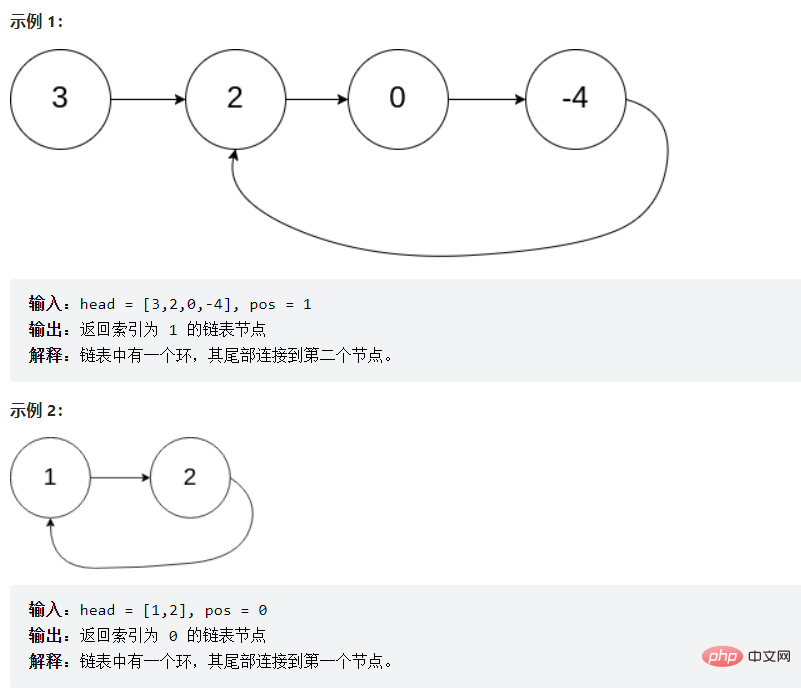

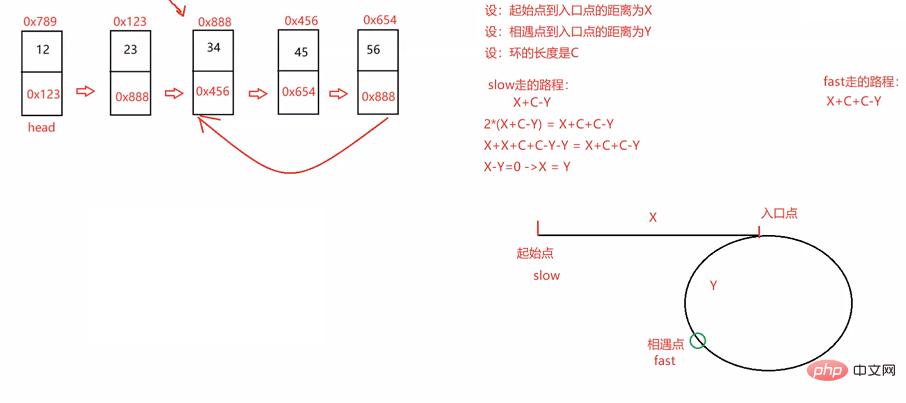
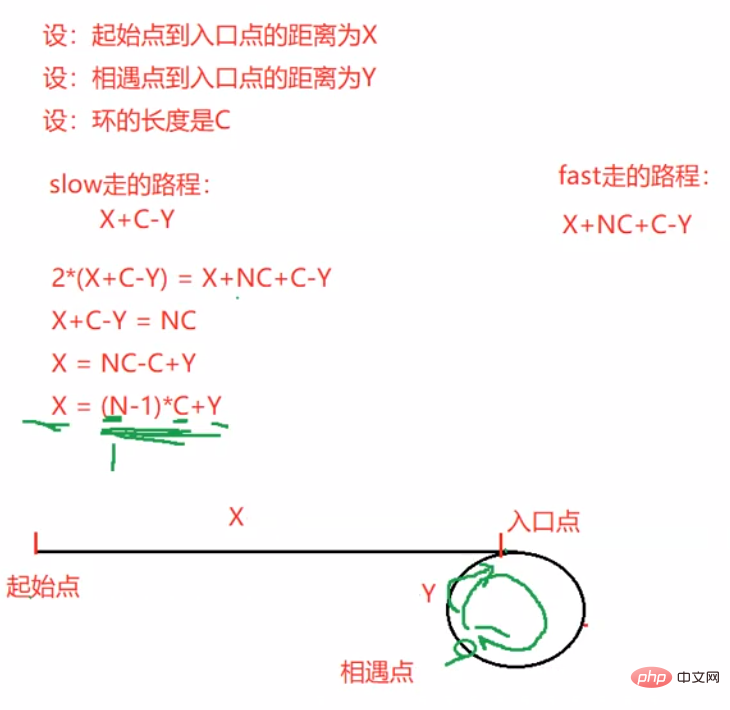
public ListNode detectCycle(ListNode head) {
if (head == null) {
return null;
}
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) {
break;
}
}
if (fast == null || fast.next == null) {
return null;
}
fast = head;
while (fast != slow) {
fast = fast.next;
slow = slow.next;
}
return fast;}4. 顺序表和链表的区别和联系
4.1顺序表和链表的区别
顺序表:一白遮百丑
白:空间连续、支持随机访问
丑:
链表:一(胖黑)毁所有
胖黑:以节点为单位存储,不支持随机访问
所有:
组织:
1、顺序表底层是一个数组,他是一个逻辑上和物理上都是连续的
2、链表是一个由若干结点组成的一个数据结构,逻辑上是连续的 但是在物理上[内存上]是不一定连续的。
操作:
1、顺序表适合,查找相关的操作,因为可以使用下标,直接获取到某个位置的元素
2、链表适合于,频繁的插入和删除操作。此时不需要像顺序表一样,移动元素。链表的插入 只需要修改指向即可。
3、顺序表还有不好的地方,就是你需要看满不满,满了要扩容,扩容了之后,不一定都能放完。所以,他空间上的利用率不高。
4.2数组和链表的区别
链表随用随取 要一个new一个
而数组则不一样 数组是一开始就确定好的
4.3AeeayList和LinkedList的区别
集合框架当中的两个类
集合框架就是将 所有的数据结构,封装成Java自己的类
以后我们要是用到顺序表了 直接使用ArrayList就可以。
推荐学习:《java视频教程》
以上がJavaのシーケンスリストとリンクリストを例を交えて詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7494
7494
 15
1377
52
77
11
19
49
15
1377
52
77
11
19
49


 Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーターのガイド。ここでは、Java の関数について例を挙げて説明し、2 つの異なるジェネレーターについて例を挙げて説明します。
 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
