

12款免费与开源的NoSQL数据库介绍_MySQL

NoSQL
Naresh Kumar是位软件工程师与热情的博主,对于编程与新事物拥有极大的兴趣,非常乐于与其他开发者和程序员分享技术上的研究成果。近日,Naresh撰文谈到了12款知名的免费、开源NoSQL数据库,并对这些数据库的特点进行了分析。

现在,NoSQL数据库变得越来越流行,我在这里总结出了一些非常棒的、免费且开源的NoSQL数据库。在这些数据库中,MongoDB独占鳌头,拥有相当大的使用量。这些免费且开源的NoSQL数据库具有很好的可伸缩性与灵活性,非常适合于大数据存储与处理。相较于传统的关系型数据库,这些NoSQL数据库在性能上具有很大的优势。然而,这些NoSQL数据库未必最适合你。大多数常见的应用仍然可以使用传统的关系型数据库进行开发。NoSQL数据库依然不太适合于那些任务关键型的事务要求。我对这些数据库进行了一些简单介绍,下面就来看看。
1. MongoDB
MongoDB是个面向文档的数据库,使用JSON风格的数据格式。它非常适合于网站的数据存储、内容管理与缓存应用,并且通过配置可以实现复制与高可用性功能。
MongoDB具有很强的可伸缩性,性能表现优异。它使用C++编写,基于文档存储。此外,MongoDB还支持全文检索、跨WAN与LAN的高可用性、易于实现的复制、水平扩展、基于文档的丰富查询、在数据处理与聚合等方面具有很强的灵活性。
2. Cassandra
这是个Apache软件基金会的项目,Cassandra是个分布式数据库,支持分散的数据存储,可以实现容错以及无单点故障等。换句话说,“Cassandra非常适合于那些无法忍受数据丢失的应用”。
3. CouchDB
这也是Apache软件基金会的一个项目,CouchDB是另一个面向文档的数据库,以JSON格式存储数据。它兼容于ACID,像MongoDB一样,CouchDB也可以用于存储网站的数据与内容,以及提供缓存等。你可以通过JavaScript在CouchDB上运行MapReduce查询。此外,CouchDB还提供了一个非常方便的基于Web的管理控制台。它非常适合于Web应用。
4. Hypertable
Hypertable模仿的是Google的BigTable数据库系统。Hypertable的创建者将“成为高可用、PB规模的数据库开源标准”作为Hypertable的目标。换言之,Hypertable的设计目标是跨越多个廉价的服务器可靠地存储大量数据。
5. Redis
这是个开源、高级的键值存储。由于在键中使用了hash、set、string、sorted set及list,因此Redis也称作数据结构服务器。这个系统可以帮助你执行原子操作,比如说增加hash中的值、集合的交集运算、字符串拼接、差集与并集等。Redis通过内存中的数据集实现了高性能。此外,该数据库还兼容于大多数编程语言。
6. Riak
Riak是最为强大的分布式数据库之一,它提供了轻松且可预测的伸缩能力,向用户提供了快速测试、原型与应用部署能力,从而简化应用的开发过程。
7. Neo4j
Neo4j是一款NoSQL图型数据库,具有非常高的性能。它拥有一个健壮且成熟的系统的所有特性,向程序员提供了灵活且面向对象的网络结构,可以让开发者充分享受到拥有完整事务特性的数据库的所有好处。相较于RDBMS,Neo4j还对某些应用提供了不少性能改进。
8. Hadoop HBase
HBase是一款可伸缩、分布式的大数据存储。它可以用在数据的实时与随机访问的场景下。HBase拥有模块化与线性的可伸缩性,并且能够保证读写的严格一致性。HBase提供了一个Java API,可以实现轻松的客户端访问;提供了可配置且自动化的表分区功能;还有Bloom过滤器以及block缓存等特性。
9. Couchbase
虽然Couchbase是CouchDB的派生,不过它已经成为了一款功能完善的数据库产品。它向文档数据库转移的趋势会让MongoDB感到压力。每个节点上它都是多线程的,这是个非常主要的可伸缩性优势,特别是当托管在自定义或是Bare-Metal硬件上时更是如此。借助于一些非常棒的集成特性,诸如与Hadoop的集成,Couchbase对于数据存储来说是个非常不错的选择。
10. MemcacheDB
这是个分布式的键值存储系统,我们不应该将其与缓存解决方案搞混;相反,它是个持久化存储引擎,用于数据存储并以非常快速且可靠的方式检索数据。它遵循memcache协议。其存储后端用于Berkeley DB中,支持诸如复制与事务等特性。
11. REVENDB
RAVENDB是第二代开源数据库,它面向文档存储并且无模式,这样就可以轻松将对象存储到其中了。它提供了非常灵活且快速的查询,通过对复制、多租与分片提供开箱即用的支持使得我们可以非常轻松地实现伸缩功能。它对ACID事务提供了完整的支持,同时又能保证数据的安全性。除了高性能之外,它还通过bundle提供了轻松的可扩展性。
12. Voldemort
这是个自动复制的分布式存储系统。它提供了自动化的数据分区功能,透明的服务器失败处理、可插拔的序列化功能、独立的节点、数据版本化以及跨越各种数据中心的数据分发功能。
各位读者,不知在你的项目中曾经、现在或是未来使用了哪些NoSQL数据库。现今的NoSQL世界纷繁复杂,NoSQL数据库也多如牛毛,而且有一些数据库提供了相似的特性,本文所列出的只是其中比较有代表性的12款NoSQL产品。你是否使用过他们呢?是否使用了本文没有介绍的产品呢?他们有哪些特性打动了你,让你决定使用他们呢?非常欢迎将你的经历与看法与我们一起分享。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。
人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7322
7322
 9
1625
14
1350
46
1262
25
1209
29
9
1625
14
1350
46
1262
25
1209
29

 リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
最新の AIGC オープンソース プロジェクト、AnimagineXL3.1 をご紹介します。このプロジェクトは、アニメをテーマにしたテキストから画像へのモデルの最新版であり、より最適化された強力なアニメ画像生成エクスペリエンスをユーザーに提供することを目的としています。 AnimagineXL3.1 では、開発チームは、モデルのパフォーマンスと機能が新たな高みに達することを保証するために、いくつかの重要な側面の最適化に重点を置きました。まず、トレーニング データを拡張して、以前のバージョンのゲーム キャラクター データだけでなく、他の多くの有名なアニメ シリーズのデータもトレーニング セットに含めました。この動きによりモデルの知識ベースが充実し、さまざまなアニメのスタイルやキャラクターをより完全に理解できるようになります。 AnimagineXL3.1 では、特別なタグと美学の新しいセットが導入されています
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
 北京大学の最も強力なオープンソース aiXcoder-7B コード モデル!実際の開発シナリオに重点を置き、企業のプライベート展開向けに設計
Apr 09, 2024 pm 06:10 PM
北京大学の最も強力なオープンソース aiXcoder-7B コード モデル!実際の開発シナリオに重点を置き、企業のプライベート展開向けに設計
Apr 09, 2024 pm 06:10 PM
テクノロジー界の最新の発展から判断すると、AI コード生成の概念は最近非常に人気が高まっています。しかし、皆さん、AI プログラミングの質問はより人目を引くものだと感じていますが、実際の企業開発シナリオとなると、それだけでは十分ではないと常に感じていますか?このとき、地味な上級プレイヤーである aiXcoder が行動を起こし、大きな動きをリリースしました。これは、新しいオープン ソース コード モデル、aiXcoder-7BBase バージョンであり、エンタープライズ ソフトウェア開発シナリオでの展開に特に適したコード モデルです。待ってください。パラメーターが「わずか」 70 億個しかない大規模なコード モデルは、どのような AI プログラミング レベルを示すことができるのでしょうか?まず、HumanEval、MBPP、MultiPL-E の 3 つの主流の評価セットでのパフォーマンスを見てみましょう。その平均スコアは、実際に 340 億のパラメータを持つ Co のスコアを上回っています。
 いくつかの .NET オープンソース AI および LLM 関連プロジェクト フレームワークを共有する
May 06, 2024 pm 04:43 PM
いくつかの .NET オープンソース AI および LLM 関連プロジェクト フレームワークを共有する
May 06, 2024 pm 04:43 PM
現在、人工知能(AI)技術の開発は本格化しており、さまざまな分野で大きな可能性と影響力を発揮しています。本日、Dayao は、参考にしていただけるよう、4 つの .NET オープン ソース AI モデル LLM 関連プロジェクト フレームワークを共有します。 https://github.com/YSGStudyHards/DotNetGuide/blob/main/docs/DotNet/DotNetProjectPicks.mdSemanticKernelSemanticKernel は、OpenAI、Azure などの大規模言語モデル (LLM) を統合するように設計されたオープン ソース ソフトウェア開発キット (SDK) です。
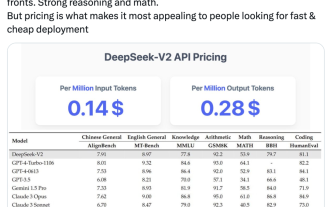 国内のオープンソース MoE 指標が爆発的に増加: GPT-4 レベルの機能、API 価格はわずか 1%
May 07, 2024 pm 05:34 PM
国内のオープンソース MoE 指標が爆発的に増加: GPT-4 レベルの機能、API 価格はわずか 1%
May 07, 2024 pm 05:34 PM
最新の国内大規模オープンソース MoE モデルは、デビュー直後から人気を集めています。 DeepSeek-V2 のパフォーマンスは GPT-4 レベルに達しますが、オープンソースで商用利用は無料で、API 価格は GPT-4-Turbo のわずか 1% です。そのため、公開されるとすぐに大きな話題を呼びました。公開されているパフォーマンス指標から判断すると、DeepSeekV2 の包括的な中国語機能は多くのオープンソース モデルの機能を上回っています。同時に、GPT-4Turbo や Wenkuai 4.0 などのクローズド ソース モデルも第一段階にあります。総合的な英語力もLLaMA3-70Bと同じ第一段階にあり、同じくMoEであるMixtral8x22Bを上回っています。また、知識、数学、推論、プログラミングなどでも優れたパフォーマンスを示します。 128K コンテキストをサポートします。これをイメージしてください
 PHP で MySQLi を使用してデータベース接続を確立するための詳細なチュートリアル
Jun 04, 2024 pm 01:42 PM
PHP で MySQLi を使用してデータベース接続を確立するための詳細なチュートリアル
Jun 04, 2024 pm 01:42 PM
MySQLi を使用して PHP でデータベース接続を確立する方法: MySQLi 拡張機能を含める (require_once) 接続関数を作成する (functionconnect_to_db) 接続関数を呼び出す ($conn=connect_to_db()) クエリを実行する ($result=$conn->query()) 閉じる接続 ( $conn->close())
