

タッチはこれまでにないほどリアルです。南カリフォルニア大学の2人の中国人博士が「触覚」アルゴリズムを革新

エレクトロニクス技術の発達により、いつでもどこでも「視聴覚の饗宴」が楽しめるようになり、人間の聴覚と視覚は完全に解放されました。
#近年、デバイスに「ハプティクス」を追加することが、特に「メタバース」の概念の恩恵により、徐々に新しい研究の注目の的となっています。高い触覚が仮想世界のリアリティを大幅に高めることは間違いありません。

現在の触覚センシング技術は主に「データ駆動型」モデルを通じてタッチをシミュレートし、レンダリングします。モデルは最初にユーザーと実際のテクスチャとのインタラクションを記録します。信号はテクスチャ生成部分に入力され、触感が振動の形でユーザーに「再生」されます。
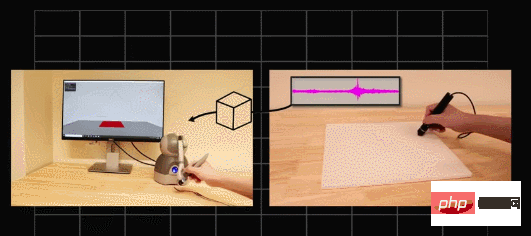
# 最近のいくつかの手法は、主にユーザーのインタラクティブな動作と高周波振動信号に基づいて、摩擦や微細な表面特徴などのテクスチャ特徴をモデル化しています。 。

データドリブンによりシミュレーションの現実性が大幅に向上しますが、依然として多くの制限があります。
#例えば、世の中には「無数」のテクスチャが存在しており、それぞれのテクスチャを記録するとなると、想像を絶する人手と物的資源が必要となります。また、一部のニッチなユーザーのニーズを満たすこともできません。

人間は接触に対して非常に敏感です。同じ物体に対しても人によって感情が異なります。データ駆動型のアプローチでは、問題を根本的に解決することはできません。タッチ テクスチャ記録とテクスチャ レンダリングの知覚的な不一致の問題。
最近、南カリフォルニア大学ビタビ工学部の 3 人の博士課程の学生が、人間を使用してテクスチャの詳細を解決する新しい「好み主導型」モデル フレームワークを提案しました。生成された仮想知覚を調整する機能により、最終的に非常に現実的な触覚を実現できます。この論文は、IEEE Transactions on Haptics に掲載されました。

論文リンク: https://ieeexplore.ieee.org/document/9772285
好み主導のモデルは、まずユーザーに現実的なタッチ テクスチャを提供し、次にモデルは、数十の変数を使用して 3 つの仮想テクスチャをランダムに生成し、ユーザーはその中から実際のオブジェクトに最も似ていると感じるテクスチャを選択できます。
継続的な試行錯誤とフィードバックにより、モデルは検索を通じて変数の分布を継続的に最適化し、生成されるテクスチャをユーザーの好みに近づけます。コンピュータが読み取った内容と人間が実際に感じた内容との間には常にギャップがあるため、この方法にはテクスチャを直接記録して再生する場合に比べて大きな利点があります。

このプロセスは、実際には、「当事者 A と当事者 B」に似ています。間違っている場合は、戻ってアルゴリズム (当事者 B) を修正し、生成されたエフェクトが満足のいくまで再生成します。
これは実際には非常に合理的です。なぜなら、同じ物体に触れたときに人によって異なる感情が生じるからです。しかし、コンピュータが発する信号は同じなので、人それぞれに合わせたタッチのカスタマイズが必要です!
システム全体は 2 つのモジュールで構成されています。1 つ目は、潜在空間のベクトルをテクスチャ モデルにマッピングするために使用される深層畳み込み敵対的生成ネットワーク (DCGAN) です。トレーニング用の UPenn Haptic Texture Toolkit (HaTT)。
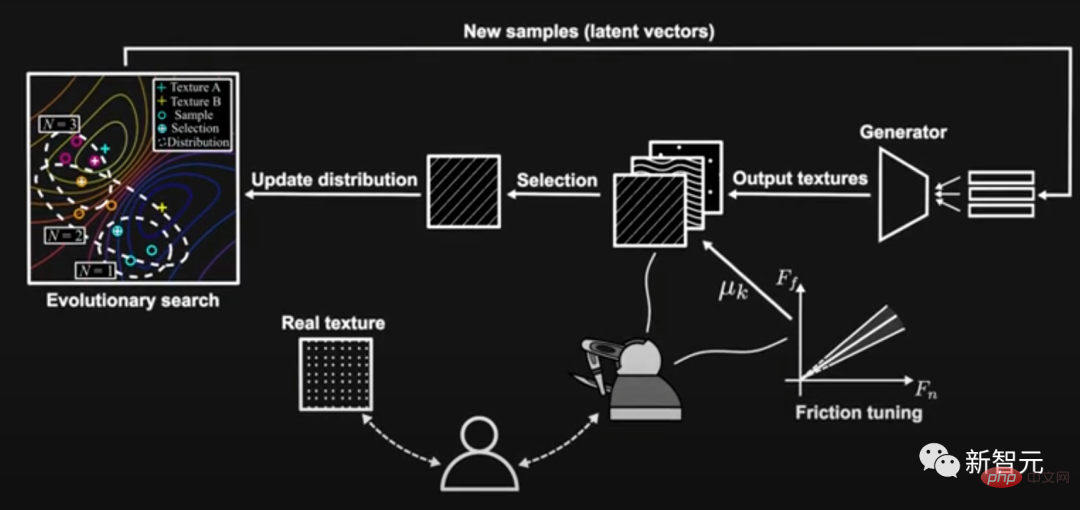
2 番目のモジュールは比較ベースの進化アルゴリズムです: 生成されたテクスチャ モデルのセットから、共分散行列適応進化戦略 (CMA-ES) がユーザーの好みのフィードバックに基づいて新しいテクスチャ モデルを作成します。
実際のテクスチャをシミュレートするために、研究者らはまずユーザーにカスタム ツールを使用して実際のテクスチャに触れるよう依頼し、次に触覚デバイスを使用して一連の仮想テクスチャ候補に触れるように依頼します。 、触覚フィードバックは、デバイスのスタイラスに接続された Haptuator を介して送信されます。
ユーザーが行う必要があるのは、実際のテクスチャに最も近い仮想テクスチャを選択し、シンプルなスライダー インターフェイスを使用してテクスチャの量を調整することだけです。摩擦 摩擦は質感に重要な要素であるため、摩擦は人によって異なります。
次に、ユーザーの選択に応じた進化戦略に従ってすべての仮想テクスチャが更新され、ユーザーは再度選択して調整します。
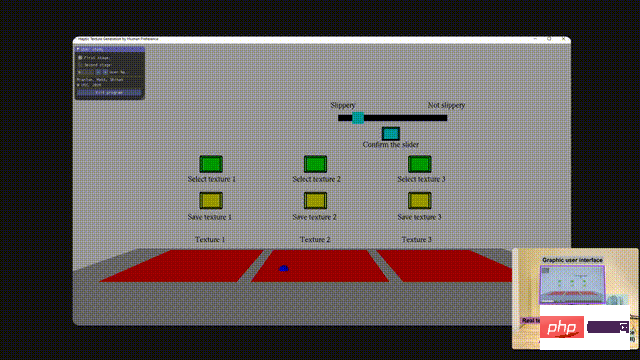
ユーザーが実際のテクスチャに近いと思われる仮想テクスチャを見つけて保存するか、より近い仮想テクスチャが見つかるまで、上記のプロセスを繰り返します。見つからない 。
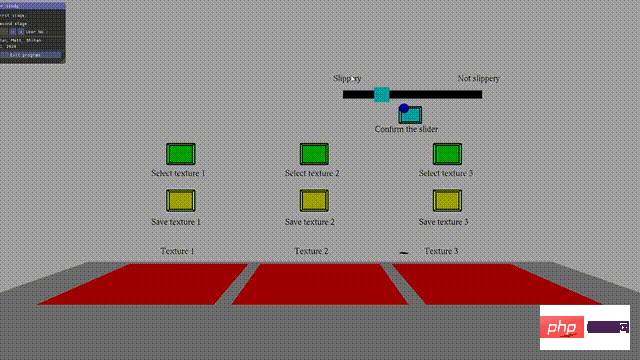
研究者らは、評価プロセスを 2 つのフェーズに分割し、それぞれに別の参加者グループを設けました。
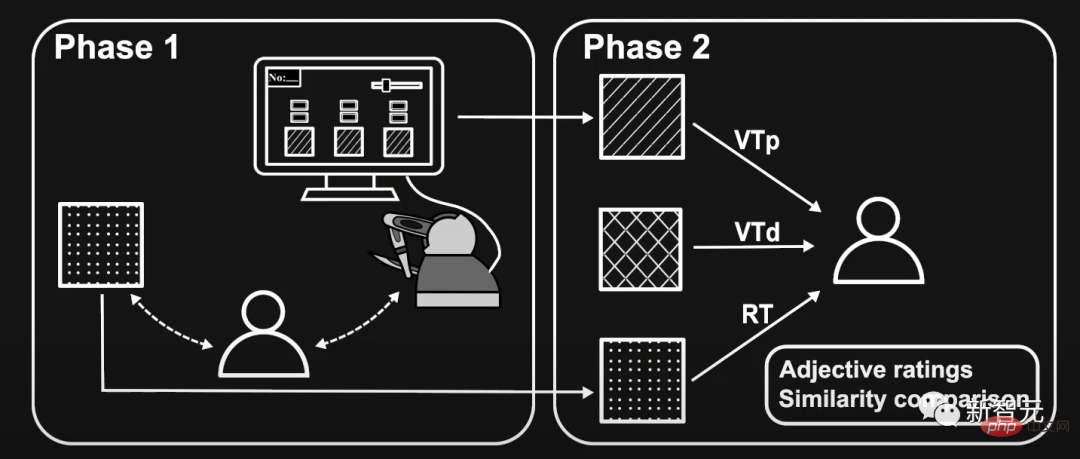
#最初のステージでは、5 人の参加者がそれぞれ 5 つの実際のテクスチャに対して仮想テクスチャを生成および検索しました。
第 2 段階では、最終的に保存されたプリファレンス駆動テクスチャ (VTp) とそれに対応する実際のテクスチャ (RT) との間のギャップを評価します。
評価方法は主に形容詞評価を使用して、粗さ、硬さ、滑らかさを含む知覚次元を評価します。
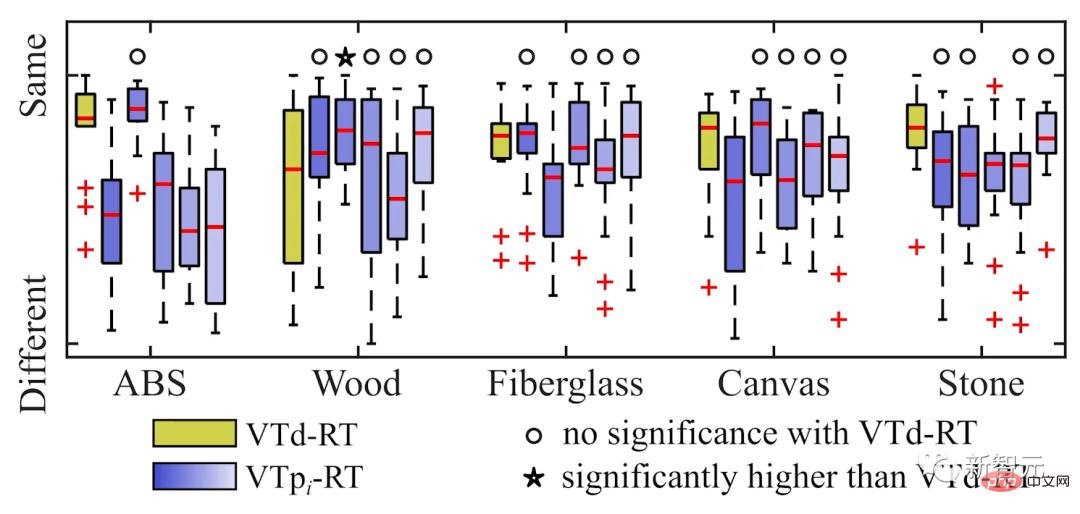
#そして、VTp、RT、データドリブン テクスチャ (VTd) の類似点を比較します。
#実験結果は、進化のプロセスに従って、ユーザーがデータ駆動型モデルよりも現実的な仮想テクスチャ モデルを効果的に見つけることができることも示しています。
さらに、参加者の 80% 以上が、好み主導型モデルによって生成された仮想テクスチャ評価の方が、優先モデルによって生成された仮想テクスチャ評価よりも優れていると信じていました。データ駆動型モデル。
触覚デバイスは、ビデオ ゲーム、ファッション デザイン、手術シミュレーションなどでますます人気が高まっており、家庭でも使用できるようになってきています。ラップトップを使用するユーザーは、触覚デバイスと同じくらい人気があります。
#たとえば、一人称視点のビデオ ゲームにタッチを追加すると、プレーヤーの現実感が大幅に高まります。

論文の著者は、私たちがツールを通じて環境と対話するとき、触覚フィードバックは単なる形式、感覚フィードバックの一種にすぎないと述べています。そしてオーディオもまた感覚的なフィードバックであり、どちらも非常に重要です。
#ゲームに加えて、この作業の結果は、非常に正確である必要がある歯科または外科のトレーニングで使用される仮想テクスチャに特に役立ちます。
「外科トレーニングは、非常にリアルなテクスチャと触覚フィードバックを必要とする非常に巨大な分野です。また、装飾デザインでは、開発中にテクスチャの高度な精度が必要です。それをシミュレートしてください」地上で製造してから製造します。」

ビデオ ゲームからファッション デザインに至るまで、あらゆるものに触覚テクノロジーが統合されており、既存の仮想テクスチャ データベースはこのユーザー好みのアプローチで改善できます。
テクスチャ検索モデルを使用すると、ユーザーはペンシルベニア大学の触覚テクスチャ ツールキットなどのデータベースから仮想テクスチャを抽出することもでき、目的のテクスチャが得られるまで改良できます。結果。
#このテクノロジーをテクスチャ検索モデルと組み合わせると、他の人が以前に記録した仮想テクスチャを使用し、それに基づいてテクスチャを最適化できます。戦略。
#著者は、将来的にはモデルに実際のテクスチャさえ必要なくなるかもしれないと想像しています。

私たちの生活の中で共通するいくつかのことの感覚は非常に直感的であり、私たちは写真を見ることで感覚を微調整するように組み込まれています。実際のテクスチャを参照する必要はありません。
たとえば、テーブルを見たとき、その表面についての事前の知識を使用して、テーブルに触れたときにどのように感じるかを想像できます。知識があれば、ユーザーに視覚的なフィードバックを提供し、一致するコンテンツを選択できるようにすることができます。
この記事の筆頭著者である Shihan Lu は、現在、南カリフォルニア大学コンピュータ サイエンス学部の博士候補者です。イマーシブ テクノロジーにおけるサウンド関連の作業。ツールが仮想テクスチャと対話するときに一致するサウンドを導入することで、仮想テクスチャをより没入型にします。

この記事の 2 番目の著者である Mianlun Zheng (Zheng Mianlun) は、南方大学コンピュータ サイエンス学部の博士候補者です。カリフォルニア州武漢大学を卒業し、学士号と修士号を取得しました。
 ##
##
以上がタッチはこれまでにないほどリアルです。南カリフォルニア大学の2人の中国人博士が「触覚」アルゴリズムを革新の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1658
1658
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能 (AI) と法執行機関の融合により、犯罪の予防と検出の新たな可能性が開かれます。人工知能の予測機能は、犯罪行為を予測するためにCrimeGPT (犯罪予測技術) などのシステムで広く使用されています。この記事では、犯罪予測における人工知能の可能性、その現在の応用、人工知能が直面する課題、およびこの技術の倫理的影響について考察します。人工知能と犯罪予測: 基本 CrimeGPT は、機械学習アルゴリズムを使用して大規模なデータセットを分析し、犯罪がいつどこで発生する可能性があるかを予測できるパターンを特定します。これらのデータセットには、過去の犯罪統計、人口統計情報、経済指標、気象パターンなどが含まれます。人間のアナリストが見逃す可能性のある傾向を特定することで、人工知能は法執行機関に力を与えることができます
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察
Oct 20, 2023 am 08:45 AM
Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察
Oct 20, 2023 am 08:45 AM
1. マルチモーダル大型モデルの発展の歴史 上の写真は、1956 年に米国のダートマス大学で開催された最初の人工知能ワークショップです。このカンファレンスが人工知能開発の始まりとも考えられています。記号論理学の先駆者たち(前列中央の神経生物学者ピーター・ミルナーを除く)。しかし、この記号論理理論は長い間実現できず、1980 年代と 1990 年代に最初の AI の冬の到来さえもたらしました。最近の大規模な言語モデルが実装されて初めて、ニューラル ネットワークが実際にこの論理的思考を担っていることがわかりました。神経生物学者ピーター ミルナーの研究は、その後の人工ニューラル ネットワークの開発に影響を与えました。彼が参加に招待されたのはこのためです。このプロジェクトでは。
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
 SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
上記と著者の個人的な理解は、自動運転システムにおいて、認識タスクは自動運転システム全体の重要な要素であるということです。認識タスクの主な目的は、自動運転車が道路を走行する車両、路側の歩行者、運転中に遭遇する障害物、道路上の交通標識などの周囲の環境要素を理解して認識できるようにすることで、それによって下流のシステムを支援できるようにすることです。モジュール 正しく合理的な決定と行動を行います。自動運転機能を備えた車両には、通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなど、さまざまな種類の情報収集センサーが装備されており、自動運転車が正確に認識し、認識できるようにします。周囲の環境要素を理解することで、自動運転車が自動運転中に正しい判断を下せるようになります。頭
