

ChatGPT と Google Bard: どちらが優れていて、どちらが悪いのでしょうか? 違いを大きくレビューします!

AIGC 業界の 2 つの最大の競合相手: ChatGPT 対 Google Bard! この記事では、これら 2 つの人工知能エンジンの技術的な違いを紹介します。
翻訳者 | Cui Hao
レビュアー | Sun Shujuan
冒頭
AIGC 業界の 2 つの最大の競合相手: ChatGPT 対 Google Bard! この記事の説明これら 2 つの人工知能エンジンの技術的な違い。
Google Bard と ChatGPT のこれまでの最大の違いは、Bard は ChatGPT について知っていますが、ChatGPT は Bard について知りません。 ChatGPT を試すことはできますが、Bard はまだほとんどの人にとって手の届かないところにあります。

ChatGPT と Google Bard の戦いが始まります
ChatGPT と Google Bard はどちらも人工知能チャットボットです。人工知能の簡易版はすでに携帯電話で利用可能で、「良い」と入力すると、次の単語が「朝」であると携帯電話が予測する。
ChatGPT は元々 OpenAI によって開発され、その後 Microsoft によって驚くべき 100 億ドルの資金提供を受けました (以前の 10 億ドルの投資に加えて)。 Google 側は、検索の独占が終わりを迎えるかもしれないと若干パニックになり、Bard を立ち上げましたが、このバージョンにはまだいくつかの欠陥がありました。初めてのライブ デモンストレーション中に、バードは Google を当惑させるいくつかの事実上の誤りを犯しました。
ChatGPT と Google Bard はスマートフォンの予測テキスト機能よりも複雑です。これら 2 つの知能ロボットの違いを理解したい場合は、次のコンテンツを見逃すことはできません。
ここでは、2 つの人工知能エンジンの技術的な違いについて詳しく説明します。
ChatGPT と吟遊詩人: 隠された秘密?
次の表から、多くの詳細を確認することで、両者の技術的な違いをすぐに理解できます。
| # #C hatGPT |
B ard |
|
| GPT-3.5 | LaMDA、つまり、対話アプリケーションの言語モデル | |
| Transformer | Transformer |
|
トレーニング データ |
ネットワーク テキスト、主にデータセットは「common Crawl」と呼ばれ、2021 年半ばに予定されています。 |
156 万語の公開対話データとネットワーク テキスト |
目的 | 多目的テキスト生成チャットボットになる |
#検索支援専用 |
パラメータ |
##1,750 億パラメータ | ##1,370 億パラメータ# #クリエイター |
| OpenAI | 利点 | |
#- より柔軟でオープンテキストを処理可能 | #- トレーニング データは 2021 年時点のものです
-現在のトレーニング データ - 会話用に特別にトレーニングされているため、話しかけるとより人間らしく聞こえます。 |
|
欠点 |
#- 対話はそれほど説得力がありません #- そうではありません慎重に微調整してください ##-まだです | ##-一般的なテキスト作成には適していない可能性があります
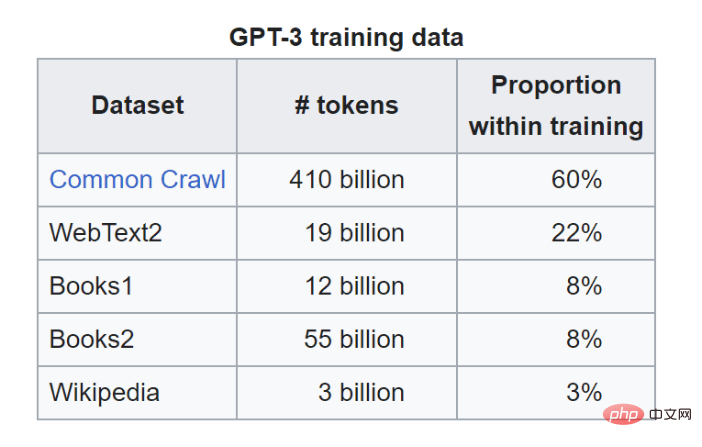
# 上の表で 2 つの違いを理解した後、他の指標について詳しく見てみましょう。 ChatGPT とは何ですか?ChatGPTは2022年11月30日、突如ステージに現れました。 2022 年 12 月 4 日の時点で、このサービスの毎日のユーザー数は 100 万人を超えています。 2023 年 1 月には、このユーザー数は 1 億人を超えました。 このツールが突然人気を博した基本的な理由は、多くのトピックに対してほぼ人間のような方法で信頼できる回答を提供でき、インターネット接続があれば誰でも使用できることです。 ChatGPT は、フレンドリーな人工知能ソリューションの作成に焦点を当てている、サンフランシスコにある人工知能研究所である OpenAI によって作成されました。チャットボットは、テキストが与えられると要求者に応答を継続的に提供できる大規模な言語モデルである GPT-3.5 に基づいて開発されています。 ChatGPT は、これに基づいて追加のトレーニングを追加します。人間のトレーナーがモデルとの対話を通じてモデルを改善し、「報酬」を通じて高品質の回答を提供する能力をモデルに与えます。 トレーニング データGPT-3.5 は、Common Crawl と呼ばれる一般的なデータセットを含む、巨大な Web テキスト データセットでトレーニングされます。 Common Crawl には、生の Web ページ データ、メタデータ抽出、テキスト抽出など、ペタバイト単位の Web データが含まれています。たとえば、StrataScratch からの URL のコレクションが含まれています。 ChatGPT で使用されるトレーニング データが ChatGPT でのネチズンの入力から来ていると考えるのはクレイジーではありませんか? Common Crawl はトレーニング データの 60% を担当しますが、GPT-3.5 には他のデータ ソースもあります。
Google Bard とは何ですか?Google Bard は、ChatGPT が非常に人気になったときに Google によって発売されたインテリジェントなチャット ロボットです。 ChatGPT とは異なり、Bard は Google 独自のモデルである LaMDA を利用しています。 LaMDA は Language Model for Conversational Applications の略称ですが、ChatGPT とは異なり、ほとんどの人がまだアクセスできないという単純な理由から、それほど驚くべきものではありません。 Google は 2 月初旬に Bard のぎこちないデモを公開しましたが、現在 Bard を利用できるのは選ばれた少数の人だけです。 Google Bard の主な利点は、インターネットにオープンであることです。 ChatGPT に「今の大統領は誰ですか?」と尋ねても、それはわかりません。これは、2021 年半ば頃に学習データが途切れたためです。一方、バード氏は現在インターネットで入手可能な情報を利用しました。理論的には、バード氏は今日インターネット上のデータを抽出して、現在誰が大統領であるかを伝えることができるはずです。 Bard がいくつかの重要な側面で ChatGPT よりも優れていることが簡単にわかります。
トレーニング データまず第一に、LaMDA は、GPT-n モデルのようなテキストを単に生成するのではなく、会話、特に会話についてトレーニングされます。 ChatGPT はトレーニング データについて恥ずかしがりませんが、Bard がトレーニングされたデータについてはあまりわかっておらず、LaMDA の研究論文を見ることで推測できます。 Googleの研究者らは、トレーニングデータの12.5%がGPT-nモデルなどのCommon Crawlから来ていると述べている。さらに 12.5% はウィキペディアからのものです。研究論文によると、彼らは1兆5600億語の「公衆の会話データとネットワークテキスト」を使用したという。 完全な内訳は次のとおりです:
上記の情報から、データを共同で知ることができます。もちろん、Wikipedia もあります。残りのデータは明らかに Google によって意図的に隠蔽されており、おそらく Bard (および LaMDA) が模倣されるのを防ぐためと思われます。 LaMDA は、もともと Google が開発したオープンソースのニューラル ネットワーク アーキテクチャである Transformer のニューラル言語モデルを微調整することによって形成されました。 (GPT も Transformer に基づいています)。
ChatGPT には煩わしさやナンセンスな発言を防ぐための障壁がいくつかありますが、Google は Bard をより優れた安全なチャット ロボットにするために品質を確保する方法を重視しています。 Bard は「高品質、根拠のある、安全」になるよう微調整されています。 Google はこれについて多くのことを述べているので、関連するブログ投稿を読むことをお勧めしますが、あまり時間がない場合は、基本的に次の側面に分けることができます。
原題: ChatGPT vs Google Bard: A Comparison of the Technical Differences 、著者: Nate Rosidi |
以上がChatGPT と Google Bard: どちらが優れていて、どちらが悪いのでしょうか? 違いを大きくレビューします!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
8月1日の本サイトのニュースによると、SKハイニックスは本日(8月1日)ブログ投稿を発表し、8月6日から8日まで米国カリフォルニア州サンタクララで開催されるグローバル半導体メモリサミットFMS2024に参加すると発表し、多くの新世代の製品。フューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) の紹介。以前は主に NAND サプライヤー向けのフラッシュ メモリ サミット (FlashMemorySummit) でしたが、人工知能技術への注目の高まりを背景に、今年はフューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) に名前が変更されました。 DRAM およびストレージ ベンダー、さらに多くのプレーヤーを招待します。昨年発売された新製品SKハイニックス
 AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
7月5日のこのウェブサイトのニュースによると、グローバルファウンドリーズは今年7月1日にプレスリリースを発行し、自動車とインターネットでの市場シェア拡大を目指してタゴール・テクノロジーのパワー窒化ガリウム(GaN)技術と知的財産ポートフォリオを買収したことを発表した。モノと人工知能データセンターのアプリケーション分野で、より高い効率とより優れたパフォーマンスを探求します。生成 AI などのテクノロジーがデジタル世界で発展を続ける中、窒化ガリウム (GaN) は、特にデータセンターにおいて、持続可能で効率的な電力管理のための重要なソリューションとなっています。このウェブサイトは、この買収中にタゴール・テクノロジーのエンジニアリングチームがGLOBALFOUNDRIESに加わり、窒化ガリウム技術をさらに開発するという公式発表を引用した。 G
