

Microsoft、ワンストップで高性能軽量モデルを取得できる自動ニューラルネットワークトレーニングプルーニングフレームワーク「OTO」を提案

OTO は、業界初の自動化されたワンストップのユーザーフレンドリーで多用途なニューラル ネットワーク トレーニングおよび構造圧縮フレームワークです。
人工知能の時代では、ニューラル ネットワークをどのように展開して維持するかが製品化の重要な課題です。モデルのパフォーマンスの損失を可能な限り最小限に抑えながらコンピューティング コストを節約するために、ニューラル ネットワークを圧縮することが重要になっています。 DNN を製品化するための鍵の 1 つ。

#DNN 圧縮には一般に、枝刈り、知識蒸留、量子化という 3 つの方法があります。プルーニングは、モデルのパフォーマンスを可能な限り維持しながら、冗長な構造を特定して削除し、DNN をスリム化することを目的とした、最も汎用性が高く効果的な圧縮方法です。一般に、3 つの方法は相互に補完し合い、連携して最高の圧縮効果を実現できます。

ただし、既存のプルーニング手法のほとんどは、特定のモデルと特定のタスクのみを対象としており、専門分野の強力な知識が必要であるため、通常、AI 開発者は多大なエネルギーを費やす必要があります。これらの方法を独自のシナリオに適用すると、多くの人的資源と物的リソースが消費されます。
OTO の概要
既存のプルーニング手法の問題を解決し、AI 開発者に利便性を提供するために、Microsoft チームは Only-Train-Once OTO フレームワークを提案しました。 OTO は、業界初の自動化されたワンストップのユーザーフレンドリーでユニバーサルなニューラル ネットワーク トレーニングおよび構造圧縮フレームワークであり、一連の成果が ICLR2023 および NeurIPS2021 で公開されています。
OTO を使用することで、AI エンジニアはターゲットのニューラル ネットワークを簡単にトレーニングし、高性能かつ軽量なモデルをワンストップで取得できます。 OTO は、開発者のエンジニアリング時間と労力への投資を最小限に抑え、既存の方法で通常必要となる時間のかかる事前トレーニングや追加のモデル微調整を必要としません。
- 論文リンク:
- OTOv2 ICLR 2023: https://openreview.net/pdf?id=7ynoX1ojPMt
- OTOv1 NeurIPS 2021: https://proceedings .neurips.cc/paper_files/paper/2021/file/a376033f78e144f494bfc743c0be3330-Paper.pdf
- コードリンク:
https://github.com/tianyic/only_train_once
- どのネットワーク構造を削除できるかを確認するにはどうすればよいですか?
- モデルのパフォーマンスをできるだけ失わずにネットワーク構造を削除するにはどうすればよいでしょうか?
- 上記の 2 つの点を自動的に達成するにはどうすればよいでしょうか?
自動化されたゼロ不変グループ (ゼロ不変グループ) のグループ化
ネットワーク構造の複雑さと相関関係により、ネットワーク構造を削除するとネットワークが残る可能性があります。構造が無効です。したがって、自動ネットワーク構造圧縮における最大の問題の 1 つは、残りのネットワークが引き続き有効になるように一緒に枝刈りする必要があるモデル パラメーターをどのように見つけるかということです。この問題を解決するために、Microsoft チームは OTOv1 でゼロ不変グループ (ZIG) を提案しました。ゼロ不変グループは、グループの対応するネットワーク構造が削除された後も、残りのネットワークが引き続き有効であるように、削除可能な最小単位の一種として理解できます。ゼロ不変グループのもう 1 つの優れた特性は、ゼロ不変グループがゼロに等しい場合、入力値が何であっても、出力値は常にゼロになることです。 OTOv2 では、研究者らはさらに、一般ネットワークにおけるゼロ不変グループのグループ化問題を解決するための一連の自動化アルゴリズムを提案および実装しました。自動グループ化アルゴリズムは、一連のグラフ アルゴリズムを慎重に組み合わせて設計されており、アルゴリズム全体が非常に効率的で、時間と空間の複雑さが線形になります。
二重半平面投影勾配最適化アルゴリズム (DHSPG)
ターゲット ネットワークのすべてのゼロ不変グループを分割した後、次のモデルのトレーニングおよび枝刈りタスクでは、どのゼロ不変グループが冗長で、どのグループが重要であるかを特定する必要があります。圧縮モデルのパフォーマンスを確保するには、冗長なゼロ不変グループに対応するネットワーク構造を削除する必要がありますが、重要なゼロ不変グループは保持する必要があります。研究者らは、この問題を構造的スパース化問題として定式化し、それを解決するための新しいデュアル半空間投影勾配 (DHSPG) 最適化アルゴリズムを提案しました。
DHSPG は、冗長なゼロ不変式グループを非常に効果的に見つけてゼロに投影し、重要なゼロ不変式グループを継続的にトレーニングして、元のモデルと同等のパフォーマンスを達成できます。
従来のスパース最適化アルゴリズムと比較して、DHSPG はより強力で安定したスパース構造探索機能を備え、トレーニング検索スペースを拡大するため、通常はより高い実際のパフォーマンス結果が得られます。

軽量圧縮モデルを自動的に構築する
DHSPG を使用してモデルをトレーニングすると、ゼロ不変 A ソリューションが得られます。グループの構造的疎性が高い、つまり、ゼロに射影される多くのゼロ不変グループを含む解は、モデルのパフォーマンスも高くなります。次に、研究者らは、圧縮ネットワークを自動的に構築するために、冗長なゼロ不変グループに対応するすべての構造を削除しました。ゼロ不変グループの特性により、つまり、ゼロ不変グループがゼロに等しい場合、入力値が何であっても、出力値は常にゼロになるため、冗長なゼロ不変グループを削除しても、ネットワークに影響を与える可能性があります。したがって、OTO を通じて取得された圧縮ネットワークは、従来の方法で必要とされたモデルのさらなる微調整を必要とせずに、完全なネットワークと同じ出力を持ちます。
数値実験
分類タスク

##表 1: CIFAR10 BN モデルの VGG16 および VGG16-パフォーマンス
CIFAR10 の VGG16 実験では、OTO は浮動小数点数を 86.6%、パラメータ数を 97.5% 削減し、そのパフォーマンスは印象的でした。
CIFAR10 の ResNet50 実験では、量子化なしで OTO が優れたパフォーマンスを発揮 SOTA ニューラル ネットワーク圧縮フレームワーク AMC と ANNC は、FLOP の 7.8% とパラメータの 4.1% のみを使用します。
 #表 3. ImageNet の ResNet50 実験
#表 3. ImageNet の ResNet50 実験
ImageNet の ResNet50 実験では、さまざまな構造的疎性ターゲットの下での OTOv2 のパフォーマンスが示されています。既存の SOTA メソッドと同等かそれ以上です。
 表 4: より多くの構造とデータ セット
表 4: より多くの構造とデータ セット
OTO はさらに多くのデータ セットとモデル構造を実現しました。悪くないパフォーマンスです。
低レベル視覚タスク
 表 4: CARNx2
表 4: CARNx2
の実験超解像タスクでは、OTOワンストップトレーニングによりCARNx2ネットワークを圧縮し、オリジナルモデルと同等の性能を達成し、計算量とモデルサイズを75%以上圧縮しました。
言語モデル タスク
#さらに、研究者らは、Bert のコア アルゴリズムの 1 つである DHSPG 最適化アルゴリズムも実行しました。比較実験により、他のスパース最適化アルゴリズムと比較してその高いパフォーマンスが検証されます。 Squad では、トレーニングに DHSPG を使用することで得られるパラメーター削減とモデルのパフォーマンスが、他のスパース最適化アルゴリズムよりもはるかに優れていることがわかります。 
以上がMicrosoft、ワンストップで高性能軽量モデルを取得できる自動ニューラルネットワークトレーニングプルーニングフレームワーク「OTO」を提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1421
52
1316
25
1266
29
1239
24
14
1421
52
1316
25
1266
29
1239
24

 Microsoft、Win11 8月累積アップデートをリリース:セキュリティの向上、ロック画面の最適化など。
Aug 14, 2024 am 10:39 AM
Microsoft、Win11 8月累積アップデートをリリース:セキュリティの向上、ロック画面の最適化など。
Aug 14, 2024 am 10:39 AM
8 月 14 日のこのサイトのニュースによると、今日の 8 月のパッチ火曜日イベント日に、Microsoft は 22H2 および 23H2 用の KB5041585 更新プログラム、および 21H2 用の KB5041592 更新プログラムを含む、Windows 11 システム用の累積的な更新プログラムをリリースしました。 8 月の累積更新プログラムで上記の機器がインストールされた後、このサイトに添付されるバージョン番号の変更は次のとおりです。 21H2 機器のインストール後、機器のインストール後、バージョン番号は Build22000.314722H2 に増加しました。バージョン番号は Build22621.403723H2 に増加しました。 装置のインストール後、バージョン番号は Build22631.4037 に増加しました。 Windows 1121H2 の更新プログラムの主な内容は次のとおりです。 改善: 改善されました。
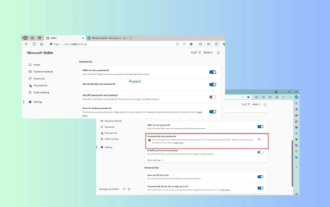 Microsoft Edgeアップグレード:自動パスワード保存機能が禁止? !ユーザーはショックを受けました!
Apr 19, 2024 am 08:13 AM
Microsoft Edgeアップグレード:自動パスワード保存機能が禁止? !ユーザーはショックを受けました!
Apr 19, 2024 am 08:13 AM
4 月 18 日のニュース: 最近、Canary チャネルを使用している Microsoft Edge ブラウザーの一部のユーザーが、最新バージョンにアップグレードした後、パスワードを自動的に保存するオプションが無効になっていることに気づいたと報告しました。調査の結果、これは機能のキャンセルではなく、ブラウザのアップグレード後の軽微な調整であることが判明しました。 Edge ブラウザを使用して Web サイトにアクセスする前に、Web サイトのログイン パスワードを保存するかどうかを尋ねるウィンドウがブラウザにポップアップ表示されるとユーザーが報告しました。保存を選択すると、Edge は次回ログインするときに保存されたアカウント番号とパスワードを自動的に入力するため、ユーザーは非常に便利になります。しかし、最新のアップデートはデフォルト設定を変更する微調整に似ています。ユーザーはパスワードを保存することを選択し、設定で保存されたアカウントとパスワードの自動入力を手動でオンにする必要があります。
 Microsoft Win11 の 7z および TAR ファイルを圧縮する機能は、24H2 バージョンから 23H2/22H2 バージョンにダウングレードされました
Apr 28, 2024 am 09:19 AM
Microsoft Win11 の 7z および TAR ファイルを圧縮する機能は、24H2 バージョンから 23H2/22H2 バージョンにダウングレードされました
Apr 28, 2024 am 09:19 AM
4 月 27 日のこのサイトのニュースによると、Microsoft は今月初めに Windows 11 Build 26100 プレビュー バージョン アップデートを Canary チャネルと Dev チャネルにリリースしました。これは Windows 1124H2 アップデートの RTM バージョンの候補になると予想されています。新バージョンの主な変更点は、ファイルエクスプローラー、Copilotの統合、PNGファイルメタデータの編集、TARおよび7z圧縮ファイルの作成など。 @PhantomOfEarth は、Microsoft が TAR および 7z 圧縮ファイルの作成など、24H2 バージョン (ゲルマニウム) の一部の機能を 23H2/22H2 (ニッケル) バージョンに継承していることを発見しました。図に示すように、Windows 11 は TAR のネイティブ作成をサポートします。
 Microsoft Edge ブラウザーのアップデート: ユーザー エクスペリエンスを向上させるために「画像のズームイン」機能を追加しました
Mar 21, 2024 pm 01:40 PM
Microsoft Edge ブラウザーのアップデート: ユーザー エクスペリエンスを向上させるために「画像のズームイン」機能を追加しました
Mar 21, 2024 pm 01:40 PM
3月21日のニュースによると、Microsoftは最近ブラウザ「Microsoft Edge」をアップデートし、実用的な「画像拡大」機能を追加した。 Edge ブラウザを使用している場合、ユーザーは画像を右クリックするだけで、ポップアップ メニューでこの新機能を簡単に見つけることができます。さらに便利なのは、ユーザーが画像の上にカーソルを置き、Ctrl キーをダブルクリックして、画像をズームインする機能をすぐに呼び出すこともできることです。編集者の理解によれば、新しくリリースされた Microsoft Edge ブラウザーは、Canary チャネルで新機能についてテストされています。安定版ブラウザでは、実用的な「画像拡大」機能も正式に開始し、より便利な画像閲覧体験をユーザーに提供しています。海外の科学技術メディアも注目
 Microsoft の全画面ポップアップは、Windows 10 ユーザーに急いで Windows 11 にアップグレードするよう促します
Jun 06, 2024 am 11:35 AM
Microsoft の全画面ポップアップは、Windows 10 ユーザーに急いで Windows 11 にアップグレードするよう促します
Jun 06, 2024 am 11:35 AM
6 月 3 日のニュースによると、Microsoft はすべての Windows 10 ユーザーに全画面通知を積極的に送信し、Windows 11 オペレーティング システムへのアップグレードを奨励しています。この移行には、ハードウェア構成が新しいシステムをサポートしていないデバイスが含まれます。 2015 年以来、Windows 10 は市場シェアの 70% 近くを占め、Windows オペレーティング システムとしての優位性を確固たるものにしました。しかし、そのシェアは82%を大きく上回り、2021年に発売されるWindows 11のシェアを大きく上回っている。 Windows 11 は発売から 3 年近く経ちますが、市場への浸透はまだ遅いです。 Microsoft は、Windows 10 の技術サポートを 2025 年 10 月 14 日以降に終了すると発表しました。
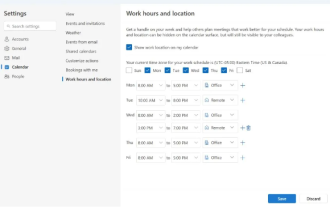 Microsoft、Outlook for Windowsの新バージョンを発売:カレンダー機能を包括的にアップグレード
Apr 27, 2024 pm 03:44 PM
Microsoft、Outlook for Windowsの新バージョンを発売:カレンダー機能を包括的にアップグレード
Apr 27, 2024 pm 03:44 PM
4 月 27 日のニュースで、Microsoft は Windows クライアント用 Outlook の新しいバージョンのテストを間もなくリリースすると発表しました。今回のアップデートでは主にカレンダー機能の最適化を行い、ユーザーの作業効率の向上と日々のワークフローのさらなる簡素化を目指しています。 Outlook for Windows クライアントの新バージョンの改良点は、より強力な予定表管理機能にあります。ユーザーは個人の勤務時間や位置情報をより簡単に共有できるようになり、会議の計画がより効率的にできるようになりました。さらに、Outlook にはユーザーフレンドリーな設定も追加されており、ユーザーは会議を自動的に早く終了したり、遅く開始したりするように設定できるため、会議室を変更したり、休憩したり、コーヒーを楽しんだりする際に、より柔軟に対応できるようになりました。 。によると
 画像の類似性比較にコントラスト損失を使用してシャム ネットワークを探索する
Apr 02, 2024 am 11:37 AM
画像の類似性比較にコントラスト損失を使用してシャム ネットワークを探索する
Apr 02, 2024 am 11:37 AM
はじめに コンピュータ ビジョンの分野では、画像の類似性を正確に測定することは、幅広い実用化を伴う重要なタスクです。画像検索エンジンから顔認識システム、コンテンツベースの推奨システムに至るまで、類似した画像を効果的に比較して見つける機能が重要です。シャム ネットワークとコントラスト損失を組み合わせることで、データ駆動型の方法で画像の類似性を学習するための強力なフレームワークが提供されます。このブログ投稿では、シャム ネットワークの詳細を掘り下げ、コントラスト損失の概念を探り、これら 2 つのコンポーネントがどのように連携して効果的な画像類似性モデルを作成するかを探っていきます。まず、Siamese ネットワークは、同じ重みとパラメータを共有する 2 つの同一のサブネットワークで構成されています。各サブネットワークは入力画像を特徴ベクトルにエンコードします。
 Microsoftは、2024年後半にWindows 11でNTLMを段階的に廃止し、Kerberos認証に完全に移行する予定です
Jun 09, 2024 pm 04:17 PM
Microsoftは、2024年後半にWindows 11でNTLMを段階的に廃止し、Kerberos認証に完全に移行する予定です
Jun 09, 2024 pm 04:17 PM
2024 年後半、マイクロソフトの公式セキュリティ ブログは、セキュリティ コミュニティからの呼びかけに応えてメッセージを公開しました。同社は、セキュリティを向上させるために、2024 年後半にリリースされる Windows 11 から NTLAN Manager (NTLM) 認証プロトコルを廃止する予定です。これまでの説明によれば、マイクロソフトは以前にも同様の動きを行っているという。昨年 10 月 12 日、Microsoft は公式プレス リリースで、NTLM 認証方法を段階的に廃止し、より多くの企業とユーザーに Kerberos への切り替えを促すことを目的とした移行計画を提案しました。 NTLM 認証をオフにした後にハードウェア接続されたアプリケーションやサービスで問題が発生する可能性がある企業を支援するために、Microsoft は IAKerb と
