

MySQL のデータベース バッファ プール (バッファ プール) について理解します。


InnoDB ストレージ エンジンを使用するテーブルの場合、メモリとディスク間のスワップインおよびスワップアウトの基本粒度として、ストレージ スペースがページ単位で管理されます。ページをディスクからメモリにロードすると、ディスク I/O が実行されます。ディスク I/O のオーバーヘッドは全体のパフォーマンスに大きく影響しますが、対応するページをメモリから直接読み込めば、ディスク I/O によるパフォーマンスの低下が軽減され、効率が大幅に向上するのではないでしょうか。これを踏まえて、Buffer Pool (
Buffer Pool) が登場したので、次は InnoDB の Buffer Pool について説明します。
バッファ プール
バッファ プールは非常に優れているので、すべてのデータをバッファ プールに保存すればよいのではないかと考える人もいるかもしれません。いいえ、いいえ、バッファ プールは、オペレーティング システムによって割り当てられる連続したメモリです。メモリはディスクに比べて容量がはるかに小さく、高価です。それでは、オペレーティング システムはバッファ プールにどれだけのメモリを割り当てるのでしょうか?
- デフォルトでは、バッファ プールのサイズは 128MB です;
もちろん、マシンのメモリ容量が非常に大きい場合は、起動オプション パラメータを構成できます。構成ファイル innodb_buffer_pool_size の単位は bytes で、最小値は 5MB 未満にすることはできません。
バッファ プールの内部構造
バッファ プールは、オペレーティング システムによって割り当てられた連続メモリを、デフォルト サイズ 16KB の複数のページ (バッファ ページ) に分割します [現時点では、ディスク ページはバッファ プールにキャッシュされます] ページをディスクからバッファ プールにスワップするとき、その場所はどのように割り当てられますか?そのため、これらのバッファプール内のバッファページを識別するための制御情報が必要となり、この制御情報はコントロールブロックと呼ばれるメモリ領域に格納され、バッファページと1対1に対応している。制御ブロックのサイズも固定です。したがって、この連続したメモリ空間では、必然的にメモリの断片化が発生します。要約すると、バッファ プールの内部構造は次のようになります。
- バッファ ページ
- 制御ブロック: ページ番号、バッファ プール内のバッファ ページのアドレス、リンク リスト ノード情報など
- メモリの断片化 [メモリが適切に割り当てられている場合、メモリの断片化は不要です]
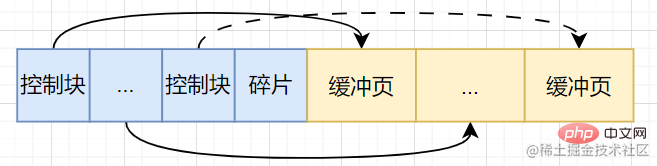
バッファ プールの管理
上記のリンク先リストノード情報は制御ブロックに記載されていますが、リンクリストノードは何に使用されるのでしょうか?これは、バッファー プール内のページをより適切に管理するためです。制御ブロックとバッファ ページの間には 1 対 1 の対応があるため、リンク リストは制御ブロックをリンクするために使用されます。
1) フリー リンク リスト
すべてのフリー バッファ ページに対応するコントロール ブロックをリンクして、リンク リストを形成します。
問題の解決策: ページをディスクからバッファー プールにスワップするとき、バッファー プール内のどのページが空いているかを識別するにはどうすればよいですか?フリー リンク リストでは、ディスク ページがバッファ プールにスワップされると、フリー リンク リストから直接フリー バッファ ページが取得され、ディスク ページ内の対応する情報がバッファ ページに対応する制御ブロックに埋められます。そして、フリーリンクリストからコントロールブロックを削除するだけです。
2) リンク リストの更新
バッファ プール内のバッファ ページのデータが変更され、ディスク上のデータと不整合が生じた場合、そのページはダーティ ページと呼ばれます。 。すべてのダーティ ページに対応する制御ブロックをリンクして更新リンク リストを形成し、このリンク リストに基づいて将来のある時点で対応するキャッシュ ページのデータをディスクにリフレッシュします。
3) LRU リンク リスト
バッファ プールのサイズには制限があり、キャッシュされたページがバッファ プールのサイズを超える場合、つまり、空きバッファ ページがありません。追加される新しいページです。バッファ プールに入るとき、LRU 戦略が採用され、バッファ プールから古いバッファ ページが削除されてから、新しいページが追加されます。 LRU リンクリストは内容が多いので、次回は別途紹介します。
LRUリンクリストに含まれる「理念」
まずは先読みの仕組みについて触れておきます
I/Oの最適化の仕組みその名の通り、これらのページはバッファ プールにロードされ、すぐに必要になることが予想されます。これらのリクエストでは、範囲内のすべてのページが導入されます。これは、いわゆる ローカリティ原則 . 目的は、ディスク I/O を削減することです。
先読みメカニズムを理解する前に、InnoDB の論理ストレージ ユニット (テーブルスペース → セグメント → エクステント → ページ) を確認してみましょう。後で使用する領域について具体的に説明します。領域は、物理的な場所で連続した 64 ページ です。つまり、領域のサイズは 1MB です。
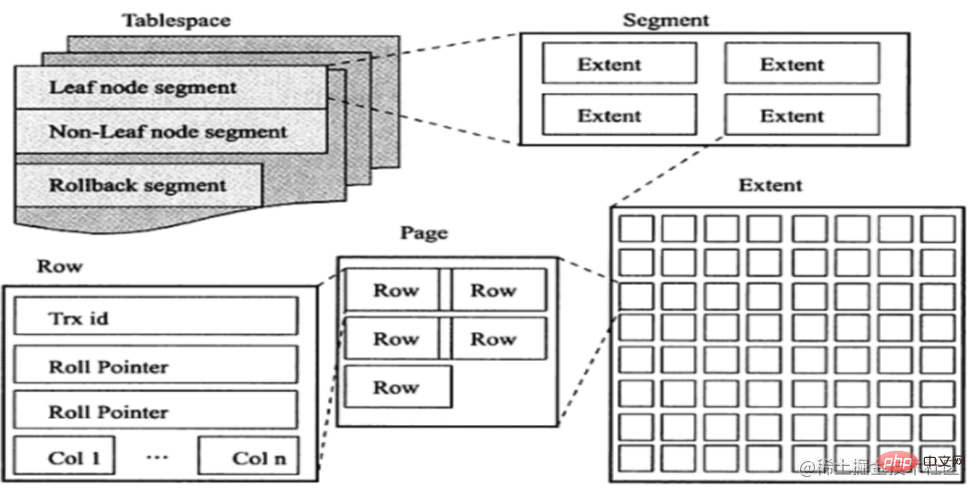
先読みメカニズムは、次の 2 つのタイプに細分できます。
- 線形先読み: バッファ プール内で順次アクセスされるページに基づいて、どのページがすぐに必要になるかを予測する手法。 innodb_read_ahead_threshold パラメータを設定すると、連続してアクセスされる特定の領域のページがこのパラメータの値を超えると、非同期読み取りリクエストがトリガーされ、次の領域のすべてのページがバッファ プールに読み込まれます。
- ランダム先読み: ページが読み取られる順序に関係なく、バッファ プール内にすでにあるページに基づいて、ページがいつ必要になるかを予測できます。同じエクステントの連続した 13 ページがバッファ プール内で見つかった場合、InnoDB はエクステントの残りのページをプリフェッチするリクエストを非同期的に発行します。ランダム読み取りは、変数 innodb_random_read_ahead を構成することで制御されます。 従来の LRU はバッファ ページをどのように管理しますか?
LRU アルゴリズムを使用して、最も最近使用されていないバッファ ページを管理し、対応するリンク リストを形成して簡単に削除します。
ページがアクセスされると (つまり、最新のアクセスが)
ページがバッファー プール内にあると、対応する制御ブロックがリンクされた LRU の先頭に移動されます。 list- ページはバッファ プールにありません。バッファ プールでは、最後にある最も最近使用されていないページが削除され、そのページがディスクからロードされ、LRU リンク リストの先頭に配置されます
- では、なぜ InnoDB はこのような直感的な LRU アルゴリズムを使用しないのでしょうか?理由は次のとおりです。
- 先読み失敗
バッファ プールに先読みされたページは、LRU の先頭に配置されます。リンクされたリストですが、その多くはページが読み取れない可能性があります。
- バッファ プールの汚染
低頻度のページをバッファ プールに多数読み込むと、高頻度のページがバッファから削除されます。プールから削除されます。 。たとえば、
full table scan 最適化された LRU はバッファ ページをどのように管理しますか?
上記の欠点に基づいて、特定の最適化された方法では、従来の LRU リンク リストをホット データ エリア [若いエリア] とコールド データ エリア [古いエリア] の 2 つの部分に分割します。
ホットデータ領域 [若い領域]: 使用頻度の高いバッファページ
- コールドデータ領域 [古い領域] : 使用頻度の低い領域
- 構造図は次のとおりです。
innodb_old_blocks_pct オプションは、コールド データ領域の 割合を制御します。
#改良された LRU は、先読み障害の問題をどのようにより適切に解決できるでしょうか?
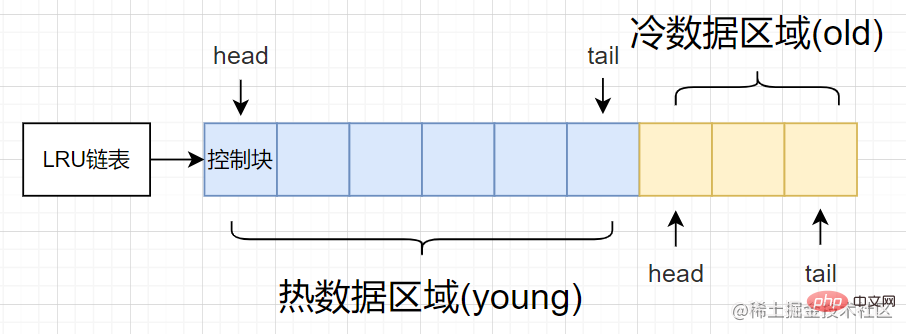
ページがその後アクセスされない場合、そのページはコールド データ領域から徐々に削除されますが、通常、ホット データ領域内の頻繁にアクセスされるバッファ ページには影響しません。
- 改良された LRU は、バッファ プール汚染の問題をどのように解決できるでしょうか?
- 結論を先に話します。この問題は十分に最適化されていません。理由は次のとおりです [テーブル全体のスキャンを例に挙げます]:
A初めてアクセスしたページもコールドデータ領域の先頭に配置されますが、その後のアクセスではホットデータ領域の先頭に配置され、アクセス頻度の高いページも排除されます。
では、バッファプール汚染の問題を解決するにはどうすればよいでしょうか?
- バッファ プールでは、コールド データ領域の時間ウィンドウ メカニズムが導入されています。つまり、ページへのその後のアクセスとページへの最初のアクセスの間の時間間隔が、指定されたウィンドウ値より大きい場合にのみ、コールドデータ領域からページが削除され、ホットデータ領域の先頭に移動します。ウィンドウ値が指定値より小さい場合、移動操作は実行されません。
innodb_old_blocks_time
パラメーター [単位 ms] で設定できます。デフォルトは 1000 ミリ秒で、1 秒を指定すると、テーブル全体のスキャンなどのほとんどの操作が除外されます。たとえば、テーブル全体のスキャン中、ページへの複数のアクセス間の時間間隔は 1 秒を超えることはありません。- バッファ プール VS クエリ キャッシュ
-
バッファ プールとクエリ キャッシュは同じものですか? →Not
クエリ キャッシュとは、クエリ結果を事前にキャッシュし、次回実行することなく結果を直接取得できるようにすることです。 MySQL のクエリ キャッシュはクエリ プランをキャッシュするのではなく、クエリの対応する結果をキャッシュすることに注意してください。ヒット条件が厳しく、データテーブルが変更されるとクエリキャッシュが無効になるため、ヒット率が低くなります。
- [関連する推奨事項:
- mysql ビデオ チュートリアル ]
以上がMySQL のデータベース バッファ プール (バッファ プール) について理解します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7498
7498
 15
1377
52
77
11
19
52
15
1377
52
77
11
19
52

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
