

なんという騒音でしょう! ChatGPT は言語を理解できますか? PNAS:まず「理解」とは何かを勉強しましょう

#機械がこの質問について考えることができるかどうかは、潜水艦が泳げるかどうかを尋ねるようなものです。 ——Dijkstra
ChatGPT がリリースされるずっと前から、業界は大規模モデルによってもたらされる変化の匂いをすでに感じていました。 昨年 10 月 14 日、サンタフェ研究所のメラニー・ミッチェル教授とデビッド・C・クラカウアー教授は、arXiv 上で大規模な事前研究が行われるかどうかに関する議論を包括的に調査したレビューを発表しました。訓練された言語モデルは言語を理解できるため、この記事では賛成派と反対派の議論、およびこれらの議論から導き出される広範な知能科学における重要な問題について説明しています。


大規模な事前トレーニング モデルは、基礎モデルとも呼ばれ、数十億から数兆のパラメータ (重み) を持つディープ ニューラル ネットワークであり、大規模な自然言語コーパス (オンライン テキスト、オンライン ブックなどを含む) で使用されます。 「事前トレーニング」を実行した後。
トレーニング中のモデルのタスクは、入力文の欠落部分を予測することであるため、この方法は「自己教師あり学習」とも呼ばれ、結果として得られるネットワークは複雑になります。統計モデル を使用すると、トレーニング データ内の単語やフレーズが互いにどのように関連しているかを取得できます。
このモデルは、自然言語を生成するために使用でき、特定の自然言語タスクに合わせて微調整したり、「ユーザーの意図」によりよく一致するようにさらにトレーニングしたりできますが、専門家以外の人にとっては言語がどのように正確であるかモデルがこれらのタスクを達成できるかどうかは、科学者にとって謎のままです。
ニューラル ネットワークの内部動作はほとんど不透明であり、ニューラル ネットワークを構築する研究者でさえ、この規模のシステムに対する直感には限界があります。

##あるしきい値を超えると、まるで宇宙人が突然現れて、恐ろしいほど人間的な方法で私たちとコミュニケーションをとることができるようです。現時点で明らかなことが 1 つだけあります。大きな言語モデルは人間ではなく、その行動のいくつかの側面は知性があるように見えますが、もし人間の知性ではないとしたら、その知性の性質は何でしょうか?
#大規模な言語モデルのパフォーマンスは衝撃的ですが、最先端の LLM は脆弱性や人的ミス以外のミスが依然として発生しやすいです。 ただし、パラメータの数とトレーニング コーパスのサイズが拡大することで、ネットワークのパフォーマンスが大幅に向上していることがわかり、この分野の一部の研究者もこれによって導かれています。十分な大きさのネットワークとトレーニング データセット、言語モデル (マルチモーダル バージョン)、そしておそらくマルチモーダル バージョンが存在する限り、人間レベルの知性と理解につながると主張することはできません。 人工知能の新しいスローガンが登場しました: 必要なのはスケールだけです! この声明は、人工知能研究コミュニティにおける大規模な言語モデルに関する議論も反映しています: あるグループは、言語モデルが真に理解できると信じています。言語 を習得しており、一般的な方法で推論することができます(ただし、まだ人間のレベルには達していません)。 たとえば、Google の LaMDA システムはテキストで事前トレーニングされ、その後会話タスクで微調整されるため、非常に幅広いドメインのユーザーと会話できるようになります。理解陣営を支持する VS 理解陣営に反対する
もう一方の学派は、GPT-3 や LaMDA などの大規模な事前トレーニング済みモデルは、言語出力がどれほど流暢であっても、これらのモデルには実践的な経験がなく、世界のメンタルモデルがないため、理解することはできません。 
機械の理解は人間とは異なります
「LLM の理解」議論の双方がそれぞれの見解を裏付ける十分な直観を持っていますが、現在利用可能な認知科学に基づいた理解に関する洞察があります。 LLM に関するこのような質問に答えます。
実際、一部の研究者は心理テスト (もともと人間の理解と推論メカニズムを評価するために設計された) を LLM に適用し、場合によっては、LLM が実際に理論的に人間のように思考していることを発見しました。テストの反応や推論評価における人間のような能力とバイアス。
これらのテストは人間の汎化能力を評価するための信頼できる手段と考えられていますが、人工知能システムの場合はそうではない可能性があります。
大規模な言語モデルには、トレーニング データと入力内のトークンの間の相関関係を学習する特別な機能があり、この相関関係を使用して問題を解決できます。これとは対照的に、人間は、次のような凝縮された概念を使用します。彼らの実世界での経験。
人間向けに設計されたテストを LLM に適用する場合、結果の解釈は、これらのモデルには当てはまらない可能性のある人間の認知に関する仮定に依存する可能性があります。
進歩するには、科学者は、私たちが作り出した新しい形の「奇妙な」知能を含む、さまざまな種類の知能と理解のメカニズムを理解するための新しいベンチマークと検出方法を開発する必要があります。 、心のような存在」、そしていくつかの関連作業がすでに行われています。
モデルが大きくなり、より高機能なシステムが開発されるにつれて、LLM の理解をめぐる議論は、「理解」が意味のあるものになるように、「知能の科学を拡張する」必要性を浮き彫りにしています。人間にとっても機械にとっても。
神経科学者のテレンス・セジノウスキー氏は、LLMの知能に関する専門家のさまざまな意見は、自然知能に基づく古い考え方では十分ではないことを示していると指摘しています。
LLM と関連モデルが、前例のない規模で統計的相関を利用することで成功することができれば、おそらくそれらは、並外れた形式の超人的予測を達成できる「新しい理解の形式」とみなされる可能性があります。 DeepMind の AlphaZero および AlphaFold システムなどの機能は、それぞれチェスとタンパク質構造予測の分野に「エキゾチックな」形式の直観をもたらします。
したがって、近年、人工知能の分野では、とらえどころのない目標を追求する中で、新しい理解モード、おそらくまったく新しい概念を備えたマシンが作成されてきたと言えます。本質的な側面で進歩が見られるにつれて、これらの新しい概念はさらに充実していくでしょう。
広範なコーディング知識を必要とし、高いパフォーマンス要件を必要とする問題では、引き続き大規模な統計モデルの開発が促進される一方、限られた知識と強力な因果メカニズムを持つ問題では、理解が容易になります。人間の知性。
将来の課題は、さまざまな形の知能の詳細な理解を明らかにし、その長所と限界を識別し、これらの真に異なる認知モデルを統合する方法を学ぶための新しい科学的手法を開発することです。 。
参考文献:
https://www.pnas.org/doi/10.1073/pnas.2215907120
以上がなんという騒音でしょう! ChatGPT は言語を理解できますか? PNAS:まず「理解」とは何かを勉強しましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7508
7508
 15
1378
52
78
11
19
58
15
1378
52
78
11
19
58

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 iPhoneで言語を変更する3つの方法
Feb 02, 2024 pm 04:12 PM
iPhoneで言語を変更する3つの方法
Feb 02, 2024 pm 04:12 PM
iPhone が最も使いやすい電子機器の 1 つであることは周知の事実であり、その理由の 1 つは、自分好みに簡単にカスタマイズできることです。個人設定では、iPhone のセットアップ時に選択した言語とは別の言語に変更できます。複数の言語に精通している場合、または iPhone の言語設定が間違っている場合は、以下で説明するように変更できます。 iPhoneの言語を変更する方法[3つの方法] iOSでは、ユーザーはさまざまなニーズに合わせてiPhoneの優先言語を自由に切り替えることができます。 Siri との対話言語を変更して、音声アシスタントとのコミュニケーションを容易にすることができます。同時に、ローカルキーボードを使用する場合、複数の言語を簡単に切り替えることができ、入力効率が向上します。
 携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
インストール手順: 1. ChatGTP ソフトウェアを ChatGTP 公式 Web サイトまたはモバイル ストアからダウンロードします; 2. それを開いた後、設定インターフェイスで言語を中国語を選択します; 3. ゲーム インターフェイスでヒューマン マシン ゲームを選択し、中国スペクトル; 4 . 起動後、チャット ウィンドウにコマンドを入力してソフトウェアを操作します。
 Win10コンピュータの言語を中国語に設定するにはどうすればよいですか?
Jan 05, 2024 pm 06:51 PM
Win10コンピュータの言語を中国語に設定するにはどうすればよいですか?
Jan 05, 2024 pm 06:51 PM
コンピュータ システムをインストールしただけで、システムが英語になっている場合があります。この場合、コンピュータの言語を中国語に変更する必要があります。それでは、win10 システムでコンピュータの言語を中国語に変更するにはどうすればよいでしょうか?具体的な操作方法を説明します。 。 win10 でコンピューターの言語を中国語に変更する方法 1. コンピューターの電源を入れ、左下隅にあるスタート ボタンをクリックします。 2. 左側の設定オプションをクリックします。 3. 開いたページで「時刻と言語」を選択します 4. 開いたら、左側の「言語」をクリックします 5. ここで、希望するコンピューター言語を設定できます。
 ChatGPT と Java を使用してインテリジェントなチャットボットを開発する方法
Oct 28, 2023 am 08:54 AM
ChatGPT と Java を使用してインテリジェントなチャットボットを開発する方法
Oct 28, 2023 am 08:54 AM
この記事では、ChatGPT と Java を使用してインテリジェントなチャットボットを開発する方法を紹介し、いくつかの具体的なコード例を示します。 ChatGPT は、OpenAI によって開発された生成事前トレーニング トランスフォーマーの最新バージョンです。これは、自然言語を理解し、人間のようなテキストを生成できるニューラル ネットワーク ベースの人工知能テクノロジーです。 ChatGPT を使用すると、適応型チャットを簡単に作成できます
 中国でもchatgptは使えますか?
Mar 05, 2024 pm 03:05 PM
中国でもchatgptは使えますか?
Mar 05, 2024 pm 03:05 PM
chatgpt は中国でも使用できますが、香港やマカオでも登録できません。ユーザーが登録したい場合は、外国の携帯電話番号を使用して登録できます。登録プロセス中にネットワーク環境を切り替える必要があることに注意してください。外国のIP。
 ChatGPT PHP を使用してインテリジェントな顧客サービス ロボットを構築する方法
Oct 28, 2023 am 09:34 AM
ChatGPT PHP を使用してインテリジェントな顧客サービス ロボットを構築する方法
Oct 28, 2023 am 09:34 AM
ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築する方法 はじめに: 人工知能技術の発展に伴い、顧客サービスの分野でロボットの使用が増えています。 ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築すると、企業はより効率的でパーソナライズされた顧客サービスを提供できるようになります。この記事では、ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築する方法を紹介し、具体的なコード例を示します。 1. ChatGPTPHP をインストールし、ChatGPTPHP を使用してインテリジェントな顧客サービス ロボットを構築します。
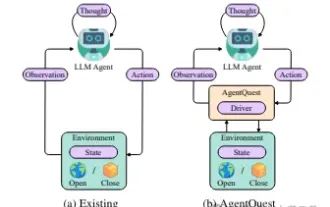 エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest
Apr 11, 2024 pm 08:52 PM
エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest
Apr 11, 2024 pm 08:52 PM
大規模モデルの継続的な最適化に基づいて、LLM エージェント - これらの強力なアルゴリズム エンティティは、複雑な複数ステップの推論タスクを解決する可能性を示しています。自然言語処理から深層学習に至るまで、LLM エージェントは徐々に研究や業界の焦点になりつつあります。LLM エージェントは、人間の言語を理解して生成するだけでなく、戦略を策定し、多様な環境でタスクを実行し、API 呼び出しやコーディングを使用して構築することもできます。ソリューション。この文脈において、AgentQuest フレームワークの導入はマイルストーンであり、LLM エージェントの評価と進歩のためのモジュール式ベンチマーク プラットフォームを提供するだけでなく、研究者にこれらのエージェントのパフォーマンスを追跡および改善するための強力なツールも提供します。より細かいレベル
