

diff アルゴリズムは、ツリー ノードを同じレベルで比較する効率的なアルゴリズムであり、ツリーをレイヤーごとに検索して横断する必要がなくなります。では、diff アルゴリズムについてどれくらい知っていますか?次の記事では、vue2 の差分アルゴリズムについて詳しく説明していますので、お役に立てれば幸いです。

以前、ライブインタビューを見ていてDiffアルゴリズムについてよく質問したのと、著者自身もVue2をよく使っているので、Vue2のDiffアルゴリズムについて勉強するつもりです。実はずっと勉強したいと思っていて、Diffアルゴリズムは割と奥が深い気がして後回しにしていたのですが、最近面接の準備をしていたので、勉強しておこうと思いました。遅かれ早かれ学習してください。この機会に Diff アルゴリズムを理解してみてはいかがでしょうか。著者は 1 日かけて学習しました。少し調べてみましたが、Diff アルゴリズムの本質を十分に理解していない可能性があります。ご容赦ください。
? これは実際には著者の研究メモとしてカウントされており、著者のレベルは限られています。改訂された記事は著者の個人的な意見を表すものにすぎません。間違いがある場合は、コメントで指摘してください。同時に、この記事は非常に長いので、辛抱強く読んでください。これを読んだ後、Diff アルゴリズムについてより深く理解できるようになると著者は信じています。この記事は、現在 Diff アルゴリズムを説明しているインターネット上のほとんどの記事よりも優れていると思います。なぜなら、この記事は、答えから直接始めるのではなく、問題から始めて、答えを読むのと同じように、問題から始めてすべての人に考え方を教えるからです。この記事では、Diff アルゴリズムの微妙さを誰もが感じられるように段階的に説明しますが、同時に、誰もが Diff アルゴリズムをより直感的に体験できるようにするための小さな実験も実施しました。
Vue2 の最下層は仮想 DOM を使用して表現するためです。ページの構造的な仮想 DOM は実際にはオブジェクトです。生成方法を知りたい場合の一般的なプロセスは次のとおりです:
.vue##) を解析します。 # file
(おそらく追加、削除、更新のいずれか) 必要なのは 1 回のクリックだけであり、最小限の更新です。 では、最小限の更新量を達成するにはどうすればよいでしょうか?次に、Diff アルゴリズムを使用する必要がありますが、Diff アルゴリズムは正確に何を比較するのでしょうか?おそらくこれが、Diff アルゴリズムを初めて学習するときに誤解しやすいところです。実際には、古い仮想 DOM と新しい仮想 DOM を比較します。 つまり、Diff アルゴリズムは、違いを見つけ、次の違いを見つけることです。 2つの仮想DOMを分割し、その差分をページ上に反映させることで最小の更新量を実現し、変更箇所のみを更新すればパフォーマンスは確実に向上します。
の get を入力すると、依存関係がここで収集されます。では、依存関係を収集するのは誰でしょうか?それは各コンポーネントです。各コンポーネントはウォッチャーであり、このコンポーネント内のすべての変数 (つまり、依存関係) を記録します。もちろん、各依存関係 (Dep) も収集しますコンポーネントのウォッチャー;
の set がトリガーされます。この関数では、データは全員に通知されます ウォッチャーがページを更新すると、各ページが更新メソッドを呼び出します このメソッドは patch;
実際には、更新しながら更新します。誰でも理解しやすいように、これら 2 つのパートは分離されています
インタビューで Diff アルゴリズムとは何かと尋ねられると、誰もが間違いなく、头头のようないくつかの単語を言うでしょう。 、tail tail、tail head、head Tail、深さ優先走査 (dfs)、同じ層の比較 これらの言葉に似ていますが、1 つまたは 2 つ言えます。文章、それは単なる味です。
実際、筆者も CSDN で公開されている Diff アルゴリズムに関する記事を読んだのですが、これは非常に読まれている記事ですが、よく理解できなかったと感じています。おそらく、自分自身が理解していなかったのか、理解していても説明していなかったのではないでしょうか。そうすれば、著者は自分の洞察をあなたと共有しましょう。
誰もが明確に理解できるように、関数呼び出しプロセスを次に示します:
Diff アルゴリズム前提条件 これは非常に重要です。前提とは何なのかと疑問に思われるかもしれません。先ほどの比較だけではないでしょうか?それは正しいですが、間違っています。なぜなら、Diff アルゴリズムは、前述の head、tail、tail、head、tail に達するからです。このステップの前提条件は、2 回比較されたノードは 同じ##です。 # 、ここでの類似性は誰もが考えているような完全に同じではありませんが、特定の条件を満たしていれば同じです。説明を簡単にするために、この記事では key と のみを含む 1 つのタグのみを考慮します。タグ名 (タグ) の場合、先ほど言った キーは同じでタグも同じ ということですが、作者の発言がある程度正しいことを証明するために、ソース コードは次のようになります。ここにも掲載されています:
// https://github.com/vuejs/vue/blob/main/src/core/vdom/patch.ts
// 36行
function sameVnode(a, b) {
return (
a.key === b.key &&
a.asyncFactory === b.asyncFactory &&
((a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)) ||
(isTrue(a.isAsyncPlaceholder) && isUndef(b.asyncFactory.error)))
)
}function patchVnode(......) {
if (oldVnode === vnode) {
return
}
......
} 関数は、新旧の仮想 DOM が key が同じでタグが同じであるかどうかを示します。 異なる場合は直接置き換えてください。同じ場合は ## を使用してください。 #patchVnode。一貫性がない場合は、元の DOM を削除して、新しい DOM に置き換えます。
patch.ts実際、現在導入されている patchVnode はソース コードに直接導入されていますが、なぜこのように分類されているのかわからないかもしれません。そのため、作成者はその理由を理解していただくためにここにいます。まず結論ですが、は
children 属性は同時に存在できません。これには、全員がテンプレートのソース コード部分を解析する必要があります と children## があるかどうかです。 # この場合、次の 9 つの状況が存在します。
| 古いノードの子 | 新しいノードのテキスト | 新しいノードの子 | |||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ❎ | ❎ | ❎ | 2 | ||||||||||||||||||||||||||||||
| ✅ | ❎ | ❎ | ##3 | ||||||||||||||||||||||||||||||
| ❎ | #❎##❎ | 4 | ❎ | ❎ | |||||||||||||||||||||||||||||
| ✅ | 5 | ❎ | ##✅ | ||||||||||||||||||||||||||||||
| ✅ | 6 | ✅ | ❎ | ||||||||||||||||||||||||||||||
| ✅ | 7 | ❎ | ❎ | ||||||||||||||||||||||||||||||
| 8 | ❎ | ✅ | ✅ | ||||||||||||||||||||||||||||||
| 9 | ✅ | ❎ | ✅ | ||||||||||||||||||||||||||||||
| # 按照上面的表格,因为如果新节点有文本节点,其实老节点不管是什么都会被替换掉,那么就可以按照 if (isUndef(vnode.text)) {
// 新虚拟 DOM 有子节点
} else if (oldVnode.text !== vnode.text) {
// 如果新虚拟 DOM 是文本节点,直接用 textContent 替换掉
nodeOps.setTextContent(elm, vnode.text)
}ログイン後にコピー 那么如果有子节点的话,那应该怎么分类呢?我们可以按照每种情况需要做什么来进行分类,比如说:
那么通过以上六种情况 (新虚拟 DOM 不含有 text,也就是不是文本节点的情况),我们可以很容易地进行归类:
其实源码也是这么来进行分类的,而且之前说的
然后我们来看看源码是怎么写吧,只看新虚拟 DOM 不含有 text,也就是不是文本节点的情况: if (isUndef(vnode.text)) {
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch)
// 递归处理,精细比较
// 对应分类 3️⃣
updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
if (__DEV__) {
checkDuplicateKeys(ch) // 可以忽略不看
}
// 对应分类 2️⃣
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 对应分类 1️⃣
removeVnodes(oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// 对应分类 1️⃣
nodeOps.setTextContent(elm, '')
}
}ログイン後にコピー ❓我们可以看到源码把分类 1️⃣ 拆开来了,这是因为如果老虚拟 DOM 有子节,那么可能绑定了一些函数,需要进行解绑等一系列操作,作者也没自信看,大致瞄了一眼,但是如果我们要求不高,如果只是想自己手动实现 Diff 算法,那么没有拆开的必要。 作者觉得这么讲可能比网上其他介绍 Diff 算法的要好,其他的可能直接给你说源码是怎么写的,可能没有说明白为啥这么写,但是通过之前这么分析讲解后可能你对为什么这么写会有更深的理解和帮助吧。 updateChildren 函数
因为当都含有子节点,即都包含 children 属性后,需要精细比较不同,不能像之前那些情况一样进行简单处理就可以了
那么这个函数中就会介绍大家经常说的 ? 在这之前我们要定义四个指针 循环条件如下: while(oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
......
}ログイン後にコピー 其实这个比较也就是按人类的习惯来进行比较的,比较顺序如下 :
根据循环条件我们可以得到两种剩余情况,如下:
其实我们上面还没有考虑如果节点为
那么我们来看源码怎么写的吧,其中用到的函数可以查看源码附录: // https://github.com/vuejs/vue/blob/main/src/core/vdom/patch.ts
// 439 行至 556 行
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
// 情况 8️⃣
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
// 情况 9️⃣
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
// 情况 1️⃣
patchVnode(...)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
// 情况 2️⃣
patchVnode(...)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// Vnode moved right
// 情况 3️⃣
patchVnode(...)
canMove &&
nodeOps.insertBefore(
parentElm,
oldStartVnode.elm,
nodeOps.nextSibling(oldEndVnode.elm)
)
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// Vnode moved left
// 情况 4️⃣
patchVnode(...)
canMove &&
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 情况 5️⃣
if (isUndef(oldKeyToIdx)) // 创建 key -> index 的 Map
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
// 找到 新头节点 的下标
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
// New element
// 如果没找到
createElm(...)
} else {
// 如果找到了
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(...)
oldCh[idxInOld] = undefined
canMove &&
nodeOps.insertBefore(
parentElm,
vnodeToMove.elm,
oldStartVnode.elm
)
} else {
// same key but different element. treat as new element
createElm(...)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx > oldEndIdx) {
// 情况 6️⃣
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(...)
} else if (newStartIdx > newEndIdx) {
// 情况 7️⃣
removeVnodes(...)
}ログイン後にコピー
v-for 中为什么要加 key这个问题面试很常见,但是可能大部分人也就只会背八股,没有完全理解,那么经过以上的介绍,我们可以得到自己的理解:
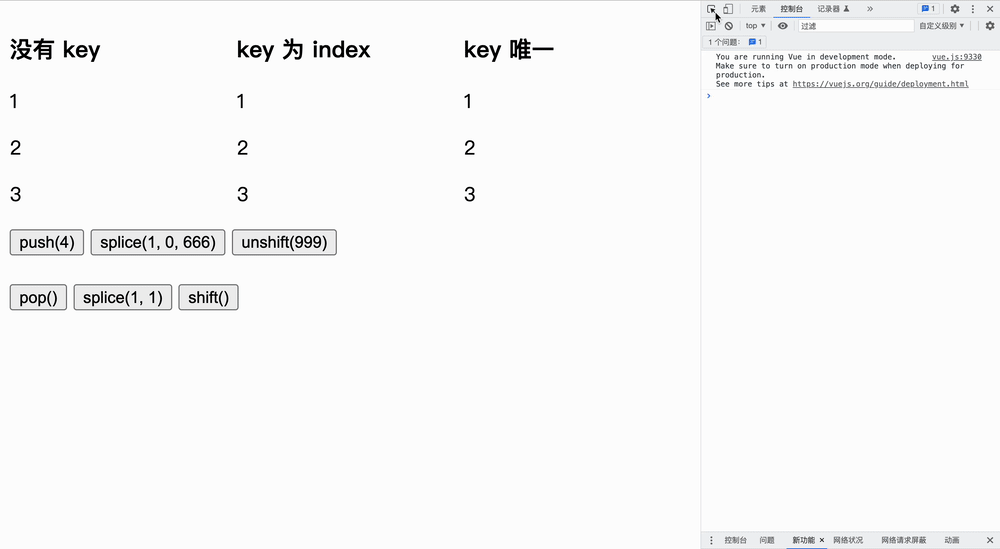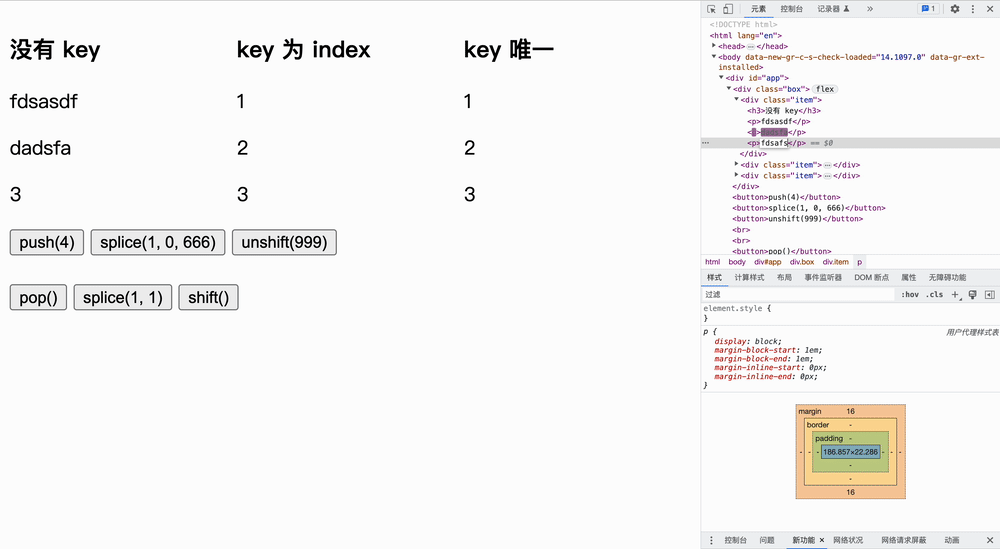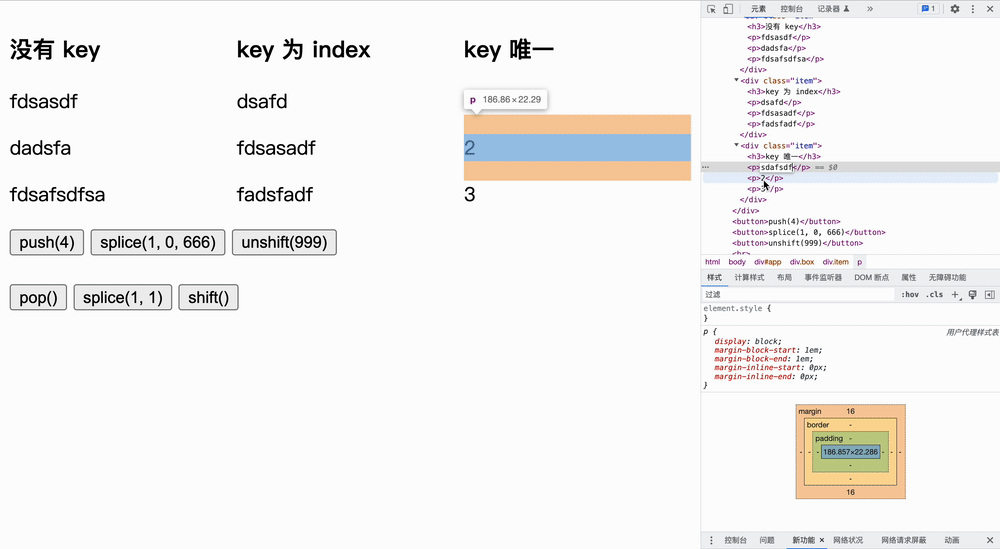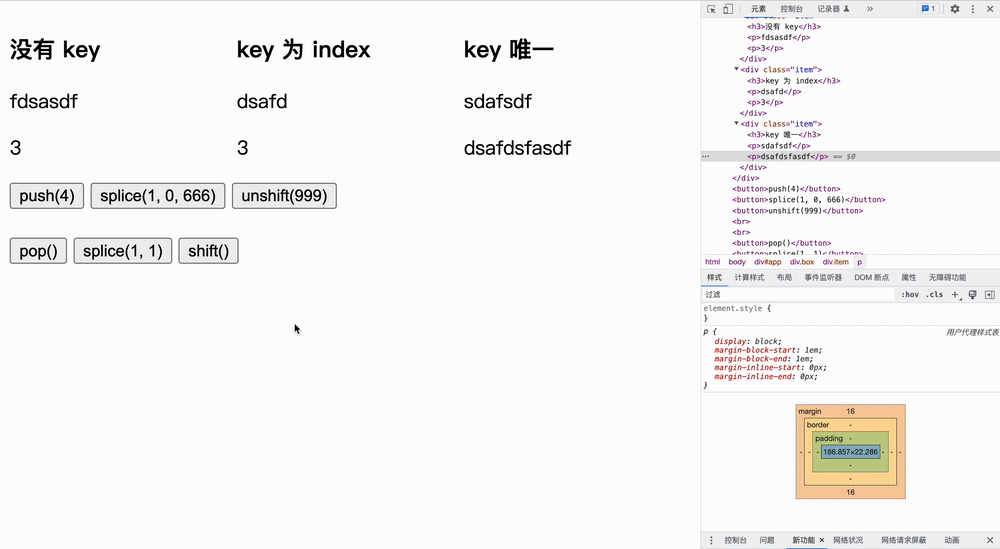
证明 key 的性能我们分为三个实验:没有 key、key 为 index、key 唯一,仅证明加了 key 可以进行最小化更新操作。 实验代码 有小伙伴评论说可以把代码贴上这样更好,那么作者就把代码附上 ?: <!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue@2/dist/vue.js"></script>
<style>
.box {
display: flex;
flex-direction: row;
}
.item {
flex: 1;
}
</style>
</head>
<body>
<div id="app">
<div>
<div>
<h3>没有 key</h3>
<p v-for="(item, index) in list">{{ item }}</p>
</div>
<div>
<h3>key 为 index</h3>
<p v-for="(item, index) in list" :key="index">{{ item }}</p>
</div>
<div>
<h3>key 唯一</h3>
<p v-for="(item, index) in list" :key="item">{{ item }}</p>
</div>
</div>
<button @click="click1">push(4)</button>
<button @click="click2">splice(1, 0, 666)</button>
<button @click="click3">unshift(999)</button>
<br /><br />
<button @click="click4">pop()</button>
<button @click="click5">splice(1, 1)</button>
<button @click="click6">shift()</button>
</div>
<script>
var app = new Vue({
el: '#app',
data: {
show: false,
list: [1, 2, 3],
},
methods: {
click1() {
this.list.push(4);
},
click2() {
this.list.splice(1, 0, 666);
},
click3() {
this.list.unshift(999);
},
click4() {
this.list.pop();
},
click5() {
this.list.splice(1, 1);
},
click6() {
this.list.shift();
}
},
})
</script>
</body>
</html>ログイン後にコピー 增加实验实验如下所示,我们首先更改原文字,然后点击按钮**「观察节点发生变化的个数」**: 在队尾增加
在队内增加
在队首增加
删除实验在队尾删除
在队内删除
在队首删除
实验结论增加实验表格为每次实验中,每种情况的最小更新量,假设列表原来的长度为
删除实验表格为每次实验中,每种情况的最小更新量,假设列表原来的长度为
通过以上实验和表格可以得到加上 key 的性能和最小量更新的个数是最小的,虽然在 写在最后本文从源码和实验的角度介绍了 Diff 算法,相信大家对 Diff 算法有了更深的了解了,如果有问题可私信交流或者评论区交流,如果大家喜欢的话可以点赞 ➕ 收藏 ? 源码函数附录
function setTextContent(node: Node, text: string) {
node.textContent = text
}ログイン後にコピー
function isUndef(v: any): v is undefined | null {
return v === undefined || v === null
}ログイン後にコピー
function isDef<T>(v: T): v is NonNullable<T> {
return v !== undefined && v !== null
}ログイン後にコピー
function insertBefore(
parentNode: Node,
newNode: Node,
referenceNode: Node
) {
parentNode.insertBefore(newNode, referenceNode)
}ログイン後にコピー
function nextSibling(node: Node) {
return node.nextSibling
}ログイン後にコピー
function createKeyToOldIdx(children, beginIdx, endIdx) {
let i, key
const map = {}
for (i = beginIdx; i <= endIdx; ++i) {
key = children[i].key
if (isDef(key)) map[key] = i
}
return map
}ログイン後にコピー 以上がVue2 の Diff アルゴリズムの詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。 このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。
著者別の最新記事
最新の問題
関連トピック
詳細>
|





















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



