

MySQL のデータ ストレージ構造の簡単な分析

この記事では、主に InnoDB のデータストレージ構造 の観点から、どのような状況で SQL クエリ効率が低下するのかを分析します。 インターネット上でこれについて不満を述べている記事をよく見かけますが、データ量が多いとクエリ効率が大幅に低下します。関連するテーブルが多い場合、クエリ効率が低下します。 1 つのテーブル内のデータ量は 100 万を超えてはなりません。

CREATE TABLE `hospital_info` ( `pk_id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `id` varchar(36) NOT NULL COMMENT '外键', `hospital_code` varchar(36) NOT NULL COMMENT '医院编码', `hospital_name` varchar(36) NOT NULL COMMENT '医院名称', `is_deleted` tinyint DEFAULT NULL COMMENT '是否删除 0否 1是', `gmt_created` datetime DEFAULT NULL COMMENT '创建时间', `gmt_modified` datetime DEFAULT NULL COMMENT 'gmt_modified', `gmt_deleted` datetime(3) DEFAULT '9999-12-31 23:59:59.000' COMMENT '删除时间', PRIMARY KEY (`pk_id`), KEY `hospital_code` (`hospital_code`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='医院信息';
InnoDB 行形式
1 行のデータから始めて、まず 1 行のデータの格納形式を理解しましょう。 。 現在、行形式はCompact、Redundant、Dynamic、Compressed の 4 つです。
通常、テーブルを作成するときに意図的に指定する必要はありません。バージョン 5.7 以降では、デフォルトで Dynamic が使用されます。
各行の形式は似ていますが、ここでは、データの各行がどのように記録されるかを簡単に理解するために、Compact を例として取り上げます。 ######################################################################
「追加情報」と「実際のデータ」の 2 つの部分に分かれています。 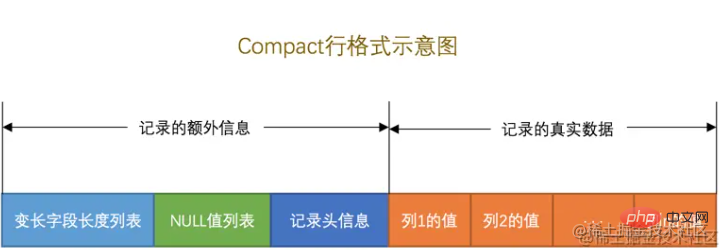
これはさらに興味深いもので、通常、フィールドを定義するときは、type と
を指定する必要があります。フィールドの長さ、例: サンプル テーブルの hospital_code フィールド定義
VARCHAR(36)。実際の使用では、hospital_code フィールドの長さは 32 ビットのみを使用します。 残りの4人のキャラクターはどうなりますか?無理に空文字を埋めてしまうと、4文字分のメモリが無駄になってしまいませんか。入力されていない場合、現在のフィールドに保存されている文字数を確認するにはどうすればよいですか?どれくらいのメモリを消費しますか? この時点で、可変長フィールドのリストはフィールド
ごとに逆順に並び、1 ~ 2 バイトを使用して各可変長フィールドの実際の長さを記録します。これにより、メモリ空間を有効に活用することができます。 同様のフィールド:VARBINARY、さまざまな TEXT
タイプ、さまざまなBLOB タイプ。 これに対応して、CHAR(10) のような「固定長フィールド」もあります。このタイプのフィールドは、初期化中にデフォルトで指定された文字長のスペースを占有します。十分ではない場合は、スペースの無駄なので空の文字を埋めてください。一般的には、必要に応じて長さを設定することをお勧めします。
もちろん、「可変長フィールドリスト」は必ず存在するわけではなく、定義されたフィールドタイプに「可変長フィールド」がなければ存在しません。拡張子:
TEXT または BLOB タイプのフィールドでは、長さが 1 ページに保存されない場合があります。この場合、ほとんどのデータは他のページに記録され、現在のページに保持されます。レコード (record). データのページのアドレス。NULL 値リスト
実際にデータを保存する際、一部の列にNULL 値が格納される場合があります。これらの値がすべて実際に記録されている場合、データの保存スペースが無駄になります。 Compact
形式では、これらの NULL 値を持つ列は均一に管理され、NULL 値リストに格納されます。データ行に NULL のフィールドがない場合、この列は生成されません。
保存方法もさらに興味深いもので、バイナリ モード逆順レコードです。
サンプル テーブルを使用して分析すると、テーブルにはis_deleted、gmt_created
、gmt_modified という 3 つのフィールドがありますが、これらは空の場合があります。レコード内の gmt_created と gmt_modified が両方とも空であると仮定すると、対応する NULL 値のリストは次のようになります。 ###############拡大する: Mysql はバイナリ データ ストレージをサポートしており、フルに使用すると、大量のストレージ スペースを削減できます。 レコード ヘッダー情報
レコード ヘッダー情報は、長さが 40 バイナリ ビットの固定 5 文字で構成されます。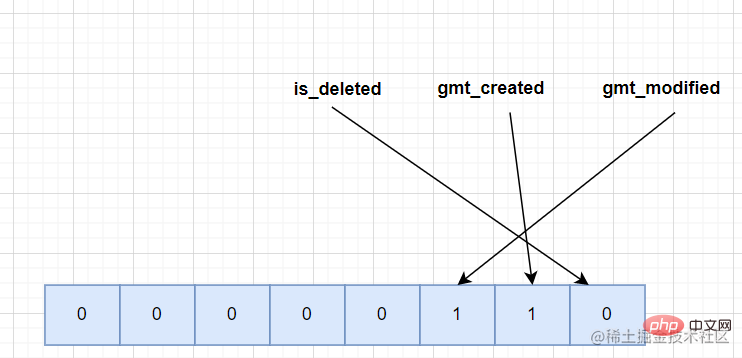
delete_mask Redis を使用したことのある人なら誰でも、Redis 内の削除されたデータは削除されないことを知っています。同じ mysql でも同じことが当てはまりますが、クリーニング プロセスでは IO 操作が発生し、効率に大きな影響を与えるため、削除されたデータはすぐには消去されません。 削除されたデータは リンク リスト
を形成し、再利用可能なスペースとして使用できます。実際のデータを記録する
これについては実際には何も言うことはありません。実際の非 NULL データを記録するだけです。 インターネットでよく見られる質問があります: 主キーが設定されていない場合はどうなりますか?
InnoDB では、主キーはレコードの一意の識別子です。ユーザーが指定しない場合、mysql は Unique (一意の) キー から 1 つを主キーとして選択します。 Unique キーがない場合、row_id という名前の非表示列が主キーとして追加されます。
さらに、transaction_id (トランザクション ID) と roll_pointer (ロールバック ポインター) の 2 つの列が追加されます。
概要
4 つの行フォーマットは非常に似ているため、1 つずつ紹介することはしません。「追加情報」と「追加情報」の 2 つの部分に分かれています。 「実際のデータ」。違いは主に、「追加情報」レコードの内容と可変長フィールドの格納にあります。
InnoDB データ ページ
データ ページの概念についてはよくご存じだと思います。 InnoDB がストレージ領域を管理するための基本単位であり、1 ページのサイズは通常 16KB です。表スペースのヘッダー情報を格納するページ、Insert Buffer 情報を格納するページ、INODE 情報を格納するページ、 undoログ情報ページなどを保存します。
ページは次のように分割されています: 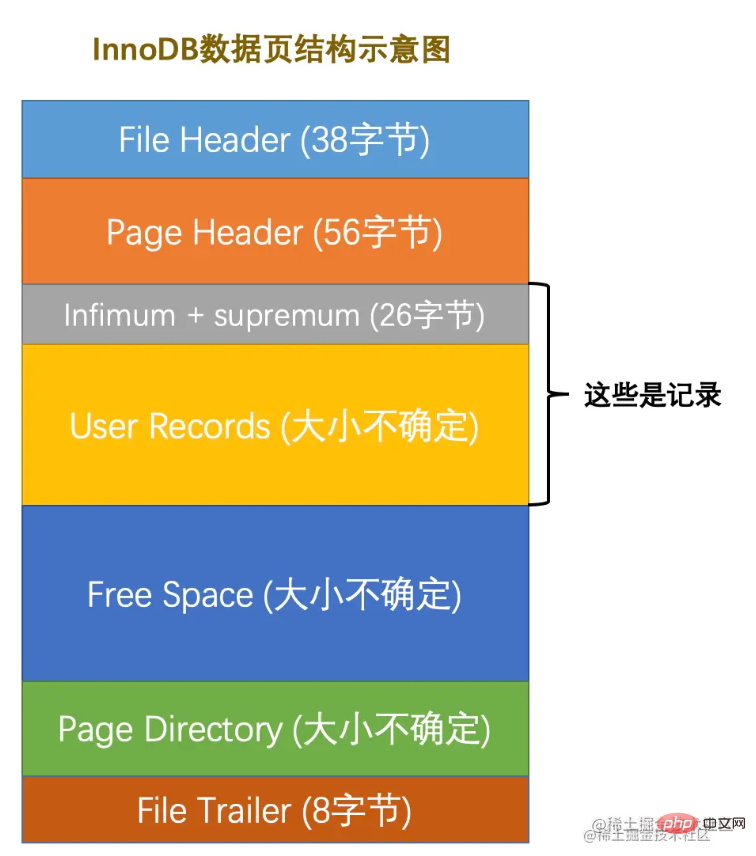
全部で 7 つのコンポーネントがありますが、7 つの部分について大まかに説明します。
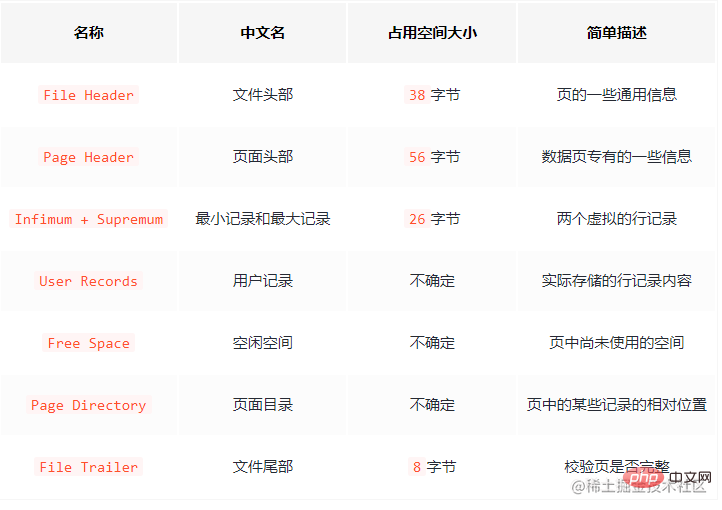
ファイル ヘッダーと ページ ヘッダーには多くの属性がありますが、ここでは 1 つずつ紹介しません。これら 2 つを知っていれば、ページ番号、前後のページのページ番号、ページ タイプ、ページ メモリ使用量など、page のいくつかの属性をローカルに記録します。ここでお話しさせていただきますが、各ページは ダブルリンクリスト によって接続されています。データ レコードは single-chained list です。
File Trailer は、ページ データの整合性を検証するために使用されます。ページ データがメモリからディスクに書き換えられるとき、データ ページの損傷を防ぐために検証する必要があります。
実際のデータ レコードが保存されている ユーザー レコード (使用済みスペース) と 空きスペース (残りのスペース) に注目してください。
さらに、Infimum と Supremum はそれぞれ最小レコードと最大レコードを識別します。つまり、ページが生成されると、デフォルトでこれら 2 つのレコードが含まれますが、これら 2 つのレコードはデータ リンク リストの先頭と末尾としてのみ使用され、実際のデータには影響しません。
要約すると、ページ内のレコードの保存は次のとおりです。
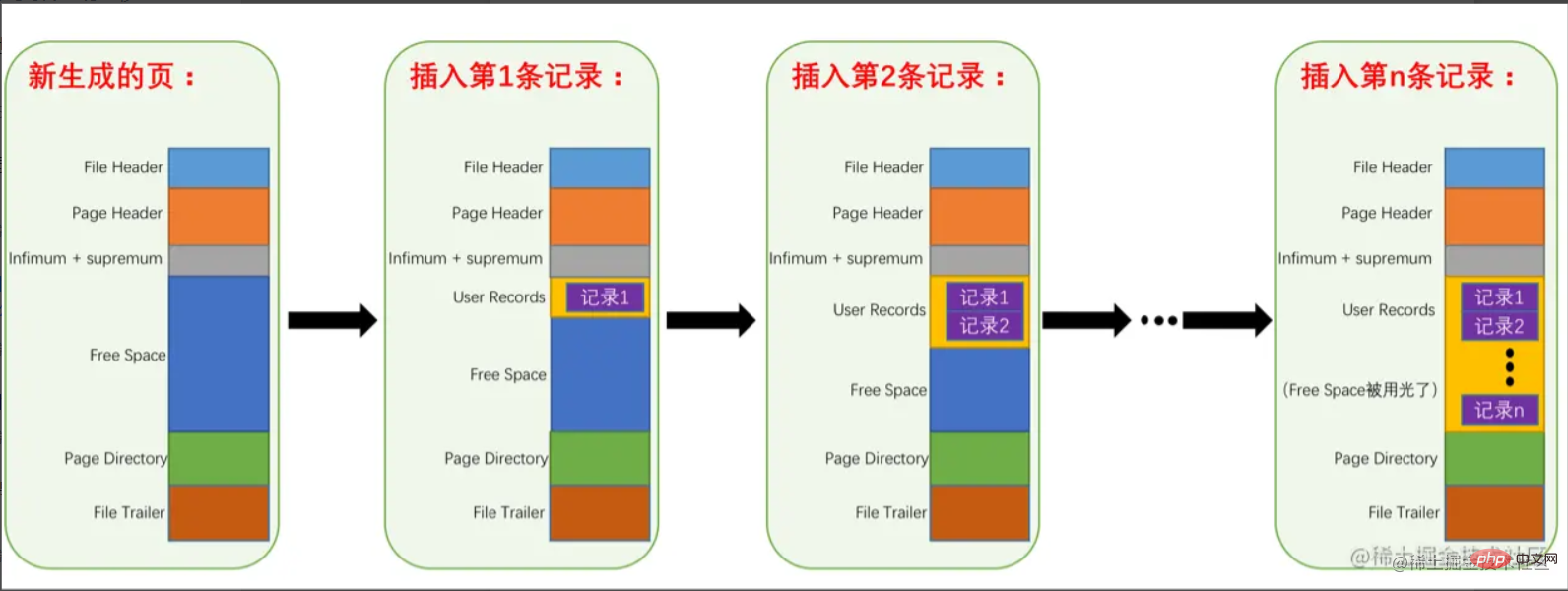 簡単に言えば、空き領域からユーザー レコードへの 変換です。空き領域が消費されるとき 空き領域がなくなると、データ ページはいっぱいであるとみなされます。
簡単に言えば、空き領域からユーザー レコードへの 変換です。空き領域が消費されるとき 空き領域がなくなると、データ ページはいっぱいであるとみなされます。
この時点で、データはデータ ページに書き込まれています。どうやって取り出すのでしょうか?データ レコードが単一リンク リストで構成されていることが上記でわかりましたが、Infimum (最小) レコードから開始してリンク リストをたどる必要があるでしょうか?
明らかに、MySQL の開発責任者がそれほど愚かであるはずはありません。そうでなければ、私はそれを行うことができます (笑)。
ここでは、ページ ディレクトリ (ページ ディレクトリ)について説明します。ページ内では、データがグループ化され、各グループの最後のレコードの アドレス オフセット が個別に抽出され、ページの終わり近くの「ページ ディレクトリ」に順番に保存されます。ページ ディレクトリは、シフト量を "slot" と呼びます。また、最後のレコード ヘッダー (n_owned) には、グループ内のレコードの数も格納されます。
ページ ディレクトリはスロットで構成されます。
全体的な構造図は次のとおりです。 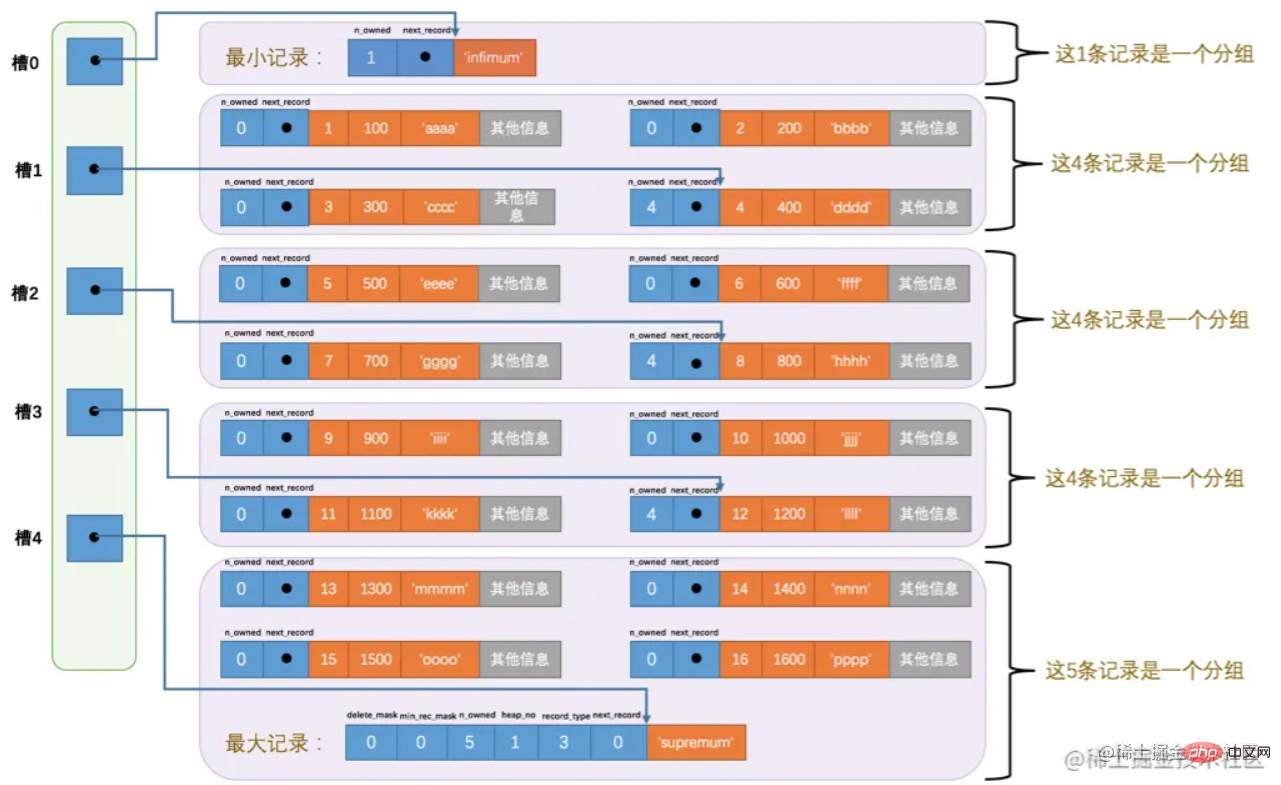
ディレクトリを取得した後のクエリは比較的単純です。 二分法を使用して簡単に検索できます。上の図では、最小スロットが 0 で、最大スロットが 4 であることがわかります。 例:
主キー レコードが 6 であるデータをクエリするとします。
1) 中央のスロットの位置を計算します。これは (0 4)/2 = 2 です。抽出されたスロットに対応するレコードの主キーは、8 > 6 であるため、8 です。
2) 同様に、最大のスロットを 2、つまり (0 2)/2 =1 に設定します。4
以降の説明を容易にするために、ページのデータ形式は次の図に示すように簡略化されています。 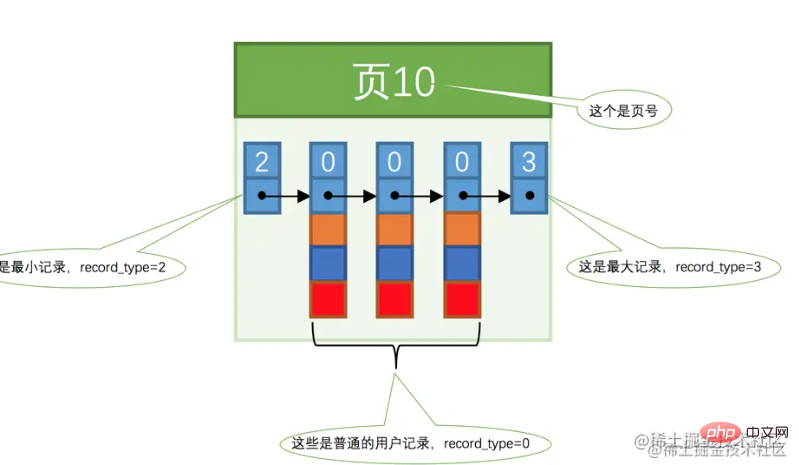
B ツリー インデックス
前に述べたように、質問について考えてみるとよいでしょう。データ ページは、おおよそ次の図に示すように、二重リンク リストを使用してリンクされています。 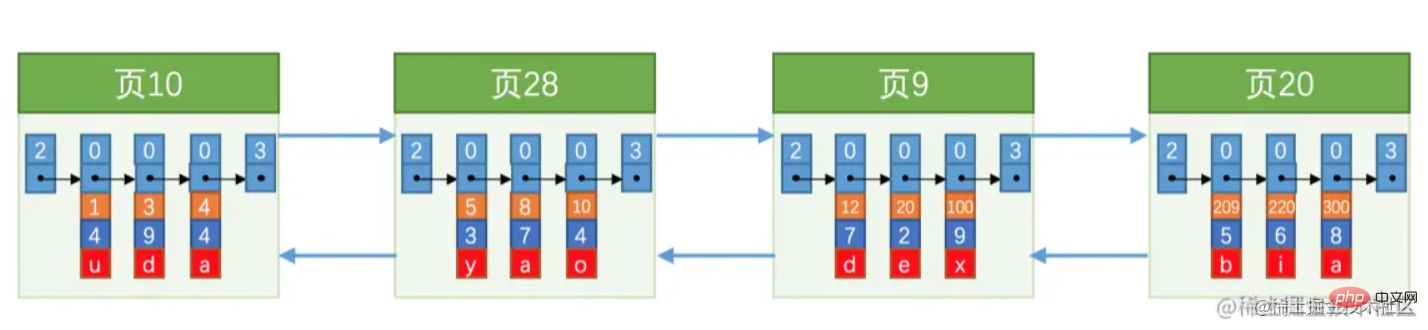 上の図からわかるように、 ページ番号は連続した ではなく、 も連続していません。必然的に連続した記憶空間 (この文は後で説明することを思い出してください) 。
上の図からわかるように、 ページ番号は連続した ではなく、 も連続していません。必然的に連続した記憶空間 (この文は後で説明することを思い出してください) 。
各ページに 3 つのレコードを保存できると仮定し、保存する必要があるレコードが 100,000 件あるとすると、30,000 以上のデータ ページが必要になります。このとき、ページ上のデータが多すぎるのと同じクエリの問題に直面します。単一ページなので、1 つずつ確認することはできません。このとき、すぐにクエリできるディレクトリも必要ですが、このディレクトリは「index」です。
上図に示すデータ ページに基づいて、次のインデックス構造を形成できます。 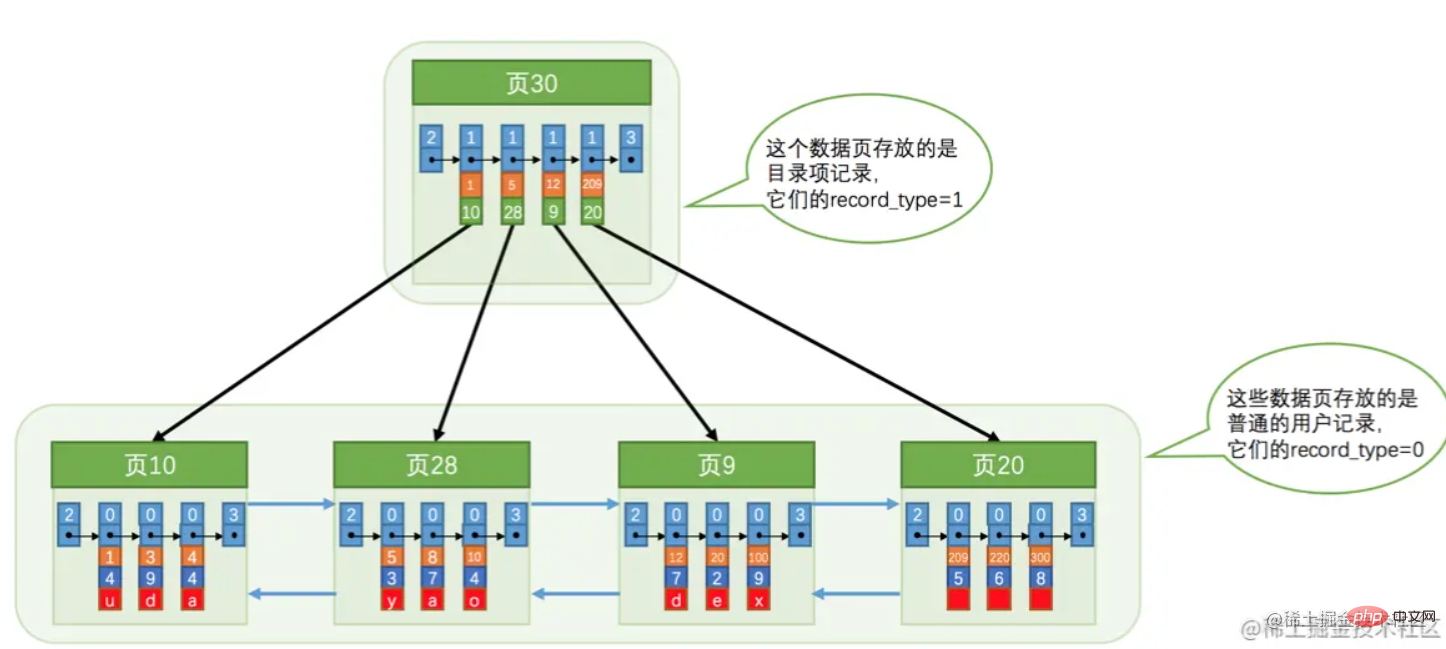 これは、クラスター化インデックスと呼ばれるもので、リーフがデータです。 。ここで注意すべき点は、「Page 30」には主キーとそれが配置されているページ番号が格納されるということです。
単一のインデックス ページがいっぱいの場合、分割されます。以下に示すように、ツリー構造を作成します。
これは、クラスター化インデックスと呼ばれるもので、リーフがデータです。 。ここで注意すべき点は、「Page 30」には主キーとそれが配置されているページ番号が格納されるということです。
単一のインデックス ページがいっぱいの場合、分割されます。以下に示すように、ツリー構造を作成します。 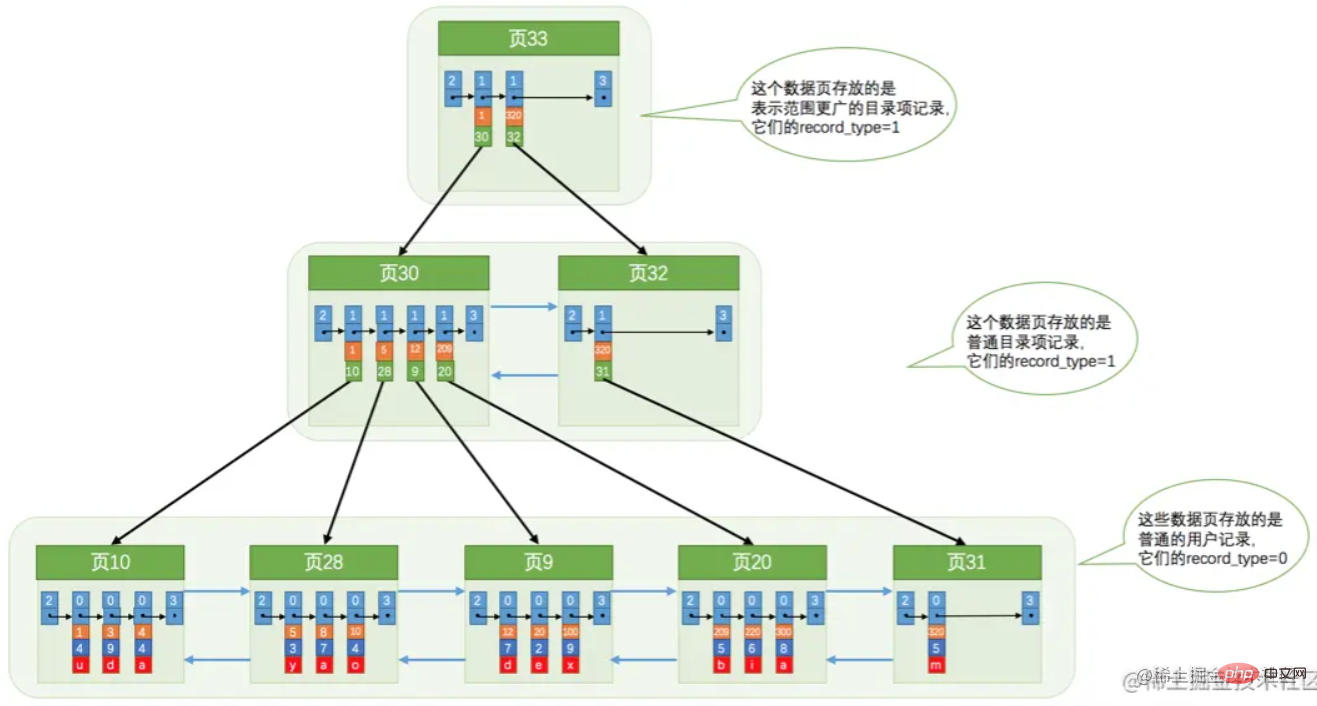 ただし、識別の便宜上、上の図は完全に正確ではありません。最初にルート ノードを生成する必要があり、ルート ノードがいっぱいになると分割されます。ルートノードは分割後のインデックスページ情報を記録します。
ただし、識別の便宜上、上の図は完全に正確ではありません。最初にルート ノードを生成する必要があり、ルート ノードがいっぱいになると分割されます。ルートノードは分割後のインデックスページ情報を記録します。
簡単に言うと、木の成長と同じで、根から幹、枝、葉へと成長していきます。
セカンダリ インデックス考え方はクラスター化インデックスと同じですが、セカンダリ インデックスのリーフ ノードが実際のデータではなく、データの主キーである点が異なります。実際のデータを取得するには、 table return 操作が必要です。
テーブル スペース
これまでに、単一データのストレージ構造と最小のストレージ データ単位ページがわかりました。データページは二重リンクリストによって接続されており、データページは必ずしも連続しているわけではありません。
このとき、同じテーブル内のレコードのページのメモリ アドレスが離れすぎている場合はどうなるでしょうか? 3 人を見つけるために、それぞれ北京、ニューヨーク、ロンドンに行くと想像してください。それらを一つ一つ探さなければならず、旅の途中で多くの時間を無駄にしてしまいます。国や都市に集めればもっと早くなります。
そこで、区という概念が生まれました。領域は 64 の連続した ページ で構成されており、デフォルトでは 1 つの領域が 1M のメモリを占有します。メモリを適用する場合、一度に 1M のスペースが占有され、データ ページが隣接するため、ランダム IO の問題はある程度解決されます。
クエリ効率をより効果的に向上させるために、B-tree の葉ノードと非葉ノードを領域単位で記録し、これらの領域の集合を「##」と呼びます。 # セグメント (セグメント) )"。 この概念では、最初のレコードを挿入するには、2 つのエリア スペース、クラスタード インデックスのルート ノード、およびデータ ページを申請する必要があります。今回は 2M のスペースを申請する必要があります。 何もしていないのに2Mのスペースがなくなってしまったのですが、これは妥当でしょうか?明らかに、これは不合理です。
そこで私たちは「断片化領域」というコンセプトを思いつきました。断片化された領域は表スペースに直接属し、どのセグメントにも属しません。メモリ割り当てのプロセスは次のように変わります。
1) データが最初に挿入されると、記憶領域がフラグメント領域から単一ページとして割り当てられます。 2) セグメントが 32 フラグメント領域ページを占有している場合、スペースは完全領域として割り当てられます。 テーブル スペースは、ゾーンのXDES Entry データ構造に加えて、システム テーブル スペースと 独立テーブル スペースにも分割されます。内容が多すぎて複雑なので、詳しく知りたい場合は原書を読んでください。
考え方
1) インデックスは多いほど良いのでしょうか?もっと増えるとどんな影響が出るのでしょうか?
多ければ多いほど良い 上記からわかるように、インデックス レコードにもメモリの消費が必要です。各インデックスは B ツリーに対応し、各ツリーはリーフ ノードと非リーフ ノードをそれぞれ記録するために 2 つのセグメントを必要とします。これにより、大量のメモリが浪費されます。 これは容認できないことではありませんが、結局のところ、インデックス自体の意味は、空間と時間を交換することです。ただし、データの追加、削除、変更によってインデックスが変更されるため、インデックスでノードを再割り当てし、ページ メモリをリサイクルして割り当てる必要があることを知っておく必要があります。これらはすべて IO 操作であるため、インデックスが多すぎると必然的にパフォーマンスの低下につながります。 したがって、結合インデックスを合理的に使用すると、単一インデックスが多すぎる問題を解決できます。さらに、インデックスには長さ制限があり、長すぎるフィールドはインデックス作成には適していません。2) インデックスのクエリ効率が非常に高いのはなぜですか?
これは実際にはアルゴリズムの問題です。クラスター化インデックスを例に挙げます。非リーフ ノードのインデックス ページにはそれぞれ 1,000 個のデータを記録でき、各リーフ ノードには 500 個のデータを記録できると仮定します。 A 3 レイヤーの B ツリー (ルート ノードを除く) には 10001000500 レコードを保存できます。 3 層構造のインデックスは非常に多くのレコードを格納でき、毎回のデータ検索に必要なクエリ数はわずかなので、当然効率が高くなります。
実際には、1 つのインデックス ページに記録できるデータはこれよりもはるかに大きくなります。 同様に、ここで問題が考えられます。リーフ ノード内の 1 つのデータが非常に大きく、データ ページに 3 レコードしか保存できない場合、B ツリーの深さはテーブル内の 1 つのレコードのサイズも最適化されます。3) データ量が多い場合、SQL の実行は遅くなりますか?
実は、この問題について本当に文句を言いたいのですが、数百万のデータのクエリ効率は xx 秒で、遅すぎます。 mysql のパフォーマンスが一部のデータベースよりも確かに低いことは否定できませんが、数百万のデータを処理すると速度が低下するため、SQL とテーブル構造の設計が合理的であるかどうかを検討してください。数百万レベルは言うまでもなく、数千万レベルでもミリ秒レベルのクエリを実現できます。 量について話すだけではナンセンスです。テーブルに数百のフィールドがある場合や、非常に長い文字を含むフィールドがある場合は、ロックによって占有されているメモリ サイズを実際に確認する必要があります。そうなると神も救えない。
概要
この記事では主に MySql のデータ構造の概念を紹介しており、内容のほとんどは書籍「Mysql をルートから理解する」から引用しています。いくつかの概念を理解するための基礎として役立つように、多くの簡略化が行われています。
間違いや漏れがある場合は、修正していただきありがとうございます。
[関連する推奨事項: mysql ビデオ チュートリアル ]
以上がMySQL のデータ ストレージ構造の簡単な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7564
7564
 15
1386
52
86
11
28
99
15
1386
52
86
11
28
99

 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 SQLデータベースの構築方法
Apr 09, 2025 pm 04:24 PM
SQLデータベースの構築方法
Apr 09, 2025 pm 04:24 PM
SQLデータベースの構築には、DBMSの選択が必要です。 DBMSのインストール。データベースの作成。テーブルの作成;データの挿入;データの取得。データの更新。データの削除。ユーザーの管理。データベースのバックアップ。
