
この記事では、Redis の面接でよくある質問 20 個をまとめました。お役に立てば幸いです。

Redis は、正式な英語名は Remote Dictionary Server (リモート辞書サービス) で、ANSI C 言語で書かれたオープン ソースのログ タイプで、ネットワークをサポートし、メモリとKey-Value データベースであり、複数の言語で API を提供します。
MySQL データベースとは異なり、Redis データはメモリに保存されます。読み取りおよび書き込み速度は非常に高速で、1 秒あたり 100,000 回を超える読み取りおよび書き込み操作を処理できます。したがって、Redis はキャッシュに広く使用されているだけでなく、分散ロックにもよく使用されます。さらに、Redis はトランザクション、永続性、LUA スクリプト、LRU 駆動イベント、およびさまざまなクラスター ソリューションをサポートします。 2. Redis の基本的なデータ構造タイプについて話す
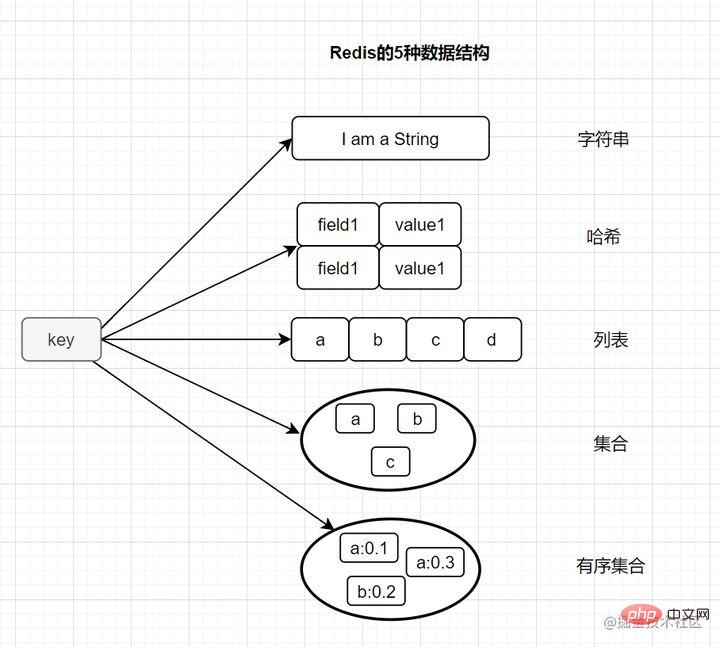 String (string)
String (string)
get key など。SDS (単純な動的文字列) カプセル化を使用します。sds のソース コードは次のとおりです。 :
struct sdshdr{
unsigned int len; // 标记buf的长度
unsigned int free; //标记buf中未使用的元素个数
char buf[]; // 存放元素的坑
}C 言語ネイティブであるのに、Redis が 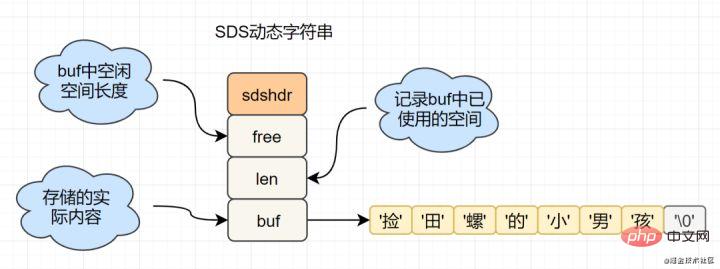 SDS
SDS
char[] いい匂いしませんか? たとえば、SDS では、文字列の長さは O(1) の時間計算量で取得できますが、C 文字列の場合は、文字列全体を走査する必要があり、時間計算量は O です。 (n)
Hash (ハッシュ)
はじめに: Redis では、ハッシュ タイプは、キーと値のペア (k-v) である v (値) 自体を指します。構造
ziplist (圧縮リスト), 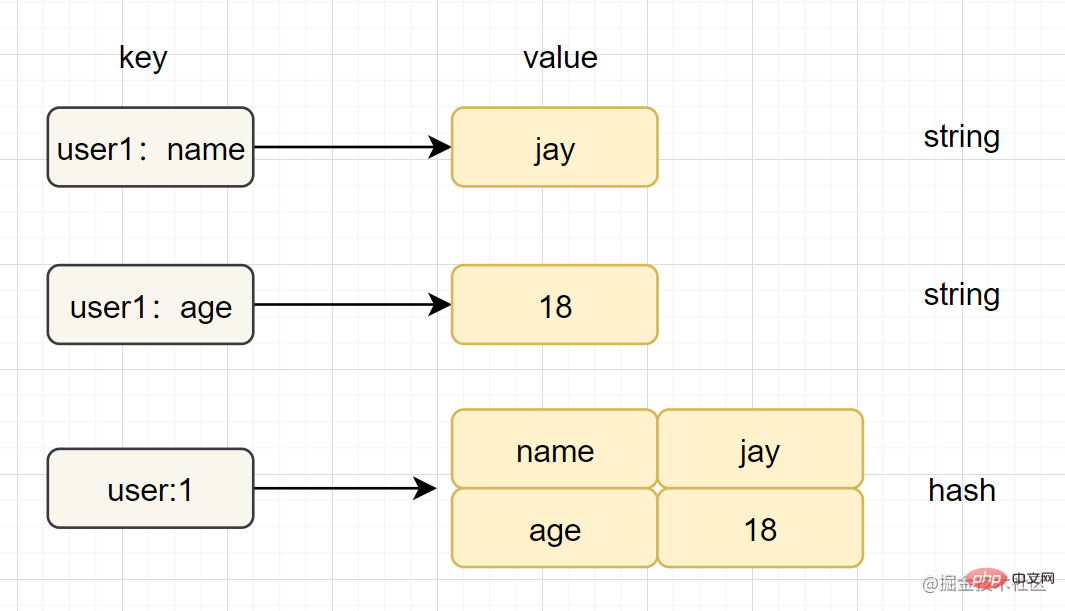
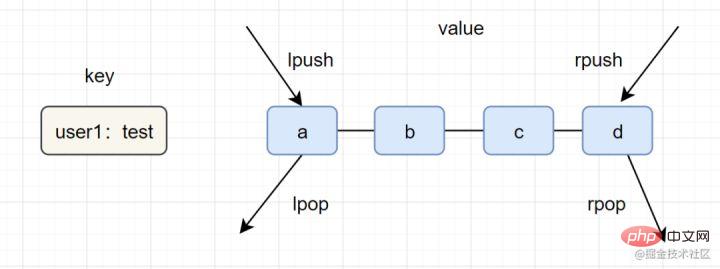
lpush lpop=Stack (スタック)
lpush rpop=Queue (キュー)
- lpsh ltrim=Capped Collection (限定コレクション)
- lpush brpop=Message Queue (メッセージキュー)
- Set (コレクション)
はじめに: set 型は複数の文字列要素を保存するためにも使用されますが、要素の重複は許可されません。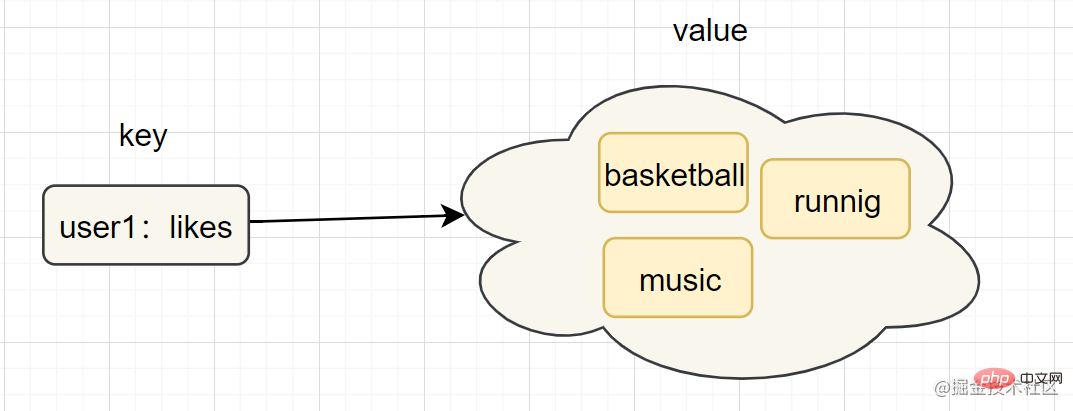
intset (整数セット) , 注意事項 : smembers、lrange、hgetall は比較的重いコマンドですが、要素が多すぎて Redis がブロックされる可能性がある場合は、sscan を使用して完了できます。 zadd キー スコア メンバー [スコア メンバー...], zrank キー メンバーziplist (圧縮リスト)、skiplist (スキップ リスト)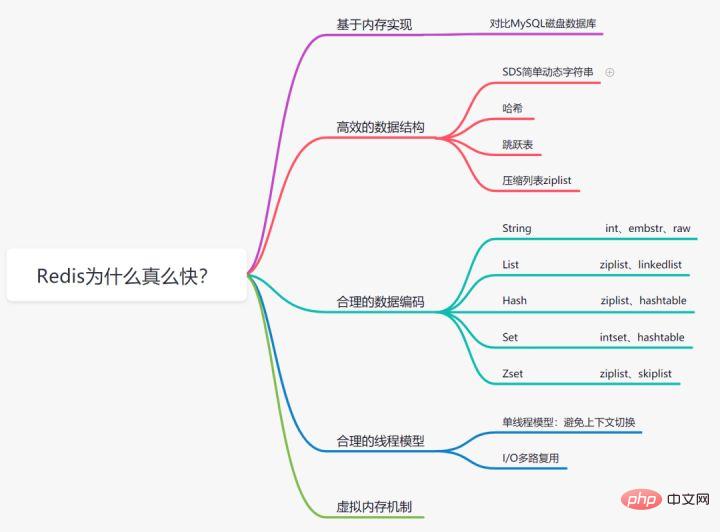
Redis が速い理由
誰もがメモリの読み取りを知っています。データがディスクに保存される MySQL データベースと比較して、Redis データベースはディスクよりもはるかに高速なメモリ ストレージに基づいて実装され、ディスク I/O の消費を節約します。
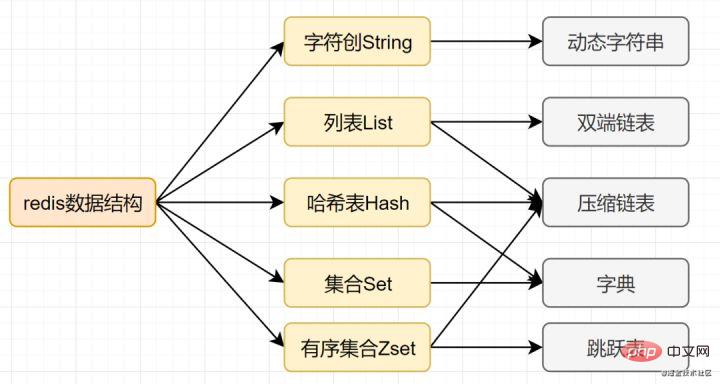
効率を向上させるために、Mysql インデックスは B ツリー データ構造を選択することがわかっています。実際、合理的なデータ構造により、アプリケーション/プログラムを高速化できます。まず、Redis のデータ構造と内部エンコード図を見てみましょう。
#SDS 単純な動的文字列
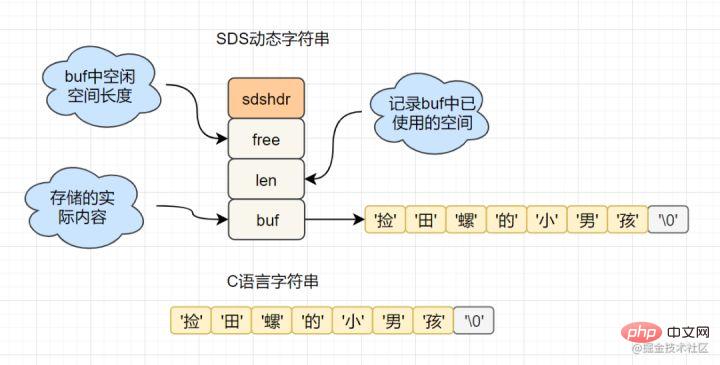
- #文字列の長さの処理: Redis は文字列の長さを取得します。時間計算量は O(1) ですが、C 言語では最初からたどる必要があり、計算量は O(n);
- スペースの事前割り当て : 文字列が変更される頻度が高くなるほど、メモリの割り当ても頻繁になり、パフォーマンスが消費されます。SDS の変更とスペースの拡張により、追加の未使用スペースが割り当てられ、パフォーマンスの損失が軽減されます。
- Lazy space release: SDS が短縮されると、余分なメモリ領域をリサイクルする代わりに、free に余分な領域が記録されます。その後変更があった場合、free に記録された領域は割り当てを削減するために直接使用されます。
- バイナリ セーフティ: Redis はバイナリ データを保存できます。C 言語では、文字列は '\0' に遭遇すると終了しますが、SDS では、len 属性が文字列の終わりをマークします。
Dictionary
Redis は K-V 型のメモリ データベースであり、すべてのキー値は辞書に格納されます。ディクショナリは HashMap などのハッシュ テーブルであり、キーを通じて対応する値を直接取得できます。ハッシュテーブルの特徴としては、O(1)の計算量で対応する値が得られる。
ジャンプ テーブル
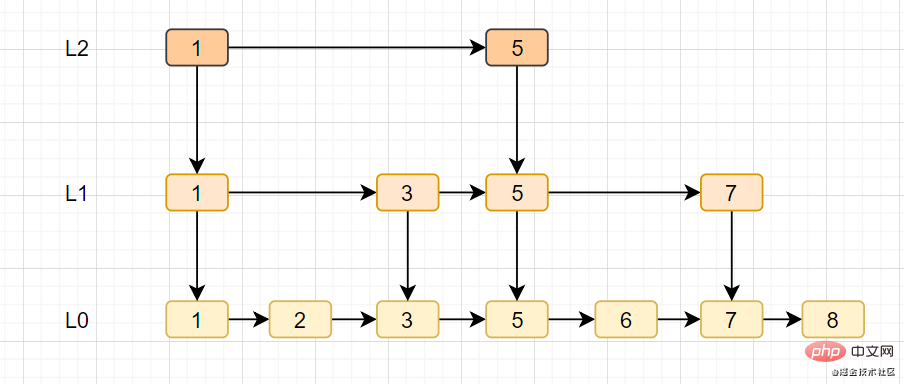
- スキップ テーブルは Redis の独自のデータ構造であり、リンク リストに基づいて複数のデータを追加します。 -レベルインデックスの改善、検索効率。
- スキップ テーブルは、平均 O(logN) および最悪の場合の O(N) 複雑さによるノード検索をサポートし、順次操作を通じてノードをバッチで処理することもできます。
Redis は複数のデータ型をサポートしており、各基本型には複数のデータ構造がある場合があります。いつ、どのようなデータ構造を使用するか、どのエンコーディングを使用するかは、Redis デザイナーの要約と最適化の結果です。
- 文字列: 数値が格納される場合は、int 型のエンコードが使用されます。数値以外が格納される場合は、39 バイト以下の文字列は embstr になります。39 バイトより大きい場合は、embstr になります。バイトの場合は、生のエンコードです。
- リスト: リスト内の要素の数が 512 未満で、リスト内の各要素の値が 64 バイト (デフォルト) 未満の場合は、ziplist エンコードを使用します。それ以外の場合は、リンクリスト エンコードを使用します。
- Hash: Ha ハッシュ型要素の数が 512 未満で、すべての値が 64 バイト未満の場合は ziplist エンコーディングを使用し、それ以外の場合はハッシュテーブル エンコーディングを使用します。
- Set: セット内の要素がすべて整数で、要素の数が 512 未満の場合は、intset エンコーディングを使用します。それ以外の場合は、ハッシュテーブル エンコーディングを使用します。
#Zset: 順序付きセット内の要素の数が 128 未満で、各要素の値が 64 バイト未満の場合は、ziplist エンコーディングを使用します。それ以外の場合は、skiplist (スキップ リスト) エンコーディングを使用します
I/O 多重化
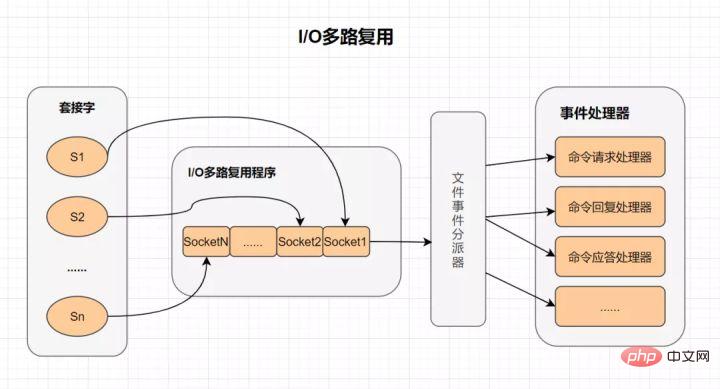
複数の I/O 多重化テクノロジを使用すると、単一のスレッドで複数の接続リクエストを効率的に処理できます。Redis は、I/O 多重化テクノロジの実現として epoll を使用します。さらに、Redis 独自のイベント処理モデルは、ネットワーク I/O にあまり時間を費やすことなく、epoll での接続、読み取り、書き込み、およびシャットダウンをイベントに変換します。I/O 多重化とは何ですか?
- I/O: ネットワーク I/O
- マルチチャネル: 複数のネットワーク接続
- 多重化: 同じスレッドを再利用します。
- IO 多重化は実際には同期 IO モデルであり、複数のファイル ハンドルを監視できるスレッドを実装します。ファイル ハンドルの準備が完了すると、対応する読み取りおよび書き込み操作を実行するようにアプリケーションに通知できます。ファイル ハンドルがない場合は、準備ができている場合、アプリケーションはブロックされ、CPU が引き渡されます。
シングル スレッド モデル
Redis は VM 機構を自ら直接構築するため、通常のシステムのようにシステム関数を呼び出すことがなく、ある程度の無駄が発生します。移動してリクエストしてください。
Redis の仮想メモリ メカニズムとは何ですか?
仮想メモリ メカニズムは、アクセス頻度の低いデータ (コールド データ) をメモリからディスクに一時的に交換し、アクセスする必要がある他のデータ (ホット データ) のために貴重なメモリ領域を解放します。 。 データ)。 VM 機能は、ホット データとコールド データの分離を実現できるため、ホット データはメモリ内に残り、コールド データはディスクに保存されます。これにより、メモリ不足によるアクセス速度の低下の問題を回避できます。
まず、一般的なキャッシュの使用方法を見てみましょう。読み取りリクエストが来たとき、まずキャッシュをチェックします。キャッシュがヒットした場合は直接戻りますが、キャッシュがミスした場合はデータベースをチェックし、データベースの値をキャッシュに更新してから戻ります。
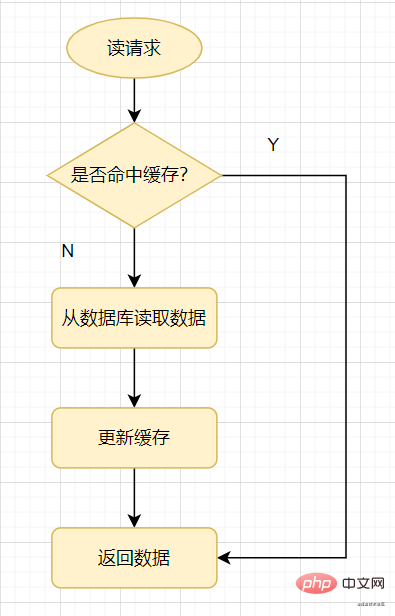
キャッシュの読み取り
キャッシュ侵入: 存在してはいけないデータのクエリを指します。これは、キャッシュがミスするために必要です。データベースからクエリを実行する場合、データが見つからない場合、そのデータはキャッシュに書き込まれません。これにより、存在しないデータがリクエストされるたびにデータベース内でクエリが行われることになり、データベースに負荷がかかります。
平たく言えば、読み取りリクエストがアクセスされるとき、キャッシュにもデータベースにも特定の値がないため、この値に対する各クエリ リクエストがデータベースに侵入します。これがキャッシュの侵入です。 . .
キャッシュの侵入は通常、次の状況によって発生します。
キャッシュの侵入を回避するにはどうすればよいですか? 一般に 3 つの方法があります。
ブルーム フィルターの原理: 初期値 0 のビットマップ配列と N 個のハッシュ関数で構成されます。キーに対して N 個のハッシュ アルゴリズムを実行して N 個の値を取得します。これらの N 個の値をビット配列でハッシュし、1 に設定します。次に、チェック時に、これらの特定の位置がすべて 1 であれば、ブルーム フィルター処理が行われます。サーバーはキーが存在すると判断します。 。
キャッシュ スノー ラン: は、キャッシュ内の大量のデータの有効期限を指します。クエリ データの量が膨大で、すべてのリクエストがデータベースに直接アクセスするため、データベースに過剰な負荷がかかり、ダウンタイムさえ発生します。
キャッシュ ブレークダウン: とは、ホットスポット キーがある時点で期限切れになることを指します。この時点で、このキーに対して多数の同時リクエストがあり、大量のリクエストがデータベースにヒットします。
キャッシュ ブレークダウンは少し似ています。実際、それらの違いは、キャッシュ クラッシュは、データベースに過剰な負荷がかかっているか、さらにはダウンしていることを意味することです。キャッシュ ブレークダウンは、DB データベース レベルへの同時リクエストの数が単に多いだけです。ブレークダウンはキャッシュ スノーランのサブセットであると考えることができます。一部の記事では、この 2 つの違いは、ブレークダウンが特定のホット キー キャッシュを対象としているのに対し、Xuebeng は多くのキーを対象としている点であると考えられています。
解決策は 2 つあります:
ホット キー とは何ですか? Redisではアクセス頻度の高いキーをホットスポットキーと呼びます。
ホットスポット キーのリクエストがサーバー ホストに送信されると、リクエスト量が特に多いため、ホスト リソースが不足したり、ダウンタイムが発生したりして、通常のサービスに影響を与える可能性があります。
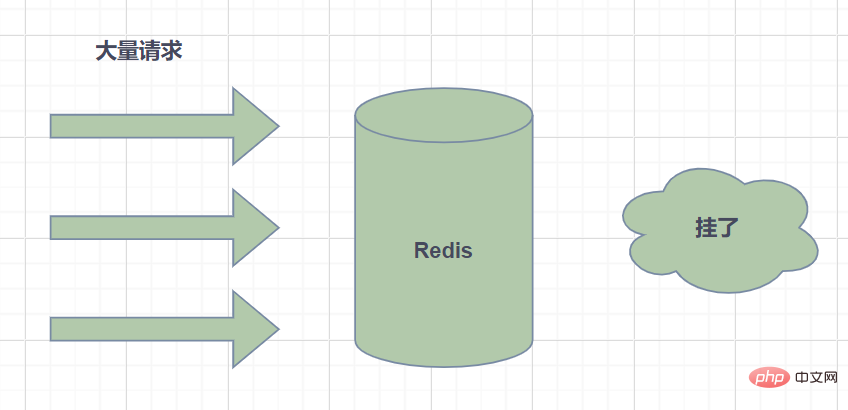
ホットスポット キーはどのように生成されますか?主な理由は 2 つあります。
- ユーザーが消費するデータは、速報セール、話題のニュース、その他のシナリオなど、より多くの読み取りとより少ない書き込みが必要なシナリオなど、生成されるデータよりもはるかに大きいためです。
- リクエストシャーディングが集中し単一のRediサーバーの性能を超え、例えば固定名のキーとハッシュが同一サーバーに落ちてしまうとインスタントアクセス量が膨大になりマシンのボトルネックを超えてしまい、ホットキーの問題を引き起こします。
では、日々の開発においてホットキーを特定するにはどうすればよいでしょうか?
- どのホット キーがエクスペリエンスに基づいているかを決定する;
- クライアント統計をレポートする;
- サービス エージェント層にレポートする
ホットキーの問題を解決するにはどうすればよいですか?
- Redis クラスターの拡張: シャード コピーを追加して読み取りトラフィックのバランスをとる;
- ホット キーをさまざまなサーバーに配布する;
- セカンダリ キャッシュを使用する、つまり、 JVM ローカル キャッシュにより、Redis 読み取りリクエストが削減されます。
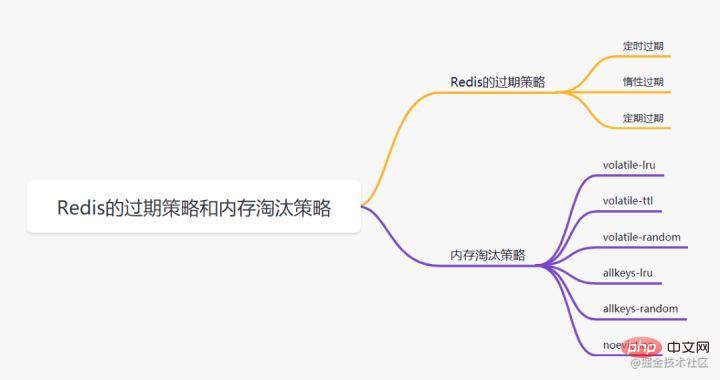
#キーを 設定するとき、有効期限をキー 60 のように設定できます。このキーが 60 秒後に期限切れになるように指定します。60 秒後に Redis はそれをどのように処理しますか?まず、いくつかの有効期限戦略を紹介します。
# 有効期限のあるキーごとにタイマーを作成する必要があり、有効期限に達するとキーはすぐにクリアされます。 。この戦略は期限切れのデータを即座にクリアでき、メモリに非常に優しいですが、期限切れのデータを処理するために大量の CPU リソースを占有するため、キャッシュの応答時間とスループットに影響します。遅延有効期限
キーにアクセスしたときのみ、キーの有効期限が切れているかどうかを判定し、有効期限が切れている場合はクリアします。この戦略は CPU リソースを最大限に節約できますが、メモリには非常に優しくありません。極端な場合には、期限切れの多数のキーに再度アクセスできなくなり、クリアされずに大量のメモリを占有してしまうことがあります。定期的な有効期限
一定の時間ごとに、特定の数のデータベースの有効期限切れディクショナリ内の特定の数のキーがスキャンされ、期限切れのキーがクリアされます。 。この戦略は、最初の 2 つの戦略の折衷案です。スケジュールされたスキャンの時間間隔と各スキャンの制限された消費時間を調整することにより、さまざまな状況下で CPU とメモリのリソース間の最適なバランスを実現できます。 expires ディクショナリは、有効期限が設定されたすべてのキーの有効期限データを保存します (key はキー空間内のキーへのポインタ、value はミリ秒精度のキーの UNIX タイムスタンプ)。 。キースペースは、Redis クラスターに保存されているすべてのキーを指します。Redis は、
遅延有効期限と定期有効期限の両方を使用します2 つの有効期限戦略を使用します。
但是呀,如果定期删除漏掉了很多过期的key,然后也没走惰性删除。就会有很多过期key积在内存内存,直接会导致内存爆的。或者有些时候,业务量大起来了,redis的key被大量使用,内存直接不够了,运维小哥哥也忘记加大内存了。难道redis直接这样挂掉?不会的!Redis用8种内存淘汰策略保护自己~
- volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
- allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
- volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
- allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰;
- volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。
- allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰;
- noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
我们一提到redis,自然而然就想到缓存,国内外中大型的网站都离不开缓存。合理的利用缓存,比如缓存热点数据,不仅可以提升网站的访问速度,还可以降低数据库DB的压力。并且,Redis相比于memcached,还提供了丰富的数据结构,并且提供RDB和AOF等持久化机制,强的一批。
当今互联网应用,有各种各样的排行榜,如电商网站的月度销量排行榜、社交APP的礼物排行榜、小程序的投票排行榜等等。Redis提供的zset数据类型能够实现这些复杂的排行榜。
比如,用户每天上传视频,获得点赞的排行榜可以这样设计:
zadd user:ranking:2021-03-03 Jay 3
zincrby user:ranking:2021-03-03 Jay 1
zrem user:ranking:2021-03-03 John
zrevrangebyrank user:ranking:2021-03-03 0 2
各大网站、APP应用经常需要计数器的功能,如短视频的播放数、电商网站的浏览数。这些播放数、浏览数一般要求实时的,每一次播放和浏览都要做加1的操作,如果并发量很大对于传统关系型数据的性能是一种挑战。Redis天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
如果一个分布式Web服务将用户的Session信息保存在各自服务器,用户刷新一次可能就需要重新登录了,这样显然有问题。实际上,可以使用Redis将用户的Session进行集中管理,每次用户更新或者查询登录信息都直接从Redis中集中获取。
几乎每个互联网公司中都使用了分布式部署,分布式服务下,就会遇到对同一个资源的并发访问的技术难题,如秒杀、下单减库存等场景。
好き/嫌い、ファン、共通の友人/お気に入り、プッシュ、プルダウンの更新などはソーシャル ネットワーキングの重要な機能です通常、ソーシャルな Web サイトへのアクセスは多く、従来のリレーショナル データはこの種のデータの保存には適していませんが、Redis が提供するデータ構造はこれらの機能を比較的簡単に実現できます。
メッセージ キューは、ActiveMQ、RabbitMQ、Kafka やその他の一般的なメッセージ キュー ミドルウェアなど、大規模な Web サイトに必須のミドルウェアです。ビジネスの分離、トラフィックのピークカット、およびリアルタイム パフォーマンスの低いサービスの非同期処理に使用されます。 Redis は、単純なメッセージ キュー システムを実装できるパブリッシュ/サブスクライブおよびブロック キュー機能を提供します。さらに、これはプロフェッショナルなメッセージ ミドルウェアと比較することはできません。
# は、数億のユーザーのシステム チェックイン、数の統計など、数億のデータを扱うシナリオで使用されます。重複のないログイン数、ユーザーがオンラインかどうかなど。 Tencent には 10 億人のユーザーがいますが、ユーザーがオンラインであるかどうかを数ミリ秒以内に確認するにはどうすればよいでしょうか?ユーザーごとにキーを作成してそれを 1 つずつ記録するなどとは決して言わないでください (必要なメモリは計算できますが、これは非常に恐ろしいことであり、同様の要件は数多くあります。ここでは適切な操作を使用してください。setbit、getbit、およびbitcount コマンドの原理は次のとおりです: Redis で十分な長さの配列を構築し、各配列要素は 0 と 1 の 2 つの値のみを持つことができ、この配列の添字インデックスはユーザー ID を表すために使用されます (数値) の場合、明らかに、これは何億もの長さの大きな配列で、添え字と要素の値 (0 と 1) を通じてメモリ システムを構築できます。
Redis はメモリベースの非リレーショナル K-V データベースです。メモリベースであるため、Redis サーバーがハングアップするとデータが失われます。データ損失を避けるために、Redis は 永続性 、つまりデータをディスクに保存します。
Redis は RDB と AOF の 2 つの永続化メカニズムを提供します。その永続的なファイルの読み込み
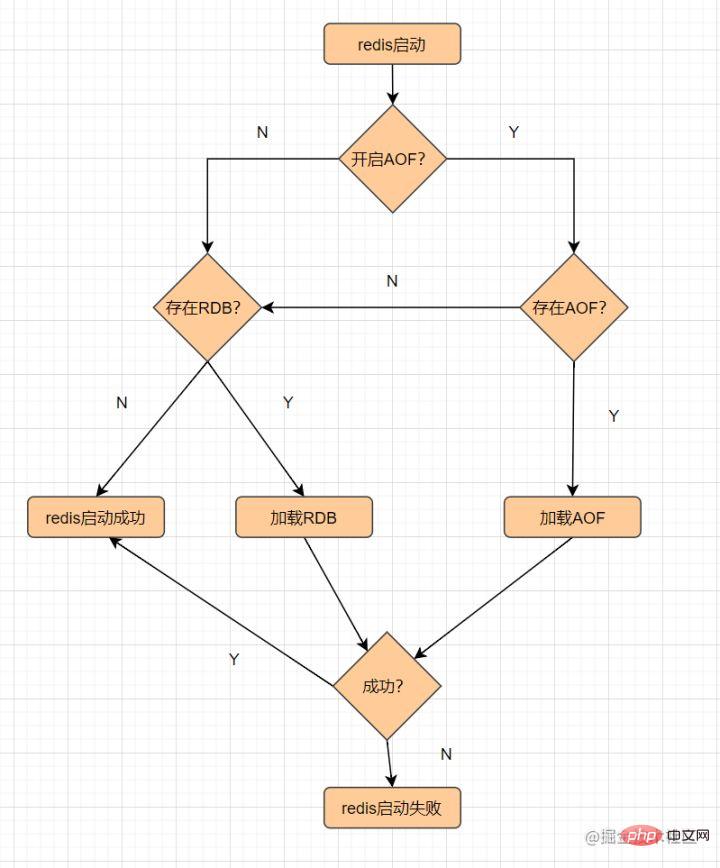
RDB はメモリ データをディスクに保存します。
スナップショットとは何ですか? このように理解すると、現時点でのデータの写真を撮り、保存できます。
RDB 永続性とは、指定された時間間隔内で指定された回数だけ実行することを指します。書き込み操作は、メモリ内のデータ セットのスナップショットをディスクに書き込みます。これは、Redis のデフォルトの永続化方法です。操作が完了すると、 dump.rdb ファイルが指定されたディレクトリに生成され、Redis が再起動されます。dump.rdb ファイルをロードしてデータを復元します。RDB トリガー メカニズムには主に次のものが含まれます。

RDB の利点
RDB の欠点
永続化、ログ形式を使用します各書き込み操作を記録し、ファイルに追加し、AOF ファイル内のコマンドを再実行して、再起動時にデータを復元します。これは主にデータの永続性の問題、最適化のリアルタイムの問題を解決します。 AOF のワークフローは次のとおりです:
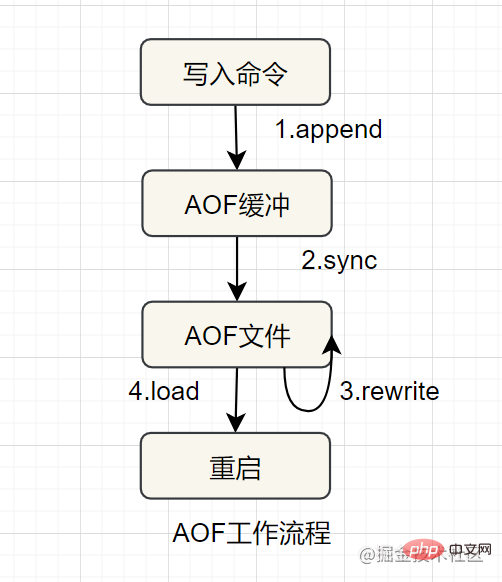
高層データの一貫性と整合性
AOF が記録するコンテンツが増えるほど、ファイルが大きくなり、データの回復が遅くなります。
という 3 つのデプロイメント モードがあります。
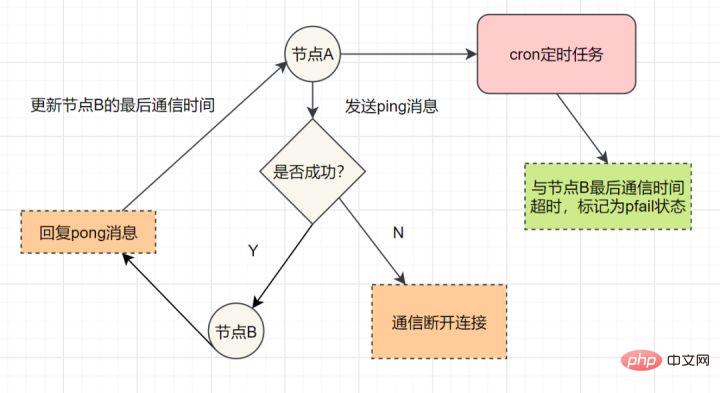
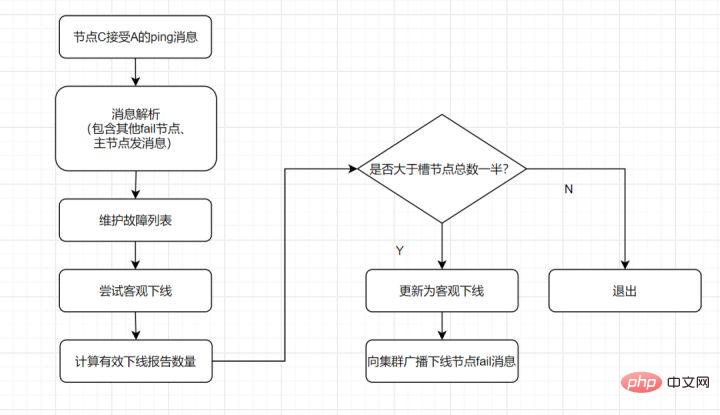
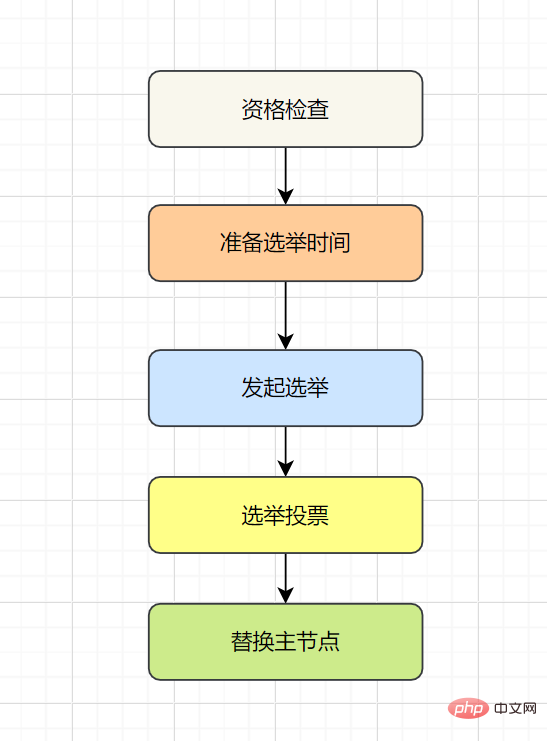
9.1 マスター/スレーブ モード です。 マスター/スレーブ レプリケーションには、完全レプリケーションと増分レプリケーションが含まれます。一般に、スレーブが初めてマスターに接続を開始する場合、または初めての接続とみなされる場合は、フル コピーが使用されます。フル コピー プロセスは次のとおりです: redis のバージョン 2.8 以降では、sync コマンドはシステム リソースを消費し、psync の方が効率的であるため、psync が sync の代わりに使用されています。 スレーブがマスターと完全に同期した後、マスター上のデータが再度更新されると、増分レプリケーションがトリガーされます。 マスター ノードでデータが増加または減少すると、 Sentinel モード: 1 つ以上の Sentinel インスタンスで構成される Sentinel システム。すべての Redis マスター ノードとスレーブ ノードを監視でき、監視対象のマスター ノードが は、オフライン マスター サーバーの下のスレーブ ノードを新しいマスター ノード に自動的にアップグレードします。ただし、センチネル プロセスが Redis ノードを監視する場合、問題が発生する可能性があります (単一点の問題 )。そのため、複数のセンチネルを使用して Redis ノードを監視することができ、各センチネル間で継続的な通信が行われます。 フェイルオーバー プロセスとは何ですか? 通常の状況では、各センチネルは、10 秒に 1 回、知っているすべてのマスターとスレーブに INFO コマンドを送信します。 マスターが Sentinel によって客観的にオフラインとしてマークされると、Sentinel がオフライン マスターのすべてのスレーブに INFO コマンドを送信する頻度が 10 秒に 1 回から 1 秒に 1 回に変更されます マスターがオフラインであることに同意する十分なセンチネルがいない場合、マスターの客観的なオフライン ステータスは削除されます。マスターがセンチネルの PING コマンドに対して有効な応答を返した場合、マスターの主観的なオフライン ステータスは削除されます。オフラインステータスが削除されます。ステータスが削除されます。 センチネル モードはマスター/スレーブ モードに基づいており、読み取りと書き込みの分離を実現します。また自動的に切り替わり、システムの可用性が高くなります。ただし、各ノードに保存されるデータは同じであるため、メモリを無駄に消費し、オンラインで拡張するのは簡単ではありません。そこで、Redis3.0 で追加され、Redis の 分散ストレージ が実装された Cluster クラスターが登場しました。データをセグメント化します。これは、オンライン拡張の問題を解決するために、 各 Redis ノードが異なるコンテンツを格納することを意味します。さらに、レプリケーションおよびフェイルオーバー機能も提供します。 各ノードはどのように通信しますか? ゴシッププロトコルを通じて! を介して他のノードと通信します。通信する場合は、外部サービスのポート番号に 10000 を加えた特別なポート番号を使用します。たとえば、ノードのポート番号が 6379 の場合、他のノードとの通信に使用するポート番号は 16379 になります。ノード間の通信には特別なバイナリ プロトコルが使用されます。 ハッシュ スロット スロット アルゴリズム 分散ストレージなので、クラスター クラスターで使用される分散アルゴリズムは ですか?いいえ、ただし ハッシュ スロット スロット アルゴリズム 。 データベース全体は 16384 個のスロット (スロット) に分割されており、Redis に入力される各キーと値のペアはキーに従ってハッシュされ、これら 16384 個のスロットに割り当てられます。使用されるハッシュ マップも比較的単純で、CRC16 アルゴリズムを使用して 16 ビット値を計算し、その後 16384 を法とします。データベース内の各キーはこれら 16384 個のスロットの 1 つに属し、クラスター内の各ノードはこれらの 16384 個のスロットを処理できます。 クラスター内の各ノードは、ハッシュ スロットの一部を担当します。たとえば、現在のクラスターにはノード A、B、および C があり、各ノードのハッシュ スロットの数 = 16384/3、 Redis Cluster クラスターでは、16384 スロットに対応するノードが正常に動作していることを確認する必要があります。場合、担当するスロットも失敗し、クラスター全体が機能しなくなります。 したがって、高可用性を確保するために、クラスター クラスターではマスター/スレーブ レプリケーションが導入され、1 つのマスター ノードが 1 つ以上のスレーブ ノードに対応します。他のマスター ノードがマスター ノード A に ping を実行するときに、マスター ノードの半分以上が A との通信がタイムアウトになると、マスター ノード A はダウンしていると見なされます。マスター ノードがダウンすると、スレーブ ノードが有効になります。 Redis の各ノードには 2 つのものがあり、1 つはスロットで、その値の範囲は 0 ~ 16383 です。もう 1 つはクラスターで、クラスター管理プラグインとして理解できます。アクセスするキーが到着すると、Redis は CRC16 アルゴリズムに基づいて 16 ビット値を取得し、結果のモジュロ 16384 を取得します。 Jiangzi の各キーは、0 ~ 16383 の番号が付いたハッシュ スロットに対応します。この値を使用して、対応するスロットに対応するノードを見つけ、アクセス操作のために対応するノードに自動的にジャンプします。 虽然数据是分开存储在不同节点上的,但是对客户端来说,整个集群Cluster,被看做一个整体。客户端端连接任意一个node,看起来跟操作单实例的Redis一样。当客户端操作的key没有被分配到正确的node节点时,Redis会返回转向指令,最后指向正确的node,这就有点像浏览器页面的302 重定向跳转。 故障转移 Redis集群实现了高可用,当集群内节点出现故障时,通过故障转移,以保证集群正常对外提供服务。 redis集群通过ping/pong消息,实现故障发现。这个环境包括主观下线和客观下线。 主观下线: 某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。 主观下线 客观下线: 指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移。 流程如下: 客观下线 故障恢复:故障发现后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,以保证集群的高可用。流程如下: 分布式锁,是控制分布式系统不同进程共同访问共享资源的一种锁的实现。秒杀下单、抢红包等等业务场景,都需要用到分布式锁,我们项目中经常使用Redis作为分布式锁。 选了Redis分布式锁的几种实现方法,大家来讨论下,看有没有啥问题哈。 如果执行完 笔者看过有开发小伙伴是这么实现分布式锁的,但是这种方案也有这些缺点: 10.3:set的扩展命令(set ex px nx)(注意可能存在的问题) 这个方案可能存在这样的问题: 在这里,判断当前线程加的锁和释放锁是不是一个原子操作。如果调用jedis.del()释放锁的时候,可能这把锁已经不属于当前客户端,会解除他人加的锁。 一般也是用lua脚本代替。lua脚本如下: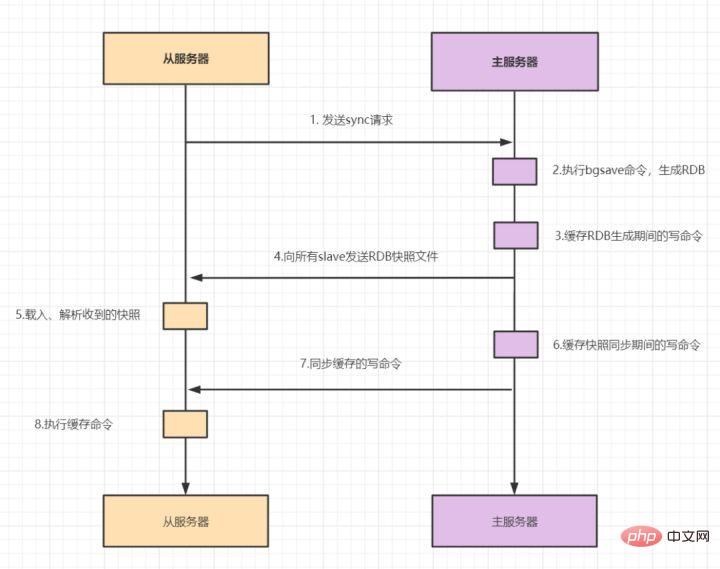
replicationFeedSalves() 関数がトリガーされます。その後マスター ノードで呼び出される各コマンドは、replicationFeedSlaves()スレーブノードと同期します。この関数を実行する前に、マスターノードはユーザーが実行したコマンドにデータ更新があるかどうかを判断し、データ更新があり、スレーブノードが空でなければ、この関数が実行されます。この関数の機能は次のとおりです。 ユーザーが実行したコマンドをすべてのスレーブ ノードに送信します。そして、スレーブ ノードに実行させます。プロセスは次のとおりです。 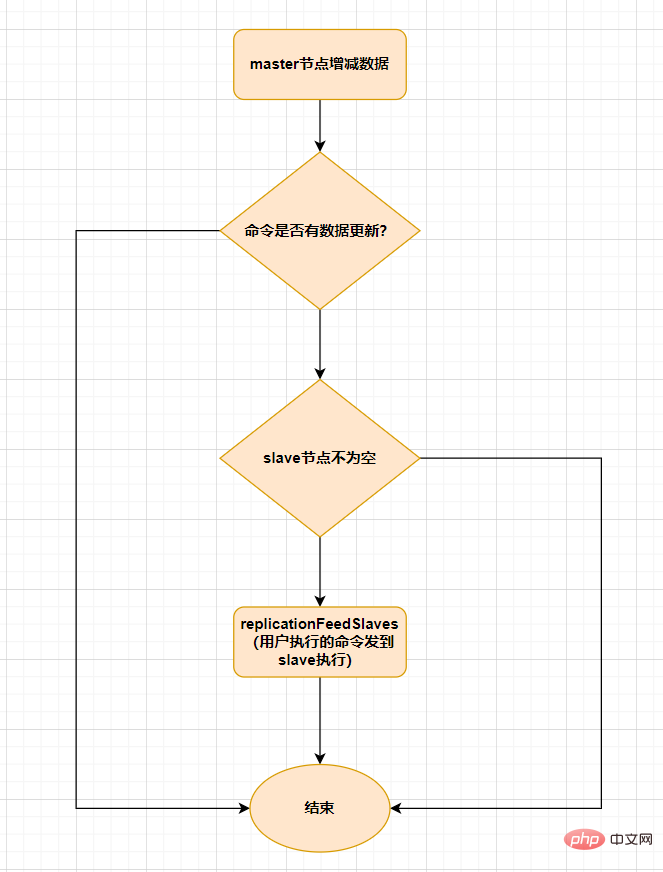
##9.2 センチネル モード
マスター/スレーブ モードでは、マスター ノードが何らかの理由でサービスを提供できなくなると、障害が発生した場合は、手動で交換する必要があります。 スレーブ ノードがマスター ノードに昇格し、アプリケーションにマスター ノードのアドレスを更新するように通知されます。明らかに、この障害処理方法は、ほとんどのビジネス シナリオでは受け入れられません。 Redis は、この問題を解決するために、2.8 以降、Redis Sentinel (Sentinel) アーキテクチャを正式に提供しています。 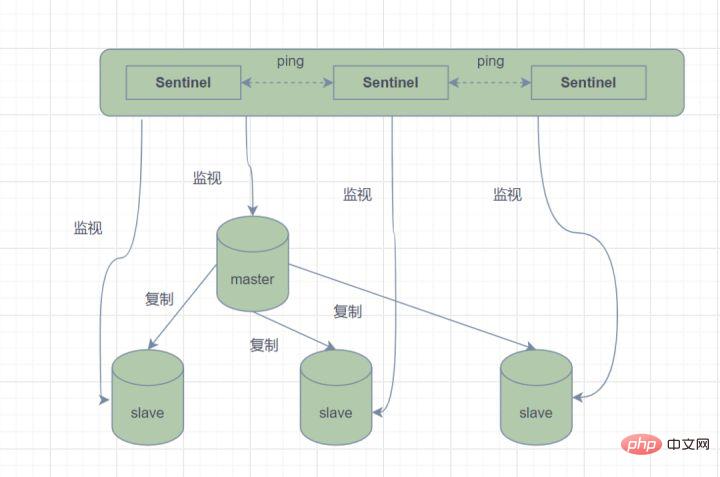
コマンドを送信し、Redis サーバーを待機します。 (マスター サーバーとスレーブ サーバーを含む) 実行ステータスの監視に戻ります。 Sentinel はマスター ノードがダウンしていることを検出し、スレーブ ノードからマスター ノードに自動的に切り替えて、他のスレーブ ノードに通知します。パブリッシュおよびサブスクライブ モードでは、構成ファイルを変更してホストを切り替えられるようにします。 Sentinel は、高可用性を実現するために相互監視も行います。
メイン サーバーがダウンし、Sentinel 1 がこの結果を最初に検出すると仮定すると、システムはSentinel 1 はメイン サーバーが利用できないと主観的に信じているだけであり、この現象は主観的なオフラインになります。後続のセンチネルもメイン サーバーが利用できないことを検出し、その数が特定の値に達すると、センチネル間で投票が行われ、投票の結果に従って 1 つのセンチネルがフェイルオーバー操作を実行します。切り替えが成功すると、各センチネルはパブリッシュ/サブスクライブ モードを使用して、監視するスレーブ サーバーをホストに切り替えます。このプロセスは、客観的オフラインと呼ばれます。このようにして、クライアントに対してすべてが透過的になります。
Sentinel の動作モードは次のとおりです: 9.3 クラスター クラスター モード
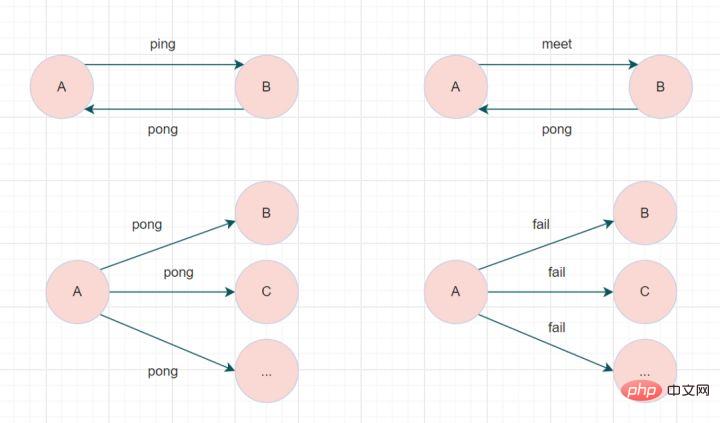
#meet メッセージ: 新しいノードに参加するよう通知します。メッセージ送信者は受信者に現在のクラスタへの参加を通知し、meet メッセージ通信が正常に完了すると、受信ノードはクラスタに参加し、定期的な ping および pong メッセージ交換を実行します。
クラスターバス(クラスターバス)
特に、各ノードは 
10. 使用过Redis分布式锁嘛?有哪些注意点呢?
10.1 命令setnx + expire分开写
if(jedis.setnx(key,lock_value) == 1){ //加锁
expire(key,100); //设置过期时间
try {
do something //业务请求
}catch(){
}
finally {
jedis.del(key); //释放锁
}
}setnx加锁,正要执行expire设置过期时间时,进程crash掉或者要重启维护了,那这个锁就“长生不老”了,别的线程永远获取不到锁啦,所以分布式锁不能这么实现。10.2 setnx + value值是过期时间
long expires = System.currentTimeMillis() + expireTime; //系统时间+设置的过期时间
String expiresStr = String.valueOf(expires);
// 如果当前锁不存在,返回加锁成功
if (jedis.setnx(key, expiresStr) == 1) {
return true;
}
// 如果锁已经存在,获取锁的过期时间
String currentValueStr = jedis.get(key);
// 如果获取到的过期时间,小于系统当前时间,表示已经过期
if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) {
// 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间(不了解redis的getSet命令的小伙伴,可以去官网看下哈)
String oldValueStr = jedis.getSet(key_resource_id, expiresStr);
if (oldValueStr != null && oldValueStr.equals(currentValueStr)) {
// 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才可以加锁
return true;
}
}
//其他情况,均返回加锁失败
return false;
}jedis.getSet(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。if(jedis.set(key, lock_value, "NX", "EX", 100s) == 1){ //加锁
try {
do something //业务处理
}catch(){
}
finally {
jedis.del(key); //释放锁
}
}10.4 set ex px nx + 校验唯一随机值,再删除
if(jedis.set(key, uni_request_id, "NX", "EX", 100s) == 1){ //加锁
try {
do something //业务处理
}catch(){
}
finally {
//判断是不是当前线程加的锁,是才释放
if (uni_request_id.equals(jedis.get(key))) {
jedis.del(key); //释放锁
}
}
}
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end;
这种方式比较不错了,一般情况下,已经可以使用这种实现方式。但是存在锁过期释放了,业务还没执行完的问题(实际上,估算个业务处理的时间,一般没啥问题了)。
分布式锁可能存在锁过期释放,业务没执行完的问题。有些小伙伴认为,稍微把锁过期时间设置长一些就可以啦。其实我们设想一下,是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。
当前开源框架Redisson就解决了这个分布式锁问题。我们一起来看下Redisson底层原理是怎样的吧:
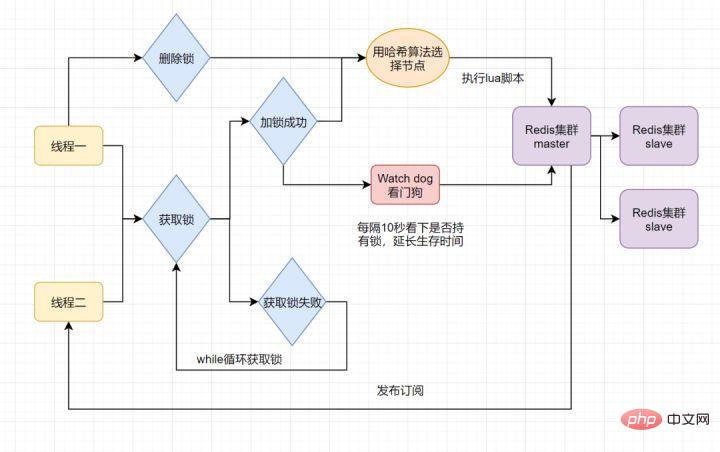
只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题。
Redis一般都是集群部署的,假设数据在主从同步过程,主节点挂了,Redis分布式锁可能会有哪些问题呢?一起来看些这个流程图:
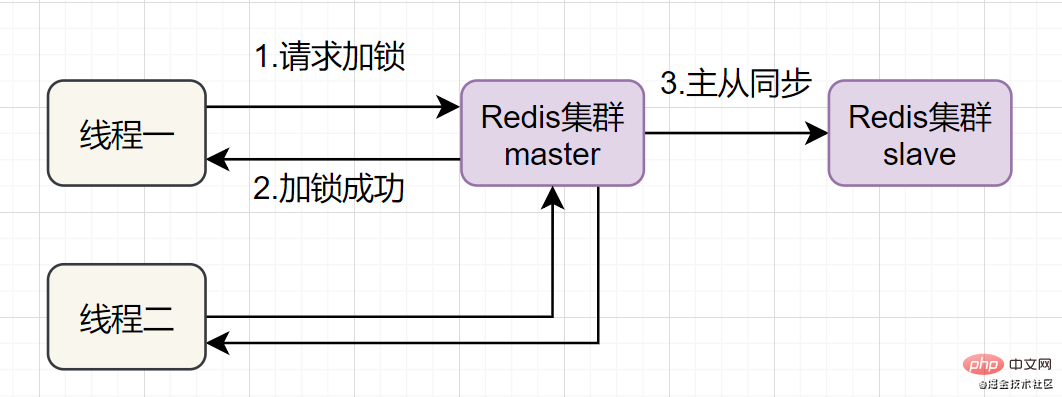
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock。Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
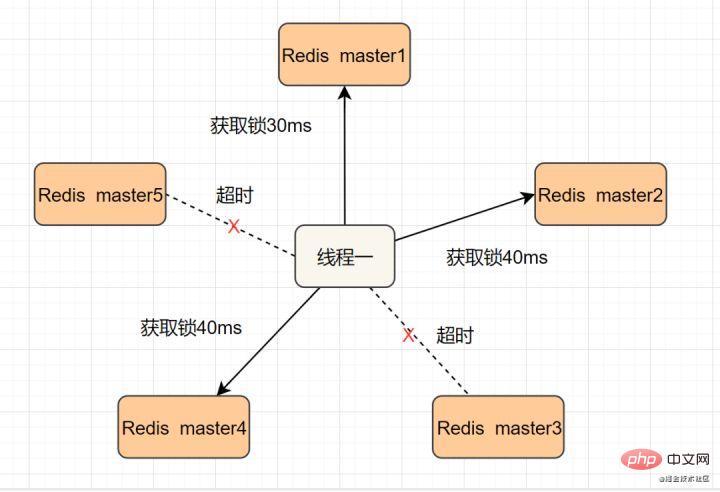
RedLock的实现步骤:如下
- 1.获取当前时间,以毫秒为单位。
- 2.按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
- 3.客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
- 如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
- 如果获取锁失败(没有在至少N/2+1个master实例取到锁,有或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)。
简化下步骤就是:
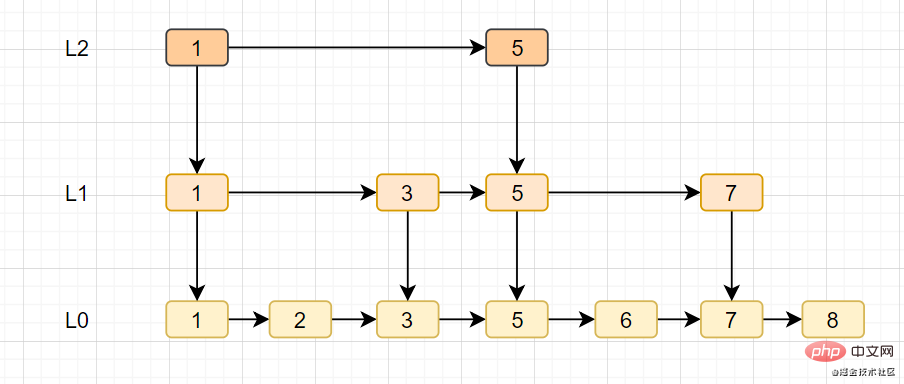
跳跃表
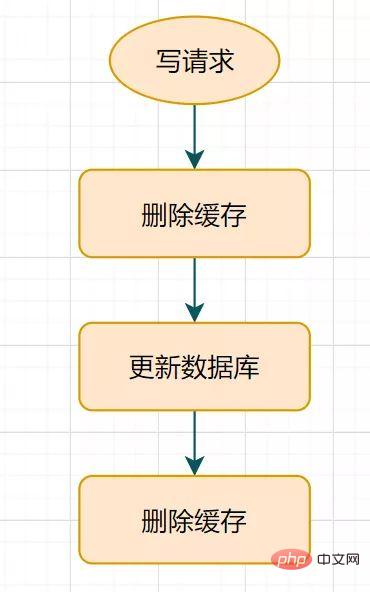
このスリープ時間 = ビジネス ロジック データの読み取りにかかる時間は数百ミリ秒です。読み取りリクエストを確実に終了させるために、書き込みリクエストは、読み取りリクエストによってもたらされる可能性のあるキャッシュされたダーティ データを削除できます。このソリューションは悪くありません。スリープ期間中 (たとえば、わずか 1 秒) に限り、ダーティ データが存在する可能性がありますが、一般の企業はそれを受け入れます。しかし、
2 番目のキャッシュの削除が失敗した場合はどうなるでしょうか キャッシュとデータベースのデータがまだ不整合である可能性がありますよね?キーに自然な有効期限を設定して、自動的に期限切れになるようにしてはどうでしょうか?企業は有効期限内にデータの不整合を受け入れる必要がありますか?それとも他にもっと良い解決策があるのでしょうか?
14.2 キャッシュ削除の再試行メカニズム遅延二重削除はキャッシュ削除の 2 番目のステップで失敗し、データの不整合が発生する可能性があるためです。このソリューションを使用して最適化できます。削除が失敗した場合は、さらに数回削除して、キャッシュの削除が確実に成功するようにします。したがって、削除キャッシュの再試行メカニズムを導入できます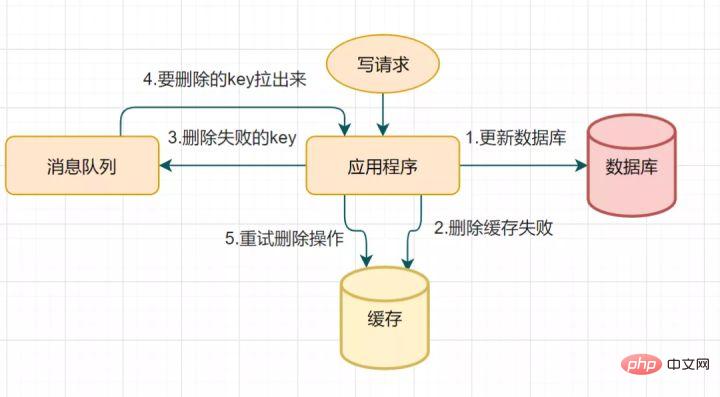 #キャッシュ削除の再試行 トライアルプロセス
#キャッシュ削除の再試行 トライアルプロセス
が発生します。実際、データベースのバイナリログを通じてキーを非同期的に削除するという方法で最適化することもできます。
#mysql を例に挙げます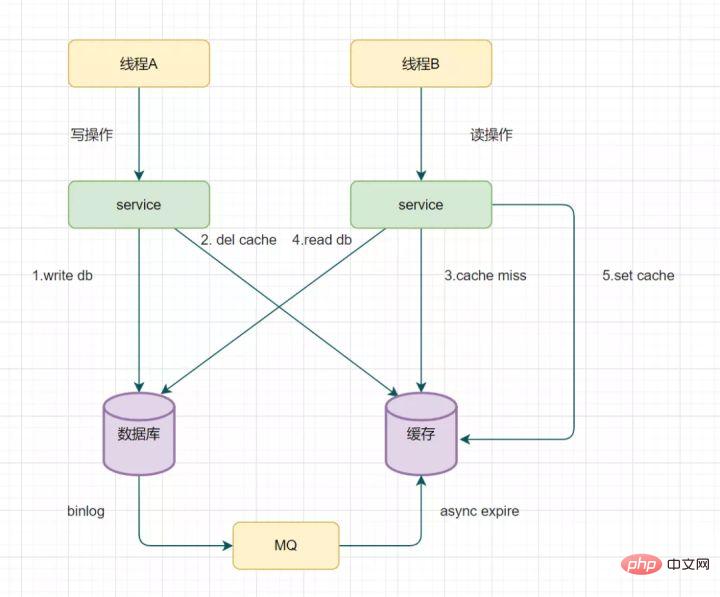
Alibaba の運河を使用して binlog ログを収集し、MQ キューに送信できます
つまり、Redis トランザクションは、キュー内の一連のコマンドを 順次、1 回限り、排他的に実行するものです。
Redis トランザクション実行のプロセスは次のとおりです。
トランザクション開始 (MULTI)コマンドエンキュー
ハッシュ テーブルの検索速度は非常に速く、Java の HashMap に似ており、O(1) の時間計算量でキーと値のペアをすばやく見つけることができます。まず、キーを通じてハッシュ値を計算し、対応するハッシュ バケットの場所を見つけて、次にエントリを見つけて、エントリ内の対応するデータを見つけます。
ハッシュ衝突とは何ですか?
ハッシュの競合: 同じハッシュ値が異なるキーを通じて計算され、結果として同じハッシュ バケットが生成されます。
ハッシュの競合を解決するために、Redis は チェーン ハッシュ を使用します。連鎖ハッシュとは、同じハッシュ バケット内の複数の要素がリンク リストに格納され、ポインタを使用して順番に接続されることを意味します。
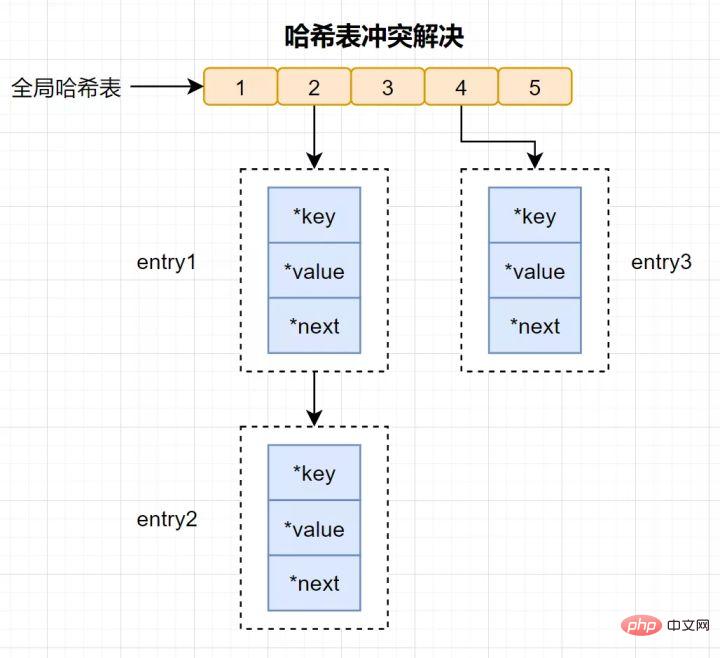
#読者の中にはまだ疑問を持つ人もいるかもしれません。ハッシュ競合チェーン上の要素は、ポインターを介して 1 つずつ検索して操作することしかできません。大量のデータがハッシュ テーブルに挿入されると、競合が多くなり、競合リンク リストが長くなり、クエリの効率が低下します。
効率を維持するために、Redis は ハッシュ テーブルに対して再ハッシュ 操作を実行します。これは、ハッシュ バケットを追加して競合を減らすことを意味します。再ハッシュをより効率的にするために、Redis はデフォルトで 2 つのグローバル ハッシュ テーブルも使用します。1 つはメイン ハッシュ テーブルと呼ばれる現在使用用で、もう 1 つは拡張用であり、バックアップ ハッシュ テーブル と呼ばれます。
18. RDB の生成中に、Redis は書き込みリクエストを同時に処理できますか?はい。Redis には、RDB を生成するための 2 つの命令 (save と bgsave) が用意されています。
シンプルな実装、高速な解析速度、優れた可読性 という利点があります。
20. ブルーム フィルターキャッシュ侵入問題に対処するには、ブルーム フィルターを使用できます。ブルームフィルターとは何ですか?
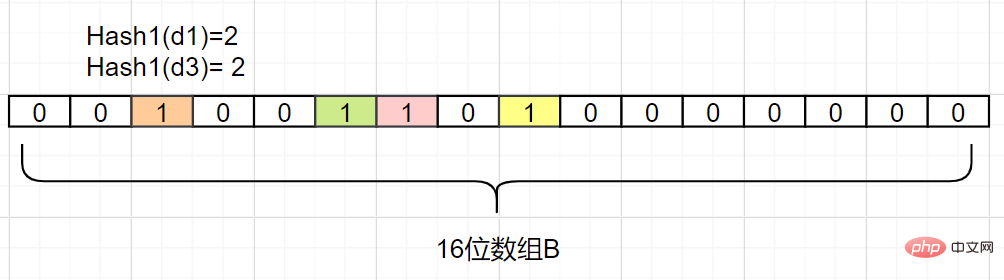
ブルーム フィルターは、スペースをほとんど占有しないデータ構造です。長いバイナリ ベクトルと一連のハッシュ マッピング関数で構成されます。要素がセット、スペース内にあるかどうかを取得するために使用されます。効率とクエリ時間は一般的なアルゴリズムよりもはるかに優れていますが、一定の誤認識率と削除の難しさがあるという欠点があります。ブルームフィルターの原理は何ですか? 集合 A があり、A には n 個の要素があるとします。 k ハッシュ ハッシュ 関数を使用して、A の各要素 を配列 B の異なる位置にビット長でマップします。これらの位置の 2 進数は両方とも 1 に設定されます。チェック対象の要素がこれらの k 個のハッシュ関数によってマッピングされ、その k 位置の 2 進数 がすべて 1 であることが判明した場合、この要素は集合 A に属する可能性が高くなります。それ以外の場合、セット A に属してはなりません。 簡単な例を見てみましょう。セット A に 3 つの要素、つまり {
d1,d2,d3} があるとします。ハッシュ関数は 1 つあり、Hash1 です。次に、A の各要素を長さ 16 ビットの配列 B にマップします。
#Hash1 (d1) = 2 と仮定して、d1 をマップします。次のように、配列 B の添え字 2 を持つグリッドを 1 に変更します。 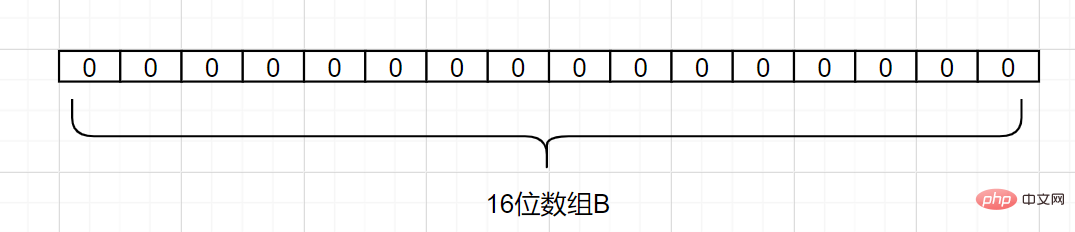
Hash1(d2) = 5 と仮定して、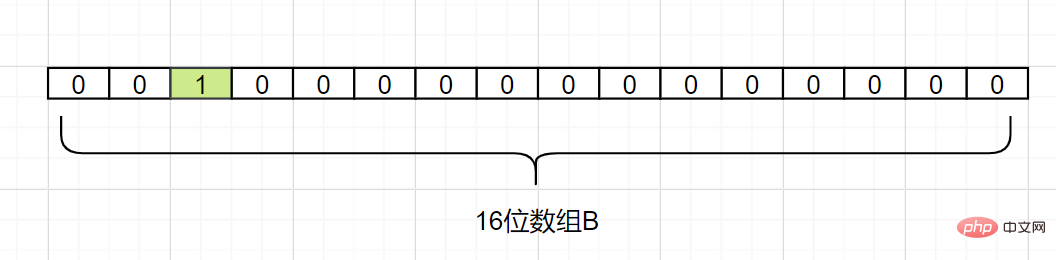 d2
d2
## 次に、ハッシュ 1 (d3) も 2 に等しいと仮定して、
d3 をマッピングします。また、添字を 2 グリッド添字 1 に設定します。 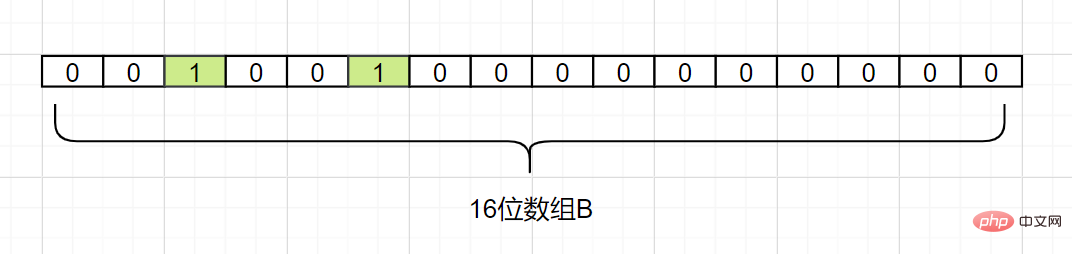
したがって、要素 dn がセット A に含まれるかどうかを確認する必要があります。Hash1 (dn) によって取得されるインデックス添字を計算するだけで済みます。それが 0 である限り、つまりこれは次のことを意味します。要素
はセット A にありません。インデックスの添字が 1 の場合はどうなりますか?その場合、要素 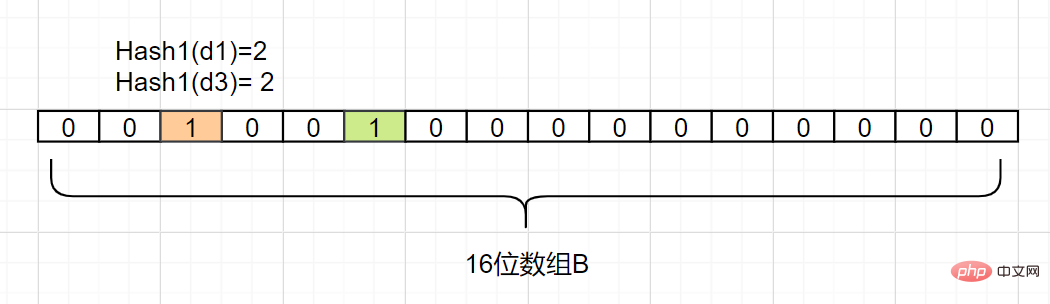 は A の要素
は A の要素
欠点 があります: ハッシュ False が存在します。衝突による陽性 、判断に誤りがあります。 このエラーを減らす方法? Hash2(d1)=6、Hash2(d3)=8 と仮定して、別の Hash2ハッシュ マッピング関数を追加します。そうでない場合は競合しません。次のように: エラーが発生した場合でも、ブルーム フィルターが store を完了していないことがわかります。 data は、一連のハッシュ マップ関数を使用して位置を計算し、バイナリ ベクトルを埋めます。 数値が非常に大きいの場合、ブルーム フィルターは非常に低いエラー率で多くのストレージ スペースを節約でき、非常にコスト効率が高くなります。 現在、ブルーム フィルターを適切に実装するオープン ソース クラス ライブラリが存在します。たとえば、Google の Guava クラス ライブラリ 、Twitter の Algebird クラス ライブラリなど、簡単に入手できるか、Redis 独自のクラス ライブラリに基づいています。ライブラリ ビットマップが独自のデザインを実装することも可能です。 プログラミング関連の知識について詳しくは、プログラミング ビデオをご覧ください。 !
以上がRedis の典型的な面接の 20 の質問と回答の要約 (共有)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



