

Linuxカーネルのソースコードはどのファイルに置かれていますか?

Linux カーネルのソース コードは、/usr/src/linux ディレクトリに配置されます。カーネル ソース コードの構成: 1. アーチ ディレクトリ (コア ソース コードでサポートされるハードウェア アーキテクチャに関連するコア コードが含まれます); 2. インクルード ディレクトリ (コアのインクルード ファイルのほとんどが含まれます); 3. initディレクトリにはコアのスタートアップ コードが含まれ、4. mm ディレクトリにはすべてのメモリ管理コードが含まれ、5. drivers ディレクトリにはシステム内のすべてのデバイス ドライバが含まれ、6. Ipc ディレクトリにはコアのプロセス間通信コードが含まれます。

#このチュートリアルの動作環境: linux7.3 システム、Dell G3 コンピューター。
Linux カーネルのソース コードはどこですか?
Linux カーネルのソース コードは、多くのソースから入手できます。一般に、インストールされた Linux システムでは、/usr/src/linux ディレクトリの内容がカーネル ソース コードです。
ソースコードの読み込みをスムーズに進めるためには、事前にソースコードの知識背景をある程度理解しておくのがベストです。
Linux カーネルのソース コードは次のように構成されます (Linux ディレクトリに相対していると仮定します):
arch
このサブディレクトリには、このコア ソース コードでサポートされるハードウェア アーキテクチャに関連するコア コードが含まれています。たとえば、X86 プラットフォームの場合は i386 です。
include
このディレクトリには、ほとんどのコア インクルード ファイルが含まれています。サポートされているアーキテクチャごとにサブディレクトリもあります。
init
このディレクトリには、コアの起動コードが含まれています。
mm
このディレクトリには、すべてのメモリ管理コードが含まれています。特定のハードウェア アーキテクチャに関連するメモリ管理コードは、arch/*/mm ディレクトリにあります (たとえば、X86 に対応するコードは、arch/i386/mm/fault.c です)。
drivers
システム内のすべてのデバイス ドライバーは、このディレクトリにあります。さらに、いくつかの種類のデバイス ドライバーに分類され、それぞれに、ドライバー/サウンドに対応するサウンド カード ドライバーなど、対応するサブディレクトリもあります。
Ipc
このディレクトリには、コアのプロセス間通信コードが含まれています。
modules
このディレクトリには、構築され、動的にロードできるモジュールが含まれています。
fs Linux
サポートされているファイル システム コード。ファイル システムが異なれば、対応するサブディレクトリも異なります。たとえば、ext2 ファイル システムは ext2 サブディレクトリに対応します。
カーネル
メインコアコード。同時に、プロセッサ構造に関連するコードが Arch/*/kernel ディレクトリに配置されます。
#Net
#コア ネットワーク部分のコード。内部の各サブディレクトリはネットワークの側面に対応します。Lib
このディレクトリには、コア ライブラリ コードが含まれています。プロセッサ アーキテクチャに関連するライブラリ コードは、arch/*/lib/ ディレクトリに配置されます。 #Scriptsこのディレクトリには、コアの構成に使用されるスクリプト ファイルが含まれています。
Documentationこのディレクトリには、参照用のドキュメントがいくつか含まれています。
#Linux カーネル ソース コードの解析方法
1 カーネル ソース コードの明確さ
If Linux を分析してオペレーティング システムの本質を掘り下げたい場合は、カーネルのソース コードを読むのが最も効果的な方法です。優れたプログラマーになるには、多くの練習とコード作成が必要であることは誰もが知っています。プログラミングは重要ですが、プログラミングだけを行う人は、自分の知識領域に限定されてしまいがちです。自分の知識の幅を広げたい場合は、他の人が書いたコード、特に自分よりも進んだ人が書いたコードにもっと触れる必要があります。このアプローチを通じて、私たちは自分自身の知識の輪の制約を打ち破り、他の人の知識の輪に入り、通常は短期間では学ぶことができない情報についてさらに学ぶことができます。 Linux カーネルは、オープン ソース コミュニティの無数の「マスター」によって注意深く保守されており、これらの人々はすべてトップ コード マスターと呼ぶことができます。 Linux カーネル コードを読むことで、カーネル関連の知識を学ぶだけでなく、プログラミング スキルとコンピュータの理解を学び理解することの方が価値があると私は考えています。
私もプロジェクトを通じて Linux カーネルのソースコードの解析に携わることになり、ソースコードの解析から多くの恩恵を受けました。関連するカーネルの知識を得ることができただけでなく、カーネル コード 1 に対する私のこれまでの理解も変わりました。カーネルのソースコードの分析は「手の届かない」わけではありません。カーネルのソース コード分析の難しさは、ソース コード自体にあるのではなく、より適切な方法や手段を使用してコードを分析する方法にあります。カーネルが巨大なため、通常のデモプログラムのように main 関数から段階的に解析することはできず、途中から介入してカーネルのソースコードを 1 つずつ「突破」する方法が必要です。この「リクエスト オン デマンド」アプローチにより、特定の詳細にこだわりすぎることなく、ソース コードの主要な部分を把握できるようになります。###2。芯のデザインが素敵です。カーネルの特殊なステータスにより、カーネルの実行効率は現在のコンピュータ アプリケーションのリアルタイム要件に応えるのに十分高くなければならないため、Linux カーネルでは C 言語とアセンブリのハイブリッド プログラミングが使用されます。しかし、ソフトウェアの実行効率とソフトウェアの保守性は、多くの場合、相反するものであることは誰もが知っています。カーネルの効率を確保しながらカーネルの保守性を向上させる方法は、カーネルの「美しい」設計にかかっています。
3.素晴らしいプログラミングスキル。アプリケーション ソフトウェア設計の一般的な分野では、コーディングの状況はあまり強調されないかもしれません。開発者はソフトウェアの優れた設計により注意を払い、コーディングは単なる実装手段の問題です。斧を使って木を切るのと同じで、何も必要はありません。考えすぎ。しかし、これはカーネルでは当てはまらず、優れたコーディング設計は保守性を向上させるだけでなく、コードのパフォーマンスも向上させます。 カーネルに対する理解は人によって異なります。カーネルに対する理解が深まるにつれて、カーネルの設計と実装についてより多くの考えや経験を積むことになります。したがって、この記事は、Linux カーネルの扉の外をさまよっているより多くの人々が Linux の世界に入り、カーネルの魔法と素晴らしさを自分で体験できるようにガイドしたいと考えています。また、私はカーネル ソース コードの専門家ではありません。ソース コードの分析における私自身の経験と経験を共有し、必要な方に参考と支援を提供できればと思っています。コンピュータ業界のために、特にオペレーティング システム カーネルに関して、ささやかな努力をしてください。早速(長くなってしまいました、ごめんなさい~)、私自身の Linux カーネル ソース コード分析方法を共有しましょう。2 カーネル ソース コードは難しいですか?
本質的に言えば、Linux カーネル コードを分析することは、他の人のコードを見ることと何ら変わりません。なぜなら、目の前にあるものだからです。一般に、それはあなた自身が書いたコードではありません。まずは簡単な例ですが、見知らぬ人からランダムにプログラムを渡され、ソースコードを読んだ上でそのプログラムの機能設計を説明してくださいと言われますが、自分のプログラミングスキルは大丈夫だと思っている人の多くは、そんなことは大したことないと思っているはずです。彼のコードを最初から最後まで辛抱強く読めば、必ず答えが見つかります。そして、実際にその通りです。それでは、仮説を変えてみましょう。この人が Linus で、彼があなたに渡したのが Linux カーネルのモジュールのコードだったとしても、あなたはまだそれほどリラックスした気分になるでしょうか?躊躇する人も多いかもしれません。見知らぬ人から与えられたコード (もちろん、ライナスがあなたのことを知っている場合は違いますが、笑~) が私たちにこれほど異なる感情を与えるのはなぜでしょうか?次のような理由があると思います。 1. Linux カーネルのコードは、「外の世界」にとってはどこか神秘的であり、あまりにも巨大なので、突然目の前に置かれたときに起動するのが不可能に感じるかもしれません。たとえば、メイン関数が見つからないという非常に小さな理由が原因である可能性があります。単純なデモ プログラムの場合、コードの意味を最初から最後まで解析できますが、カーネル コードを解析する方法はまったく効果がありません。Linux コードを最初から最後まで読むことは誰にもできないからです (実際には必要がないため) 、そして使用するときは、それを見てください)。 2.大規模なソフトウェアのコードに触れたことのある人も多いと思いますが、その多くはアプリケーションプロジェクトであり、コードの形式や意味はよく触れるビジネスロジックと関連しています。カーネル コードは異なり、カーネル コードが処理する情報のほとんどはコンピューターの最下層と密接に関連しています。たとえば、オペレーティング システム、コンパイラ、アセンブリ、アーキテクチャなどに関する関連知識が不足している場合も、カーネル コードを読むことが難しくなります。 3.カーネルコードを分析する方法は十分に合理的ではありません。大量の複雑なカーネル コードに直面する場合、全体的な観点から始めないと、コードの詳細で行き詰まってしまいがちです。カーネル コードは巨大ですが、設計原則とアーキテクチャも存在します。そうでない場合、カーネル コードを保守するのは誰にとっても悪夢でしょう。コードモジュールの全体的な設計思想を明確にしてからコードの実装を分析すれば、ソースコードの分析は簡単で幸せなものになるかもしれません。 これは、これらの問題についての私の個人的な理解です。大規模なソフトウェア プロジェクトに携わったことがない場合、Linux カーネル コードを分析することは、大規模なプロジェクトでの経験を積む良い機会になるかもしれません (実際、Linux コードは、私がこれまでに経験した最大のプロジェクトです!)。基盤となるコンピューターを十分に理解していない場合は、分析と学習を同時に行うことで基盤となる知識を蓄積することを選択できます。コードの分析の進み具合は最初は少し遅いかもしれませんが、知識が蓄積され続けると、Linux カーネルの「ビジネス ロジック」が徐々に明確になっていきます。最後のポイントは、グローバルな視点で分析のソースコードをどのように把握するかですが、これも私の経験を共有したいと思います。3 カーネルソースコードの解析手法
3.1 データ収集
本質を探る前に、新しいものを理解するという視点からこのプロセスにより、新しいものについての予備的な概念を得ることができます。例えば、ピアノを習いたいと思った場合、まずピアノを弾くためには基礎的な音楽理論、簡易記譜法、五線譜などの基礎知識が必要であることを理解し、次にピアノの演奏技術や運指を学び、ようやくピアノを始めることができます。ピアノの練習中。
カーネル コードの分析についても同様で、まず分析対象のコードに含まれるコンテンツを特定する必要があります。プロセスの同期とスケジューリングのコード、メモリ管理のコード、デバイス管理のコード、システム起動のコードなどですか。カーネルのサイズが大きいため、すべてのカーネル コードを一度に分析することはできないため、適切な分業を行う必要があります。アルゴリズム設計が示すように、大きな問題を解決するには、まずそれに含まれる部分的な問題を解決する必要があります。
分析対象のコード範囲を特定したら、手元にあるすべてのリソースを使用して、コードのこの部分の全体的な構造と一般的な機能をできるだけ包括的に理解できます。

ここで言及されているすべてのリソースは、Baidu、Google 大規模オンライン検索エンジン、オペレーティング システム原理の教科書および専門書籍、または他の人が提供する経験や情報、さらには Linux ソース コードによって提供されるドキュメントの名前、コメント、ソース コード識別子 (コード内の識別子の名前を過小評価しないでください。重要な情報が得られる場合もあります)。つまり、ここでのすべてのリソースは、考えられるすべての利用可能なリソースを指します。もちろん、このような形式の情報収集で必要な情報をすべて入手することは不可能ですが、できる限り網羅的に情報を収集したいと考えています。収集する情報が包括的であればあるほど、その後のコード分析プロセスでより多くの情報を使用できるようになり、分析プロセスの難易度が低くなるためです。
ここでは、Linux 周波数変換メカニズムによって実装されたコードを分析することを想定した簡単な例を示します。今のところこの用語しかわかっていませんが、文字通りの意味からすると、CPU の周波数調整に関係するものであると大まかに推測できます。情報収集を通じて、次の関連情報を取得できるはずです:
1. CPUFreq メカニズム。
2.パフォーマンス、省電力、ユーザースペース、オンデマンド、保守的な周波数調整戦略。
3. /ドライバー/cpufreq/。
4. /ドキュメント/cpufreq。
5. P ステートと C ステート。
Linux カーネル コードを分析するときにこの情報を収集できた場合は、非常に「幸運」です。結局のところ、Linux カーネルに関する情報は、確かに .NET や JQuery ほど豊富ではありませんが、強力な検索エンジンや関連する研究資料が存在しなかった 10 年以上前に比べれば、「偉大な情報」と呼ぶべきでしょう。ハーベスト時代!簡単な「検索」 (1 ~ 2 日かかる場合があります) によって、コードのこの部分が配置されているソース コード ファイル ディレクトリも見つかりました。この種の情報はまさに「貴重」であると言わざるを得ません。
3.2 ソース コードの場所
データ収集から、ソース コードに関連するソース コード ディレクトリを見つけることができたのは「幸運」でした。ただし、これは、このディレクトリ内のソース コードを実際に分析していることを意味するものではありません。見つかったディレクトリが散在している場合もあれば、特定のマシンに関連するコードが多数含まれている場合もあります。そのため、マシンに関連する特殊なコードよりも、分析対象のコードの主要なメカニズムに関心があることがあります (これはカーネルの性質をより深く理解するのに役立ちます)。したがって、情報の中からコードファイルが含まれる情報を慎重に選択する必要があります。もちろん、このステップが一度に完了する可能性は低く、分析対象のすべてのソース コード ファイルを一度に選択でき、どれも見逃されないという保証は誰にもできません。しかし、心配する必要はありません。ほとんどのモジュールに関連するコア ソース ファイルをキャプチャできれば、後でコードを詳細に分析することで自然にそれらをすべて見つけることができます。
上記の例に戻り、/documention/cpufreq にあるドキュメントを注意深く読みます。現在の Linux ソース コードでは、モジュールに関連するドキュメントがソース コード ディレクトリのドキュメント フォルダーに保存されます。分析対象のモジュールにドキュメントがない場合、主要なソース コード ファイルを見つけるのが多少難しくなりますが、解析したいソースコードが見つからなくなることはありません。ドキュメントを読むことで、少なくともソース ファイル /driver/cpufreq/cpufreq.c に注目することができます。このソース ファイルのドキュメントと、以前に収集した周波数変調戦略を組み合わせることで、cpufreq_performance.c、cpufreq_powersave.c、cpufreq_userspace.c、cpufreq_ondemand、および cpufreq_conservative.c の 5 つのソース ファイルに簡単に注目できます。関係する書類はすべて見つかったでしょうか?心配しないで、それらから分析を開始すると、遅かれ早かれ他のソース ファイルが見つかるでしょう。 Windows で SourceInsight を使用してカーネル ソース コードを読み取る場合、コード分析と組み合わせた関数呼び出しやシンボル参照検索などの機能を通じて、他のファイル freq_table.c、cpufreq_stats.c、および /include/linux/cpufreq を簡単に見つけることができます。 。

3.3 簡単なコメント
簡単なコメント見つかったソース コード ファイルで、各変数、マクロ、関数、構造体などを分析します。コード要素の意味と機能。これを単純な注釈と呼ぶのは、この部分の注釈作業が非常に単純であるという意味ではなく、この部分の注釈は、大まかに意味を説明するものであれば、あまり詳細にする必要がないという意味です。関連するコード要素。それどころか、ここでの作業は、分析プロセス全体の中で実際には最も難しいステップです。カーネル コードを深く掘り下げるのは初めてなので、特に初めてカーネル ソース コードを分析する人にとっては、多くのなじみのない GNU C 構文と圧倒的なマクロ定義に非常にがっかりするでしょう。この時点で、落ち着いてそれぞれの重要な困難を理解していれば、将来同じような困難に遭遇したときに罠にはまることはありません。さらに、カーネルに関連する他の知識も木のように拡大し続けます。 たとえば、cpufreq.c ファイルの先頭に「DEFINE_PER_CPU」マクロの使用方法が表示されますが、この情報を参照すれば、このマクロの意味と機能は基本的に理解できます。ここで使用する方法は、以前にデータを収集した方法と基本的に同じですが、sourceinsight が提供する定義へ移動機能を使用して定義を表示したり、LKML (Linux Kernel Mail List) を使用して定義を表示したりすることもできます。つまり、あらゆる手段を使用すれば、このマクロの意味を常に取得できます。CPU ごとに独立して使用される変数を定義できます。 一度にコメントを正確に記述することにはこだわりません (各関数の具体的な実装プロセスを理解する必要さえありません。一般的な機能の意味を理解するだけです)。収集したコメントを組み合わせます。データとそれに続くコードの分析により、コメントの意味が継続的に改善されます (ここでは、ソース コード内の元のコメントと識別子の名前付けが非常に役に立ちます)。継続的な注釈、情報への継続的な参照、および注釈の意味の継続的な変更を通じて。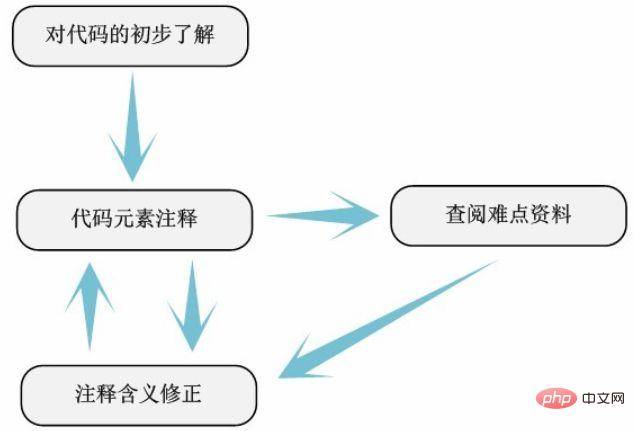
#関係するすべてのソース コード ファイルを配置した後単純なアノテーションを使用すると、次の結果が得られます:
1.基本的には、ソース コード内のコード要素の意味を理解します。
2.基本的に、このモジュールに関係する主要なソース コード ファイルはすべて見つかりました。
以前に収集した情報とデータに基づいて分析するコードの全体的またはアーキテクチャの説明と組み合わせることで、分析結果とデータを比較して、コードの理解を決定および修正することができます。このように、簡単なコメントを通じて、ソースコードモジュール全体の主な構造を把握することができます。これにより、単純なアノテーションの基本的な目的も達成されます。
3.4 詳細なコメント
コードの簡単なコメントが完了すると、モジュールの分析の半分が完了したと考えられ、残りのコンテンツが完成します。コードを徹底的に分析し、徹底的に理解する必要があります。単純なコメントではコード要素の特定の意味を必ずしも正確に説明できるとは限らないため、詳細なコメントが非常に必要です。このステップでは、次のことを明確にする必要があります:
1.変数定義を使用する場合。
2.マクロで定義したコードを使用する場合。
3.関数のパラメータと戻り値の意味。
4.関数の実行フローと呼び出し関係。 ####5.構造体フィールドの具体的な意味と使用条件。
関数の外側のコード要素の意味は基本的に単純なコメントで明らかであるため、このステップを詳細関数アノテーションと呼ぶこともできます。関数自体の実行フローとアルゴリズムが、この部分のアノテーションと分析の主なタスクです。
たとえば、cpufreq_ondemand ポリシーの実装アルゴリズム (関数 dbs_check_cpu 内) がどのように実装されるかなどです。アルゴリズムの詳細を理解するには、関数で使用される変数と呼び出される関数を徐々に分析する必要があります。最良の結果を得るには、これらの複雑な関数の実行フローチャートと関数呼び出し図が必要です。これは最も直観的な表現方法です。

#コメントのこのステップを通じて、基本的に分析対象のコード全体を完全に把握できます。という仕組みが実装されています。すべての分析作業は 80% 完了したと考えられます。このステップは特に重要で、分析対象のコードの内部モジュールの分割をよりよく理解できるように、アノテーション情報を十分に正確にするよう努める必要があります。 Linux カーネルは、マクロ構文「module_init」および「module_exit」を使用してモジュール ファイルを宣言しますが、モジュール内のサブ関数の分割は、モジュールの関数の完全な理解に基づいています。モジュールを正しく分割することによってのみ、モジュールが提供する外部関数と変数を把握できます (EXPORT_SYMBOL_GPL または EXPORT_SYMBOL によってエクスポートされたシンボルを使用)。そうして初めて、モジュール内の識別子の依存関係を分析する次のステップに進むことができます。
3.5 モジュールの内部識別子の依存関係
4 番目のステップでコード モジュールを分割することで、モジュールを 1 つずつ「簡単に」分析できます。一般に、ファイルの最後にあるモジュールの入口関数と出口関数から開始できます (「module_init」と「module_exit」で宣言された関数は通常、ファイルの最後にあります)。それらが呼び出す関数 (によって定義された関数) に基づいて、キー変数 (このファイル内のグローバル変数または他のモジュールの外部変数) は、「関数-変数-関数」依存関係図を描画します。これを識別子依存関係図と呼びます。
もちろん、モジュール内の識別子の依存関係は単純なツリー構造ではなく、多くの場合、複雑なネットワーク関係になります。このとき、コードに対する詳細なコメントの役割が反映されます。関数自体の意味に基づいてモジュールをサブ関数に分割し、各サブ関数の識別子依存ツリーを抽出します。
3.6 モジュール間の相互依存関係
モジュール間の相互依存関係
すべてのモジュールの内部識別子の依存関係図が整理されると、他のモジュールの変数または関数に従って簡単に作成できます。モジュール間の依存関係を特定します。


スルースルーモジュール間の依存関係図により、解析対象のコード全体におけるモジュールの状態や機能を明確に表現できます。これに基づいて、モジュールを分類し、コードのアーキテクチャ上の関係を整理できます。
 cpufreq のモジュール依存関係図に示されているように、全周波数変調がはっきりとわかります。戦略モジュールは、コア モジュール cpufreq、cpufreq_stats、および freq_table に依存します。 3 つの依存モジュールをコードのコア フレームワークに抽象化すると、これらの周波数変調戦略モジュールはこのフレームワーク上に構築され、ユーザー層との対話を担当します。コア モジュール cpufreq は、基礎となるシステムとの対話を担当するドライバーおよびその他の関連インターフェイスを提供します。したがって、次のモジュール アーキテクチャ図が得られます。
cpufreq のモジュール依存関係図に示されているように、全周波数変調がはっきりとわかります。戦略モジュールは、コア モジュール cpufreq、cpufreq_stats、および freq_table に依存します。 3 つの依存モジュールをコードのコア フレームワークに抽象化すると、これらの周波数変調戦略モジュールはこのフレームワーク上に構築され、ユーザー層との対話を担当します。コア モジュール cpufreq は、基礎となるシステムとの対話を担当するドライバーおよびその他の関連インターフェイスを提供します。したがって、次のモジュール アーキテクチャ図が得られます。  もちろん、アーキテクチャ図はモジュールを無機的につなぎ合わせたものではありません。それを私たちが調べた情報と組み合わせることで、アーキテクチャ図の意味を豊かにすることができます。したがって、ここでのアーキテクチャ図の詳細は、理解する人によって異なります。ただし、アーキテクチャ図の本体の意味は基本的に同じです。この時点で、分析対象のカーネル コードのすべての分析が完了しました。
もちろん、アーキテクチャ図はモジュールを無機的につなぎ合わせたものではありません。それを私たちが調べた情報と組み合わせることで、アーキテクチャ図の意味を豊かにすることができます。したがって、ここでのアーキテクチャ図の詳細は、理解する人によって異なります。ただし、アーキテクチャ図の本体の意味は基本的に同じです。この時点で、分析対象のカーネル コードのすべての分析が完了しました。 関連する推奨事項: 「
Linux ビデオ チュートリアル以上がLinuxカーネルのソースコードはどのファイルに置かれていますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7549
7549
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
Centosとubuntuの重要な違いは次のとおりです。起源(CentosはRed Hat、for Enterprises、UbuntuはDebianに由来します。個人用のDebianに由来します)、パッケージ管理(CentosはYumを使用し、安定性に焦点を当てます。チュートリアルとドキュメント)、使用(Centosはサーバーに偏っています。Ubuntuはサーバーやデスクトップに適しています)、その他の違いにはインストールのシンプルさが含まれます(Centos is Thin)
 Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosのインストール手順:ISO画像をダウンロードし、起動可能なメディアを燃やします。起動してインストールソースを選択します。言語とキーボードのレイアウトを選択します。ネットワークを構成します。ハードディスクをパーティション化します。システムクロックを設定します。ルートユーザーを作成します。ソフトウェアパッケージを選択します。インストールを開始します。インストールが完了した後、ハードディスクから再起動して起動します。
 メンテナンスを停止した後のCentosの選択
Apr 14, 2025 pm 08:51 PM
メンテナンスを停止した後のCentosの選択
Apr 14, 2025 pm 08:51 PM
Centosは廃止されました、代替品には次のものが含まれます。1。RockyLinux(最高の互換性)。 2。アルマリン(Centosと互換性); 3。Ubuntuサーバー(設定が必要); 4。RedHat Enterprise Linux(コマーシャルバージョン、有料ライセンス); 5。OracleLinux(CentosとRhelと互換性があります)。移行する場合、考慮事項は次のとおりです。互換性、可用性、サポート、コスト、およびコミュニティサポート。
 Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法は? Dockerデスクトップは、ローカルマシンでDockerコンテナを実行するためのツールです。使用する手順には次のものがあります。1。Dockerデスクトップをインストールします。 2。Dockerデスクトップを開始します。 3。Docker Imageを作成します(DockerFileを使用); 4. Docker画像をビルド(Docker Buildを使用); 5。Dockerコンテナを実行します(Docker Runを使用)。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
CentOSが停止した後、ユーザーは次の手段を採用して対処できます。Almalinux、Rocky Linux、Centosストリームなどの互換性のある分布を選択します。商業分布に移行する:Red Hat Enterprise Linux、Oracle Linuxなど。 Centos 9ストリームへのアップグレード:ローリングディストリビューション、最新のテクノロジーを提供します。 Ubuntu、Debianなど、他のLinuxディストリビューションを選択します。コンテナ、仮想マシン、クラウドプラットフォームなどの他のオプションを評価します。
 VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSコードシステムの要件:オペレーティングシステム:オペレーティングシステム:Windows 10以降、MACOS 10.12以上、Linux Distributionプロセッサ:最小1.6 GHz、推奨2.0 GHz以上のメモリ:最小512 MB、推奨4 GB以上のストレージスペース:最低250 MB以上:その他の要件を推奨:安定ネットワーク接続、XORG/WAYLAND(Linux)
 Dockerはどのような根本的なテクノロジーを使用していますか?
Apr 15, 2025 am 07:09 AM
Dockerはどのような根本的なテクノロジーを使用していますか?
Apr 15, 2025 am 07:09 AM
Dockerは、コンテナエンジン、ミラー形式、ストレージドライバー、ネットワークモデル、コンテナオーケストールツール、オペレーティングシステム仮想化、コンテナレジストリを使用して、コンテナ化機能をサポートし、軽量でポータブルで自動化されたアプリケーションの展開と管理を提供します。
