

Vue2 diffアルゴリズムがすぐわかる(画像と文章で詳しく解説)

diff アルゴリズムは、ツリー ノードを同じレベルで比較する効率的なアルゴリズムであり、ツリーをレイヤーごとに検索して横断する必要がなくなります。それでは、diff アルゴリズムについてどれくらい知っていますか?次の記事では、vue2 の差分アルゴリズムについて詳しく説明していますので、お役に立てれば幸いです。

私は長い間 Vue 2 のソース コードを見てきました。フローの使用から TypeScript の使用に至るまで、ソース コードを開いて毎回見ていきます。毎回、beforeMount の段階である、VNode (Visual Dom Node、vdom を直接呼び出すこともできる) の生成方法についての data 初期化 部分だけを見ていました。コンポーネントを更新するときに VNode (diff) を比較する方法 () は慎重に研究されたことがありません。両端の差分アルゴリズム が使用されていることだけがわかります。この両端の開始と終了については、次のとおりです。見たことがなかったので、今回じっくり勉強するために記事を書いてみました。内容が間違っている場合は、ご指摘いただけると幸いです。ありがとうございます~
diff とは何ですか?
私の理解では、diff とは次のことを指します。 differences、つまり 古いコンテンツと新しいコンテンツの差分を計算する ; Vue の差分アルゴリズムは、 シンプルで効率的な # 方法を通じて古いコンテンツと新しいコンテンツを迅速に比較します。 ## メソッド VNode ノード配列 の違いは、最小限の dom 操作で ページ コンテンツ を更新することです。 [関連する推奨事項: vuejs ビデオ チュートリアル 、Web フロントエンド開発 ]ここには 2 つの必要な前提条件があります:
- 古い VNode 配列と新しい VNode 配列の 2 つのセットが同時に存在します
- したがって、これは通常のみ発生します data 更新時 ページ コンテンツを更新する必要がある場合、
を実行します。 なぜ VNode なのか?
上で述べたように、diff で比較されるのは実際の dom ノードではなく VNode です。なぜ VNode が使用されるのか? ほとんどの人は比較するのだと思います。それは明らかです。簡単に説明しましょう。~Vue で VNode を使用する理由は大まかに 2 つあります:
VNode はフレームワーク デザイナーとして設計されています。 JavaScript オブジェクト自体は実際の DOM ノードよりも単純なプロパティを備えており、操作中に DOM クエリを実行する必要がないため、計算中のパフォーマンス消費を大幅に最適化できます
- #VNode から実際の DOM へのリンク レンダリング プロセスは、さまざまなプラットフォーム (Web、WeChat アプレット) に応じて異なる方法で処理され、各プラットフォームに適応した実際の DOM 要素を生成できます
- diff 中にこのプロセスでは、古いノード データと新しいノード データが走査されますが、それに比べて、VNode を使用するとパフォーマンスが大幅に向上します。 プロセスのソート
tree の形式で存在し、ルート ノードはすべて
、仮想ノードが実際の dom ノードと確実に一致するようにするために、VNode はツリー構造も使用します。コンポーネントの更新時にすべての VNode ノードを比較する必要がある場合、古いノードと新しいノードの両方のセットを 徹底的に走査して比較する必要があり、これによりパフォーマンスに多大なオーバーヘッドが発生します。 ; したがって、Vue のデフォルトでは、同じレベルのノードの比較、つまり、
の場合、差分操作のみが同じレベルで実行されます。 一般的に、diff 操作は v-for ループまたは v-if/v-else、
component などで発生します。 ノード オブジェクトを動的に生成します (静的ノードは通常変更されず、比較は非常に高速です)。このプロセスは dom を更新するため、ソース コードではこのプロセスに対応するメソッド名は ## となります。 #updateChildren 、src/core/vdom/patch.ts にあります。以下に示すように: ここでは、Vue コンポーネント インスタンスの作成および更新プロセスのレビューを示します:
 最初にすべての
最初にすべての
からcreated
ステージに進み、主にデータとステータス、およびいくつかの基本的なイベントとメソッドを処理します
- beforeMount
と dom の作成およびマウント段階、つまり
その後、$mount(vm .$options.el)メソッドは、Vnode- と
mounted
の間に入ります。 (コンポーネントが更新された場合はここと同様)プロトタイプの
$mountはplatforms/web/runtime-with-compiler.tsに書き換えられ、元の実装は # にあります。 # #platforms/web/runtime/index.ts; 元の実装メソッドでは、実際にmountComponentメソッドを呼び出してrender; を実行します。 ## 以下のruntime-with-compilerは、テンプレート文字列コンパイルモジュールを追加します。これは、解析後にoptions で templateを実行します。コンパイルされ、関数内のoptions.render- mountComponent
_updateにバインドされた関数に変換され、レンダリング メソッド
updateComponent = が定義されます。 () => (vm._update(vm._render())、before構成でwatcherインスタンスをインスタンス化します (つまりrenderWatcher)、watch観察オブジェクトを定義したばかりのupdateComponentメソッドとして定義して、最初のコンポーネントのレンダリングを実行し、依存関係コレクションをトリガーします。ここで、before構成のみbeforeMount/beforeUpdateフック関数をトリガーするメソッドを設定します。これが、beforeMountステージとbeforeUpdateステージで実際の dom ノードを取得できない理由です。それは、古い dom ノードの- メソッドが
関数はまずmountComponent
patchと同じファイルで定義されており、そのコアはを読み取ることです。コンポーネント インスタンスの$el(古い dom ノード) および _vnode(古い VNode) は、_render()# によって生成されたvnodeと比較されます。 ## 関数。patch操作- を比較して、古いノードがあるかどうかを確認します
序文の内容。そうでない場合は、新しいものである必要があります。コンポーネントを作成して直接レンダリングします。古いノードがある場合は、
patchVnode、を使用して古いノードと新しいノードを比較します。古いノードと新しいノードの場合は、新しいノードには一貫性があり、両方に children子ノードがあります。次に、コア ロジックdiff -updateChildren子ノード比較 updateを入力します。このメソッドも同様です。私たちがよくdiffアルゴリズムと呼ぶもの
古いものと新しいものを比較しているため、 VNode 配列では、まず 比較 判定方法:
sameNode (a, b)、ノードの追加方法 addVnodes、ノードの削除方法 もちろん、removeVnodes が VNode に一貫性があると sameNode が判断した後でも、patchVnode は単一の新しい VNode と古い VNode の内容を詳細に比較して、内部データを更新する必要があります。 sameNode(a, b)
このメソッドの目的は 1 つあります。古いノードと新しいノードが同じかどうかを比較する。
このメソッドでは、最初に比較するのは、a と b の key が同じかどうかです。これが、Vue が
v-for、v-if、Dynamic を記録する理由です。 v-else などのノードは、ノードの一意性を識別するために key を設定する必要があります。key が存在し、同じである場合は、内部の変更が変更されたかどうかを比較するだけで済みます。通常の状況では、これにより多くの DOM 操作が削減されますが、これが設定されていない場合は、対応するノード要素が直接破棄され、再構築されます。 次に、それが非同期コンポーネントであるかどうかを比較し、ここではコンストラクターが一貫しているかどうかを比較します。 次に、比較のために 2 つの異なる状況を入力します:
- unknown
関数の全体的なプロセスは次のとおりです。次のように
addVnodes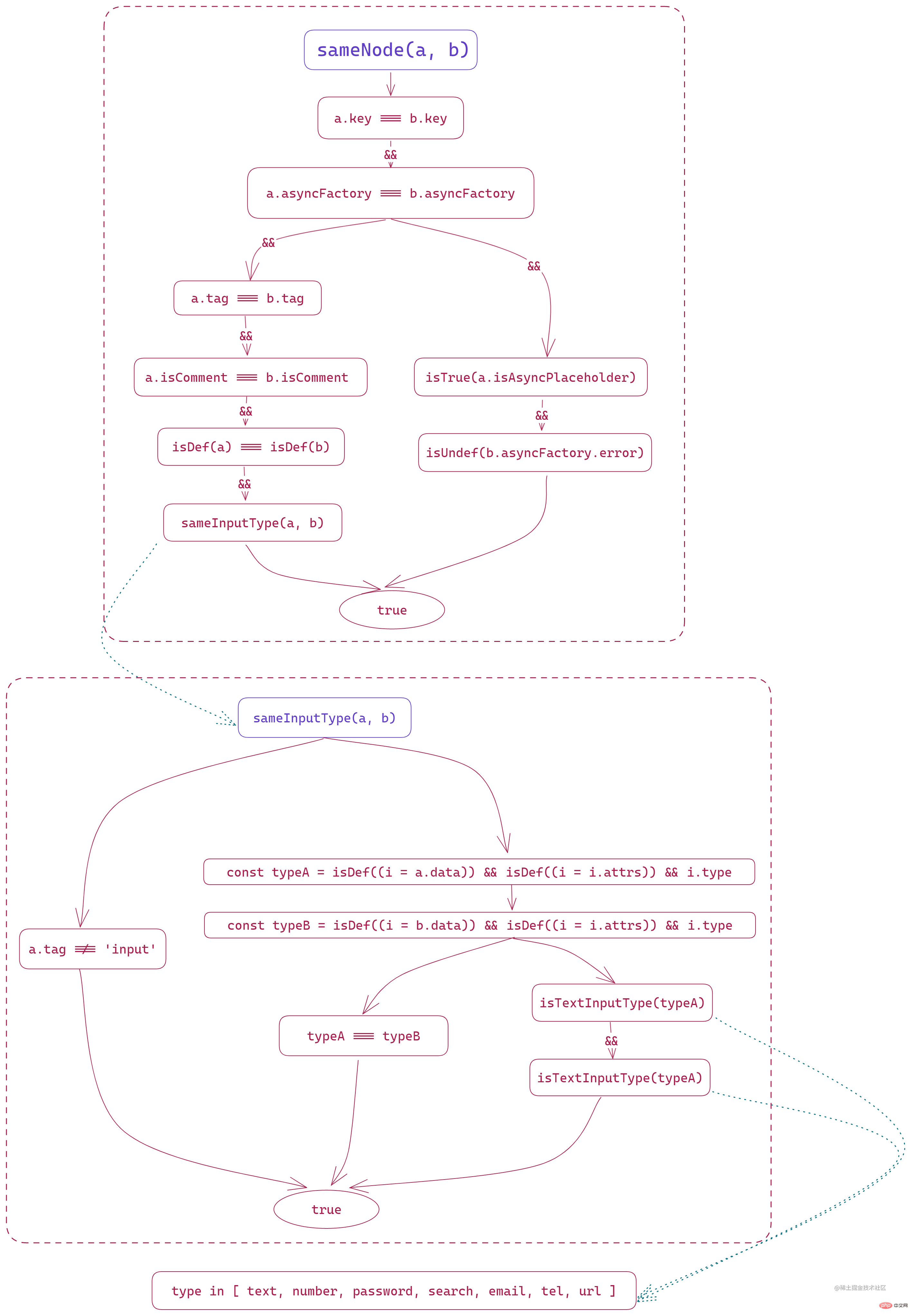
名前が示すように、新しい VNode ノードを追加します。 この関数は 6 つのパラメータを受け取ります:
parentElm現在のノード配列の親要素、
refElm 指定された位置の要素、vnodes 新しい仮想ノード配列、startIdx 新しいノード配列の挿入された要素の開始位置、endIdx 新しいノード配列の挿入された要素の終了インデックス、 insertedVnodeQueue ノード キューを挿入する必要がある仮想ノード。 内部関数は、startIdx から
位置 まで vnodes 配列を走査し、その後 # を呼び出します。 ##createElm vnodes[idx] に対応する要素を作成し、refElm の前に順番に挿入します。 もちろん、この vnodes[idx] には Component コンポーネントが存在する可能性があり、対応するコンポーネントを作成するために
も呼び出されます。実例。 <blockquote><p>全体 <code>VNode と dom は両方とも ツリー構造 であるため、同じレベルで 比較した後、より深い VNode を処理する必要があります。現在のレベルと dom 処理 。
removeVnodes
addVnodes とは対照的に、このメソッドは VNode ノードを削除するために使用されます。
このメソッドは削除のみであるため、次の 3 つのパラメータのみが必要です: vnodes 古い仮想ノード配列、startIdx 開始インデックス、endIdx インデックスの終了。
内部関数は、startIdx から endIdx 位置 まで vnodes 配列を走査します ( の場合)。 vnodes[idx ] 未定義でない場合は、tag 属性に従って処理されます:
- が存在し、それが存在することを示します。要素またはコンポーネントは、
- vnodes[idx]
の内容を再帰的に処理し、remove フックと破棄フックをトリガーする必要がありますは存在しません タグは、プレーン テキスト ノード であることを示しており、dom -
patchVnode
実際の完全な比較と dom update によるノード比較の方法。
このメソッドでは、主にnine のメイン パラメータ判定が含まれており、さまざまな処理ロジックに対応しています:
古い VNode と新しい VNode は一致しています, これは、変更がないことを意味します。 直接終了
新しい VNode に実際の dom バインディングがあり、更新する必要があるノード セットが配列の場合、現在の VNode をコピーします。 VNode はコレクションの指定された位置に移動します。
- 古いノードが
非同期コンポーネントであり、ロードが完了していない場合は、
を直接終了します。それ以外の場合は、渡します。 ハイドレート - この関数は、新しい VNode をレンダリング用の実際の dom に変換します。どちらの場合も、
は関数を終了します。
と古いものと新しいものがある場合ノードが両方とも static ノードkey - が等しいか、
isOnce が指定されている場合にノードが更新されない場合、古いノードのコンポーネント インスタンスが直接更新されます。 reused
属性があり、# で構成されている場合##prepatchおよびexit the function新しい VNode ノードに data フック関数、実行 - prepatch(oldVnode, vnode)
ノードに比較フェーズに入るように通知します。通常、このステップではパフォーマンスの最適化を構成します
フック関数が#新しい VNode にdata属性があり、ノードの子を再帰的に変更する場合 コンポーネント インスタンスの vnode がまだラベル付きで利用可能な場合、update で構成されますcbs - コールバック関数オブジェクトと
data
で構成されたupdateHook 関数新しい VNode がテキストでない場合:古いノードと新しいノードの両方がある場合は、 - children
子ノード、updateChildren メソッドを入力します。子ノードを比較するには
#古いノードに子ノードがない場合は、VNode に対応する新しい子ノードを直接作成します- 新しいノードに子ノードがない場合は、古い VNode 子ノードを削除します
子ノードがなく、古いノードにテキスト コンテンツ構成がある場合は、前のノードをクリアしますtextText - If新しい VNode には
- text
テキストがあります (これはテキスト ノードです)。古いノードと新しいノードのテキスト コンテンツを比較して一貫性があるかどうかを確認します。そうでない場合は、テキスト コンテンツの更新を続行します。最後に、新しいノードの
に設定された - 新しいノードに子ノードがない場合は、古い VNode 子ノードを削除します
- postpatch
フック関数を呼び出して、更新が完了したことをノードに通知します
#簡単に言えば、 patchVnode - は、
同じノード更新フェーズで新しいコンテンツと古いコンテンツを比較することです。変更があれば、対応するコンテンツが更新されます。子がある場合は、対応するコンテンツが更新されます。ノードを追加し、各子ノード
の核となるロジックであり、面接でよく聞かれる質問の 1 つでもあります。の比較と更新を「再帰的に」実行します。そして子ノード配列の比較と更新は diff
updateChildren メソッドの分析に入りましょう~##updateChildren
まず考えてみましょう。
新しい配列に基づいて 2 つのオブジェクト配列の要素の違いを比較します。メソッドは何ですか? 一般的に言えば、
を直接走査して、配列内の各要素の順序と差分を見つけることができます。これが 単純な diff アルゴリズム です。 つまり、
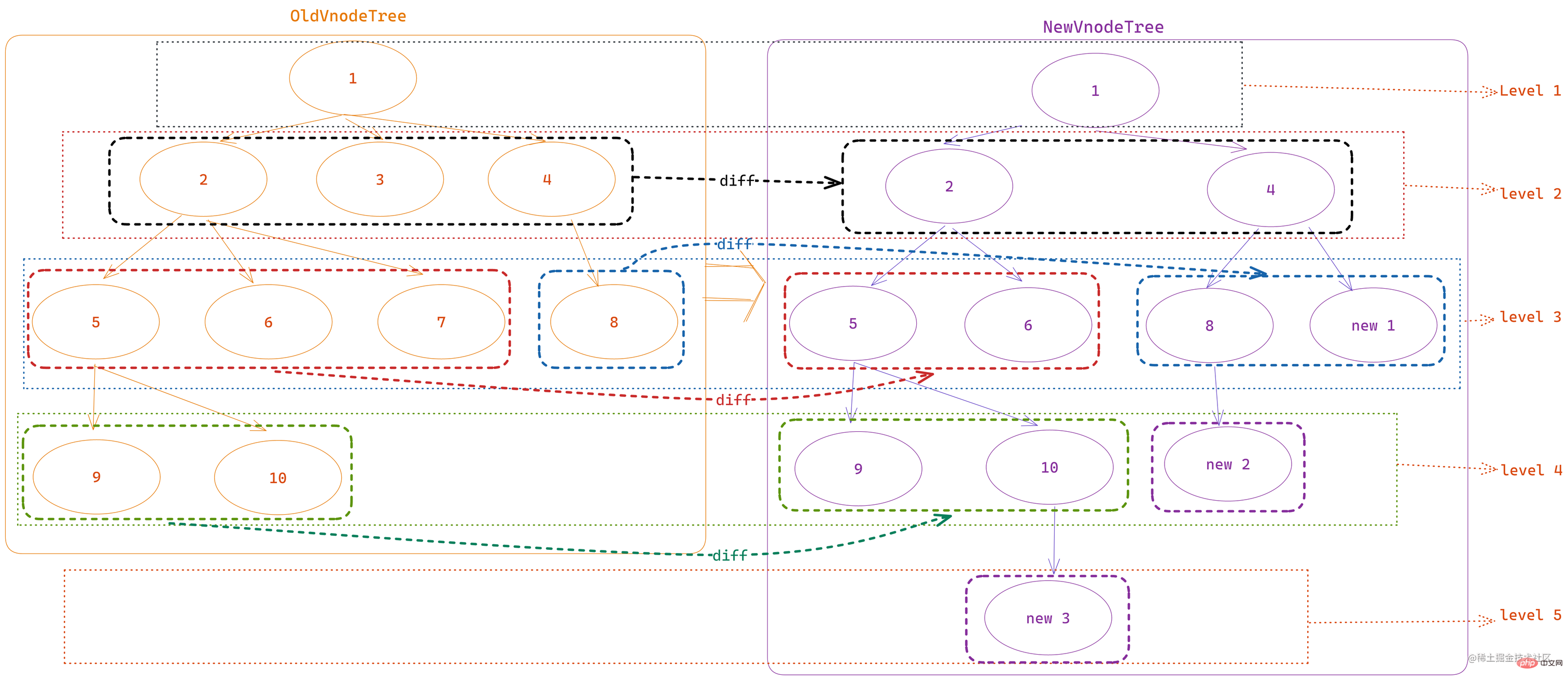
は、新しいノード配列を走査し、各サイクルで古いノード配列を再度走査して 2 つのノードが一貫しているかどうかを比較し、比較することによって新しいノードが追加されるか、削除されるか、移動されるかを決定します。結果 、プロセス全体で m*n 回の比較が必要なため、デフォルトの時間計算量はオンです。 この比較方法は、多数のノード更新中に非常にパフォーマンスを消費するため、Vue 2 はそれを最適化し、 両端は 両端から開始して中央まで横断します。比較用のアルゴリズム。 double-ended diff 最も複雑な比較状況です。 等しいかどうかを判断します。つまり、 true 1. 新しいノード状態と古いノード状態をプリセットする 初期ノード順序の古いノード配列として コピーされたソース コード (oldCh は、 ここで停止 条件は 古いノード配列または新しいノード配列のどちらかの走査が終了するとすぐに、走査 が直ちに停止します。 この時のノードの状態は以下の通りです: 2. 比較する前にvnodeが存在することを確認してください 両端比較アルゴリズム (両端差分#) に変更しました。 ##。 両端差分アルゴリズム
名前が示すように、 には 5 つの比較状況 があります:
、5番目は は
と等しいです。以下では、あらかじめ設定された状況を分析して実行します。 上記の 5 つの状況を同時に実証するために、次の新しいノード配列と古いノード配列をプリセットします。 :
(1 から 7 までの合計 7 つのノードを含む)
newChildren、ノードも 7 つありますが、古いノードと比較すると、vnode 8 が 1 つ増えています。 比較する前に、まず次のことを行う必要があります2 つのノード セットの両端インデックスを定義します let oldStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newStartIdx = 0
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
oldChildren
newCh は newChildren 次に、トラバーサル比較の stop 条件を定義します。操作while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx)

新旧を保証するため、ノード配列は比較時に無効な比較を行わず、古いノード配列 の先頭部分と末尾部分が連続しており、値が であるデータ
をまず除外します。 ###未定義###。 if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]もちろん、これはこの例には当てはまらないため、無視できます。
 3. 古いヘッドは新しいヘッドと同等です
3. 古いヘッドは新しいヘッドと同等です
開始インデックスに相当します。指すノードは 基本的に一貫性がある である場合、この時点で
patchVnode が呼び出され、2 つの vnode と 2 つの開始インデックスの詳細な比較と dom 更新が実行されます。 に移動されます。つまり: if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(
oldStartVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}
はヘッドノードの等価性と似ています。この状況は、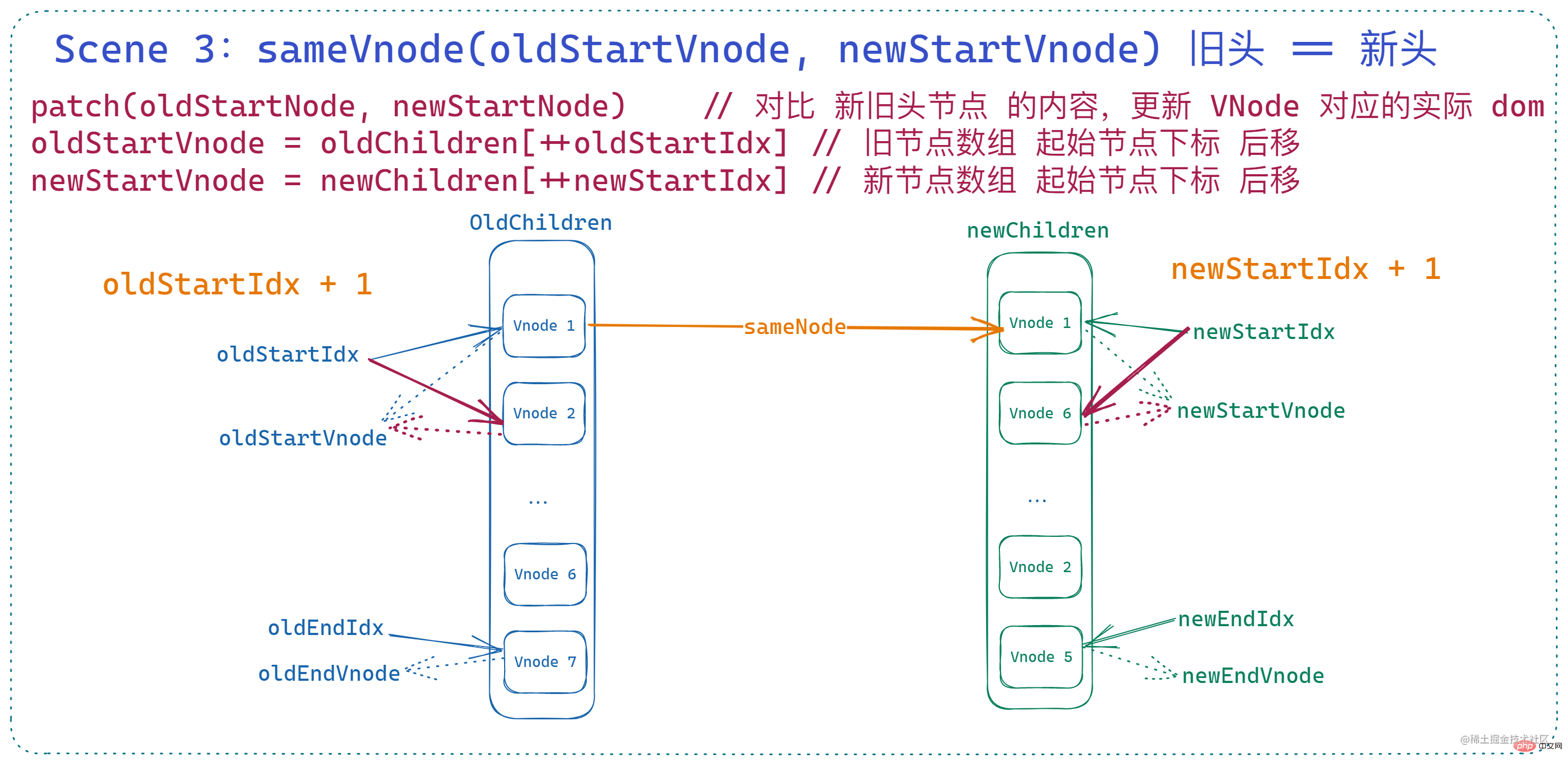 古いノード配列と新しいノード配列の最後のノードが基本的に同じであることを意味します##。このとき、
古いノード配列と新しいノード配列の最後のノードが基本的に同じであることを意味します##。このとき、
は、2 つの末尾ノードの合計を比較するためにも呼び出されます。dom を更新し、 2 つの端のインデックスを前方に移動します。 if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(
oldEndVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}ログイン後にコピー
このときのノードとインデックスの変更は図 if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(
oldEndVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}5 に示すとおりです。古いヘッドと新しいヘッドは同じです。 tail
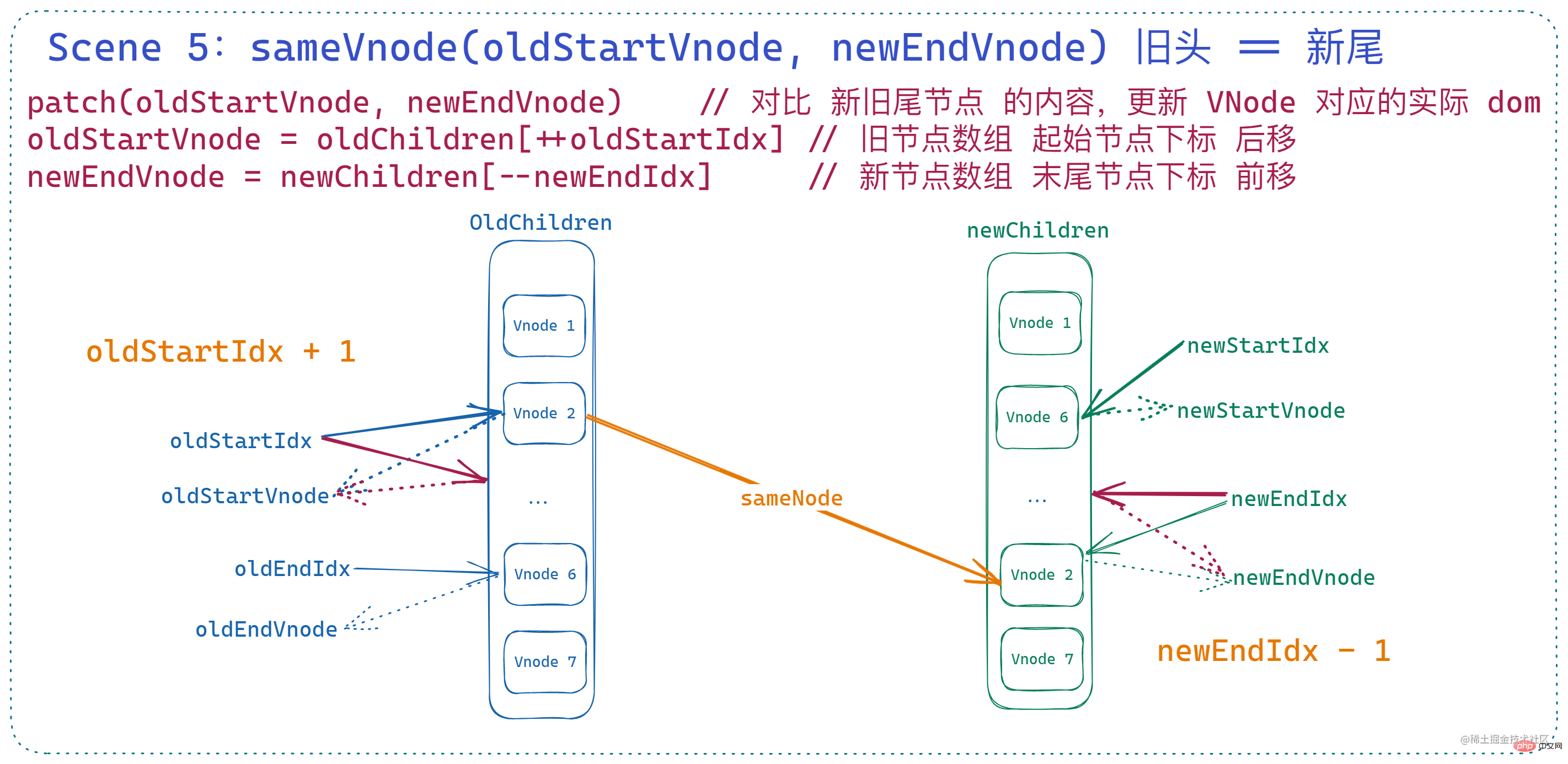
これが意味するのは、
古いノード配列の現在の開始インデックスが指す vnode は、新しいノード配列の現在の終了インデックスが指す vnode と基本的に同じであるということです. 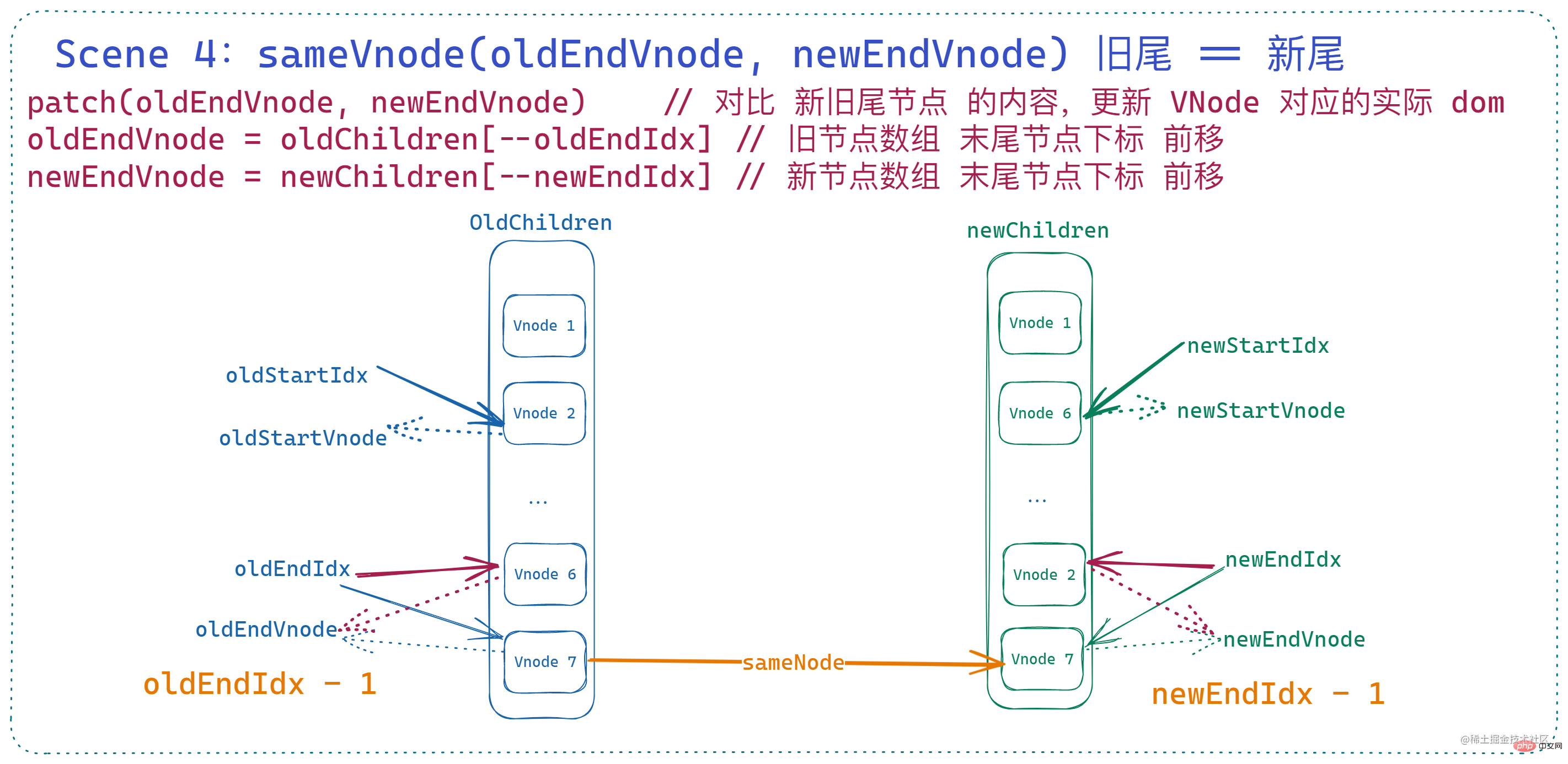 patchVnode
patchVnode
ただし、上の 2 つとの違いは、この場合、 ノードが移動されるため、
patchVnode で終了し、その後 になることです。 古いヘッド ノード を
を介して現在の古いテール ノード の後の に再挿入します。 その後、 古いノードの開始インデックスが後方に移動し、新しいノードの終了インデックスが 前方に移動します。 これを見て、なぜ 古いノード配列 がここに移動されるのかと疑問に思うかもしれません。これは、属性 elm
実際の dom ノード シーケンス を横に移動することになり、これが であることに注意してください。現在の末尾ノード (インデックスが変更されるとき) その後、これが古いノード配列の終わりであるとは限りません。
即:
if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(
oldStartVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}此时状态如下:
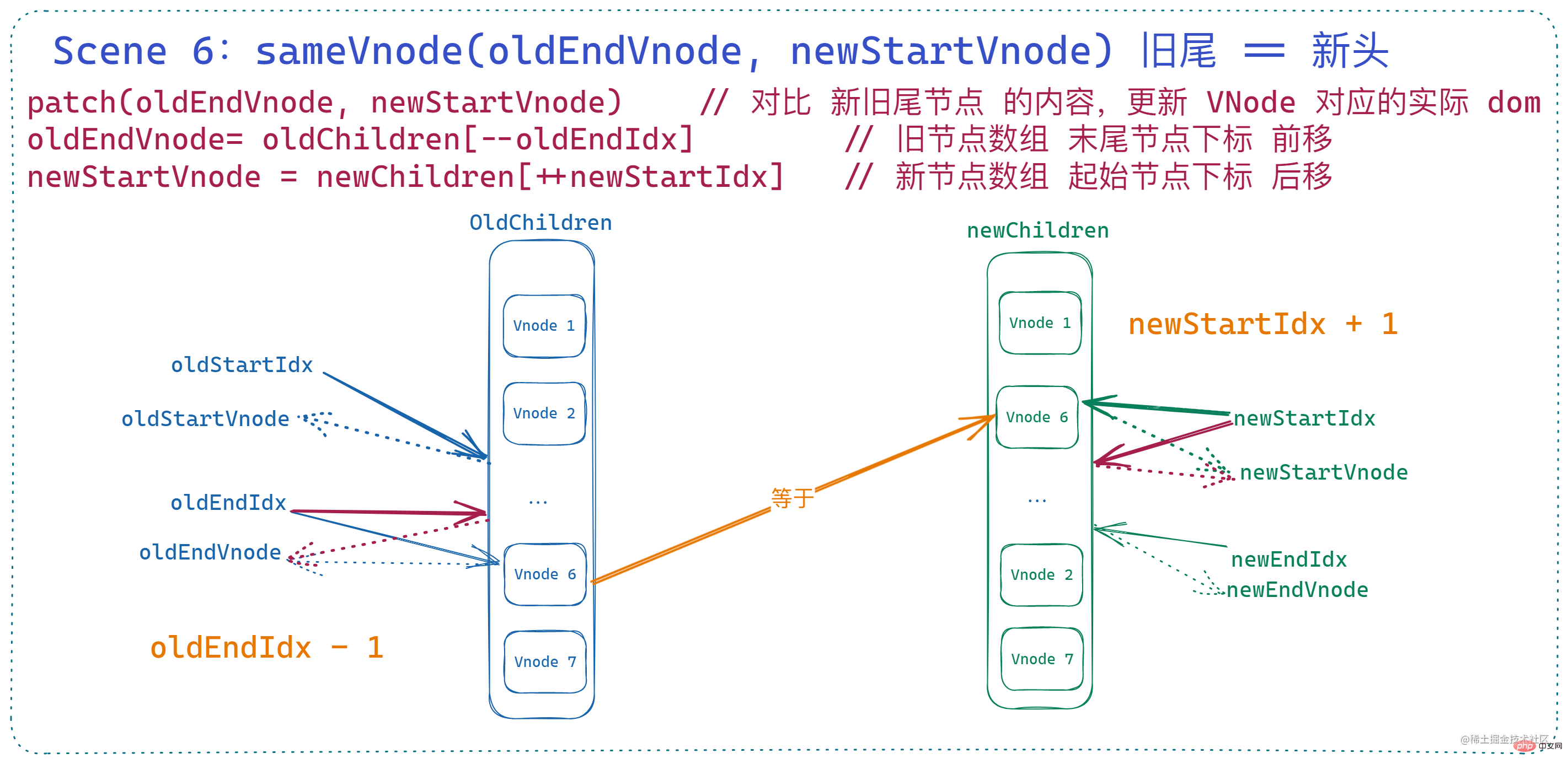
6. 旧尾等于新头
这里与上面的 旧头等于新尾 类似,一样要涉及到节点对比和移动,只是调整的索引不同。此时 旧节点的 末尾索引 前移、新节点的 起始索引 后移,当然了,这里的 dom 移动对应的 vnode 操作是 将旧节点数组的末尾索引对应的 vnode 插入到旧节点数组 起始索引对应的 vnode 之前。
if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(
oldEndVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}此时状态如下:
7. 四者均不相等
在以上情况都处理之后,就来到了四个节点互相都不相等的情况,这种情况也是 最复杂的情况。
当经过了上面几种处理之后,此时的 索引与对应的 vnode 状态如下:
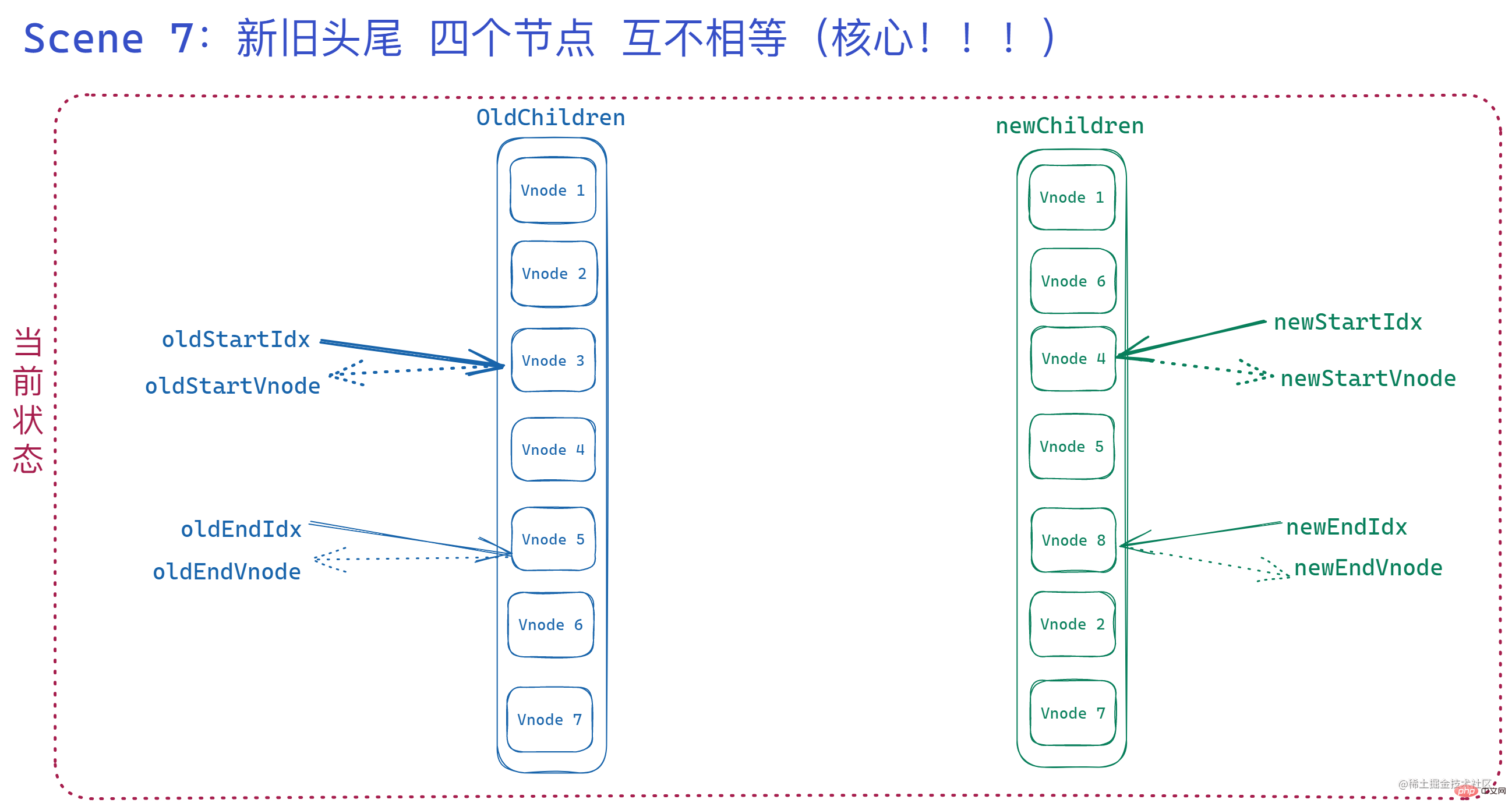
可以看到四个索引对应的 vnode 分别是:vnode 3、vnode 5、 vnode 4、vnode 8,这几个肯定是不一样的。
此时也就意味着 双端对比结束。
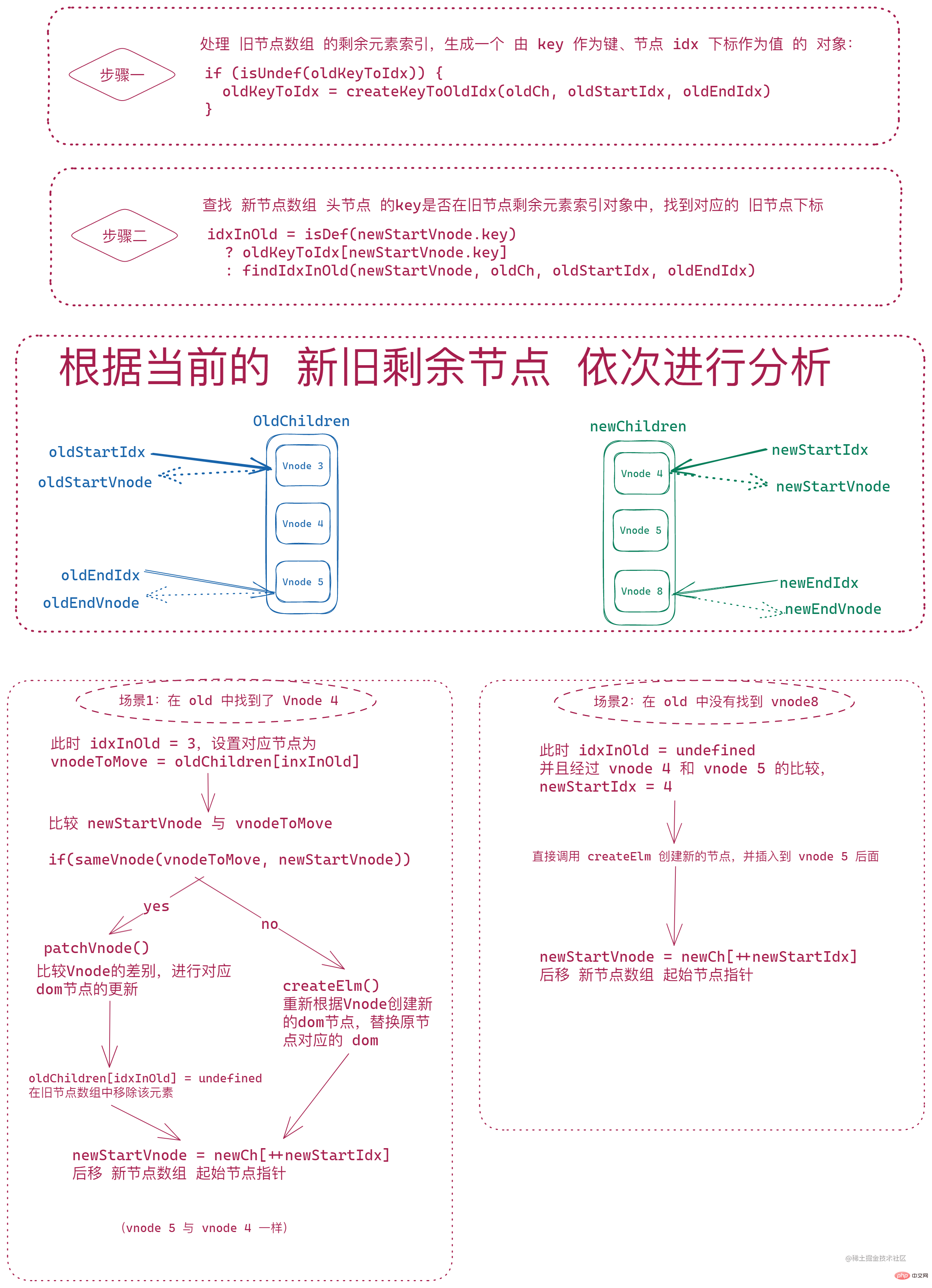
后面的节点对比则是 将旧节点数组剩余的 vnode (oldStartIdx 到 oldEndIdx 之间的节点)进行一次遍历,生成由 vnode.key 作为键,idx 索引作为值的对象 oldKeyToIdx,然后 遍历新节点数组的剩余 vnode(newStartIdx 到 newEndIdx 之间的节点),根据新的节点的 key 在 oldKeyToIdx 进行查找。此时的每个新节点的查找结果只有两种情况:
找到了对应的索引,那么会通过
sameVNode对两个节点进行对比:- 相同节点,调用
patchVnode进行深层对比和 dom 更新,将oldKeyToIdx中对应的索引idxInOld对应的节点插入到oldStartIdx对应的 vnode 之前;并且,这里会将 旧节点数组中idxInOld对应的元素设置为undefined - 不同节点,则调用
createElm重新创建一个新的 dom 节点并将 新的 vnode 插入到对应的位置
- 相同节点,调用
没有找到对应的索引,则直接
createElm创建新的 dom 节点并将新的 vnode 插入到对应位置
注:这里 只有找到了旧节点并且新旧节点一样才会将旧节点数组中
idxInOld中的元素置为undefined。
最后,会将 新节点数组的 起始索引 向后移动。
if (isUndef(oldKeyToIdx)) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
// New element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(
vnodeToMove,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
oldCh[idxInOld] = undefined
canMove &&
nodeOps.insertBefore(
parentElm,
vnodeToMove.elm,
oldStartVnode.elm
)
} else {
// same key but different element. treat as new element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
)
}
}
newStartVnode = newCh[++newStartIdx]
}大致逻辑如下图:
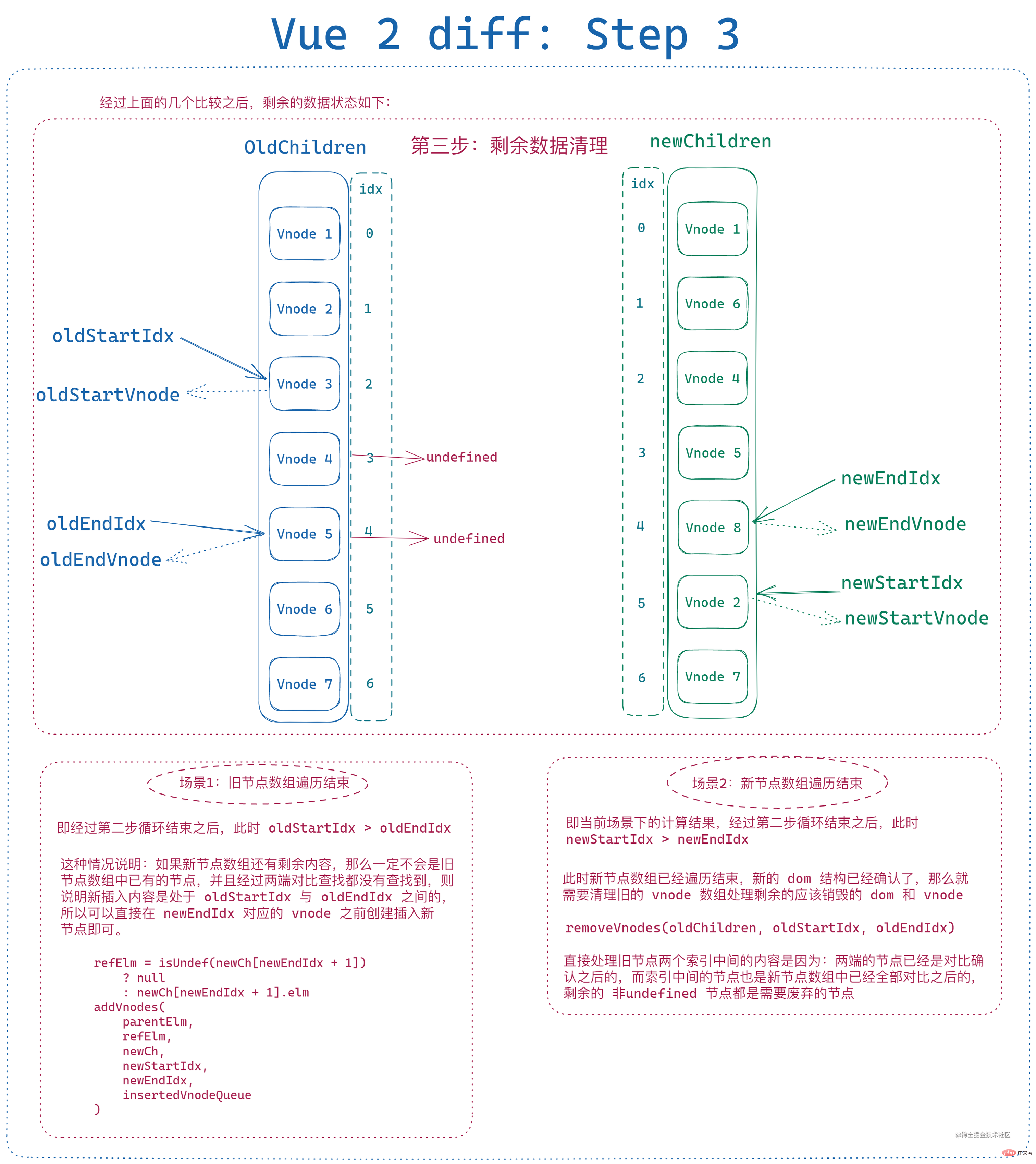
剩余未比较元素处理
经过上面的处理之后,根据判断条件也不难看出,遍历结束之后 新旧节点数组都刚好没有剩余元素 是很难出现的,当且仅当遍历过程中每次新头尾节点总能和旧头尾节点中总能有两个新旧节点相同时才会发生,只要有一个节点发生改变或者顺序发生大幅调整,最后 都会有一个节点数组起始索引和末尾索引无法闭合。
那么此时就需要对剩余元素进行处理:
- 旧节点数组遍历结束、新节点数组仍有剩余,则遍历新节点数组剩余数据,分别创建节点并插入到旧末尾索引对应节点之前
- 新节点数组遍历结束、旧节点数组仍有剩余,则遍历旧节点数组剩余数据,分别从节点数组和 dom 树中移除
即:
小结
Vue 2 的 diff 算法相对于简单 diff 算法来说,通过 双端对比与生成索引 map 两种方式 减少了简单算法中的多次循环操作,新旧数组均只需要进行一次遍历即可将所有节点进行对比。
両端の比較では 4 つの比較と移動がそれぞれ実行され、パフォーマンスは最適な解決策ではないため、Vue 3 では Longest Increasing Subsequence メソッドを導入して、両端の比較を置き換えました。 . ですが、残りは引き続き空間拡張を使用して、インデックス マップに変換することで時間の複雑さを軽減し、それによってコンピューティング パフォーマンスをさらに向上させます。
もちろん、vnode に対応する elm の実際の dom ノードはこの記事の図には示されていません。両者のモバイルの関係は誤解を招く可能性があります。「Vue.js」と合わせて読むことをお勧めします。設計と実装」。
全体的なプロセスは次のとおりです:
(学習ビデオ共有: vuejs 入門チュートリアル , プログラミングの基本ビデオ )
以上がVue2 diffアルゴリズムがすぐわかる(画像と文章で詳しく解説)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7540
7540
 15
1380
52
83
11
21
86
15
1380
52
83
11
21
86

 VUEのボタンに関数を追加する方法
Apr 08, 2025 am 08:51 AM
VUEのボタンに関数を追加する方法
Apr 08, 2025 am 08:51 AM
HTMLテンプレートのボタンをメソッドにバインドすることにより、VUEボタンに関数を追加できます。 VUEインスタンスでメソッドを定義し、関数ロジックを書き込みます。
 VueでBootstrapの使用方法
Apr 07, 2025 pm 11:33 PM
VueでBootstrapの使用方法
Apr 07, 2025 pm 11:33 PM
vue.jsでBootstrapを使用すると、5つのステップに分かれています。ブートストラップをインストールします。 main.jsにブートストラップをインポートしますブートストラップコンポーネントをテンプレートで直接使用します。オプション:カスタムスタイル。オプション:プラグインを使用します。
 vue.jsでJSファイルを参照する方法
Apr 07, 2025 pm 11:27 PM
vue.jsでJSファイルを参照する方法
Apr 07, 2025 pm 11:27 PM
vue.jsでJSファイルを参照するには3つの方法があります。タグ;; mounted()ライフサイクルフックを使用した動的インポート。 Vuex State Management Libraryを介してインポートします。
 VueでWatchの使用方法
Apr 07, 2025 pm 11:36 PM
VueでWatchの使用方法
Apr 07, 2025 pm 11:36 PM
Vue.jsの監視オプションにより、開発者は特定のデータの変更をリッスンできます。データが変更されたら、Watchはコールバック関数をトリガーして更新ビューまたはその他のタスクを実行します。その構成オプションには、すぐにコールバックを実行するかどうかを指定する即時と、オブジェクトまたは配列の変更を再帰的に聴くかどうかを指定するDEEPが含まれます。
 Vueによる前のページに戻る方法
Apr 07, 2025 pm 11:30 PM
Vueによる前のページに戻る方法
Apr 07, 2025 pm 11:30 PM
vue.jsには、前のページに戻る4つの方法があります。$ router.go(-1)$ router.back()outes&lt; router-link to =&quot;/&quot; Component Window.history.back()、およびメソッド選択はシーンに依存します。
 Vue Multi-Page開発とはどういう意味ですか?
Apr 07, 2025 pm 11:57 PM
Vue Multi-Page開発とはどういう意味ですか?
Apr 07, 2025 pm 11:57 PM
VUEマルチページ開発は、VUE.JSフレームワークを使用してアプリケーションを構築する方法です。アプリケーションは別々のページに分割されます。コードメンテナンス:アプリケーションを複数のページに分割すると、コードの管理とメンテナンスが容易になります。モジュール性:各ページは、簡単に再利用および交換するための別のモジュールとして使用できます。簡単なルーティング:ページ間のナビゲーションは、単純なルーティング構成を介して管理できます。 SEOの最適化:各ページには独自のURLがあり、SEOに役立ちます。
 Vueのバージョンを照会する方法
Apr 07, 2025 pm 11:24 PM
Vueのバージョンを照会する方法
Apr 07, 2025 pm 11:24 PM
Vue Devtoolsを使用してブラウザのコンソールでVueタブを表示することにより、Vueバージョンを照会できます。 NPMを使用して、「NPM List -G Vue」コマンドを実行します。 package.jsonファイルの「依存関係」オブジェクトでVueアイテムを見つけます。 Vue CLIプロジェクトの場合、「Vue -Version」コマンドを実行します。 &lt; script&gt;でバージョン情報を確認してくださいVueファイルを参照するHTMLファイルにタグを付けます。
 VueのDivにジャンプする方法
Apr 08, 2025 am 09:18 AM
VueのDivにジャンプする方法
Apr 08, 2025 am 09:18 AM
VUEにDIV要素をジャンプするには、VUEルーターを使用してルーターリンクコンポーネントを追加するには、2つの方法があります。 @clickイベントリスナーを追加して、これを呼び出します。$ router.push()メソッドをジャンプします。
