

Golangを使ってBingの壁紙をクロールする方法を詳しく解説


言うまでもなく、Python を使用してクローラーを作成するだけで、1 つの リクエスト で世界をカバーできます。ただし、golang に組み込まれている http パッケージは非常に強力だと聞いたので、何もする必要はありませんが、新しいことを学び、リクエストに関連する知識ポイントを確認したいだけです。 httpプロトコルの応答。言うことはあまりありません。まずは記事全体から始めましょう。
クローラ プロセスの概要graph TD
请求数据 --> 解析数据 --> 数据入库
ログイン後にコピー
上記のフローチャートからわかるように、クローラは次のようになります。手順はたったの3ステップだけです。次に、各ステップで何を行う必要があるかについて説明します。
graph TD 请求数据 --> 解析数据 --> 数据入库
- データのリクエスト: ここでは、golang の組み込みパッケージ http パッケージを使用して、ターゲット アドレスへのリクエストを開始する必要があります。このステップは完了です
- データの解析: ここでは、要求されたデータ全体が必要ではなく、特定のキー データのみが必要であるため、要求されたデータを解析する必要があります。このステップはデータ クリーニングとも呼ばれます #データ ストレージ: これは解析されたデータをデータベースに保存することであることを理解するのは難しくありません
- ##実践的な分析
まず、Bing 壁紙の公式 Web サイトにアクセスして観察してください。クローラーを実行する場合は、特にデータに注意する必要があります。これはホームページ情報です。ページ全体は非常に簡潔です。
次に、ブラウザの開発者ツールを呼び出す必要があります (これについてはよく知っているはずです。詳しくない場合は、従うのは難しいでしょう。)。  F12
F12
を確認してください。 Bing の壁紙では、右クリックしてもコンソールを呼び出すことができず、手動でのみ呼び出すことができます。心配しないで、最初の写真に従ってください。クラスメートの Chrome が中国語の場合も、同じ操作が行われます。さらにツールを選択し、開発者ツールを選択します。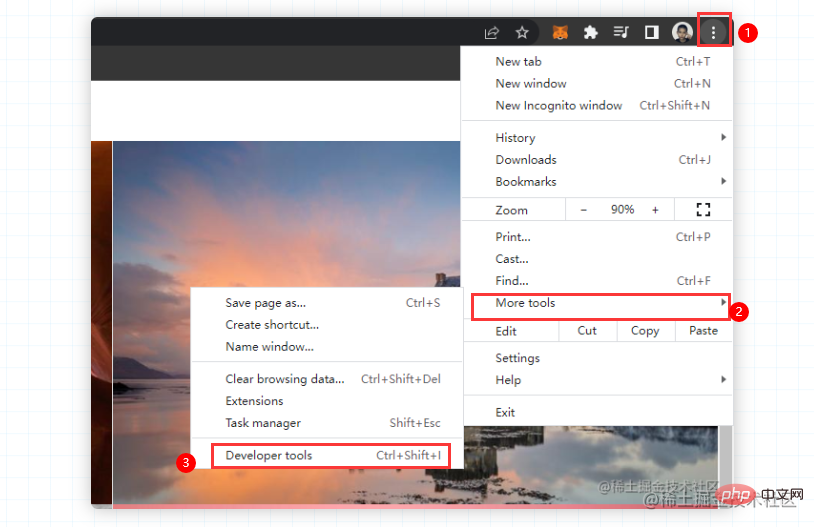 当然のことながら、誰もがこのようなページを目にするはずです
当然のことながら、誰もがこのようなページを目にするはずです
そんなことはありません問題は、Bing 壁紙 Web サイトのクロール対策エラーにすぎません。 (ずっと前にクロールしたときは、このクロール防止エラーは発生しませんでした) これは操作には影響しません
次に、必要な要素をすばやく見つけるのに役立つこのツールを選択します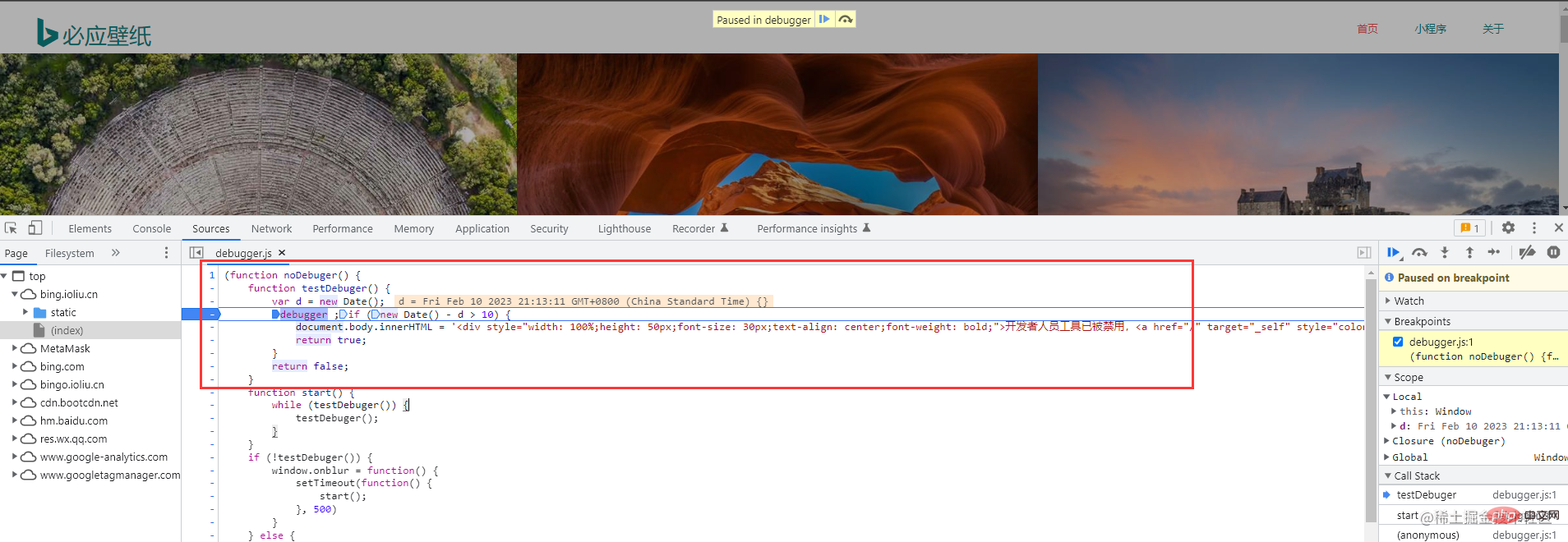 次に、必要な画像情報を見つけることができます
次に、必要な画像情報を見つけることができます
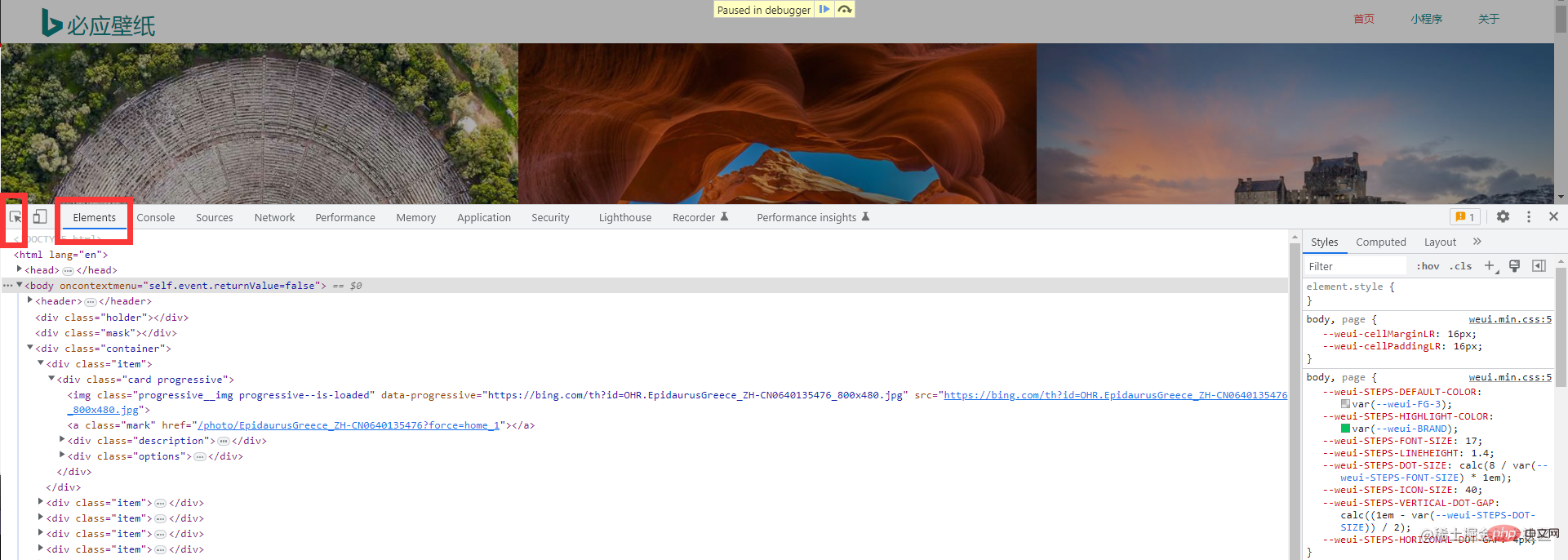
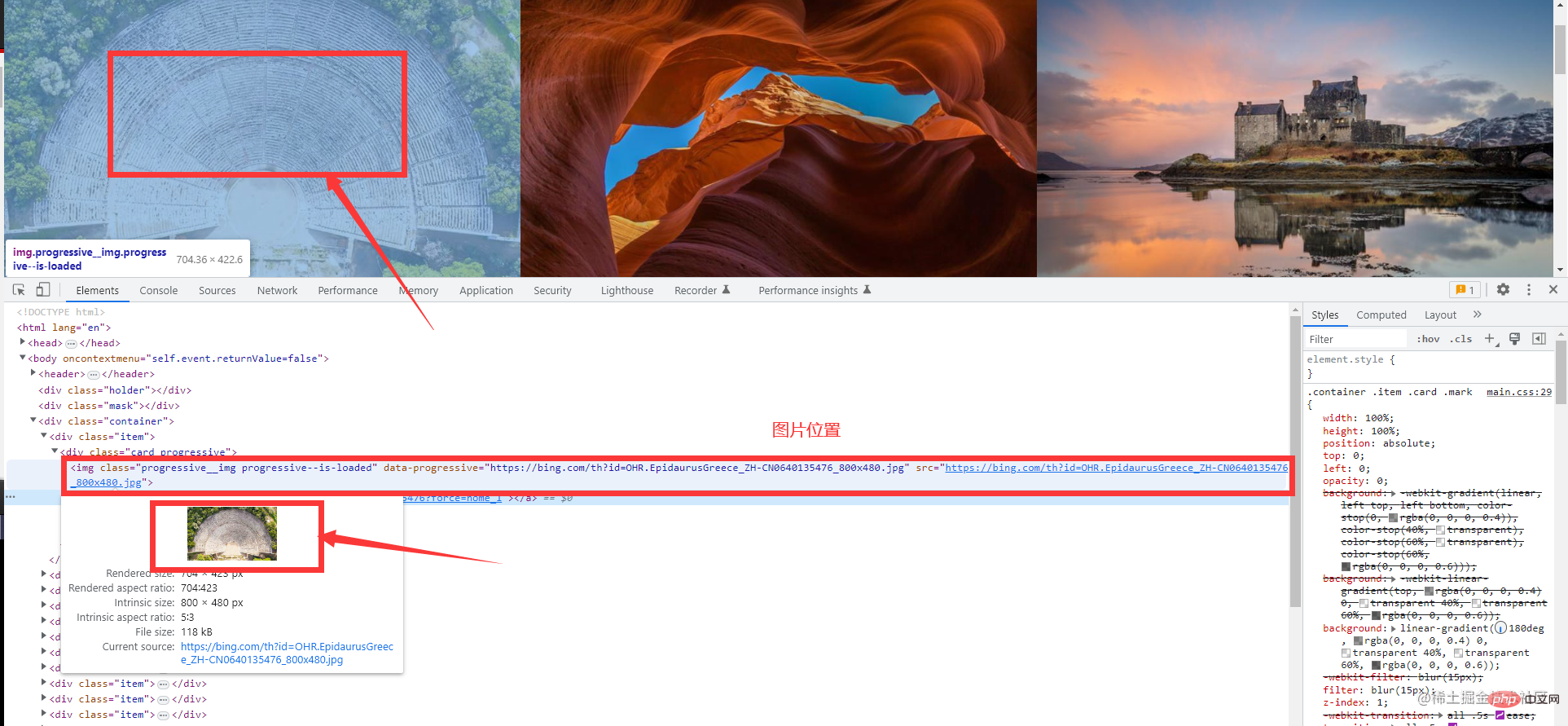 実際の戦闘コード
実際の戦闘コード
1ページをクロールするためのデータは次のとおりです
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"io"
"io/ioutil"
"log"
"net/http"
"os"
"time"
)
func Run(method, url string, body io.Reader, client *http.Client) {
req, err := http.NewRequest(method, url, body)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
if resp.StatusCode != http.StatusOK {
log.Printf("请求失败,状态码:%d", resp.StatusCode)
return
}
defer resp.Body.Close() // 关闭响应对象中的body
query, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Println("生成goQuery对象失败")
return
}
query.Find(".container .item").Each(func(i int, s *goquery.Selection) {
imgUrl, _ := s.Find("a.ctrl.download").Attr("href")
imgName := s.Find(".description>h3").Text()
fmt.Println(imgUrl)
fmt.Println(imgName)
DownloadImage(imgUrl, i, client)
time.Sleep(time.Second)
fmt.Println("-------------------------")
})
}
func DownloadImage(url string, index int, client *http.Client) {
req, err := http.NewRequest("POST", url, nil)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Println("读取请求体失败")
return
}
baseDir := "./image/image-%d.jpg"
f, err := os.OpenFile(fmt.Sprintf(baseDir, index), os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
log.Println("打开文件失败", err.Error())
return
}
defer f.Close()
_, err = f.Write(data)
if err != nil {
log.Println("写入数据失败")
return
}
fmt.Println("下载图片成功")
}
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
Run(method, url, nil, client)
}発見何が起こったのか?最初のページ p=1、2 番目のページ p=2、10 番目のページ p=10
したがって、for ループを開始し、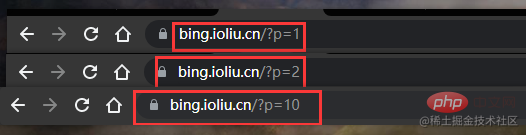
// 爬取多页的main函数如下
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
for i := 1; i < 5; i++ { // 实现分页操作
Run(method, fmt.Sprintf(url, i), nil, client)
}
}この例では、正規表現を使用するのは非常に面倒なので、サードパーティのツール パッケージを使用して Web ページ データを解析します #CSS セレクターを使用します:
goQuery以上がGolangを使ってBingの壁紙をクロールする方法を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7338
7338
 9
1627
14
1352
46
1265
25
1210
29
9
1627
14
1352
46
1265
25
1210
29

 Golang を使用してファイルを安全に読み書きするにはどうすればよいですか?
Jun 06, 2024 pm 05:14 PM
Golang を使用してファイルを安全に読み書きするにはどうすればよいですか?
Jun 06, 2024 pm 05:14 PM
Go ではファイルを安全に読み書きすることが重要です。ガイドラインには以下が含まれます。 ファイル権限の確認 遅延を使用してファイルを閉じる ファイル パスの検証 コンテキスト タイムアウトの使用 これらのガイドラインに従うことで、データのセキュリティとアプリケーションの堅牢性が確保されます。
 Golang データベース接続用の接続プールを構成するにはどうすればよいですか?
Jun 06, 2024 am 11:21 AM
Golang データベース接続用の接続プールを構成するにはどうすればよいですか?
Jun 06, 2024 am 11:21 AM
Go データベース接続の接続プーリングを構成するにはどうすればよいですか?データベース接続を作成するには、database/sql パッケージの DB タイプを使用します。同時接続の最大数を制御するには、MaxOpenConns を設定します。アイドル状態の接続の最大数を設定するには、ConnMaxLifetime を設定します。
 golangフレームワークの長所と短所の比較
Jun 05, 2024 pm 09:32 PM
golangフレームワークの長所と短所の比較
Jun 05, 2024 pm 09:32 PM
Go フレームワークは、その高いパフォーマンスと同時実行性の利点で際立っていますが、比較的新しい、開発者エコシステムが小さい、一部の機能が欠けているなどの欠点もあります。さらに、急速な変化と学習曲線はフレームワークごとに異なる場合があります。 Gin フレームワークは、効率的なルーティング、組み込みの JSON サポート、強力なエラー処理機能により、RESTful API を構築するための一般的な選択肢です。
 Golang フレームワークでのエラー処理のベスト プラクティスは何ですか?
Jun 05, 2024 pm 10:39 PM
Golang フレームワークでのエラー処理のベスト プラクティスは何ですか?
Jun 05, 2024 pm 10:39 PM
ベスト プラクティス: 明確に定義されたエラー タイプ (エラー パッケージ) を使用してカスタム エラーを作成する 詳細を提供する エラーを適切にログに記録する エラーを正しく伝播し、非表示または抑制しないようにする コンテキストを追加するために必要に応じてエラーをラップする
 Golang 単体テストのアサーションに gomega を使用するにはどうすればよいですか?
Jun 05, 2024 pm 10:48 PM
Golang 単体テストのアサーションに gomega を使用するにはどうすればよいですか?
Jun 05, 2024 pm 10:48 PM
Golang 単体テストでアサーションに Gomega を使用する方法 Golang 単体テストでは、Gomega は、開発者がテスト結果を簡単に検証できるように、豊富なアサーション メソッドを提供する人気のある強力なアサーション ライブラリです。 Gomegagoget-agithub.com/onsi/gomega をインストールする アサーションに Gomega を使用する アサーションに Gomega を使用する一般的な例をいくつか示します。 1. 等価アサーション import "github.com/onsi/gomega" funcTest_MyFunction(t*testing.T){
 golang フレームワーク開発の実践的な詳細な説明: 質疑応答
Jun 06, 2024 am 10:57 AM
golang フレームワーク開発の実践的な詳細な説明: 質疑応答
Jun 06, 2024 am 10:57 AM
Go フレームワーク開発における一般的な課題とその解決策は次のとおりです。 エラー処理: 管理にはエラー パッケージを使用し、エラーを一元的に処理するにはミドルウェアを使用します。認証と認可: サードパーティのライブラリを統合し、資格情報を確認するためのカスタム ミドルウェアを作成します。同時処理: ゴルーチン、ミューテックス、チャネルを使用してリソース アクセスを制御します。単体テスト: 分離のために getest パッケージ、モック、スタブを使用し、十分性を確保するためにコード カバレッジ ツールを使用します。デプロイメントとモニタリング: Docker コンテナを使用してデプロイメントをパッケージ化し、データのバックアップをセットアップし、ログ記録およびモニタリング ツールでパフォーマンスとエラーを追跡します。
 Golang フレームワークと Go フレームワーク: 内部アーキテクチャと外部機能の比較
Jun 06, 2024 pm 12:37 PM
Golang フレームワークと Go フレームワーク: 内部アーキテクチャと外部機能の比較
Jun 06, 2024 pm 12:37 PM
GoLang フレームワークと Go フレームワークの違いは、内部アーキテクチャと外部機能に反映されています。 GoLang フレームワークは Go 標準ライブラリに基づいてその機能を拡張していますが、Go フレームワークは特定の目的を達成するための独立したライブラリで構成されています。 GoLang フレームワークはより柔軟であり、Go フレームワークは使いやすいです。 GoLang フレームワークはパフォーマンスの点でわずかに優れており、Go フレームワークはよりスケーラブルです。ケース: gin-gonic (Go フレームワーク) は REST API の構築に使用され、Echo (GoLang フレームワーク) は Web アプリケーションの構築に使用されます。
 GolangでJSONデータをデータベースに保存するにはどうすればよいですか?
Jun 06, 2024 am 11:24 AM
GolangでJSONデータをデータベースに保存するにはどうすればよいですか?
Jun 06, 2024 am 11:24 AM
JSON データは、gjson ライブラリまたは json.Unmarshal 関数を使用して MySQL データベースに保存できます。 gjson ライブラリは、JSON フィールドを解析するための便利なメソッドを提供します。json.Unmarshal 関数には、JSON データをアンマーシャリングするためのターゲット型ポインターが必要です。どちらの方法でも、SQL ステートメントを準備し、データをデータベースに永続化するために挿入操作を実行する必要があります。
