

ノードのメモリ リークをトラブルシューティングするにはどうすればよいですか?次の記事は、ノードのメモリ リークのトラブルシューティング体験をまとめたもので、皆様のお役に立てれば幸いです。

Nodejs サーバーサイド開発のシナリオでは、メモリ リーク が間違いなく最も厄介な問題です。
しかし、プロジェクトが開発され反復され続ける限り、メモリ リークの問題は絶対に避けられず、遅かれ早かれ発生するだけです。したがって、効果的な メモリ リーク トラブルシューティング方法を体系的に習得することは、Nodejs エンジニアの最も基本的かつ中心的な能力です。
メモリ リークに対処する際の難しさは、無数の関数や関数の中から、どの行のどの関数や関数がメモリ リークの原因となっているのかを正確に特定する方法です。
残念ながら、現時点ではメモリ リークを簡単に特定できるツールは市場に存在しないため、この問題に初めて遭遇した多くのエンジニアは混乱し、対処方法がわからなくなるでしょう。
ここでは、22 年間に Memory Leak を調査した事例に基づいて、私の対処方法を共有します。
2022 Q4 ある日、研究開発ユーザー グループから、当社の研究開発プラットフォームにアクセスできないことが報告され、多数のユーザーがバックグラウンドで例外が発生しました。タスクは完了していません。
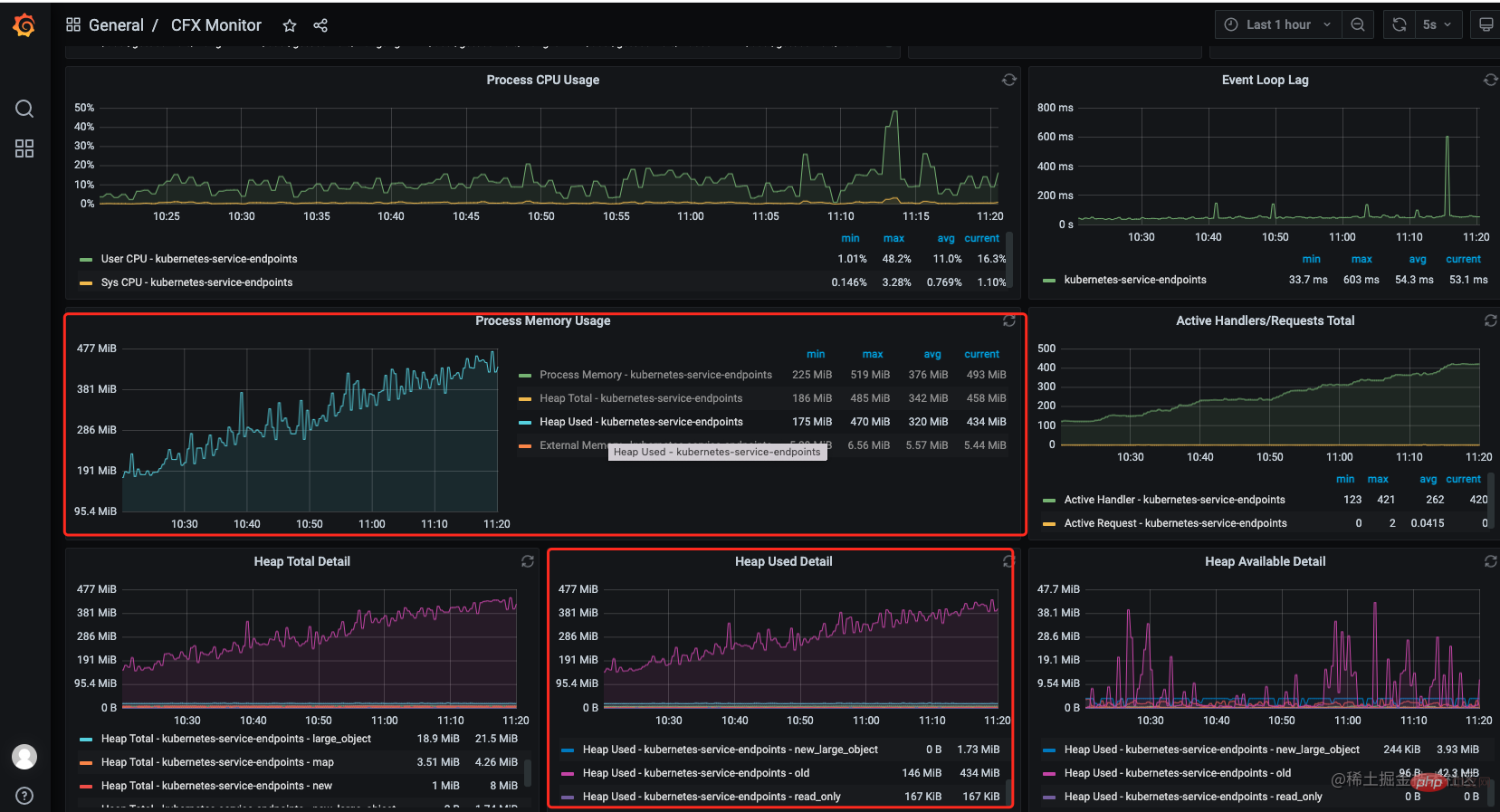
最初の反応は、メモリ リークの可能性があるということです。幸いなことに、サービスはモニタリング (prometheus grafana) に接続されています。grafana モニタリング パネルでは、 10.00 以降、メモリが制御不能になっていることが判明しました。明らかなデータ漏洩が発生しました。 [関連チュートリアルの推奨事項: nodejs ビデオ チュートリアル ]
メモリ リークの種類##手順 :
- プロセス メモリ
:rss(常駐セット サイズ)、プロセスの常駐メモリ サイズ。- heapTotal
: V8 ヒープの合計サイズ。- heapused
: 使用される V8 ヒープのサイズ。- external
: V8 オフヒープ メモリの使用量。Nodejs
のグローバル メソッドprocess.memoryUsage()を呼び出して、heapTotalと # を含むこれらのデータを取得できます。 ##heapusedは V8 ヒープの使用量であり、Node.js内の JavaScript オブジェクトが保存される場所です。また、externalは、C オブジェクトなど、非 V8 ヒープに割り当てられたメモリを表します。rssは、プロセスの合計メモリ使用量です。一般に、監視データを確認するときは、heapusedインジケーターに注目してください。
グローバル メモリ リーク
および コンポーネント で発生します。このタイプのメモリ リークもトラブルシューティングが最も簡単です。 残念ながら、
で発生したメモリ リークはこのタイプに属さないため、ローカル リークの考え方に従って分析する必要があります。
:
, コンポーネント、または他の一般的なロジックの使用)
Nuxt## ベースの SSR アプリケーションを開発していたときのことです。 # では、オンラインにする前のストレス テストでアプリケーション メモリ リークが見つかり、グローバルであることが判明しました。予期せぬリークの後、二分法を使用して問題を特定するのに約 30 分かかりました。当時のリークの原因は、サーバー側で
永続的なメモリ リークの部分的なトラブルシューティングaxiosを使用していたためでしたが、その後、
axiosを統合し、関連するものをすべてnode- に置き換えました。 fetchで解決しました。それ以来、axios PDSTに切り替えました。axiosをNodeサービスで使用することはありません。
. 特定の 非同期タスク では、このような特性により、トラブルシューティングも困難になります。この場合、分析のために heapdump が実行されます。 <p>ここでは主にこの場合の私のアイデアについて話します。<code>heapdump の詳細な説明は次の段落
Heap Dumpに記載します。 : ヒープ ダンプ。以下の部分はすべてheapdumpで表されます。heapdumpを実行するためのツールやチュートリアルは数多くあります (chrome、vscode、heapdump オープン ソース ライブラリなど)。私が使用するヒープダンプ ライブラリに関するオンライン チュートリアルは多数ありますが、ここでは説明しません。
ローカル メモリ リークのトラブルシューティングには、ある程度のメモリ リークのトラブルシューティングの経験が必要です。問題が発生するたびに、自分自身のテストとして扱ってください。経験を積んでから、メモリのトラブルシューティングを行うことができます。漏れの問題は後で発生しますが、それはますます速くなります。
これは非常に重要であり、これを知っておくと、調査の範囲が大幅に狭まる可能性があります。
この状況はよく発生します。この反復には 3 つの関数 A、B、C があり、ストレス テスト中またはオンラインになった後にメモリ リークが発生します。その後、直接ロックできるようになり、これら 3 つの新しい関数の間で小さなメモリ リークが発生します。この場合、heapdump を実行するために運用環境に移動する必要はありません。いくつかのツールを使用してローカルでメモリ リーク ポイントを簡単に分析し、特定することができます。
2020 年の Q4 における特殊な状況により、メモリ リークが見つかったとき、メモリ リークが最初に発生した時期を特定することが困難でした。大まかに 1 でロックすることしかできません。数か月以内に。今月もメジャーバージョンアップを行っているのですが、これらの機能やインターフェースを一つ一つチェックしていくと、かなりのコストがかかってしまいます。
したがって、さらに分析するには、より多くのデータを組み合わせる必要があります
ノード追加--expose-gc、このパラメータは gc() メソッドをグローバルに挿入して、GC の手動トリガーを容易にし、より正確な ヒープ スナップショットdata#プロジェクト開始後の初めてのスナップショット データの印刷ノード サービスは
heapdump中に中断されます。この時間は、その時点のサーバー メモリのサイズに応じて約 2 ~ 30 分になります。 。運用環境で
- heapdump
クリティカル ポイントでスナップショットを印刷するというのは、漠然とした説明ですが、試したことがある方ならわかると思いますが、メモリ スナップショットを印刷する前にクリティカル ポイントのすぐ近くで待機すると、印刷されません。したがって、この程度に近づくには自分をコントロールする必要があります。を実行するには、運用および保守と協力して合理的な戦略を策定する必要があります。ここでは、2 つのプライマリpodとセカンダリpodを使用します。プライマリpodが停止すると、ビジネス リクエストは、本番稼働を確保するためにセカンダリpodにロード バランシングされます。ビジネスの。 (このプロセスは運用保守と緊密に連携したプロセスである必要があります。結局のところ、heapdumpもそれらを通じてサーバー内のheap snapshotファイルを取得する必要があります)- 少なくとも 3 回実行してください
- heapdump
(実際には、最も詳細なデータを取得するために 5 回実行しました)
prometheus grafana を使用します。主にサービスの次の指標を監視します
サービス プロセスの再起動数、heapused、external、heapAvailableDetailデータのみが含まれません。十分です、heapdump
私の解析・処理結果データは非常に曖昧であり、視覚化ツールのサポートがあっても、問題を正確に特定することは困難です。今回はgrafanaのデータをいくつか組み合わせて見てみました。
grafana
モニタリング インターフェイスを通じて、メモリが増加していて減少していないことがわかりますが、同時に の数が減少していることにも気づきました。サービス内のハンドル も急増していますが、落ちることはありません。
2. これは、リークが発生した月の新機能を確認し、メモリ リークは bull メッセージ キュー コンポーネントの使用によって引き起こされているのではないかと疑ったときのことです。まず、関連するアプリケーション コードを分析しましたが、メモリ リークを引き起こすような問題があるとはわかりませんでした。
1.のハンドルリークの問題と合わせると、bullを使用した後に特定のリソースを手動で解放する必要があるようですが、現時点では具体的な理由はわかりません。
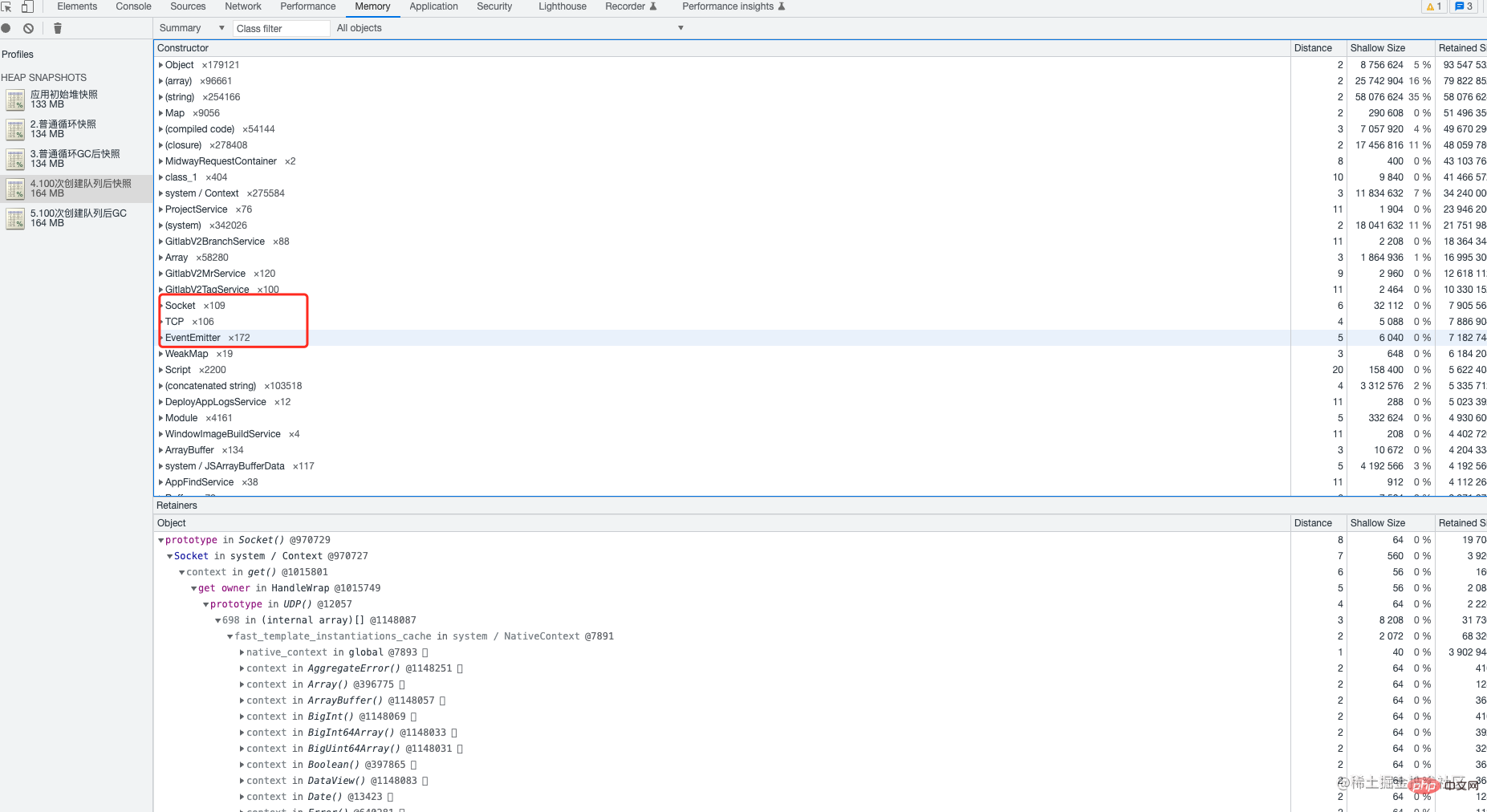
3. 次に、5 回分の heapdunmp データを分析し、そのデータを chrome にインポートしました。5 回分のヒープ スナップショットを比較した結果、次のことがわかりました。各キューの作成後、 TCP 、 Socket 、 EventEmitter イベントは解放されません。現時点では、bull の不規則な使用が原因であることはほぼ確実です。 bull では、通常、キューは頻繁に作成されず、キューによって占有されているシステム リソースは自動的に解放されないため、必要に応じて手動で解放する必要があります。
#4. コードを調整した後、再度ストレス テストを実行したところ、問題は解決しました。
ヒント: Nodejs の
handleは、基礎となるシステム リソース (ファイル、ネットワーク接続など) を指すポインターです。ハンドルを使用すると、Node.js プログラムは、基盤となるシステムと直接対話することなく、これらのリソースにアクセスして操作できるようになります。ハンドルは、Node.js ライブラリまたはモジュールで使用されるハンドルの種類に応じて、整数またはオブジェクトになります。 CommonHandle:#ヒープダンプ分析の概要
- #fs.open()
返されるファイル ハンドル- net.createServer()
返されるネットワーク サーバー ハンドル- dgram.createSocket()
返された UDP ソケット ハンドル- child_process.spawn()
#crypto.createHash()返された子プロセス ハンドル- 返されたハッシュ ハンドル
zlib.createGzip()- 返された圧縮ハンドル
chrome; 概要ビュー
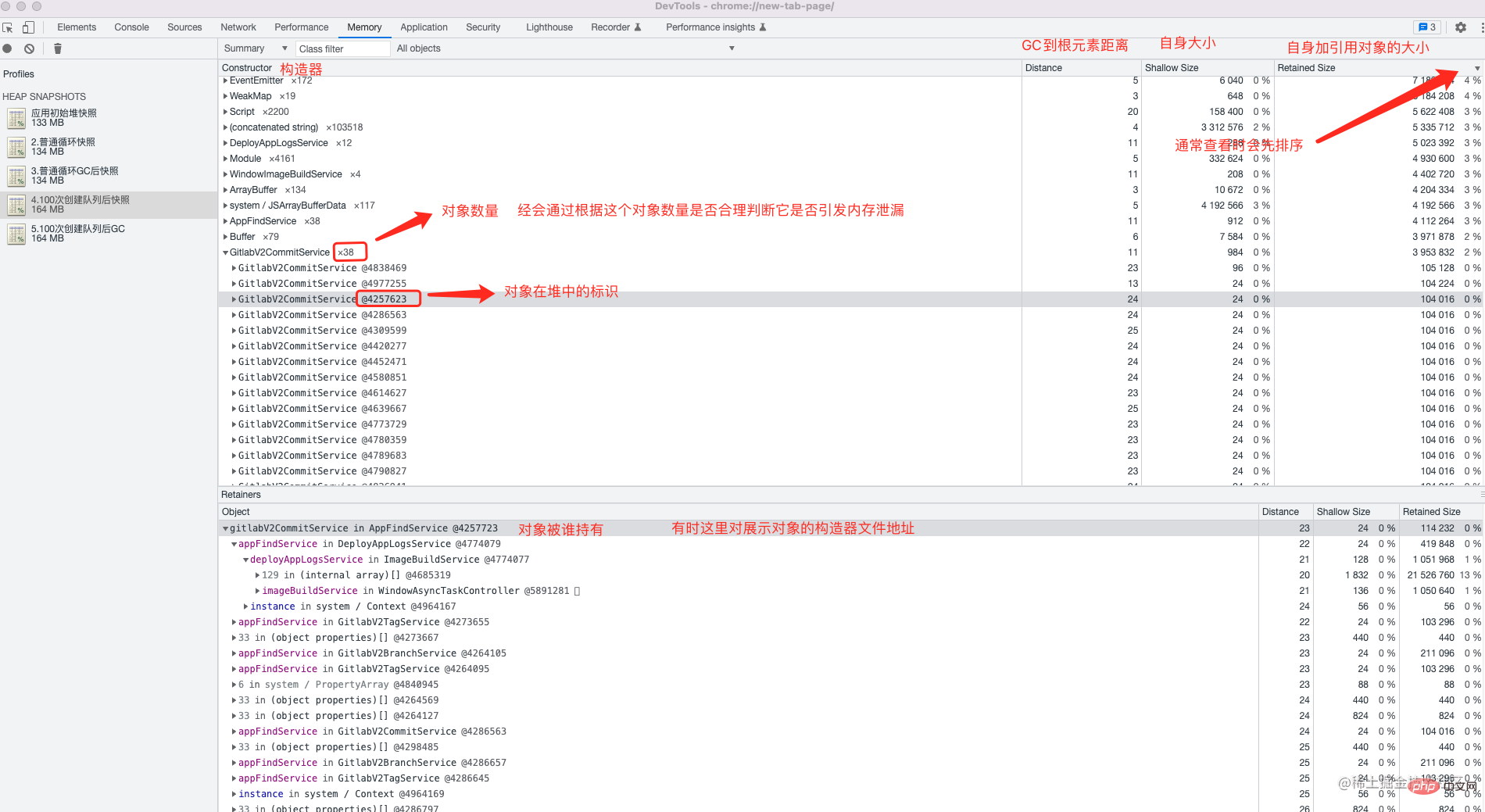
##ソケット など、メモリ リークが発生しやすい一部のオブジェクトにも注意が必要です。 EventEmitterグローバル ビューを使用します。このビューを通じて、2 つのヒープ スナップショット内のオブジェクトの数と、オブジェクトが占有するメモリの変化を比較できます。
この情報を通じて、ヒープ内のオブジェクトの値を判断し、一定の操作 (特定の操作) 後のメモリの変化を判断することができ、これらの値を通じて異常なオブジェクトを見つけることができます。これらのオブジェクトの名前属性または関数によって、メモリ リーク調査の範囲が狭まる可能性があります。 [比較] ビューで 2 つのヒープ スナップショットを選択し、それらを比較します。 2 つのヒープ スナップショット間でどのオブジェクトが追加されたか、2 つのヒープ スナップショット間でどのオブジェクトが削減されたか、どのオブジェクトのサイズが変更されたかを確認できます。
ビューでは、オブジェクト間の関係だけでなく、タイプ、サイズ、参照カウントなどのオブジェクトの詳細も表示できます。この情報により、どのオブジェクトがメモリ リークの原因となっているかを理解できます。
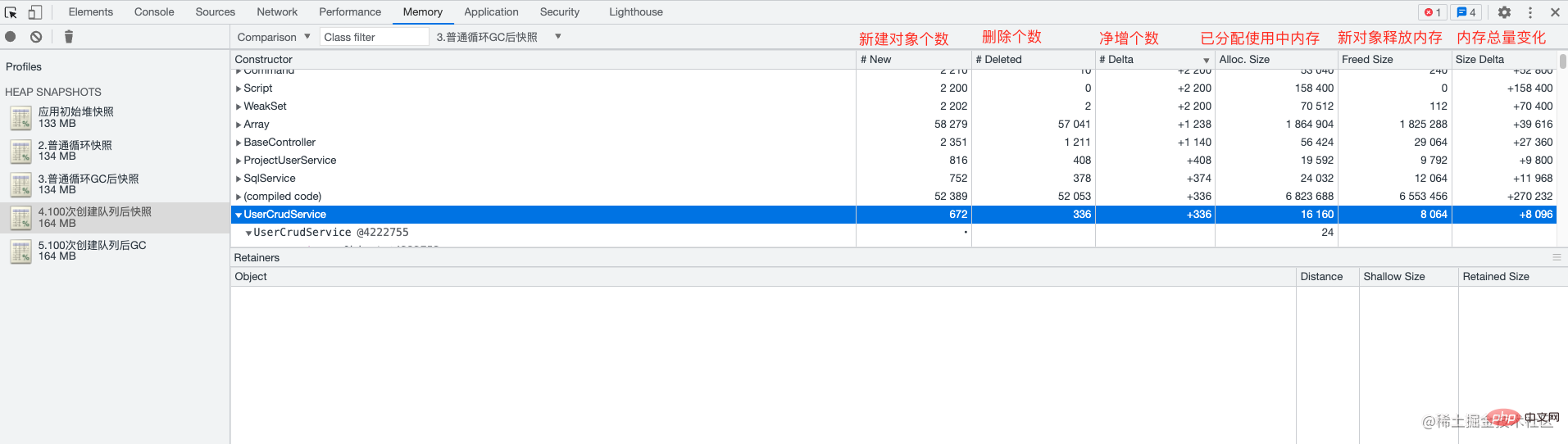
#統計ビュー
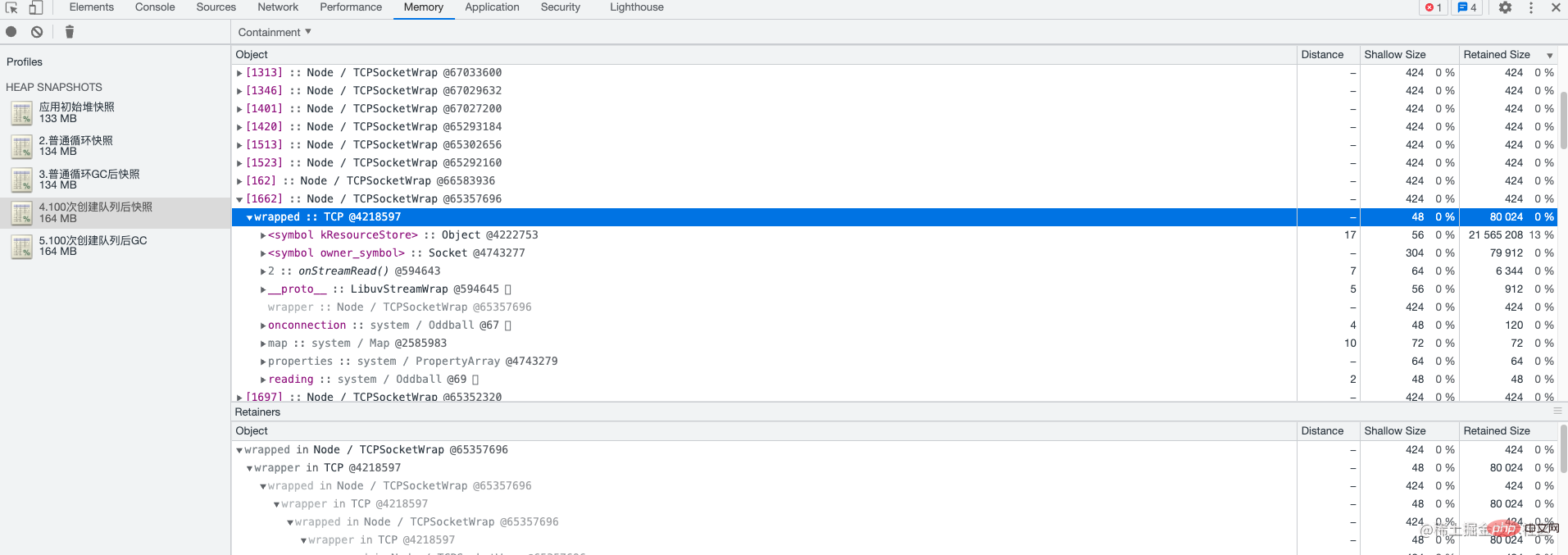 この図は非常に単純なので、詳細については説明しません
この図は非常に単純なので、詳細については説明しません
lru-cache 保存しすぎるとメモリ不足になります。Nodejs サービスでは lru-cache問題の種類を初めて特定しやすくするために、サービスにはアクセス監視が必要です
メモリ リークがグローバルかローカルかを判断します
二分法を使用して、グローバル メモリ リークのトラブルシューティングを迅速に行い、特定します。
ローカル メモリ リーク
メモリ リークの問題が発生しても恐れることはありません。メモリ リークの問題のトラブルシューティングでより多くの経験を積んでください。処理の経験が増えるほど、メモリ リークの問題は、すぐに見つけやすくなります。各解決策の後で、レビューと要約を実行し、もう一度振り返ります
ヒープ スナップショットデータは、関連するエクスペリエンスをより速く蓄積するのに役立ちます
ノード関連の知識については、nodejs チュートリアルを参照してください。
以上が【体験談まとめ】Nodeのメモリリークのトラブルシューティング方法は?アイデアを共有するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。












![Node.js の完全な入門チュートリアル [es6+npm+express+webpack+promise]](https://img.php.cn/upload/course/000/000/068/6242b4c8f1a39624.png)







![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



