

システム設計の芸術: HPC および AI アプリケーションが主流になったとき、GPU アーキテクチャはどこに向かうべきでしょうか?


私たちは何年も前に、十分なデータを備えた畳み込みニューラル ネットワークを使用して AI ワークロードをトレーニングすることが成長トレンドになりつつあると述べました。世界中の HPC (ハイ パフォーマンス コンピューティング) センターは、長年にわたってこの負荷を NVIDIA の GPU 処理に引き渡してきました。シミュレーションやモデリングなどのタスクでは、GPU のパフォーマンスは非常に優れています。本質的に、HPC シミュレーション/モデリングと AI トレーニングは実際には一種の調和収束であり、GPU は超並列プロセッサとして、この種の作業の実行に特に優れています。
しかし、2012 年以降、AI 革命が正式に勃発し、画像認識ソフトウェアの精度が初めて人間を超えるレベルに向上しました。したがって、同様の GPU 上での HPC と AI の効率的な処理の共通性がどれくらい続くかについては、非常に興味があります。そこで 2019 年の夏、モデルの改良と反復を通じて、混合精度演算ユニットを使用して、Linpack ベンチマークでの FP64 計算と同じ結果を達成しようとしました。翌年、Nvidia が「Ampere」GA100 GPU を発売する前に、私たちは HPC と AI の処理性能を再度テストしようとしました。当時、Nvidia はまだ「Ampere」A100 GPU を発売していなかったので、グラフィック カードの巨人は混合精度の tensor コアで AI モデルをトレーニングすることに正式に傾いていませんでした。答えはもちろん明らかです。FP64 ベクトル ユニット上の HPC ワークロードには、GPU のパフォーマンスを最大化するためにいくつかのアーキテクチャの調整が必要です。それらがちょっとした「二級市民」であることは疑いの余地がありません。しかし、当時はまだすべてが可能でした。
今年初めに Nvidia の「Hopper」GH100 GPU が発売されたことにより、AI と HPC の間の世代間のパフォーマンス向上の差はさらに広がりました。それだけでなく、最近の秋の GTC 2022 カンファレンスで、Nvidia の共同創設者で CET の Huang Jensen 氏は、AI ワークロード自体も多様化しており、Nvidia は CPU ビジネスの探索を開始せざるを得なくなっている、あるいはより正確に言えば、そうすべきであると述べました。 GPU 指向の最適化された拡張メモリ コントローラーと呼ばれます。
この問題については後で詳しく説明します。
2つの花が咲き、両側に1つずつです。
まず、最も明確な判断から始めましょう。 Nvidia が気象モデリング、流体力学計算、有限要素解析、量子色力学、その他の高強度数学シミュレーションなどの 64 ビット浮動小数点 HPC アプリケーションをサポートするために、GPU に強力な FP64 パフォーマンスを持たせたい場合、アクセラレータの設計アイデアは次のようになります。次のように: テンソル コアや FP32 CUDA コア (主に CUDA アーキテクチャでグラフィックス シェーダーとして使用される) を持たない製品を作成します。
しかし、残念ながらそのような製品を購入する顧客は数百人だけなので、1 つのチップの価格は数万ドル、場合によっては数十万ドルになる可能性があります。設計と製造の費用がカバーされます。より大規模で収益性の高いビジネスを構築するために、Nvidia はベクトル演算機能が CPU よりも単純に強力な、より一般的なアーキテクチャを設計する必要があります。
したがって、NVIDIA は 15 年前に HPC アプリケーション向けの製品を真剣に設計することを決定して以来、地震処理、信号処理、ゲノミクス ワークロードでの使用を含む、FP32 浮動小数点演算演算を使用する HPC シナリオに焦点を当ててきました。単精度データと処理タスクを強化し、GPU の FP64 機能を段階的に向上させます。
2012 年 7 月に発売された K10 アクセラレータには、ゲーム グラフィックス カードで使用されている GPU と同じ「Kepler」GK104 GPU が 2 つ搭載されています。 1536 個の FP32 CUDA コアを備えており、専用の FP64 コアは使用しません。 FP64 のサポートは純粋にソフトウェアで行われるため、大幅なパフォーマンスの向上は見込めません。デュアル GK104 GPU は、FP32 タスクでは 4.58 テラフロップス、FP64 では 190 ギガフロップスで実行され、比率は 24 対 1 です。 2012 年末の SC12 スーパーコンピューティング カンファレンスでリリースされた K20X は、FP32 パフォーマンスが 3.95 テラフロップス、FP64 パフォーマンスが 1.31 テラフロップスで、比率が 3:1 に増加した GK110 GPU を使用しています。この時点までに、この製品は HPC アプリケーションおよびアカデミック/ハイパースケール コンピューティング領域で AI モデルをトレーニングするユーザー向けに初期利用可能になります。 K80 GPU アクセラレータ カードは 2 つの GK110B GPU を使用します。これは、NVIDIA が当時最上位の「Maxwell」GPU に FP64 サポートを追加しなかったためで、GK110 B が当時最も人気があり、コスト効率の高いオプションとなったためです。 K80 の FP32 パフォーマンスは 8.74 テラフロップス、FP64 パフォーマンスは 2.91 テラフロップスで、依然として 3 対 1 の比率を維持しています。
「Pascal」 GP100 GPU では、FP16 混合精度インジケーターの導入により HPC と AI の間のギャップがさらに広がりましたが、ベクトル FP32 とベクトル FP64 の比率はさらに 2:1 に変換されました。 「Volta」では、GV100 以降の「Ampere」GA100 や「Hopper」GH100 などの新しい GPU にも維持されています。 Volta アーキテクチャでは、NVIDIA は固定行列 Lei を備えた Tensor コア行列数学ユニットを初めて導入しました。これにより、浮動小数点 (および整数) の計算能力が大幅に向上し、アーキテクチャ内のベクトル ユニットは引き続き維持されました。
これらの tensor コアは、ますます大規模な行列を処理するために使用されますが、特定の計算精度はますます低下しているため、このタイプの機器は非常に誇張された AI ロード スループットを達成しています。もちろん、これは機械学習自体のあいまいな統計的性質から切り離すことはできず、また、ほとんどの HPC アルゴリズムで必要とされる高精度の数学との大きなギャップも残しています。以下の図は、AI と HPC のパフォーマンスの差を対数で表したもので、両者の傾向の違いがすでにおわかりいただけると思います。
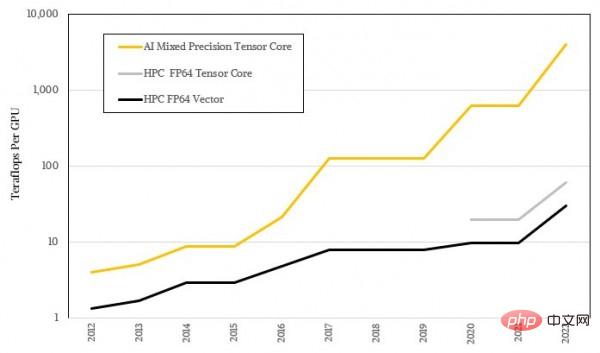
対数形式では十分に印象的ではありません。実際の比率を使用してもう一度見てみましょう:
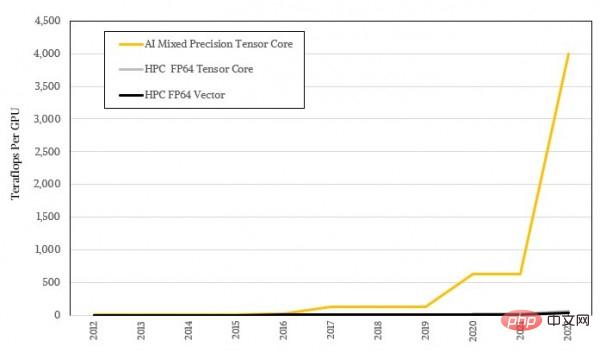
システム デザインの芸術: HPC および AI アプリケーションが主流になったとき、GPU アーキテクチャはどこに向かうべきでしょうか?
すべての HPC アプリケーションがテンソル コア用に調整できるわけではなく、すべてのアプリケーションが数学演算をテンソル コアに転送できるわけではないため、Nvidia は GPU アーキテクチャに一部のベクトル ユニットを保持しています。さらに、多くの HPC 組織は、HPL-AI のような反復ソルバーを実際に思いつくことができません。 Linpack ベンチマーク テストで使用される HPL-AI ソルバーは、FP16 と FP32 演算を備えた通常の HPL Linpack と、純粋な FP64 総当たり計算と同じ答えに収束するために少しの FP64 演算を使用します。この反復ソルバーは、オークリッジ国立研究所のフロンティア スーパーコンピューターでは 6.2 倍、理化学研究所の富岳スーパーコンピューターでは 4.5 倍の効果的な高速化を実現できます。より多くの HPC アプリケーションが独自の HPL-AI ソルバーを受け入れることができれば、AI と HPC の「分離」の問題は解決される、その日が来ると私は信じています。
しかし同時に、多くのワークロードでは、依然として FP64 のパフォーマンスが唯一の決定要因となります。そして、強力な AI コンピューティング能力で多額の利益を上げてきた Nvidia には、短期間に HPC 市場の世話をする時間は決して多くないでしょう。
さらに 2 つの花が咲き、それぞれ 1 つずつ枝分かれします
Nvidia の GPU アーキテクチャは、許容可能な HPC パフォーマンスを維持しながら、主により高い AI パフォーマンスを追求し、2 つの側面からのアプローチを使用していることがわかります。顧客は毎日、ハードウェアは 3 年ごとに更新されます。純粋な FP64 パフォーマンスの観点から見ると、Nvidia GPU の FP64 スループットは、2012 年から 2022 年までの 10 年間で、K20X の 1.3 テラフロップスから H100 の 30 テラフロップスまで 22.9 倍増加しました。テンソル コア マトリックス ユニットを反復ソルバーで使用できる場合、増加は 45.8 倍に達する可能性があります。ただし、低精度の大規模並列コンピューティングのみを必要とする AI トレーニング ユーザーの場合、FP32 から FP8 へのパフォーマンスの変化は誇張されており、初期の FP32 のコンピューティング能力は 3.95 テラフロップスから 4 ペタフロップスの FP8 スパースに増加しました。マトリックスは 1012.7 倍に向上しました。そして、当時の K20X GPU 上の FP64 エンコード AI アルゴリズム (当時の主流) と比較すると、過去 10 年間のパフォーマンス向上は情けないことにわずか 2 倍です。
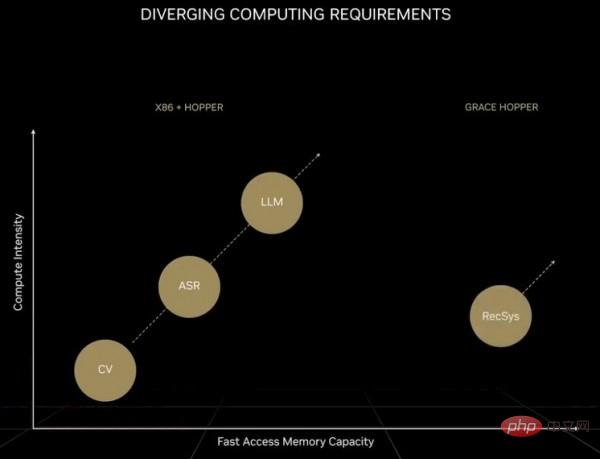
明らかに、この 2 つのパフォーマンスの差は、それほど大きなものとは言えません。黄仁勲自身も、現在のAI陣営自体が再び2つに分かれていると述べた。 1 つのタイプは、トランスフォーマー モデルによってサポートされる巨大な基本モデルであり、大規模言語モデルとも呼ばれます。このようなモデルのパラメータの数は急速に増加しており、ハードウェアの需要も増加しています。以前のニューラル ネットワーク モデルと比較すると、次の図に示すように、今日のトランスフォーマー モデルは完全に別の時代を表しています。

この図が少しぼやけていることをお許しください。ポイントは次のとおりです: 変圧器を含まない最初の AI モデルのセットでは、コンピューティング要件は 2 年間で 8 倍に増加しましたが、変圧器を含む AI モデルでは、コンピューティング要件は 2 年間で 275 倍に増加しました。浮動小数点演算が処理に使用される場合、需要を満たすにはシステム内に 100,000 個の GPU が必要になります (これは大きな問題ではありません)。ただし、FP4精度に切り替えると計算量が2倍になり、将来的にGPUに1.8nmトランジスタが採用されると計算能力は約2.5倍になるため、まだ55倍程度の差がある。 FP2 演算を実装できれば (そのような精度が問題を解決するのに十分であると仮定して)、計算量は半分に減りますが、それには少なくとも 250,000 個の GPU の使用が必要になります。さらに、大規模な言語変換モデルは拡張が難しいことが多く、特に経済的に実現可能ではありません。したがって、核兵器が強国のみにあるのと同じように、このタイプのモデルは巨大企業専用のものとなった。
「デジタル経済エンジン」としてのレコメンドシステムは、計算量が飛躍的に増加するだけでなく、大規模な言語モデルのメモリ容量をはるかに超えるデータ規模が必要となります。 GPU。 Huang Renxun は前回の GTC 基調講演で次のように述べました:
「大規模な言語モデルと比較すると、推奨システムを処理する際に各コンピューティング ユニットが直面するデータ量は一桁大きくなります。明らかに、推奨システムはより高速なメモリ速度を必要とするだけでなく、その 10 倍のメモリ速度も必要とします。大規模言語モデルのモデルのメモリ容量。大規模言語モデルは時間の経過とともに指数関数的な成長を維持し、一定の計算能力を必要としますが、推奨システムもこの成長率を維持し、より多くのメモリ容量を消費し続けます。大規模言語モデルと推奨システムは、現在の AI モデルの 2 つの最も重要なタイプと言われており、コンピューティング要件が異なります レコメンデーション システムは、数十億のユーザーと数十億のアイテム、すべての記事、すべてのビデオ、すべてのソーシャル投稿に拡張可能 各埋め込みテーブルには、数十テラバイトのデータが含まれる可能性がありますデータを処理するには、複数の GPU で処理する必要があります。レコメンデーション システムを処理する場合、ネットワークの一部でデータの並列処理を実装する必要があり、ネットワークの他の部分でモデルの並列処理を実装する必要があるため、さまざまな部分でより高い要件が要求されます。
#次の図に示すように、推奨システムの基本的なアーキテクチャです。
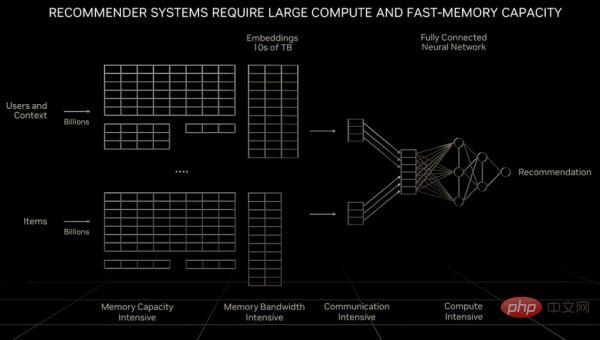
具体的なメモリ容量とこれを決定するのは帯域幅の問題であるため、NVIDIA は「Grace」Arm サーバー CPU を開発し、それを Hopper GPU と緊密に結合しました。また、必要なメイン メモリの量が非常に大きい場合、Grace は実際には Hopper のメモリ コントローラにすぎないという冗談もあります。しかし、長期的には、NVLink プロトコルを実行する多数の CXL ポートを Hooper の次世代 GPU に接続するだけかもしれません。
つまり、NVIDIA が製造した Grace-Hopper スーパー チップは、「子供」レベルの CPU クラスターを巨大な「大人」レベルの GPU アクセラレーション クラスターに組み込むことに相当します。これらの Arm CPU は従来の C および Fortran ワークロードをサポートできますが、代償が伴います。ハイブリッド クラスターの CPU 部分のパフォーマンスはクラスター内の GPU のパフォーマンスのわずか 10 分の 1 ですが、コストは 3 ~ 3 倍になります。従来のピュアCPUクラスタの5倍。
ところで、私たちは NVIDIA によるエンジニアリング上の選択を尊重し、理解しています。 Grace は優れた CPU であり、Hopper も優れた GPU であり、この 2 つの組み合わせは間違いなく良い結果をもたらします。しかし、現在起こっていることは、同じプラットフォーム上で 3 つの異なるワークロードに直面しており、それぞれがアーキテクチャを異なる方向に引っ張っているということです。高性能コンピューティング、大規模な言語モデル、推奨システム、これら 3 兄弟にはそれぞれ独自の特徴があり、コスト効率の高い方法でアーキテクチャを同時に最適化することはまったく不可能です。
そして、AI には大きな利点がある一方で、HPC は徐々に劣勢になっていることは明らかであり、この状況は 10 年近く続いています。 HPC が変革を完了したいのであれば、そのコードは FP64 上で既存の C および Fortran コードを実行することに固執し続けるのではなく、推奨システムや大規模な言語モデルに近づく必要があります。そして、HPC の顧客が AI の顧客と比較してあらゆる操作においてプレミアムを持っていることは明らかです。したがって、HPC の専門家が、より低い精度で物理世界をモデル化できる反復ソルバーの普遍的な開発方法を見つけ出さない限り、この消極的な状況を逆転させることは困難でしょう。
何十年もの間、私たちは自然そのものが数学的法則に従わないと常に感じてきました。私たちは自然の影響を説明するために高精度の数学を使用することを余儀なくされているか、客観的な現実を説明するために不適切な言語を使用しています。もちろん、自然は私たちが想像しているよりも微妙である可能性があり、反復ソルバーはモデル化したい現実に近づきます。もしこれが事実であれば、それは人類にとっての祝福であり、10 年前の HPC と AI の偶然の一致よりもさらに幸運かもしれません。
結局のところ、世界には道はなく、歩く人が増えると道になります。
以上がシステム設計の芸術: HPC および AI アプリケーションが主流になったとき、GPU アーキテクチャはどこに向かうべきでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1382
52
83
11
28
96
15
1382
52
83
11
28
96

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
SSHサービスを再起動するコマンドは次のとおりです。SystemCTL再起動SSHD。詳細な手順:1。端子にアクセスし、サーバーに接続します。 2。コマンドを入力します:SystemCtl RestArt SSHD; 3.サービスステータスの確認:SystemCTLステータスSSHD。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
