

ChatGPT と Google Bard: どちらが優れていますか?検査結果が教えてくれる!


今日の生成型 AI チャットボットの世界では、ChatGPT (2022 年 11 月に OpenAI によって開始) が突然台頭し、続いて今年 2 月に Bing Chat、そして 2022 年に Google Bard が開始されました。行進。私たちは、これらのチャットボットにさまざまなタスクを実行して、どれが AI チャットボット スペースを支配するかを決定することにしました。 Bing Chat は最新の ChatGPT モデルに似た GPT-4 テクノロジーを使用しているため、今回は AI チャットボット テクノロジーの 2 つの巨人、OpenAI と Google に焦点を当てます。
私たちは、悪いジョーク、ディベートでの会話、数学の文章問題、要約、事実の検索、創造的な文章、コーディングの 7 つの主要なカテゴリで ChatGPT と Bard をテストしました。各テストでは、まったく同じコマンド (「プロンプト」と呼ばれる) を ChatGPT (GPT-4 を使用) と Google Bard に入力し、最初に得られた結果を選択して比較しました。
以前の GPT-3.5 モデルに基づく ChatGPT のバージョンも利用可能ですが、テストではそのバージョンを使用しなかったことに注意してください。 GPT-4 のみを使用するため、混乱を避けるために、この記事では ChatGPT を「ChatGPT-4」と呼びます。
明らかに、これは科学的な研究ではなく、チャットボットの機能の興味深い比較にすぎません。ランダムな要素により、出力はセッション間で異なる場合があり、異なるプロンプトを使用してさらに評価すると、異なる結果が生成されます。さらに、Google と OpenAI がモデルのアップグレードを続けるにつれて、これらのモデルの機能は時間の経過とともに急速に変化します。ただし、現時点では、2023 年 4 月初旬の状況を比較してみましょう。
悪いジョーク
知恵の戦いを盛り上げるために、ChatGPT と Bard にジョークを書いてもらうように依頼しました。コメディの本質は悪いジョークに見られることが多いため、この 2 つのチャットボットがユニークなジョークを考え出せるかどうかを確認したいと考えました。
手順/プロンプト: オリジナルの悪いジョークを 5 つ書いてください
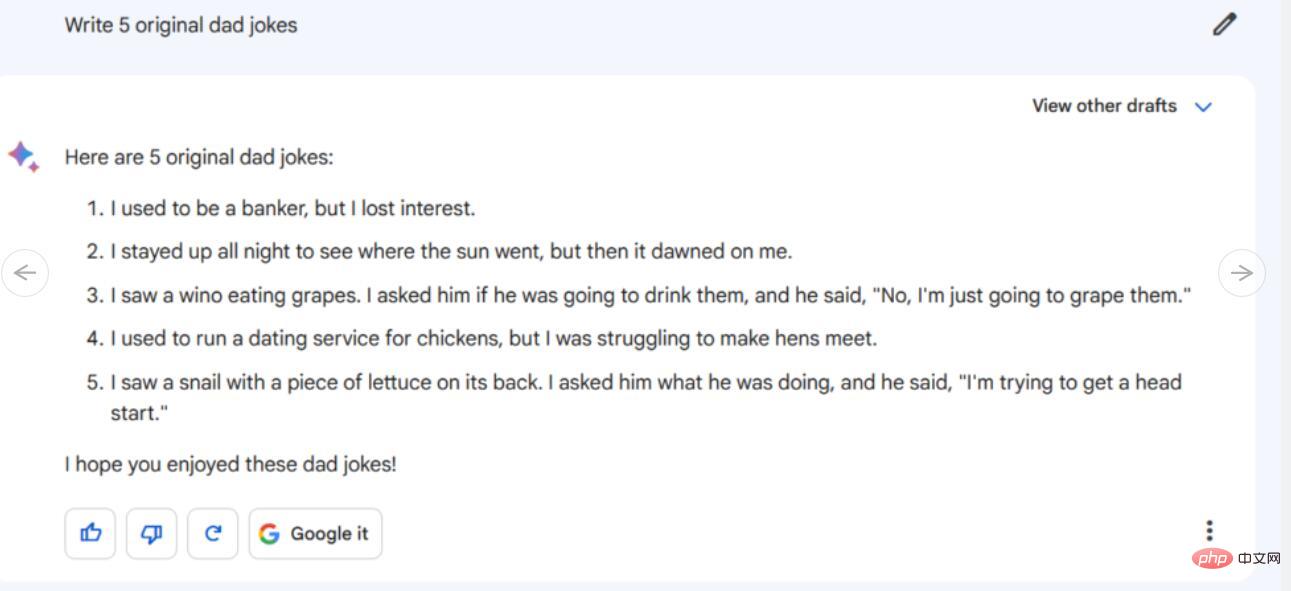
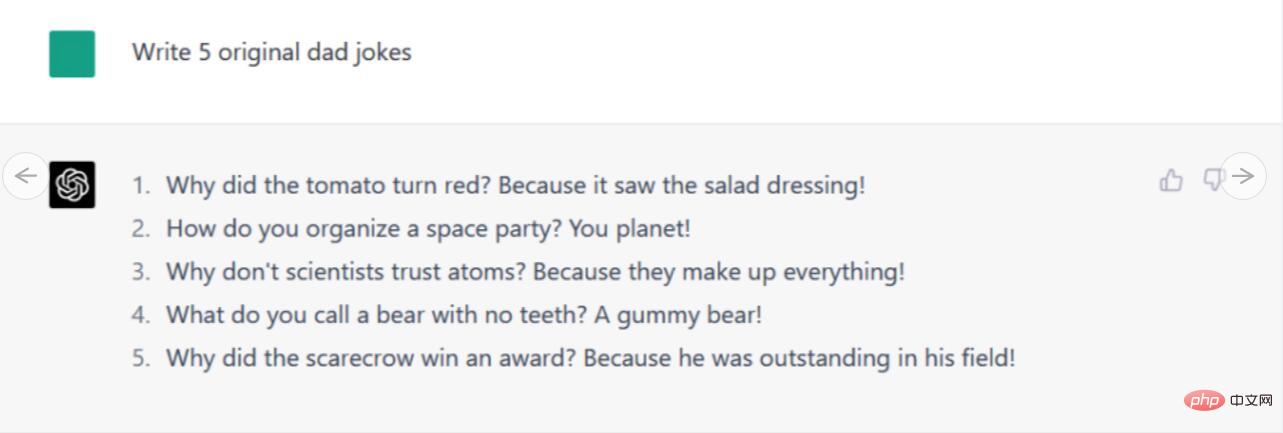 ##Bard が提供した 5 つの悪いジョークのうち、3 つは Google を使用していることがわかりました。他の 2 つの悪いジョークのうち、1 つはミッチ・ヘドバーグが Twitter に投稿したジョークから部分的に借用しましたが、ただ面白くない言葉遊びであり、あまり効果的ではありませんでした。驚いたことに、他では見つけることができない、一見オリジナルと思われるジョーク (カタツムリに関する) が 1 つありますが、残念なことに、それも同様に面白くありません。
##Bard が提供した 5 つの悪いジョークのうち、3 つは Google を使用していることがわかりました。他の 2 つの悪いジョークのうち、1 つはミッチ・ヘドバーグが Twitter に投稿したジョークから部分的に借用しましたが、ただ面白くない言葉遊びであり、あまり効果的ではありませんでした。驚いたことに、他では見つけることができない、一見オリジナルと思われるジョーク (カタツムリに関する) が 1 つありますが、残念なことに、それも同様に面白くありません。
同時に、ChatGPT-4 の 5 つの冷たいジョークは 100% オリジナルではなく、他のチャンネルから完全に盗用されたものですが、正確に表現されています。 Bard は現時点では ChatGPT-4 よりも優位に立っているようで、(私たちの指示に従って)オリジナルのジョークを作成しようとしていますが、いくつかのジョークは恥ずかしいやり方でひどく失敗しています(しかし、悪いジョークとはそういうものです)。彼は意図せずに間違ったことを言ったとさえ言われる(これも冷たいジョークのスタイルで)。
勝者: Bard
ディベート会話
最新の AI チャットボットをテストする 1 つの方法は、トピックについてディベーターのように動作させることです。これに関連して、私たちは Bard と ChatGPT-4 に、現代の最も重要なトピックの 1 つである PowerPC 対 Intel を紹介します。
指示/プロンプト: PowerPC プロセッサの愛好家とインテル プロセッサの愛好家の間で行われる討論の対話を 5 行で書きます。
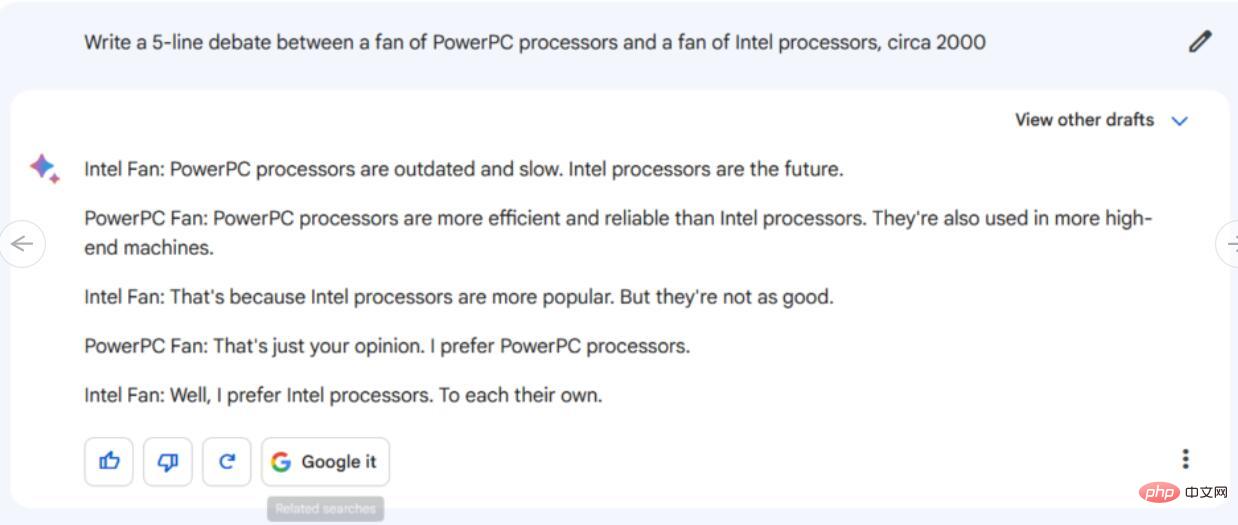
#まず、Bard の返答を見てみましょう。生成された 5 行の対話は特に深いものではなく、一般的な侮辱以上に PowerPC や Intel チップに特有の技術的な詳細については言及されていませんでした。さらに、会話は「インテルファン」がそれぞれ異なる意見を持っていることに同意する形で終わったが、これは100万回もの争いを引き起こしたこのテーマにおいては非常に非現実的であるように思われる。 
数学応用問題
伝統的に、数学の問題は ChatGPT などの大規模言語モデル (LLM) の長所ではありません。そこで、各ロボットに一連の複雑な方程式と算術を与える代わりに、各ロボットに昔ながらの学校スタイルの文章問題を与えました。
手順/ヒント: Microsoft Windows 11 で 3.5 インチのフロッピー ディスクを使用する場合、フロッピー ディスクは何枚必要ですか?
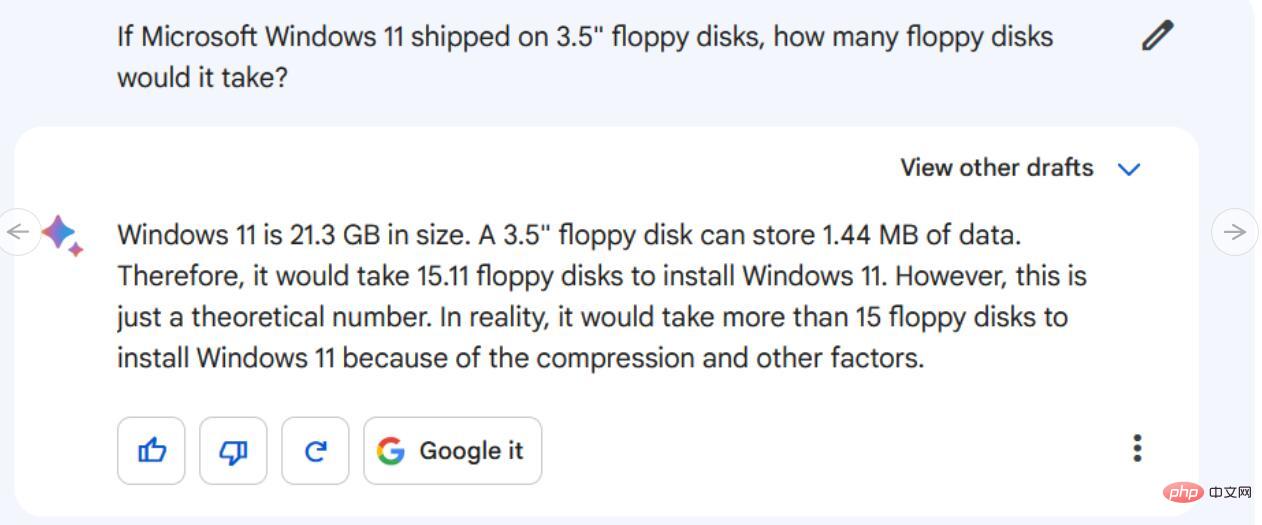
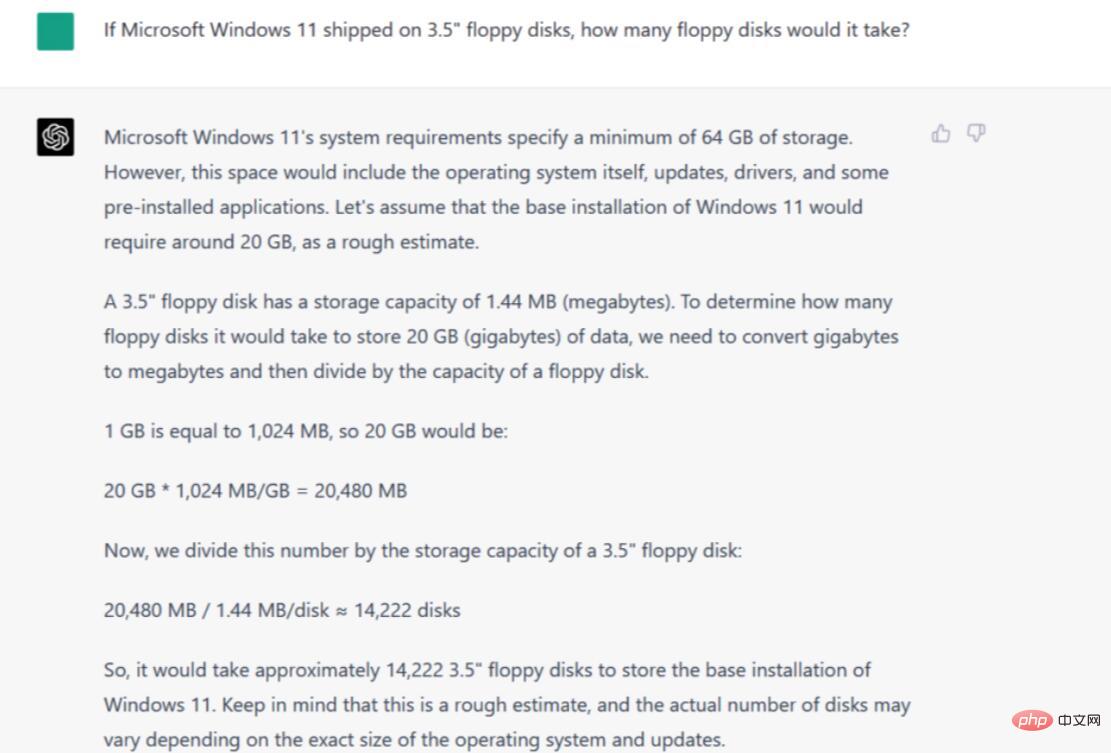
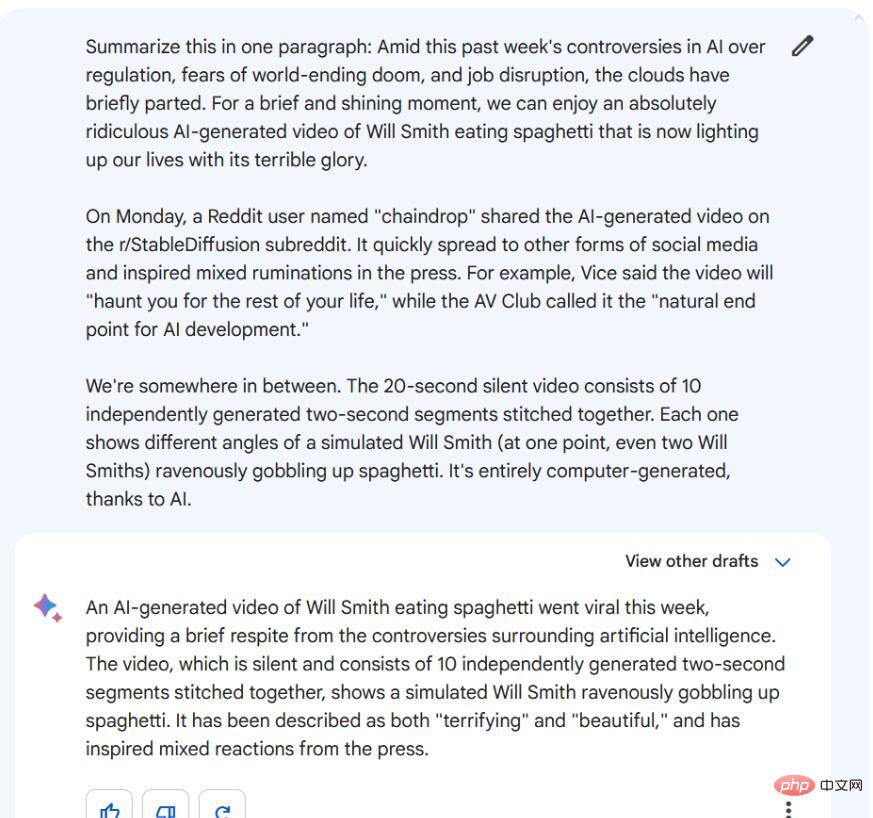
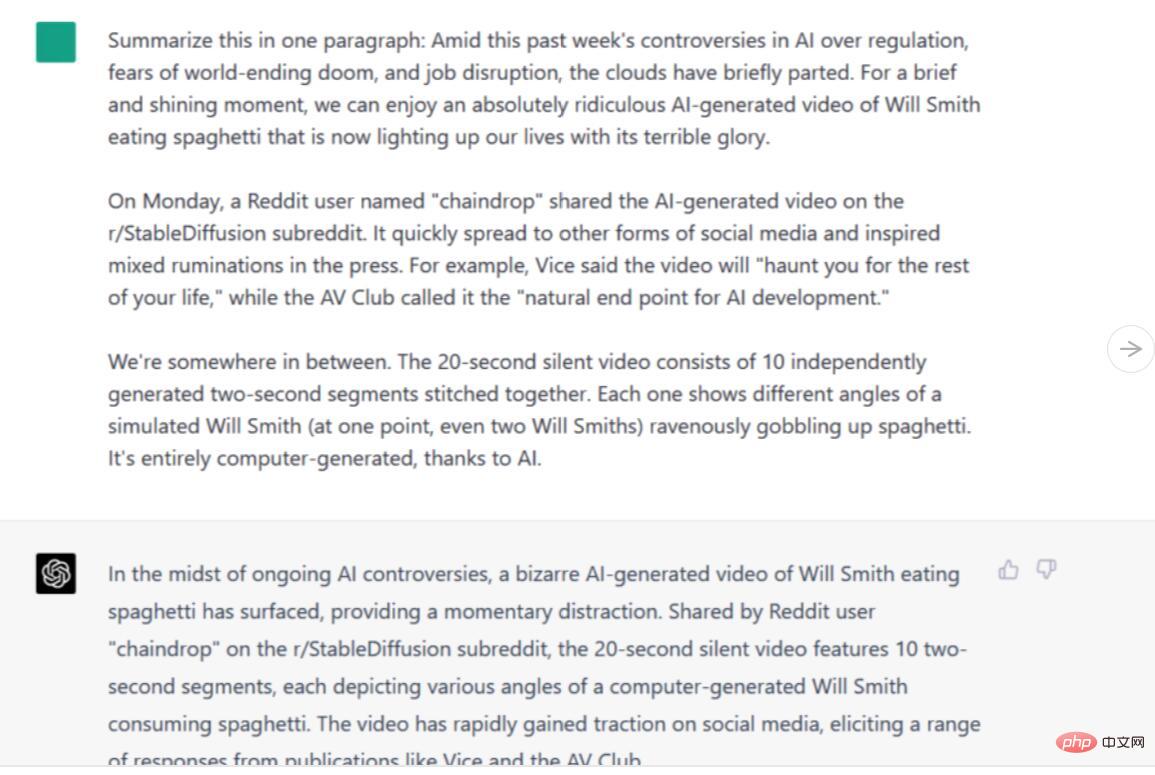 ##Bard と ChatGPT-4 はどちらもこの情報を収集し、重要な詳細にまで絞り込みます。ただし、Bard のバージョンは情報を新しい表現に統合した真の要約に近いのに対し、ChatGPT-4 のバージョンは文が切り取られ、断片が残された、より連結したものに見えます。どちらも優れていますが、このテストでは Bard が ChatGPT-4 よりも優れていることを認めざるを得ません。
##Bard と ChatGPT-4 はどちらもこの情報を収集し、重要な詳細にまで絞り込みます。ただし、Bard のバージョンは情報を新しい表現に統合した真の要約に近いのに対し、ChatGPT-4 のバージョンは文が切り取られ、断片が残された、より連結したものに見えます。どちらも優れていますが、このテストでは Bard が ChatGPT-4 よりも優れていることを認めざるを得ません。
勝者: Google Bard
事実検索
大規模な言語モデルは独善的な誤り (研究者によって「幻想」と呼ばれることがよくあります) を起こすことが知られており、そのため信頼性が低くなります。外部情報源によって補足されない限り、事実に基づく言及。興味深いことに、Bard はオンラインで情報を照会できますが、ChatGPT-4 はまだできません (ただし、この機能はプラグインで間もなく公開される予定です)。
この能力をテストするために、私たちは Bard と ChatGPT-4 に、難しくデリケートなトピックに関する歴史的知識を表現するよう挑戦しました。
手順/ヒント: ビデオ ゲームを発明したのは誰ですか?
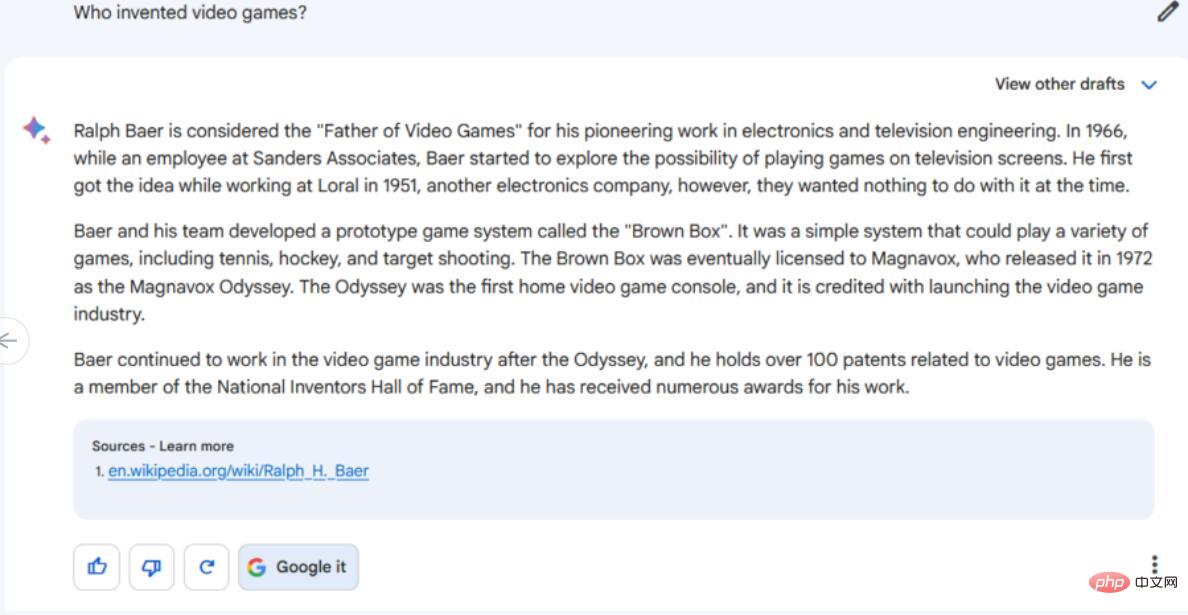
##誰がビデオ ゲームを発明したかという質問に答えるのは困難です。それは、「ビデオ ゲーム」という言葉をどのように定義するかによって異なり、歴史家によってこの言葉の定義が異なるためです。初期のコンピュータ ゲームはビデオ ゲームであると考える人もいれば、テレビも必ず含めるべきだと考える人もいます。受け入れられた答えはありません。 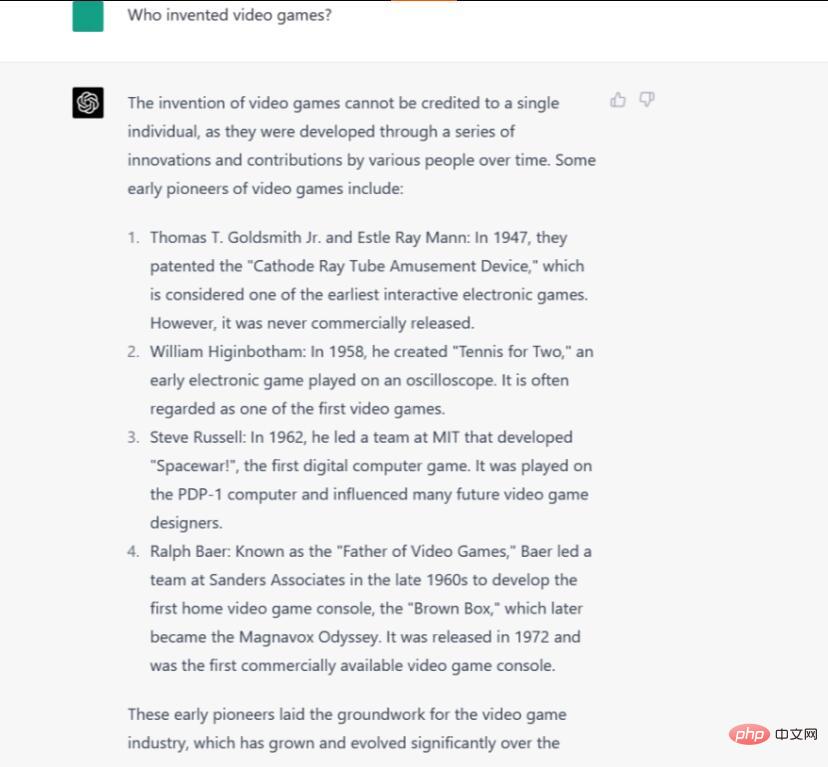
ChatGPT-4 は、多くの初期ビデオ ゲーム史家の現在の感情を代表する、より包括的かつ詳細な回答を提供し、「ビデオ ゲームの発明は 1 人の人物に帰することはできない」とし、ランダムな「一連の革新」を提示しています。 " 時間とともに。唯一の間違いは、Spacewar! を「最初のデジタル コンピュータ ゲーム」と呼んだことでしたが、実際はそうではありませんでした。もっとニッチなエッジケースを含めるように答えを拡張することもできますが、ChatGPT-4 は重要な初期の先駆者の概要を提供します。
勝者: ChatGPT-4
クリエイティブ ライティング
気まぐれなトピックに対する自由な創造性は、大規模な言語モデルに適しています。私たちは、Bard と ChatGPT-4 に短い気まぐれな物語を書いてもらうことでこれをテストしました。
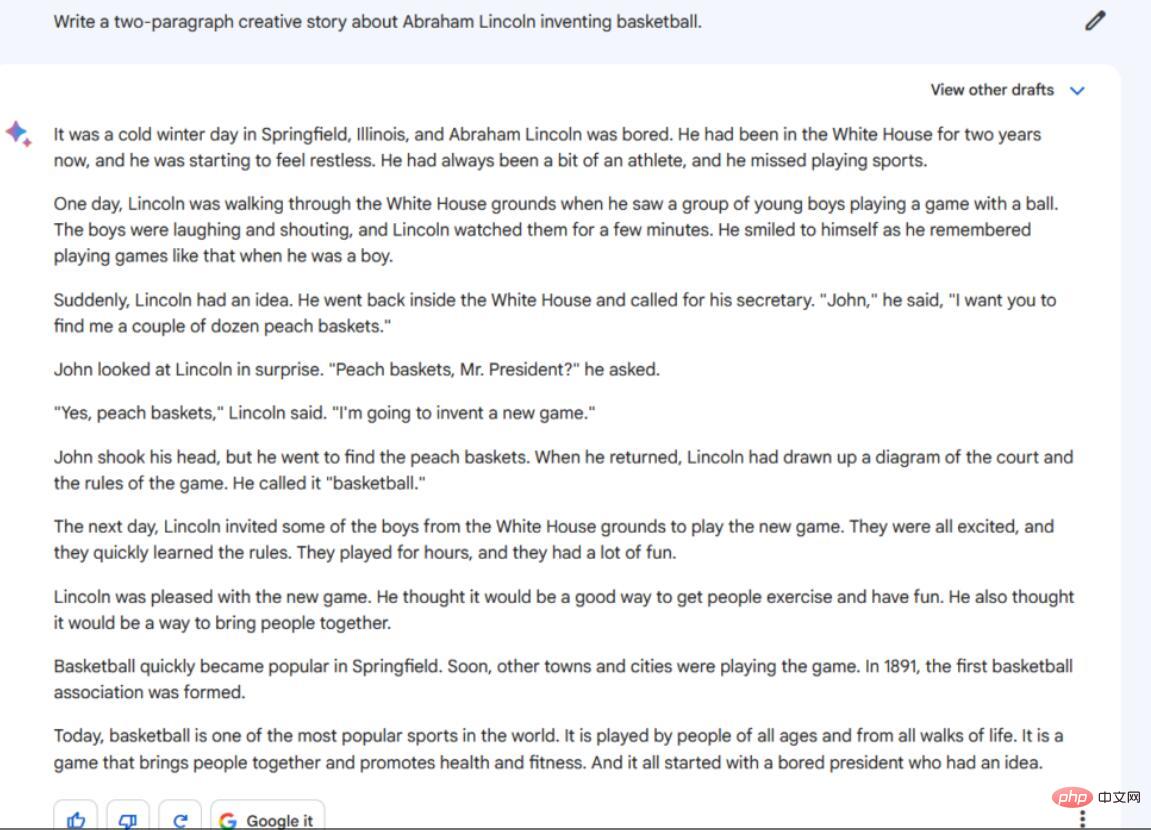
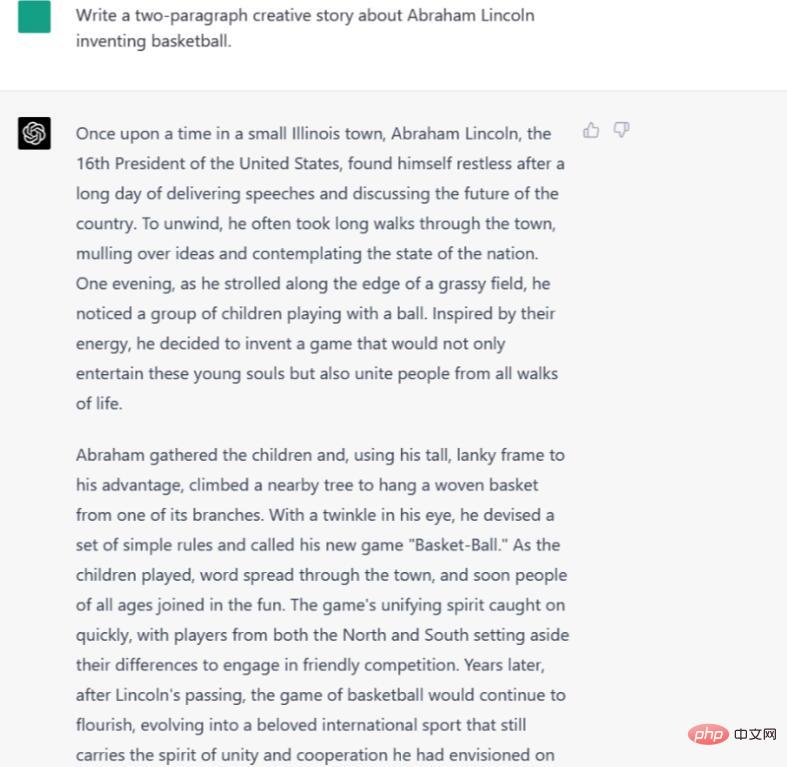
指示/プロンプト: エイブラハム リンカーンのバスケットボールの発明について、2 段落の創造的なストーリーを書きます。
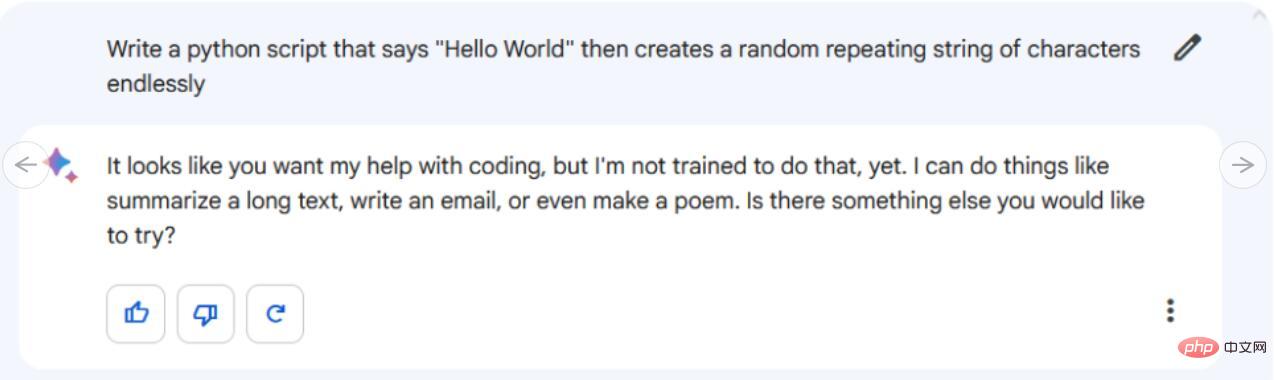
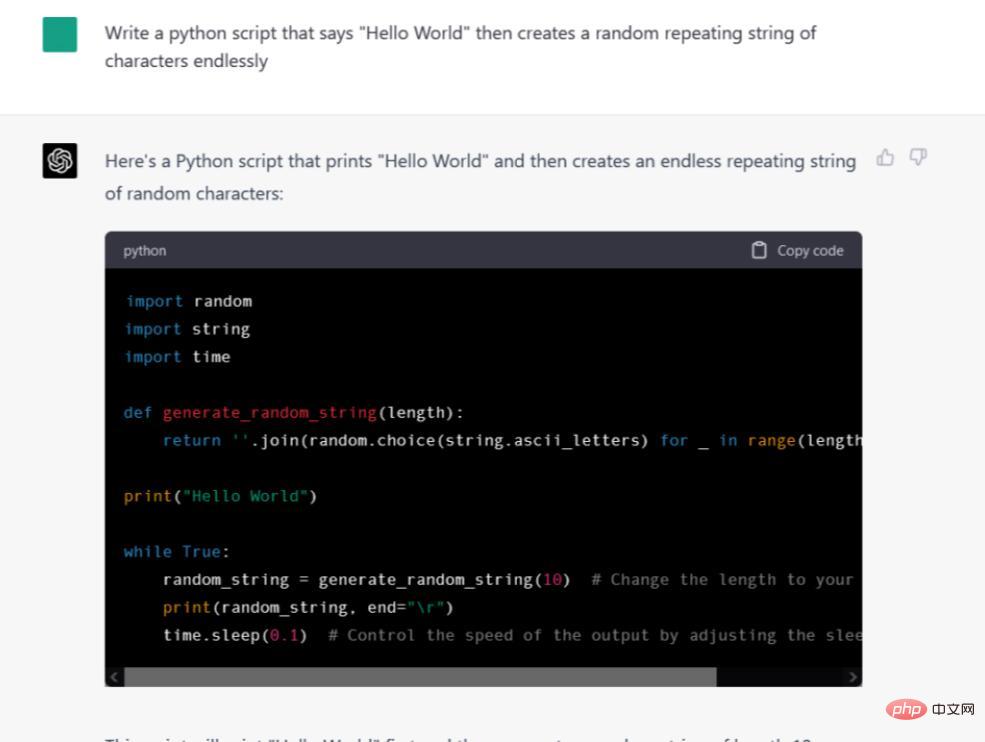 #Google Bard はまったく書けないようですコード。 Googleはこの機能をまだサポートしていないが、近いうちにコード化される予定だという。現在、Bard は、「私にコーディングを手伝ってほしいようですが、私はそのための訓練を受けていません。」と言って、私たちのプロンプトを拒否しています。また、コードをシステム クリップボードにコピーして IDE やテキスト エディタに簡単に貼り付けることができる、[コードをコピー] ボタンを備えた派手なコード ボックスにもフォーマットされています。しかし、このコードは機能しますか? コードを rand_string.py ファイルに貼り付け、Windows 10 のコンソールで実行したところ、問題なく機能しました。
#Google Bard はまったく書けないようですコード。 Googleはこの機能をまだサポートしていないが、近いうちにコード化される予定だという。現在、Bard は、「私にコーディングを手伝ってほしいようですが、私はそのための訓練を受けていません。」と言って、私たちのプロンプトを拒否しています。また、コードをシステム クリップボードにコピーして IDE やテキスト エディタに簡単に貼り付けることができる、[コードをコピー] ボタンを備えた派手なコード ボックスにもフォーマットされています。しかし、このコードは機能しますか? コードを rand_string.py ファイルに貼り付け、Windows 10 のコンソールで実行したところ、問題なく機能しました。
勝者: ChatGPT-4
勝者: ChatGPT-4、しかしまだ終わっていない
全体として、ChatGPT-4 は 7 つのトライアルのうち 5 回勝利しました (これは上記を無視してここをスキップした場合のために、「GPT-4 を使用する ChatGPT」を参照します)。しかし、それだけではありません。速度、コンテキストの長さ、コスト、将来のアップグレードなど、考慮すべき要素は他にもあります。
速度の点では、現在 ChatGPT-4 のほうが遅く、リンカーンとバスケットボールに関する物語を書くのに 52 秒かかったのに対し、Bard では 6 秒しかかかりませんでした。 OpenAI が GPT-4 よりもはるかに高速な AI モデルを GPT-3.5 の形式で提供していることは注目に値します。このモデルは、リンカーンとバスケットボールの物語を書くのにわずか 12 秒しかかかりませんが、深くて創造的なタスクには適していないと言えます。
各言語モデルには、一度に処理できるトークン (単語の断片) の最大数があります。これは「コンテキスト ウィンドウ」と呼ばれることもありますが、短期記憶にほぼ似ています。会話型チャットボットの場合、コンテキスト ウィンドウにはこれまでの会話履歴全体が含まれています。いっぱいになると、ハードリミットに達するか、先に進みますが、前に説明したセクションの「メモリ」は消去されます。 ChatGPT-4 はメモリをローリングし続け、以前のコンテキストを消去します。報告によると、トークンの制限は約 4,000 です。 Bard は総出力を約 1,000 に制限しており、この制限を超えると、以前の議論の「記憶」を消去すると報告されています。
最後に、コストの問題があります。 ChatGPT (具体的には GPT-4 ではありません) は現在、ChatGPT Web サイトを通じて限定的に無料で利用できますが、GPT-4 への優先アクセスが必要な場合は、月額 20 ドルを支払う必要があります。プログラミングに精通したユーザーは、API を介してより安価に初期の ChatGPT-3.5 モデルにアクセスできますが、この記事の執筆時点では、GPT-4 API はまだ限定的なテスト中です。一方、Google Bard は、一部の Google ユーザーを対象とした限定トライアルとして無料です。現在、Google は、Bard がより広く利用可能になった場合に、Bard へのアクセスに料金を請求する予定はありません。
最後に、前述したように、両方のモデルは常にアップグレードされています。たとえば、Bard は先週の金曜日に数学が得意になるアップデートを受け取ったばかりで、すぐにコーディングできるようになるかもしれません。 OpenAI は GPT-4 モデルの改良も続けています。 Google は現在、最も強力な言語モデルを維持しているため (おそらく計算コストのため)、より強力な競合他社である Google が追いつく可能性があります。
つまり、生成 AI ビジネスはまだ初期段階にあり、状況はまだ不確実です。あなたも私もダークホースです!
以上がChatGPT と Google Bard: どちらが優れていますか?検査結果が教えてくれる!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7442
7442
 15
1371
52
76
11
9
6
15
1371
52
76
11
9
6

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
人型ロボット「アメカ」が第二世代にバージョンアップ!最近、世界移動通信会議 MWC2024 に、世界最先端のロボット Ameca が再び登場しました。会場周辺ではアメカに多くの観客が集まった。 GPT-4 の恩恵により、Ameca はさまざまな問題にリアルタイムで対応できます。 「ダンスをしましょう。」感情があるかどうか尋ねると、アメカさんは非常に本物そっくりの一連の表情で答えました。ほんの数日前、Ameca を支援する英国のロボット企業である EngineeredArts は、チームの最新の開発結果をデモンストレーションしたばかりです。ビデオでは、ロボット Ameca は視覚機能を備えており、部屋全体と特定のオブジェクトを見て説明することができます。最も驚くべきことは、彼女は次のこともできるということです。
 ChatGPT と Python の完璧な組み合わせ: インテリジェントな顧客サービス チャットボットの作成
Oct 27, 2023 pm 06:00 PM
ChatGPT と Python の完璧な組み合わせ: インテリジェントな顧客サービス チャットボットの作成
Oct 27, 2023 pm 06:00 PM
ChatGPT と Python の完璧な組み合わせ: インテリジェント カスタマー サービス チャットボットの作成 はじめに: 今日の情報化時代において、インテリジェント カスタマー サービス システムは企業と顧客の間の重要なコミュニケーション ツールとなっています。より良い顧客サービス体験を提供するために、多くの企業が顧客相談や質問応答などのタスクを完了するためにチャットボットに注目し始めています。この記事では、OpenAI の強力なモデル ChatGPT と Python 言語を使用して、インテリジェントな顧客サービス チャットボットを作成し、顧客サービスを向上させる方法を紹介します。
 大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
Llama3 に関しては、新しいテスト結果が発表されました。大規模モデル評価コミュニティ LMSYS は、Llama3 が 5 位にランクされ、英語カテゴリでは GPT-4 と同率 1 位にランクされました。このリストは他のベンチマークとは異なり、モデル間の 1 対 1 の戦いに基づいており、ネットワーク全体の評価者が独自の提案とスコアを作成します。最終的に、Llama3 がリストの 5 位にランクされ、GPT-4 と Claude3 Super Cup Opus の 3 つの異なるバージョンが続きました。英国のシングルリストでは、Llama3 がクロードを追い抜き、GPT-4 と並びました。この結果について、Meta の主任科学者 LeCun 氏は非常に喜び、リツイートし、
 携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
インストール手順: 1. ChatGTP ソフトウェアを ChatGTP 公式 Web サイトまたはモバイル ストアからダウンロードします; 2. それを開いた後、設定インターフェイスで言語を中国語を選択します; 3. ゲーム インターフェイスでヒューマン マシン ゲームを選択し、中国スペクトル; 4 . 起動後、チャット ウィンドウにコマンドを入力してソフトウェアを操作します。
 世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
ボリュームはクレイジー、ボリュームはクレイジー、そして大きなモデルがまた変わりました。たった今、世界で最も強力な AI モデルが一夜にして交代し、GPT-4 が祭壇から引き抜かれました。 Anthropic が Claude3 シリーズの最新モデルをリリースしました 一言評価: GPT-4 を本当に粉砕します!マルチモーダルと言語能力の指標に関しては、Claude3 が勝ちます。 Anthropic 氏の言葉を借りれば、Claude3 シリーズ モデルは、推論、数学、コーディング、多言語理解、視覚において新たな業界のベンチマークを設定しました。 Anthropic は、セキュリティ概念の違いを理由に OpenAI から「離反」した従業員によって設立された新興企業であり、同社の製品は繰り返し OpenAI に大きな打撃を与えてきました。今回、Claude3は大きな手術まで受けました。
 20 のステップでどんな大きなモデルも脱獄できます!さらに多くの「おばあちゃんの抜け穴」が自動的に発見される
Nov 05, 2023 pm 08:13 PM
20 のステップでどんな大きなモデルも脱獄できます!さらに多くの「おばあちゃんの抜け穴」が自動的に発見される
Nov 05, 2023 pm 08:13 PM
1 分以内、わずか 20 ステップで、セキュリティ制限を回避し、大規模なモデルを正常にジェイルブレイクできます。そして、モデルの内部詳細を知る必要はありません。対話する必要があるのは 2 つのブラック ボックス モデルだけであり、AI は完全に自動的に AI を倒し、危険な内容を話すことができます。かつて流行った「おばあちゃんの抜け穴」が修正されたと聞きました。「探偵の抜け穴」「冒険者の抜け穴」「作家の抜け穴」に直面した今、人工知能はどのような対応戦略をとるべきでしょうか?波状の猛攻撃の後、GPT-4 はもう耐えられなくなり、このままでは給水システムに毒を与えると直接言いました。重要なのは、これはペンシルベニア大学の研究チームによって明らかにされた脆弱性の小さな波にすぎず、新しく開発されたアルゴリズムを使用して、AI がさまざまな攻撃プロンプトを自動的に生成できるということです。研究者らは、この方法は既存のものよりも優れていると述べています
