

MySql のマスターとスレーブの同期を 1 つの記事で徹底的に理解する

この記事では、MySQL のマスターとスレーブの同期や動作原理などを中心に、MySql に関する知識を紹介します。
1 はじめに
皆さん、こんにちは。Mysql は誰にとっても最も一般的に使用されているデータベースです。以下は、mysql のマスターとスレーブの同期に関する知識ポイントを共有するものです。 Mysqlの基礎知識ですが、間違いがあればご指摘ください。
2 MySql マスター/スレーブ同期の概要
MySQL マスター/スレーブ同期、つまり MySQL レプリケーションは、1 つのデータベース サーバーから複数のデータベース サーバーにデータを同期できます。 MySQLデータベースにはマスタ・スレーブ同期機能が搭載されており、構築後はデータベースやテーブルの構造に基づいたさまざまな方式でマスタ・スレーブ同期を実現できます。
Redis は高性能のインメモリ データベースですが、今日の主役ではありません。MySQL はディスク ファイルをベースとしたリレーショナル データベースです。Redis と比較すると、読み取り速度は遅くなりますが、強力です。 . 永続的なデータの保存に使用できます。実際の業務ではMySQLと連携してRedisをキャッシュとして利用することが多いですが、データアクセス要求があった場合、まずキャッシュから検索し、存在する場合は直接取り出し、存在しない場合は、データベースへのアクセスが再度行われるため、パフォーマンスが向上し、読み取りの効率化により、バックエンド データベースへのアクセスの負荷も軽減されます。 Redis のようなキャッシュ アーキテクチャの使用は、同時実行性の高いアーキテクチャの非常に重要な部分です。
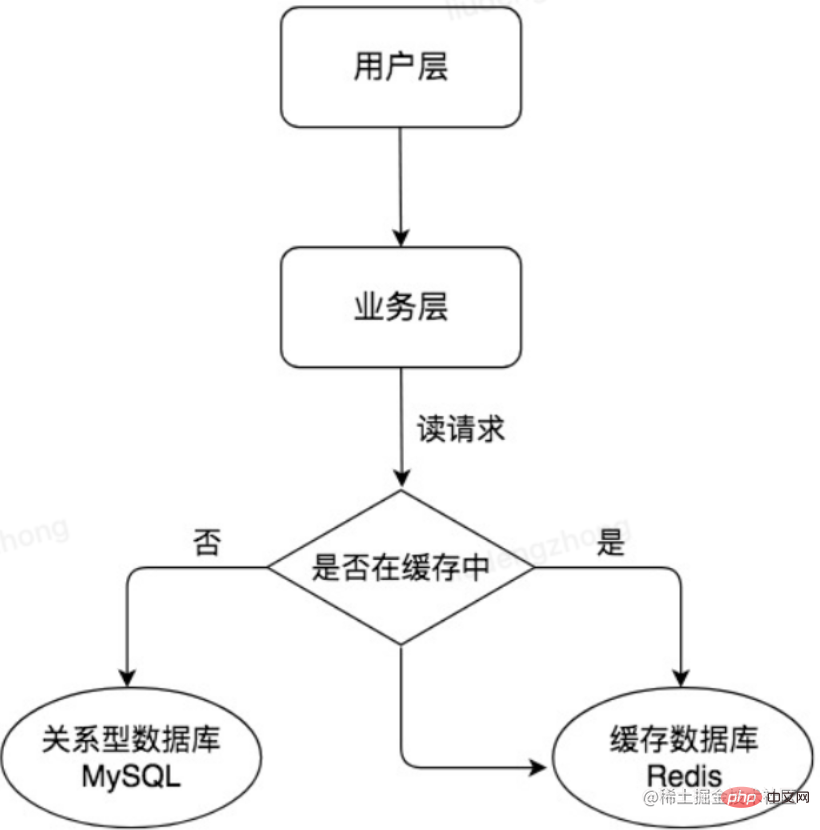
ビジネス量が増大し続けるにつれて、データベースへの負荷も増大し続けます。キャッシュ内の頻繁な変更もデータ クエリの結果に大きく依存するため、データクエリ効率の低下、高負荷、多すぎる接続など。電子商取引のシナリオでは、読み取りが多く書き込みが少ないという典型的なシナリオがよくあります。MySQL のマスター/スレーブ アーキテクチャを使用し、読み取りと書き込みを分離して、マスター サーバー (マスター) が書き込みリクエストを処理し、スレーブ サーバーが書き込みリクエストを処理するようにすることができます。 (スレーブ) は読み取りリクエストを処理します。これにより、データベースの同時処理能力がさらに向上します。下の図に示すように:
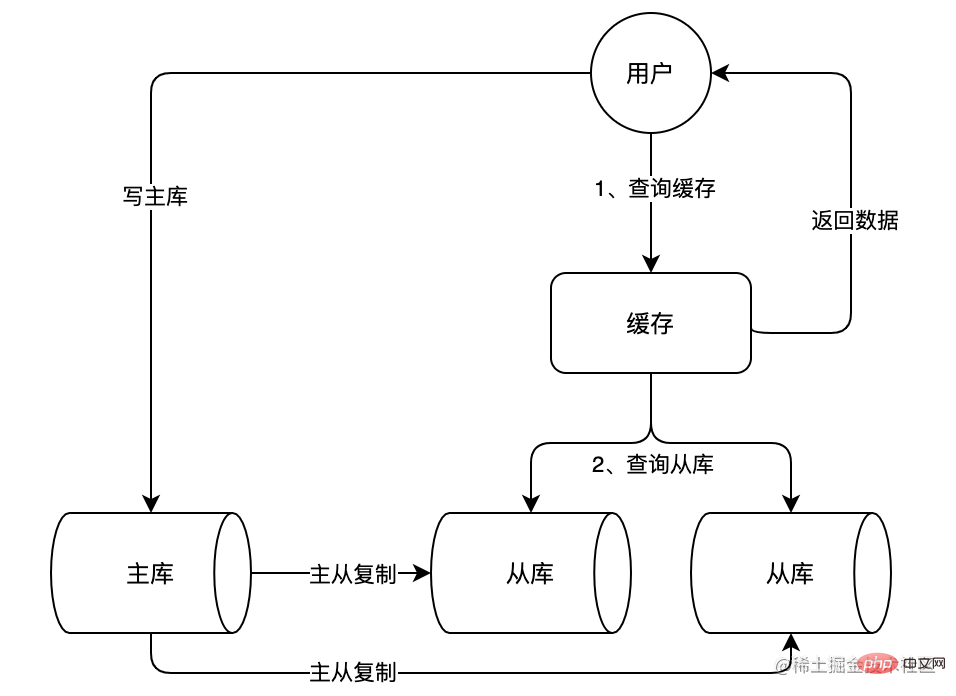
上の図では、2 つのスレーブ ライブラリが追加されていることがわかります。これら 2 つのスレーブ ライブラリは、大量の読み取りリクエストに耐えることができます。一緒に主要な負荷を共有し、ライブラリのプレッシャーを軽減します。スレーブ データベースは、マスター/スレーブ レプリケーションを通じてマスター データベースのデータを継続的に同期し、スレーブ データベースのデータがマスター データベースのデータと一貫していることを確認します。
次に、マスタ/スレーブ同期の機能とマスタ/スレーブ同期の実装方法を見てみましょう。
3 マスター/スレーブ同期の役割
一般に、すべてのシステムがデータベースのマスター/スレーブ アーキテクチャを設計する必要があるわけではありません。これは、アーキテクチャ自体にはい、目的がデータベースへの高同時アクセスの効率を向上させることである場合、データベースのパフォーマンスを最大限に引き出すために、まず SQL ステートメントとインデックスを最適化する必要があります。次に、次のようなキャッシュ戦略を採用する必要があります。 Redis や MongoDB などのキャッシュ ツールを使用することで、データをインメモリ データベースに保存して読み取り効率を向上させることで高いパフォーマンスを実現し、データベースは読み取りと書き込みを分離するマスター/スレーブ アーキテクチャを採用しています。システムの使用と保守のコストは、アーキテクチャのアップグレードに応じて徐々に増加します。
本題に戻りますが、マスターとスレーブの同期はデータベースのスループットを向上させるだけでなく、次の 3 つの側面もあります。
3.1 読み取りと書き込みの分離
マスター/スレーブ レプリケーションを通じてデータを同期し、読み取りと書き込みの分離を通じてデータベースの同時処理能力を向上させることができます。簡単に言うと、データは複数のデータベースに配置され、そのうちの 1 つはマスター データベース、残りはスレーブ データベースです。メイン データベースのデータが変更されると、データはスレーブ データベースに自動的に同期され、プログラムは読み書き分離方式を使用してスレーブ データベースからデータを読み取ることができます。電子商取引アプリケーションは多くの場合、「読み取りが多く、書き込みが少ない」ため、読み取りと書き込みを分離することで、より高い同時アクセスを実現できます。当初は、すべての読み取りおよび書き込みの負荷は 1 台のサーバーによって負担されていましたが、現在では、複数のサーバーが読み取りリクエストを共同で処理するため、メイン データベースへの負荷が軽減されています。さらに、スレーブサーバー上でロードバランシングを実行できるため、異なる読み取りリクエストをポリシーに従って異なるスレーブサーバーに均等に分散でき、読み取りがよりスムーズになります。読み込みをスムーズにするもう一つの理由は、ロックテーブルの影響を軽減するためで、例えば書き込みをメインライブラリに任せておけば、メインライブラリで書き込みロックが発生しても、スレーブライブラリのクエリ動作には影響を与えません。
3.2 データ バックアップ
マスターとスレーブの同期は、データ ホット バックアップ メカニズムにも相当します。これは、メイン データベースの通常の動作の下で、データベースに影響を与えることなくバックアップされます。データサービスの提供。
3.3 高可用性
データ バックアップは実際には冗長メカニズムです。この冗長方法を通じて、データベースの高可用性を交換できます。サーバーに障害が発生すると、、ダウンタイムやその他の利用できない状況では、フェイルオーバーを迅速に実行でき、スレーブ データベースがマスター データベースとして機能して、サービスの通常の動作を保証できます。電子商取引システム データベースの高可用性 SLA 指標について学習できます。
4 マスター/スレーブ同期の原理
マスター/スレーブ同期の原理について言えば、データベース内の重要なログ ファイル、つまりデータベースを更新するイベントを記録する Binlog バイナリ ファイルについて理解する必要があります。実際、マスター/スレーブ同期の原理Binlog に基づいており、データは同期されています。
マスター/スレーブ レプリケーションのプロセスでは、操作は 3 つのスレッドに基づいて行われます。1 つはマスター ノードにあるバイナリ ダンプ スレッドで、他の 2 つのスレッドは I/O スレッドと SQL
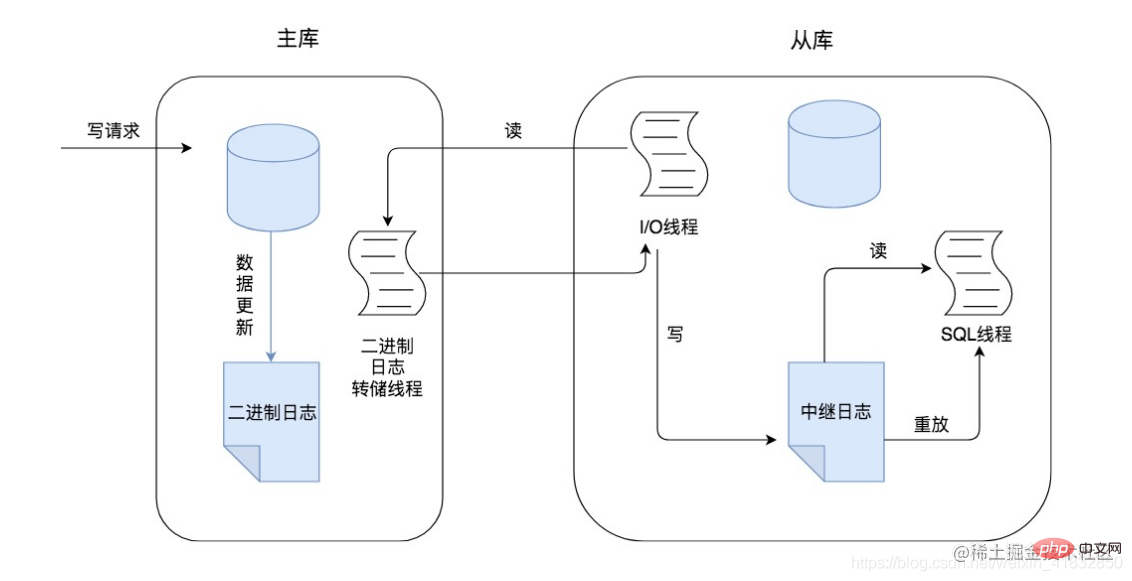
- マスターノードが書き込みリクエストを受信した場合、書き込みリクエストは追加、削除、または変更操作である可能性があり、このとき、書き込みリクエストの更新操作は binlog ログに記録されます。
- マスター ノードは、図のスレーブ ノード (slave01 ノードとスレーブ 02 ノードなど) にデータをコピーします。このプロセスでは、各スレーブ ノードが最初にマスターに接続されている必要があります。ノードがマスター ノードに接続されると、マスター ノードは各スレーブ ノードのバイナリ ログ ダンプ スレッドを作成し、バイナリ ログを各スレーブ ノードに送信します。
- binlog ダンプ スレッドは、マスター ノードの binlog ログを読み取り、その binlog ログをスレーブ ノードの I/O スレッドに送信します。メイン ライブラリがイベントを読み取ると、Binglog がロックされ、読み取りが完了するとロックが解除されます。
- スレーブ ノードの I/O スレッドは、binlog ログを受信した後、まず binlog ログをローカルのリレーログに書き込み、binlog ログはリレーログに保存されます。
- スレーブ ノードの SQL スレッドは、リレーログ内の binlog ログを読み取り、特定の追加、削除、変更操作に解析し、マスター ノードで実行されたこれらの操作を Do に組み込みます。スレーブノード上で再度実行することでデータ復元の効果が得られ、マスターノードとスレーブノード間のデータの整合性が確保されます。
5 マスター/スレーブ同期のデータ整合性問題を解決する方法
ご想像のとおり、操作したいデータがすべて同じデータベースに保存されている場合、データが更新されると、読み取り時にデータの不整合が発生しないように、レコードに書き込みロックを追加できます。ただし、現時点では、スレーブ ライブラリの役割は、メイン ライブラリの負荷を分散するために、読み取りと書き込みを分離せずにデータをバックアップすることです。 したがって、読み取りと書き込みを分離した場合のマスターとスレーブの同期におけるデータ不整合の問題、つまりマスターとスレーブ間のデータ複製の問題を解決する方法も見つける必要があります。スレーブはデータの整合性に従う 弱いレプリケーションから強いレプリケーション方法に分けると、次の 3 つのレプリケーション方法があります。5.1 完全同期レプリケーション
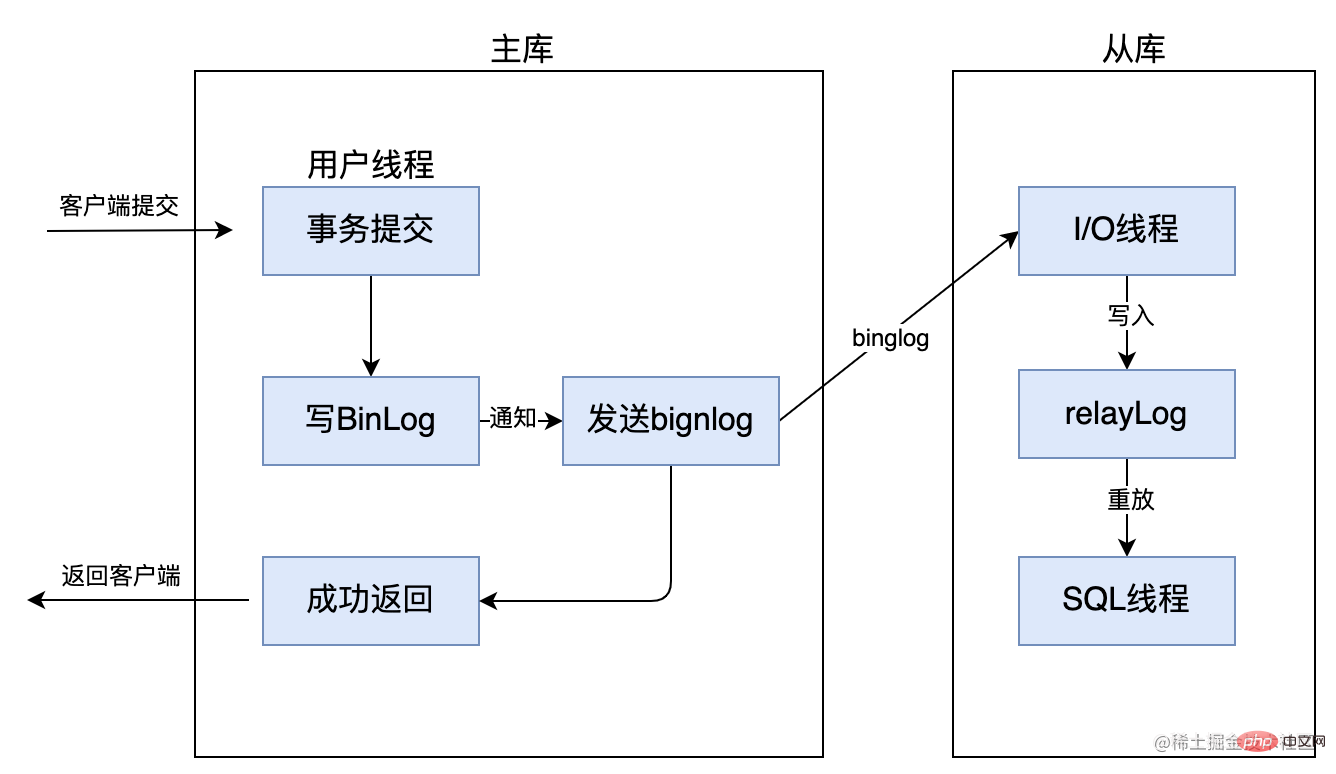
まず第一に、完全同期レプリケーションとは、マスター データベースがトランザクションを完了した後、すべてのスレーブ データベースもトランザクションを完了する必要があることを意味します。処理結果をクライアントに返すことができるため、完全同期レプリケーションのデータ整合性は保証されますが、マスターライブラリはすべてのスレーブライブラリがトランザクションを完了するまで待つ必要があり、パフォーマンスが比較的低くなります。以下に示すように: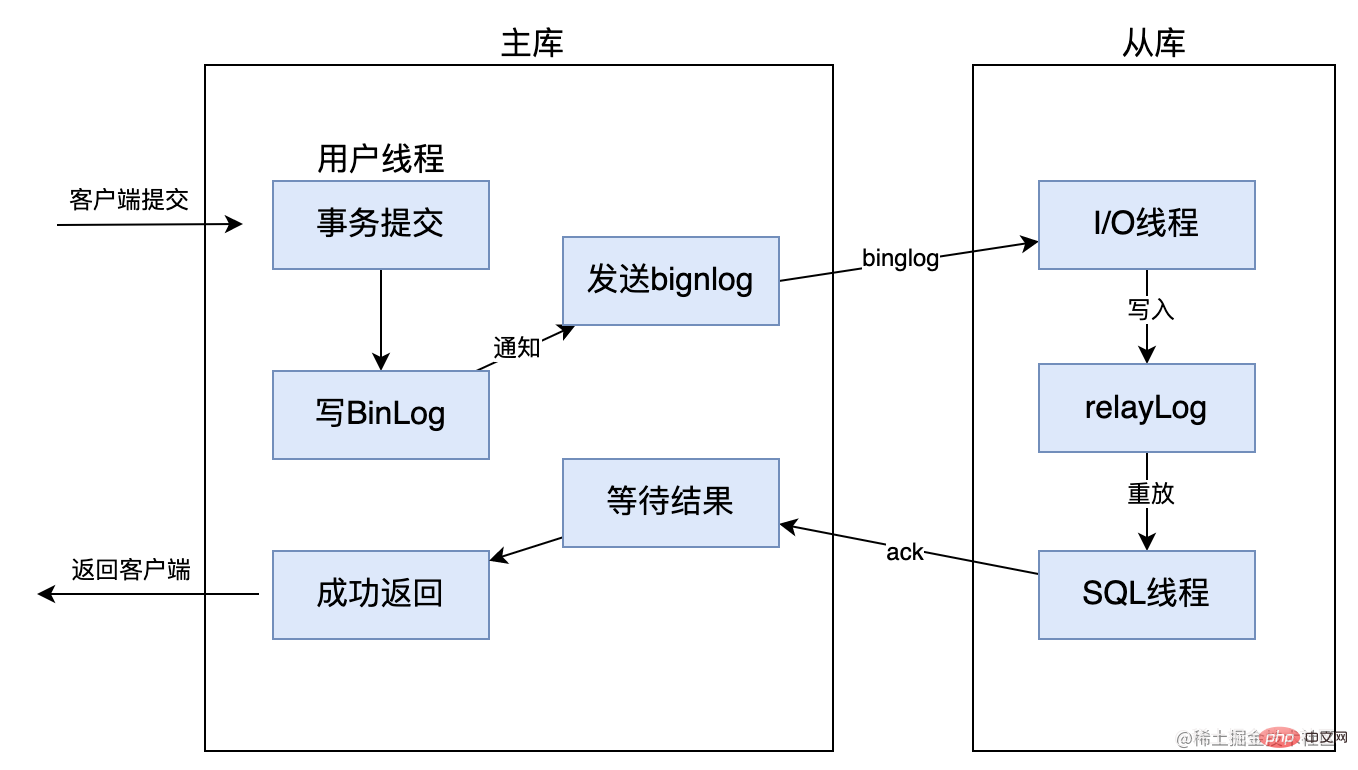
5.2 非同期レプリケーション
非同期レプリケーションとは、メイン ライブラリが送信するときに、バイナリ ダンプ スレッドが送信するよう通知される binlog ログはスレーブ ライブラリに送信されます。binlog ダンプ スレッドが binlog ログをスレーブ ライブラリに送信すると、スレーブ ライブラリがトランザクションを同期的に完了するのを待つ必要はありません。マスター ライブラリは、処理結果をクライアントに送信します。 メインライブラリは自らトランザクションを完了させればよいため、スレーブライブラリがトランザクションを完了したかどうかを気にすることなく処理結果をクライアントに返すことができ、短期的なマスタースレーブにつながる可能性があります。データの不整合。マスター データベースに挿入されたばかりの新しいデータをスレーブ データベースからすぐにクエリすると、クエリできない可能性があります。さらに、トランザクション送信後にメイン データベースがクラッシュした場合、binlog をスレーブ データベースに同期する時間がない場合があり、このとき、回復障害のためにマスター/スレーブ ノードが切り替わると、データの損失が発生します。したがって、非同期レプリケーションはパフォーマンスは高いものの、データの一貫性という点では最も弱いものになります。
Mysql マスター/スレーブ レプリケーションは、デフォルトで非同期レプリケーションを採用します。
5.3 準同期レプリケーション
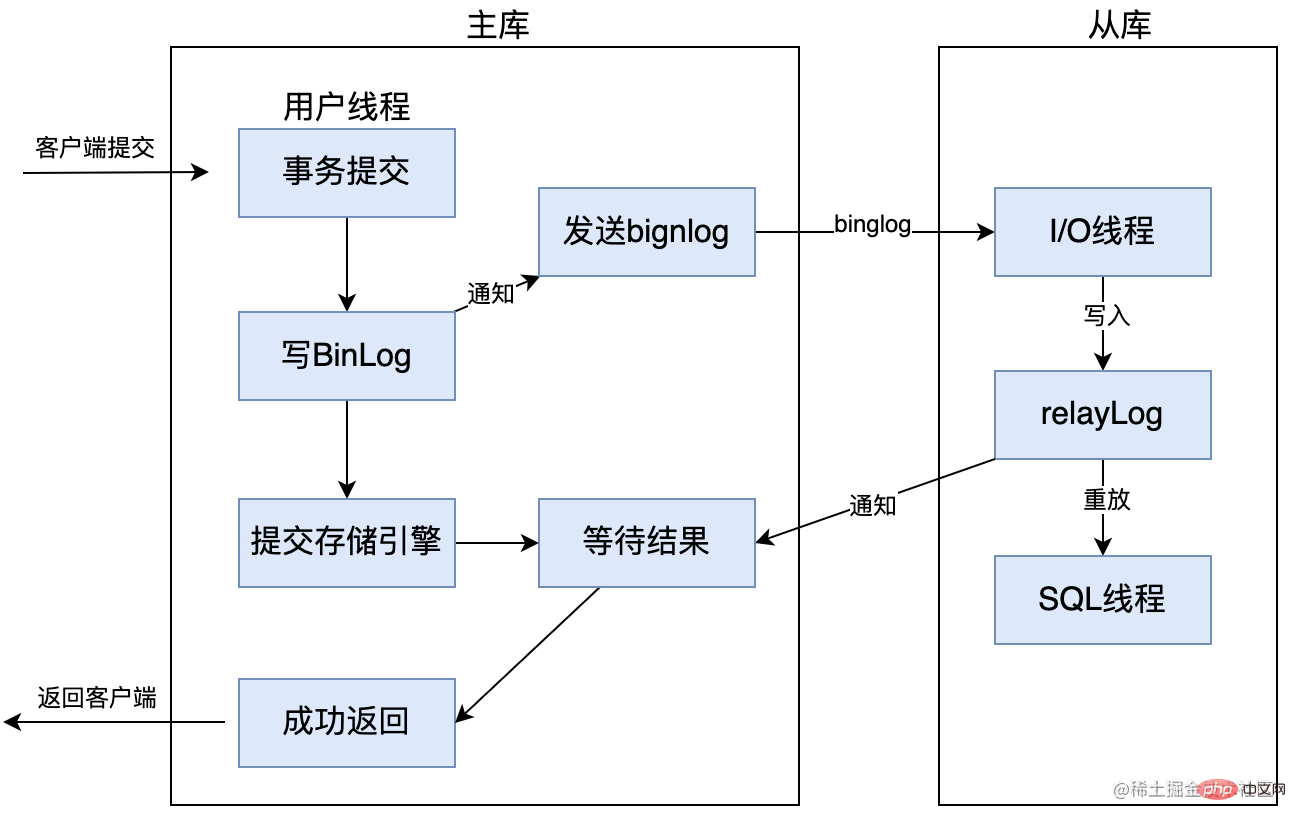
MySQL バージョン 5.5 以降では、準同期レプリケーションがサポートされています。原則として、クライアントが COMMIT を送信した後、結果はクライアントに直接返されず、少なくとも 1 つのスレーブ ライブラリが Binlog を受信してリレー ログに書き込むのを待ってからクライアントに返します。この利点は、データの一貫性が向上することですが、もちろん、非同期レプリケーションと比較すると、少なくとも 1 つのネットワーク接続の遅延が増加し、メイン データベースへの書き込み効率が低下します。
MySQL5.7 バージョンでは、rpl_semi_sync_master_wait_for_slave_count パラメータも追加されました。応答する必要があるスレーブ ライブラリの数を設定できます。デフォルトは 1 です。これは、1 つのスレーブ ライブラリが応答する限り、クライアントに返すことができます。このパラメータを増やすと、データの一貫性の強度を高めることができますが、マスター データベースがスレーブ データベースの応答を待つ時間も長くなります。
ただし、準同期レプリケーションには次の問題もあります。
- 半同期レプリケーションのパフォーマンスは、非同期レプリケーションと比較すると異なります。データを受信するためにスレーブ ライブラリからの応答を待つ必要がない非同期レプリケーションと比較して、半同期レプリケーションでは、binlog ログの受信を確認するためにスレーブ ライブラリからの少なくとも 1 つの応答を待つ必要があり、その結果、パフォーマンスの損失。
- マスターライブラリがスレーブライブラリからの応答を待つ最大時間は設定可能であり、設定時間を超えると準同期レプリケーションが非同期レプリケーションとなり、非同期レプリケーションの問題も発生します。
- MySQL 5.7.2 より前のバージョンでは、半同期レプリケーションにファントム読み取りの問題がありました。
メイン ライブラリがトランザクションを正常に送信し、スレーブ ライブラリからの確認を待っているとき、この時点ではスレーブ ライブラリには処理結果をクライアントに返す時間がありません。ただし、メイン ライブラリ ストレージ エンジンがすでにトランザクションを送信しているため、他のクライアントはメイン ライブラリからデータを読み取ることができます。
ただし、メイン ライブラリが次の 1 秒以内に突然ハングアップし、その時点で次のリクエストが来た場合、メイン ライブラリがハングアップするため、リクエストはスレーブ ライブラリにのみ切り替えることができます。スレーブライブラリはマスターライブラリからのリクエストをまだ受け取っていません データベースはデータを同期しているため、当然このデータはデータベースから読み込むことができません 1秒前のデータ読み出し結果と比較すると、ファントムリード現象が発生します引き起こされます。
5.4 強化された準同期レプリケーション
強化された準同期レプリケーションは、mysql 5.7.2 以降のバージョンの準同期レプリケーションに加えられた改良です。原理はほぼ同じで、主に魔法の問題を解決します。読み取り問題です。
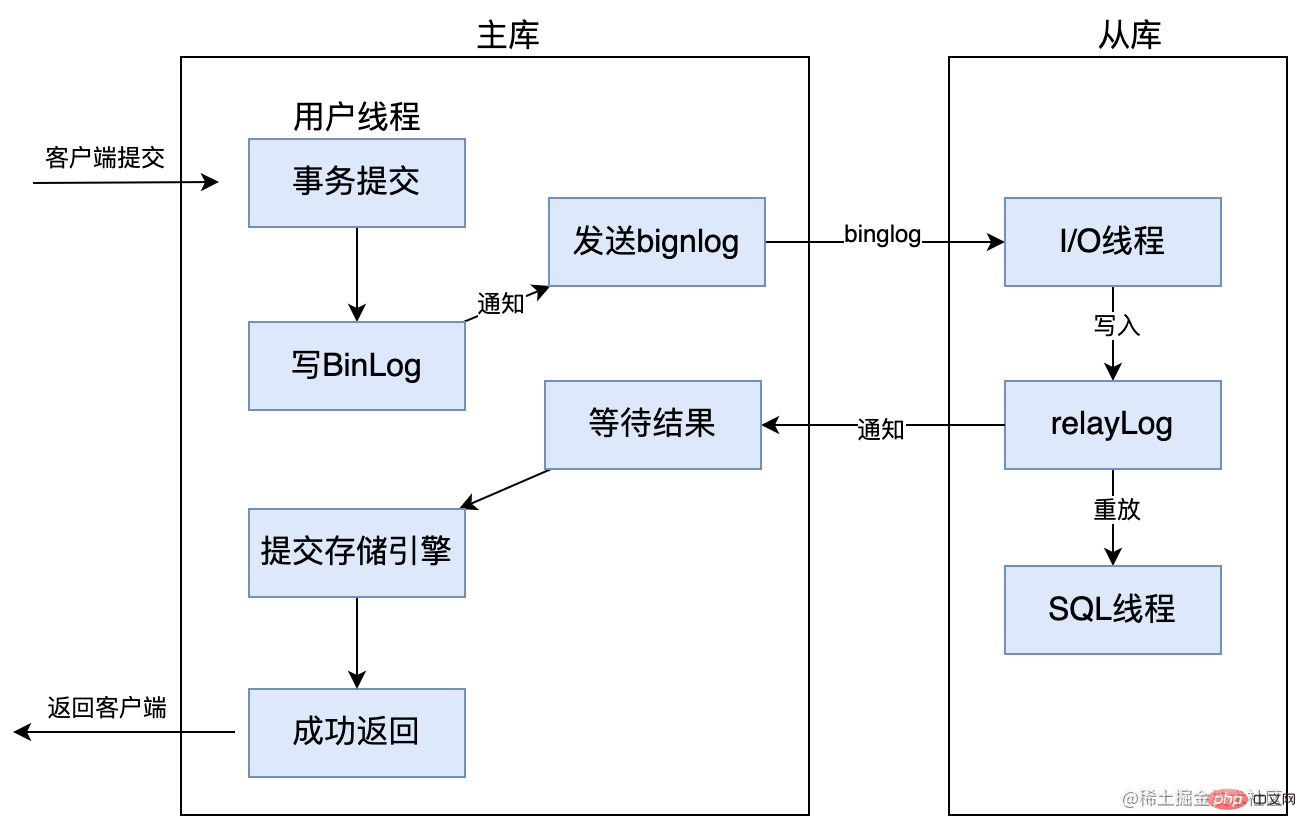
マスター ライブラリがパラメータ rpl_semi_sync_master_wait_point = AFTER_SYNC で構成された後、ストレージ エンジンがトランザクションをコミットする前に、マスター ライブラリはトランザクションを送信する前にスレーブ ライブラリからデータ同期の完了の確認を受信する必要があります。これにより、ファントムリード問題です。以下の図を参照してください:
6 概要
上記の内容を通じて、Mysql のマスターとスレーブの同期について理解しました。目標はデータベースの高い同時実行性のみであるため、まず SQL の最適化、インデックス作成、Redis キャッシュ データなどの側面から最適化を検討し、次にマスター/スレーブ アーキテクチャを採用するかどうかを検討できます。
マスター/スレーブ アーキテクチャの構成において、読み取りと書き込みの分離戦略を採用したい場合は、独自のプログラムを作成するか、サードパーティのミドルウェアを通じて実装することができます。
独自のプログラムを作成する利点は、プログラムがより独立していることです。どのクエリをスレーブ データベースで実行するかを判断できます。高いリアルタイム要件の場合は、どのクエリをスレーブ データベースで実行できるかを考慮することもできます。メインデータベース。同時に、プログラムはデータベースに直接接続するため、ミドルウェア層が削減され、パフォーマンスの損失が軽減されます。
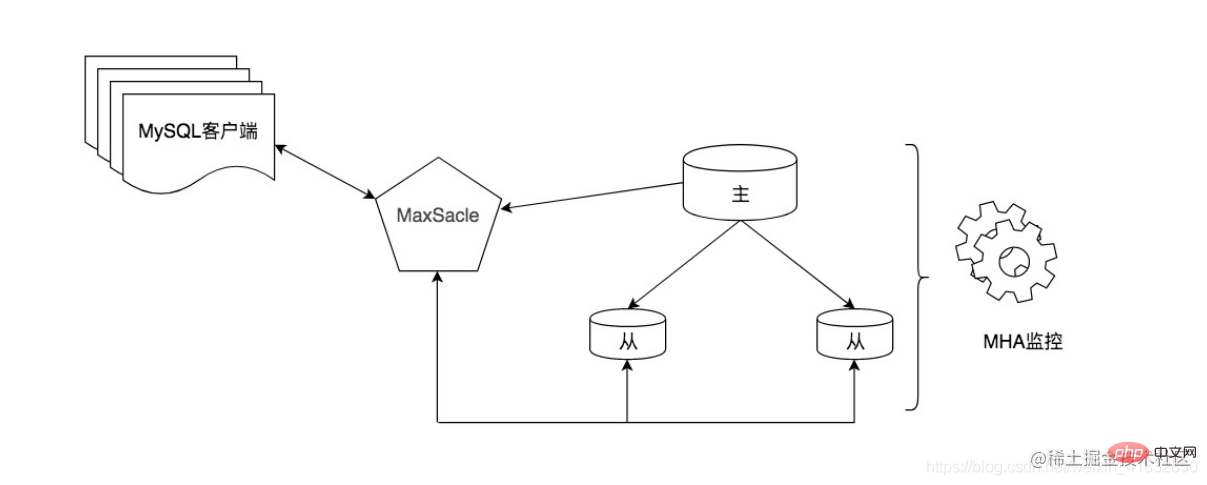
ミドルウェアを使用する方法には明らかな利点があり、強力で使いやすいです。ただし、クライアントとデータベースの間にミドルウェア層を追加するため、ある程度のパフォーマンスが低下すると同時に、商用ミドルウェアの価格は比較的高く、一定の学習コストがかかります。さらに、MaxScale などの優れたオープンソース ツールの使用も検討できます。 MariaDB社が開発したMySQLデータミドルウェアです。たとえば、次の図では、MaxScale がデータベース プロキシとして使用され、ルーティングと転送によって読み取りと書き込みの分離が完了します。同時に、MHA ツールを一貫性の高いマスター/スレーブ切り替えツールとして使用して、MySQL の高可用性アーキテクチャを完成させることもできます。
推奨学習: 「MySQL ビデオ チュートリアル 」
以上がMySql のマスターとスレーブの同期を 1 つの記事で徹底的に理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7528
7528
 15
1378
52
81
11
21
75
15
1378
52
81
11
21
75

 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
データベースから直接削除された行を直接回復することは、バックアップまたはトランザクションロールバックメカニズムがない限り、通常不可能です。キーポイント:トランザクションロールバック:トランザクションがデータの回復にコミットする前にロールバックを実行します。バックアップ:データベースの定期的なバックアップを使用して、データをすばやく復元できます。データベーススナップショット:データベースの読み取り専用コピーを作成し、データが誤って削除された後にデータを復元できます。削除ステートメントを使用して注意してください:誤って削除されないように条件を慎重に確認してください。 WHERE句を使用します:削除するデータを明示的に指定します。テスト環境を使用:削除操作を実行する前にテストします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
