

arXiv 論文「自動運転における車線検出と分類のための Sim-to-Real Domain Adaptation」、2022 年 5 月、カナダのウォータールー大学での研究。

自動運転用の教師あり検出および分類フレームワークには大規模な注釈付きデータセットが必要ですが、 教師なしドメイン適応 (UDA) は、実際のシミュレート環境を照明することで生成された合成データによって駆動され、教師なしDomain Adaptation) 方式は、低コストで時間のかからないソリューションです。この論文では、自動運転における車線の検出および分類アプリケーションのための敵対的識別および生成方法の UDA スキームを提案します。
また、CARLA の大規模な交通シーンと気象条件を利用して自然な合成データセットを作成する Simulanes データセット ジェネレーターも紹介します。提案された UDA フレームワークは、ラベル付きの合成データセットをソース ドメインとして受け取りますが、ターゲット ドメインはラベルのない実際のデータです。敵対的生成と特徴弁別器を使用して学習モデルをデバッグし、ターゲット ドメインのレーンの位置とカテゴリを予測します。評価は実際のデータセットと合成データセットを使用して実行されます。
オープンソースのUDAフレームワークは githubcom /anita-hu/sim2real-lane-detectionにあり、データセットジェネレーターはgithub.com/anita-hu/にあります。シミュレーン。
実際の運転は、交通状況、天候、周囲の環境が変化するため、多様です。したがって、現実世界におけるモデルの適応性を高めるには、シミュレーション シナリオの多様性が非常に重要です。 CARLA や LGSVL など、自動運転用のオープンソース シミュレーターが多数あります。この記事では、シミュレーション データ セットの生成に CARLA を選択します。CARLA には、柔軟な Python API に加えて、都市、田舎、高速道路のシーンをカバーする豊富な事前描画マップ コンテンツも含まれています。
シミュレーション データ ジェネレーター Simulanes は、15 車線カテゴリや動的な天候など、都市、田舎、高速道路の環境でさまざまなシミュレーション シナリオを生成します。この図は、合成データセットからのサンプルを示しています。歩行者と車両の参加者がランダムに生成されてマップ上に配置されるため、オクルージョンによってデータセットの難易度が高まります。 TuSimple および CULane データセットによると、車両付近の車線の最大数は 4 に制限されており、行アンカーがラベルとして使用されます。

CARLA シミュレーターは車線位置ラベルを直接提供しないため、ラベルの生成には CARLA のウェイポイント システムが使用されます。 CARLA ウェイポイントは、車両のオートパイロットが従う事前定義された位置で、車線の中央にあります。車線位置ラベルを取得するには、現在の車線のウェイポイントを W/2 だけ左右に移動します。ここで、W はシミュレータによって与えられた車線幅です。これらの移動されたウェイポイントは、カメラ座標系に投影され、スプラインフィットされて、所定の行アンカー ポイントに沿ってラベルが生成されます。クラス ラベルはシミュレータによって与えられ、15 クラスのうちの 1 つです。
N フレームのデータセットを生成するには、利用可能なすべてのマップで N を均等に分割します。デフォルトの CARLA マップでは、町 1、3、4、5、7、および 10 が使用されましたが、抽出された車線位置ラベルと画像の車線位置の違いにより、町 2 と 6 は使用されませんでした。マップごとに、車両の参加者はランダムな場所に生成され、ランダムに移動します。動的な天候は、時間の正弦波関数として太陽の位置を滑らかに変化させ、時折嵐を発生させることによって実現されます。嵐は、雲量、水量、滞留水などの変数を通じて環境の外観に影響を与えます。同じ位置に複数のフレームが保存されないようにするには、車両が前のフレームの位置から移動したかどうかを確認し、長時間停止していた場合は新しい車両を再生成します。
sim-to-real アルゴリズムが車線検出に適用される場合、エンドツーエンドのアプローチが採用され、超高速車線検出 (UFLD) モデルが使用されます。基本的なネットワークとして。 UFLD が選ばれたのは、その軽量アーキテクチャが、最先端の手法に匹敵するパフォーマンスを達成しながら、同じ入力解像度で 300 フレーム/秒を達成できるためです。 UFLD は、車線検出タスクを行ベースの選択方法として定式化します。各車線は、事前定義された行、つまり行アンカーの一連の水平位置によって表されます。各行アンカーの位置は w グリッド セルに分割されます。 i 番目のレーンと j 番目の行アンカーの場合、位置予測が分類問題となり、モデルは (w 1) 個のグリッド セルを選択する確率 Pi,j を出力します。出力の追加ディメンションはレーンなしです。
UFLD は、複数のスケールで特徴を集約して局所特徴をモデル化するための補助セグメンテーション ブランチを提案します。これはトレーニング中にのみ使用されます。 UFLD 法では、分割損失 Lseg としてクロスエントロピー損失が使用されます。車線分類の場合、完全接続 (FC) 層の小さなブランチが追加され、車線位置予測用の FC 層と同じ機能を受け取ります。レーン分類損失 Lcls もクロスエントロピー損失を使用します。
UDA 設定のドメイン ドリフト問題を軽減するために、UNIT ("Unsupervised Image-to-Image Translation Networks"、NIPS、2017) および MUNIT# # ("Multimodal unsupervised image-to-image translation," ECCV 2018) 敵対的生成手法と、特徴識別器を用いた敵対的判別手法を採用しています。図に示すように、敵対的生成方法(A)と敵対的識別方法(B)が提案されています。 UNIT と MUNIT は (A) で表され、画像変換用のジェネレーター入力を示します。 MUNIT への追加のスタイル入力は青い破線で示されています。わかりやすくするために、MUNIT スタイルのエンコーダー出力は画像変換には使用されないため省略されています。
 #実験結果は次のとおりです。
#実験結果は次のとおりです。
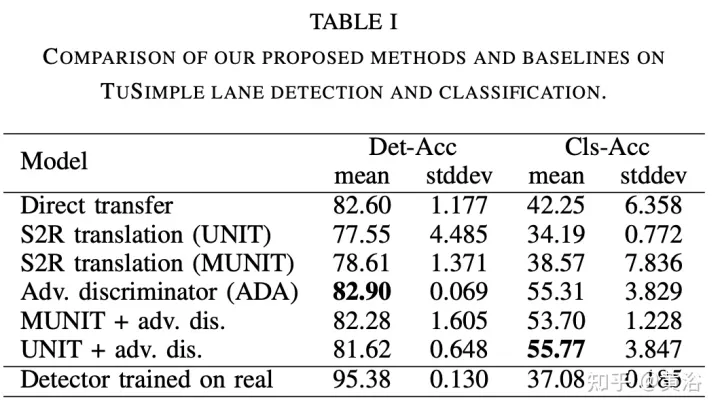
#左: 直接移行メソッド、右: 敵対的認証 (ADA) メソッド
以上が自動運転車線の検出と分類のための仮想現実領域適応手法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



