

[編集して共有] ノードモジュールに関するインタビューの質問と回答 (コレクション)

この記事では、ノード モジュールに関する面接の質問をいくつか紹介します。一般的なモジュールの問題の落とし穴をすぐに理解し、面接に合格するのに役立つことを願っています。
![[編集して共有] ノードモジュールに関するインタビューの質問と回答 (コレクション)](https://img.php.cn/upload/article/000/000/024/641d8cf83fe1a283.jpg)
ホット アップデート
プロセス js/ を再起動せずにノードをホット アップデートする方法json ファイル? この問題自体に問題があるのでしょうか?
node.js のキャッシュとホット アップデートは密接な関係にあります。まずは Node.js のモジュールの仕組みを簡単に見てみましょう (下の図) hyj1991大神)から来ています。
簡単に言うと、モジュール A を要求した後、モジュール A はキャッシュに置かれ、2 回目の取得時にキャッシュが取り出されるため、ファイルを変更しただけではファイルは削除されません。再ロード中であるため、ファイルを再ロードできるようにキャッシュを削除する必要があります。 [関連チュートリアルの推奨事項: nodejs ビデオ チュートリアル 、プログラミング教育 ]

簡単に言えば、親モジュール A がサブモジュール B を導入します。手順は次のとおりです。
- サブモジュール B のキャッシュが存在するかどうかを確認します
- 存在しない場合は、B
- B を追加します。モジュール キャッシュ
require.cacheへ (key はモジュール B のフル パス) - モジュール B の参照を親モジュール A
# のchildren 配列に追加します。
##存在する場合は、親モジュール A の - B を追加します。モジュール キャッシュ
- children
配列に B が存在するかどうかを確認します。存在しない場合は、B モジュール参照を追加します。
モジュールのメカニズム
モジュールのメカニズムは非常に一般的な問題ですが、次に、commonjs の実装原理が何であるかを理解する必要があります。 モジュールの仕組みの詳細な分析については、以前に書いた記事を参照してください。NodeJS の面接の難しい質問に何問正解できますか? , commonjsのモジュールの仕組みについては冒頭で説明しました。
モジュールのメカニズムに関する以前の説明をここに貼り付けましょう:1.1 ノード内のモジュールが何であるかを紹介してください
ノード内の各ファイルmodule はオブジェクトであり、その定義は次のとおりです:function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
this.filename = null;
this.loaded = false;
this.children = [];
}
module.exports = Module;var module = new Module(filename, parent);
1.2 require
のモジュール読み込みメカニズムを紹介してくださいこの質問は、面接官の Node モジュール メカニズムの理解を基本的に理解することができます。基本的に、それはインタビューで言及されました 1. 最初にモジュールのパスを計算します 2. モジュールがキャッシュ内にある場合は、キャッシュから削除します。 3. モジュールをロードする 4. モジュールのexports属性を出力するだけです// require 其实内部调用 Module._load 方法
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
/********************************这里注意了**************************/
// 第三步:生成模块实例,存入缓存
// 这里的Module就是我们上面的1.1定义的Module
var module = new Module(filename, parent);
Module._cache[filename] = module;
/********************************这里注意了**************************/
// 第四步:加载模块
// 下面的module.load实际上是Module原型上有一个方法叫Module.prototype.load
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};1.3 モジュールをロードするときに、各モジュールに __dirname 属性と __filename 属性があるのはなぜですか?新しいモジュールを作成します。パート 1.1 にはこれら 2 つの属性がないことがわかります。では、これら 2 つの属性はどこから来たのでしょうか?// 上面(1.2部分)的第四步module.load(filename)
// 这一步,module模块相当于被包装了,包装形式如下
// 加载js模块,相当于下面的代码(加载node模块和json模块逻辑不一样)
(function (exports, require, module, __filename, __dirname) {
// 模块源码
// 假如模块代码如下
var math = require('math');
exports.area = function(radius){
return Math.PI * radius * radius
}
});ログイン後にコピー
つまり、__filename が各モジュール、__dirname に渡されます。パラメータの場合、これら 2 つのパラメータはモジュール自体にはなく、外部から渡されます。// 上面(1.2部分)的第四步module.load(filename)
// 这一步,module模块相当于被包装了,包装形式如下
// 加载js模块,相当于下面的代码(加载node模块和json模块逻辑不一样)
(function (exports, require, module, __filename, __dirname) {
// 模块源码
// 假如模块代码如下
var math = require('math');
exports.area = function(radius){
return Math.PI * radius * radius
}
});1.4 ノードがモジュールをエクスポートするには 2 つの方法があることがわかっています。1 つは、exports.xxx=xxx です。とモジュールの間に違いはありますか? .exports={}
exports は実際には module.exports です 実際、問題 1.3 のコードですでに問題が説明されています。次に、より明確になることを願って、マスター Liao Xuefeng の説明を引用します。Node 環境では、モジュール内の変数をエクスポートする 2 つの方法があることがよくわかります:
方法 1: module.exports に値を割り当てます: // hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
module.exports = {
hello: hello,
greet: greet
};ログイン後にコピー方法 2: エクスポートを直接使用する :
// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
module.exports = {
hello: hello,
greet: greet
};// hello.js
function hello() {
console.log('Hello, world!');
}
function greet(name) {
console.log('Hello, ' + name + '!');
}
function hello() {
console.log('Hello, world!');
}
exports.hello = hello;
exports.greet = greet;ただし、エクスポートに値を直接割り当てることはできません:
// 代码可以执行,但是模块并没有输出任何变量:
exports = {
hello: hello,
greet: greet
};上記の記述が非常に混乱している場合でも、心配しないでください。ノードのロードメカニズム:
首先,Node会把整个待加载的hello.js文件放入一个包装函数load中执行。在执行这个load()函数前,Node准备好了module变量:
var module = {
id: 'hello',
exports: {}
};
load()函数最终返回module.exports:
var load = function (exports, module) {
// hello.js的文件内容
...
// load函数返回:
return module.exports;
};
var exportes = load(module.exports, module);也就是说,默认情况下,Node准备的exports变量和module.exports变量实际上是同一个变量,并且初始化为空对象{},于是,我们可以写:
exports.foo = function () { return 'foo'; };
exports.bar = function () { return 'bar'; };也可以写:
module.exports.foo = function () { return 'foo'; };
module.exports.bar = function () { return 'bar'; };换句话说,Node默认给你准备了一个空对象{},这样你可以直接往里面加东西。
但是,如果我们要输出的是一个函数或数组,那么,只能给module.exports赋值:
module.exports = function () { return 'foo'; };给exports赋值是无效的,因为赋值后,module.exports仍然是空对象{}。
结论 如果要输出一个键值对象{},可以利用exports这个已存在的空对象{},并继续在上面添加新的键值;
如果要输出一个函数或数组,必须直接对module.exports对象赋值。
所以我们可以得出结论:直接对module.exports赋值,可以应对任何情况:
module.exports = {
foo: function () { return 'foo'; }
};或者:
module.exports = function () { return 'foo'; };最终,我们强烈建议使用module.exports = xxx的方式来输出模块变量,这样,你只需要记忆一种方法。
上下文 Vm模块
通过上面的问题,面试官又抛出一个问题,每个require的js文件,作用域如何保证独立呢?
其实每一个require的js文件,本身就是一个字符串, 文件是不是字符串嘛,所以我们需要一种机制能够把字符串编译为可以运行的javascript语言。
实际上从上面的讨论我们知道,require会把引入的js包裹在function中,所以它的作用域天然就是独立的。
接着讲本章的vm模块,vm模块和function都可以建立自己独立的作用域,并且vm、function、eval还可以把字符串当做目标代码执行。所以这三者的区别就需要面试者了解。
- eval
- Function
- vm
eval、Function,在执行目标代码时,会有一个最大的问题就是安全性,无论如何目标代码不能影响我正常的服务,也就是说,这个执行环境得是一个沙盒环境,而eval显然并不具备这个能力。如果需要一段不信任的代码放任它执行,那么不光服务,整个服务器的文件系统、数据库都暴露了。甚至目标代码会修改eval函数原型,埋入陷阱等等。
function也有一个安全问题就是可以修改全局变量,所有这种new Function的代码执行时的作用域为全局作用域,不论它的在哪个地方调用的,它访问的都是全局变量。
所以也有一定的安全隐患,接下来我们的主角vm模块登场。
安全性
使用vm的模块会比eval更为安全,因为vm模块运行的脚本完全无权访问外部作用域(或自行设置一个有限的作用域)。 脚本仍在同一进程中运行,因此为了获得最佳安全性。当然你可以给上下文传入一些通用的API方便开发:
vm.runInNewContext(`
const util = require(‘util’);
console.log(util);
`, {
require: require,
console: console
});此外,另一个开源库vm2针对vm的安全性等方面做了更多的提升,vm2。避免了一些运行脚本有可能“逃出”沙盒运行的边缘情况,语法也跟易于上手,很推荐使用。
包管理
npm的包管理机制你一定要了解,不仅仅是node需要,我们前端浏览器项目本身也会引用很多第三方模块。面试必备知识点。
下图摘自抖音前端团队的npm包管理机制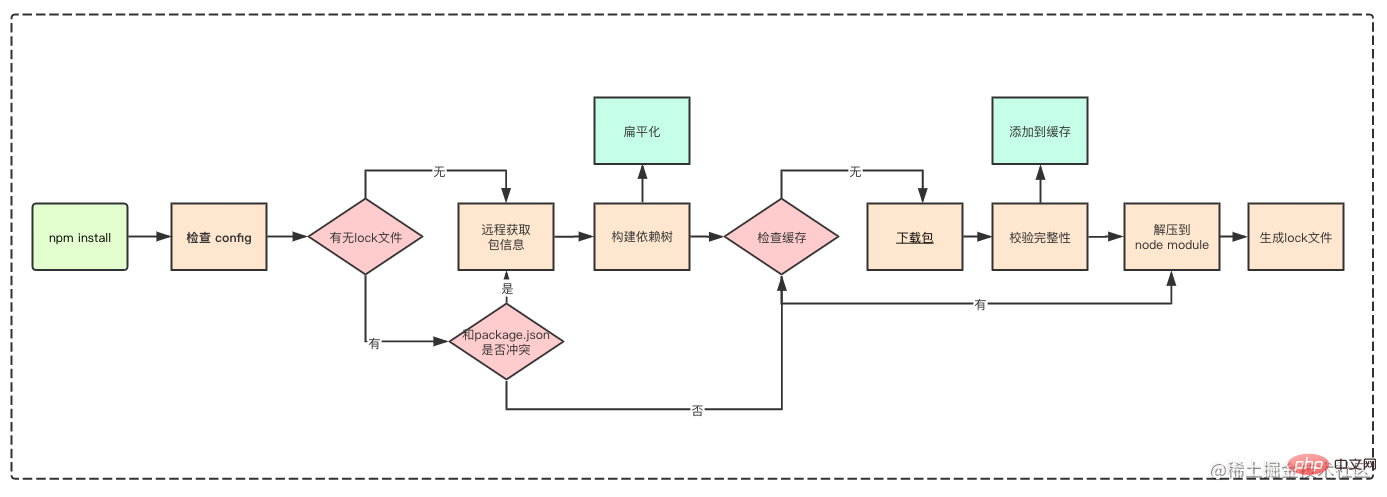
本图如果你理解的话,后面的内容就不用看了。
讲npm install 要从嵌套结构讲起
嵌套结构
在 npm 的早期版本中,npm 处理依赖的方式简单粗暴,以递归的方式,严格按照 package.json 结构以及子依赖包的 package.json 结构将依赖安装到他们各自的 node_modules 中。
如下图: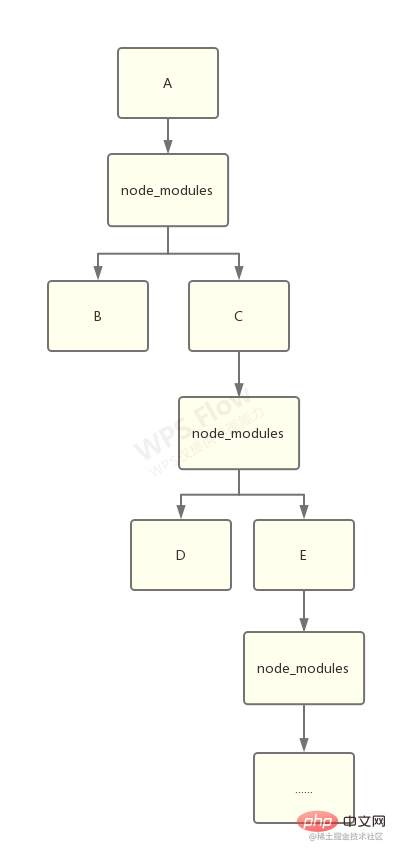 这样的方式优点很明显, node_modules 的结构和 package.json 结构一一对应,层级结构明显,并且保证了每次安装目录结构都是相同的。
这样的方式优点很明显, node_modules 的结构和 package.json 结构一一对应,层级结构明显,并且保证了每次安装目录结构都是相同的。
从上图这种情况,我们不难得出嵌套结构拥有以下缺点:
- 在不同层级的依赖中,可能引用了同一个模块,导致大量冗余
- 在 Windows 系统中,文件路径最大长度为260个字符,嵌套层级过深可能导致不可预知的问题
扁平结构
2016 年,yarn 诞生了。yarn 解决了 npm 几个最为迫在眉睫的问题:
- 安装太慢(加缓存、多线程)
- 嵌套结构(扁平化)
- 无依赖锁(yarn.lock)
- yarn 带来对的扁平化结构:
如下图,我们简单看下什么是扁平化的结构:
没错,这就是扁平化依赖管理的结果。相比之前的嵌套结构,现在的目录结构类似下面这样: 假如之前嵌套的结构如下:
node_modules ├─ a | ├─ index.js | |- node_modules -└─ b | | ├─ index.js | | └─ package.json | └─ package.json
那么扁平化处理以后,就编程下面这样,被拍平了
node_modules ├─ a | ├─ index.js | └─ package.json └─ b ├─ index.js └─ package.json
但是扁平化的结构又会引出新的问题:
最主要的就是依赖结构的不确定性!
啥意思,我就懒得画图了,拿网上的一个例子来说:
想象一下有一个 library-a,它同时依赖了 library-b、c、d、e:
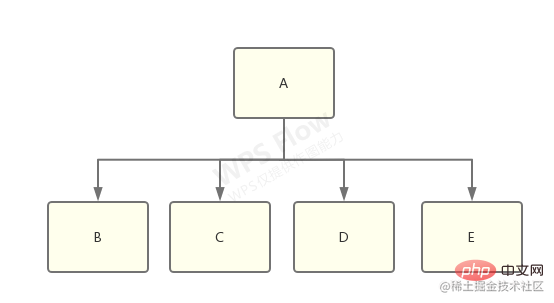
而 b 和 c 依赖了 f@1.0.0,d 和 e 依赖了 f@2.0.0:

这时候,node_modules 树需要做出选择了,到底是将 f@1.0.0 还是 f@2.0.0 扁平化,然后将另一个放到嵌套的 node_modules 中?
答案是:具体做那种选择将是不确定的,取决于哪一个 f 出现得更靠前,靠前的那个将被扁平化。
还有一个问题就是幽灵依赖,明明只安装a包,你却可以引用b包,因为a引用了b,并且扁平化处理了。
lock文件
这就是为啥要有lock文件的原因,lock文件可以保证安装包的扁平化结构的稳定。
使用新的npm包管理工具?
pnpm? 可以简单介绍一下为啥它能解决上面扁平化结构和幽灵依赖的问题。
补充问题
- a.js 和 b.js 两个文件互相 require 是否会死循环? 双方是否能导出变量? 如何从设计上避免这种问题?
答:不会, 先执行的导出其 未完成的副本, 通过导出工厂函数让对方从函数去拿比较好避免. 模块在导出的只是 var module = { exports: {...} }; 中的 exports。以下摘自阮一峰老师的博客:
CommonJS模块的重要特性是加载时执行,即脚本代码在require的时候,就会全部执行。CommonJS的做法是,一旦出现某个模块被"循环加载",就只输出已经执行的部分,还未执行的部分不会输出。
让我们来看,官方文档里面的例子。脚本文件a.js代码如下。
exports.done = false; var b = require('./b.js'); console.log('在 a.js 之中,b.done = %j', b.done); exports.done = true; console.log('a.js 执行完毕');
上面代码之中,a.js脚本先输出一个done变量,然后加载另一个脚本文件b.js。注意,此时a.js代码就停在这里,等待b.js执行完毕,再往下执行。
再看b.js的代码。
exports.done = false; var a = require('./a.js'); console.log('在 b.js 之中,a.done = %j', a.done); exports.done = true; console.log('b.js 执行完毕');
上面代码之中,b.js执行到第二行,就会去加载a.js,这时,就发生了"循环加载"。系统会去a.js模块对应对象的exports属性取值,可是因为a.js还没有执行完,从exports属性只能取回已经执行的部分,而不是最后的值。
a.js已经执行的部分,只有一行。
exports.done = false; 因此,对于b.js来说,它从a.js只输入一个变量done,值为false。
然后,b.js接着往下执行,等到全部执行完毕,再把执行权交还给a.js。于是,a.js接着往下执行,直到执行完毕。我们写一个脚本main.js,验证这个过程。
var a = require('./a.js'); var b = require('./b.js'); console.log('在 main.js 之中, a.done=%j, b.done=%j', a.done, b.done);
执行main.js,运行结果如下。
$ node main.js
在 b.js 之中,a.done = false b.js 执行完毕 在 a.js 之中,b.done = true a.js 执行完毕 在 main.js 之中, a.done=true, b.done=true
上面的代码证明了两件事。一是,在b.js之中,a.js没有执行完毕,只执行了第一行。二是,main.js执行到第二行时,不会再次执行b.js,而是输出缓存的b.js的执行结果,即它的第四行。
exports.done = true;
ES6模块的循环加载
ES6模块的运行机制与CommonJS不一样,它遇到模块加载命令import时,不会去执行模块,而是只生成一个引用。等到真的需要用到时,再到模块里面去取值。
因此,ES6模块是动态引用,不存在缓存值的问题,而且模块里面的变量,绑定其所在的模块。请看下面的例子。
// m1.js export var foo = 'bar'; setTimeout(() => foo = 'baz', 500);
// m2.js
import {foo} from './m1.js';
console.log(foo);
setTimeout(() => console.log(foo), 500);上面代码中,m1.js的变量foo,在刚加载时等于bar,过了500毫秒,又变为等于baz。
让我们看看,m2.js能否正确读取这个变化。
$ babel-node m2.js bar baz
上面代码表明,ES6模块不会缓存运行结果,而是动态地去被加载的模块取值,以及变量总是绑定其所在的模块。
这导致ES6处理"循环加载"与CommonJS有本质的不同。ES6根本不会关心是否发生了"循环加载",只是生成一个指向被加载模块的引用,需要开发者自己保证,真正取值的时候能够取到值。
请看下面的例子(摘自 Dr. Axel Rauschmayer 的《Exploring ES6》)。
// a.js
import {bar} from './b.js';
export function foo() {
bar();
console.log('执行完毕');
}
foo();// b.js
import {foo} from './a.js';
export function bar() {
if (Math.random() > 0.5) {
foo();
}
}按照CommonJS规范,上面的代码是没法执行的。a先加载b,然后b又加载a,这时a还没有任何执行结果,所以输出结果为null,即对于b.js来说,变量foo的值等于null,后面的foo()就会报错。
但是,ES6可以执行上面的代码。
$ babel-node a.js 执行完毕
a.js之所以能够执行,原因就在于ES6加载的变量,都是动态引用其所在的模块。只要引用是存在的,代码就能执行。
- 如果 a.js require 了 b.js, 那么在 b 中定义全局变量 t = 111 能否在 a 中直接打印出来?
会,作用域链的嘛。。。。
更多node相关知识,请访问:nodejs 教程!
以上が[編集して共有] ノードモジュールに関するインタビューの質問と回答 (コレクション)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7484
7484
 15
1377
52
77
11
19
37
15
1377
52
77
11
19
37

 PHP と Vue: フロントエンド開発ツールの完璧な組み合わせ
Mar 16, 2024 pm 12:09 PM
PHP と Vue: フロントエンド開発ツールの完璧な組み合わせ
Mar 16, 2024 pm 12:09 PM
PHP と Vue: フロントエンド開発ツールの完璧な組み合わせ 今日のインターネットの急速な発展の時代において、フロントエンド開発はますます重要になっています。 Web サイトやアプリケーションのエクスペリエンスに対するユーザーの要求がますます高まっているため、フロントエンド開発者は、より効率的で柔軟なツールを使用して、応答性の高いインタラクティブなインターフェイスを作成する必要があります。フロントエンド開発の分野における 2 つの重要なテクノロジーである PHP と Vue.js は、組み合わせることで完璧なツールと見なされます。この記事では、PHP と Vue の組み合わせと、読者がこれら 2 つをよりよく理解し、適用できるようにするための詳細なコード例について説明します。
 フロントエンドの面接官からよく聞かれる質問
Mar 19, 2024 pm 02:24 PM
フロントエンドの面接官からよく聞かれる質問
Mar 19, 2024 pm 02:24 PM
フロントエンド開発のインタビューでは、HTML/CSS の基本、JavaScript の基本、フレームワークとライブラリ、プロジェクトの経験、アルゴリズムとデータ構造、パフォーマンスの最適化、クロスドメイン リクエスト、フロントエンド エンジニアリング、デザインパターン、新しいテクノロジーとトレンド。面接官の質問は、候補者の技術スキル、プロジェクトの経験、業界のトレンドの理解を評価するように設計されています。したがって、候補者はこれらの分野で自分の能力と専門知識を証明するために十分な準備をしておく必要があります。
 Django はフロントエンドですか、バックエンドですか?それをチェックしてください!
Jan 19, 2024 am 08:37 AM
Django はフロントエンドですか、バックエンドですか?それをチェックしてください!
Jan 19, 2024 am 08:37 AM
Django は、迅速な開発とクリーンなメソッドを重視した Python で書かれた Web アプリケーション フレームワークです。 Django は Web フレームワークですが、Django がフロントエンドなのかバックエンドなのかという質問に答えるには、フロントエンドとバックエンドの概念を深く理解する必要があります。フロントエンドはユーザーが直接対話するインターフェイスを指し、バックエンドはサーバー側プログラムを指し、HTTP プロトコルを通じてデータと対話します。フロントエンドとバックエンドが分離されている場合、フロントエンドとバックエンドのプログラムをそれぞれ独立して開発して、ビジネス ロジックとインタラクティブ効果、およびデータ交換を実装できます。
 C# 開発経験の共有: フロントエンドとバックエンドの共同開発スキル
Nov 23, 2023 am 10:13 AM
C# 開発経験の共有: フロントエンドとバックエンドの共同開発スキル
Nov 23, 2023 am 10:13 AM
C# 開発者としての私たちの開発作業には、通常、フロントエンドとバックエンドの開発が含まれますが、テクノロジーが発展し、プロジェクトが複雑になるにつれて、フロントエンドとバックエンドの共同開発はますます重要かつ複雑になってきています。この記事では、C# 開発者が開発作業をより効率的に完了できるようにする、フロントエンドとバックエンドの共同開発テクニックをいくつか紹介します。インターフェイスの仕様を決定した後、フロントエンドとバックエンドの共同開発は API インターフェイスの相互作用から切り離せません。フロントエンドとバックエンドの共同開発をスムーズに進めるためには、適切なインターフェース仕様を定義することが最も重要です。インターフェイスの仕様にはインターフェイスの名前が含まれます
 Go 言語のフロントエンド テクノロジーの探求: フロントエンド開発の新しいビジョン
Mar 28, 2024 pm 01:06 PM
Go 言語のフロントエンド テクノロジーの探求: フロントエンド開発の新しいビジョン
Mar 28, 2024 pm 01:06 PM
Go 言語は、高速で効率的なプログラミング言語として、バックエンド開発の分野で広く普及しています。ただし、Go 言語をフロントエンド開発と結びつける人はほとんどいません。実際、フロントエンド開発に Go 言語を使用すると、効率が向上するだけでなく、開発者に新たな視野をもたらすことができます。この記事では、フロントエンド開発に Go 言語を使用する可能性を探り、読者がこの分野をよりよく理解できるように具体的なコード例を示します。従来のフロントエンド開発では、ユーザー インターフェイスの構築に JavaScript、HTML、CSS がよく使用されます。
 Java JPA の面接で選ばれた質問: 永続化フレームワークの習熟度をテストする
Feb 19, 2024 pm 09:12 PM
Java JPA の面接で選ばれた質問: 永続化フレームワークの習熟度をテストする
Feb 19, 2024 pm 09:12 PM
JPAとは何ですか? JDBC との違いは何ですか? JPA (JavaPersistence API) は、オブジェクト リレーショナル マッピング (ORM) の標準インターフェイスです。これにより、Java 開発者は、データベースに対して SQL クエリを直接記述することなく、使い慣れた Java オブジェクトを使用してデータベースを操作できるようになります。 JDBC (JavaDatabaseConnectivity) は、データベースに接続するための Java の標準 API であり、開発者は SQL ステートメントを使用してデータベースを操作する必要があります。 JPA は JDBC をカプセル化し、オブジェクト リレーショナル マッピングのためのより便利で高レベルの API を提供し、データ アクセス操作を簡素化します。 JPA ではエンティティとは何ですか?実在物
 Golang フレームワークの面接質問集
Jun 02, 2024 pm 09:37 PM
Golang フレームワークの面接質問集
Jun 02, 2024 pm 09:37 PM
Go フレームワークは、Go の組み込みライブラリを拡張するコンポーネントのセットで、事前に構築された機能 (Web 開発やデータベース操作など) を提供します。人気のある Go フレームワークには、Gin (Web 開発)、GORM (データベース操作)、RESTful (API 管理) などがあります。ミドルウェアは、HTTP リクエスト処理チェーンのインターセプター パターンであり、ハンドラーを変更せずに認証やリクエストのログ記録などの機能を追加するために使用されます。セッション管理は、ユーザー データを保存することでセッションの状態を維持します。ゴリラ/セッションを使用してセッションを管理できます。
 Golang とフロントエンド テクノロジーの組み合わせ: Golang がフロントエンド分野でどのような役割を果たすかを探る
Mar 19, 2024 pm 06:15 PM
Golang とフロントエンド テクノロジーの組み合わせ: Golang がフロントエンド分野でどのような役割を果たすかを探る
Mar 19, 2024 pm 06:15 PM
Golang とフロントエンド テクノロジーの組み合わせ: Golang がフロントエンド分野でどのような役割を果たしているかを調べるには、具体的なコード例が必要です。インターネットとモバイル アプリケーションの急速な発展に伴い、フロントエンド テクノロジーの重要性がますます高まっています。この分野では、強力なバックエンド プログラミング言語としての Golang も重要な役割を果たします。この記事では、Golang がどのようにフロントエンド テクノロジーと組み合わされるかを検討し、具体的なコード例を通じてフロントエンド分野での可能性を実証します。フロントエンド分野における Golang の役割は、効率的で簡潔かつ学びやすいものとしてです。
