

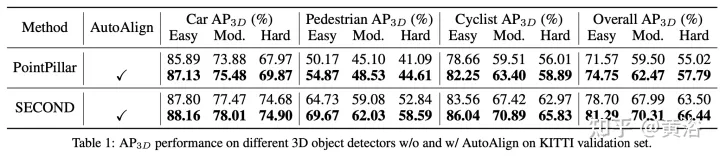
マルチモーダルフュージョン BEV ターゲット検出方式 AutoAlign V1 および V2

自動運転では、RGB 画像または LIDAR 点群によるターゲット検出が広く検討されています。ただし、これら 2 つのデータ ソースをどのように補完し、相互に有益にするかは依然として課題です。 AutoAlignV1 と AutoAlignV2 は、主に中国科学技術大学、ハルビン工業大学、SenseTime (当初は香港中文大学と清華大学を含む) の成果です。
AutoAlignV1 は、2022 年 4 月にアップロードされた arXiv 論文「AutoAlign: マルチモーダル 3D オブジェクト検出のためのピクセル インスタンス機能集約」に由来しています。

要約
この論文では、3D ターゲット検出のための自動特徴融合戦略 AutoAlign V1 を提案します。 学習可能な位置合わせマップを使用して、カメラ投影行列との決定論的な対応を確立するのではなく、画像と点群の間のマッピング関係をモデル化します。このグラフにより、モデルは動的かつデータ駆動型の方法で非準同型特徴を自動的に位置合わせすることができます。具体的には、クロスアテンション特徴位置合わせモジュールは、各ボクセルのピクセルレベルの画像特徴を適応的に集約するように設計されています。特徴アライメントプロセスにおけるセマンティック一貫性を強化するために、自己監視型クロスモーダル特徴インタラクションモジュールも設計されており、これを通じてモデルはインスタンスレベルの特徴に基づいて特徴集約を学習できます。
背景の紹介
マルチモーダル 3D オブジェクト検出器は、決定レベルの融合と特徴レベルの融合の 2 つのカテゴリに大別できます。前者は、それぞれのモードでオブジェクトを検出し、3D 空間で境界ボックスをまとめます。決定レベルの融合とは異なり、特徴レベルの融合では、マルチモーダルな特徴を 1 つの表現に組み合わせてオブジェクトを検出します。したがって、検出器は推論段階でさまざまなモダリティの機能を最大限に活用できます。これを考慮して、最近、より多くの特徴レベルの融合手法が開発されています。
ある作品では、各点を画像平面に投影し、双一次補間によって対応する画像特徴を取得します。特徴の集約はピクセルレベルで細かく実行されますが、融合点の疎性により画像領域の密集したパターンが失われます。つまり、画像特徴の意味的一貫性が破壊されます。
別の研究では、3D 検出器によって提供される初期ソリューションを使用して、さまざまなモダリティの RoI 特徴を取得し、特徴融合のためにそれらを接続します。インスタンスレベルの融合を実行することで意味の一貫性を維持しますが、最初の提案生成段階での大まかな特徴の集約や 2D 情報の欠落などの問題があります。
これら 2 つの方法を最大限に活用するために、著者らは、AutoAlign という名前の 3D オブジェクト検出用の統合マルチモーダル特徴融合フレームワークを提案します。これにより、検出器は適応的な方法でクロスモーダル特徴を集約できるようになり、非準同型表現間の関係をモデル化する際に効果的であることが証明されています。同時に、インスタンスレベルの機能の相互作用を通じてセマンティックの一貫性を維持しながら、ピクセルレベルのきめ細かい機能の集約を利用します。
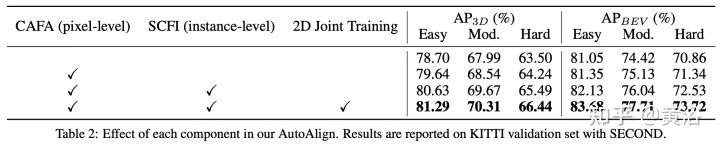
図に示すように: 機能の相互作用は 2 つのレベルで動作します: (i) ピクセル レベルの機能の集約、(ii) インスタンス レベルの機能の相互作用。
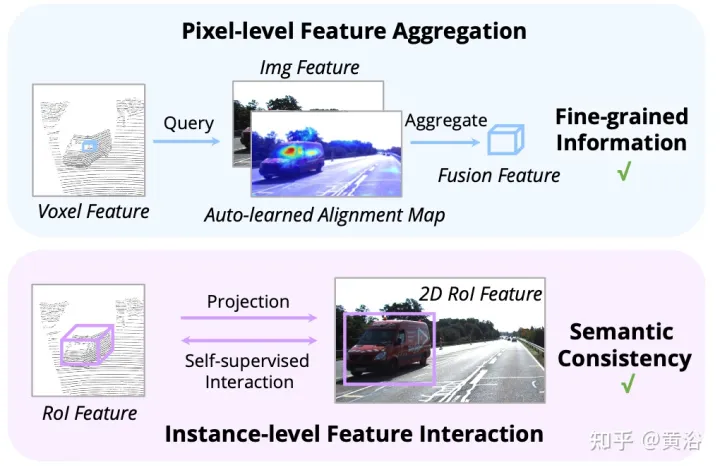
AutoAlign メソッド
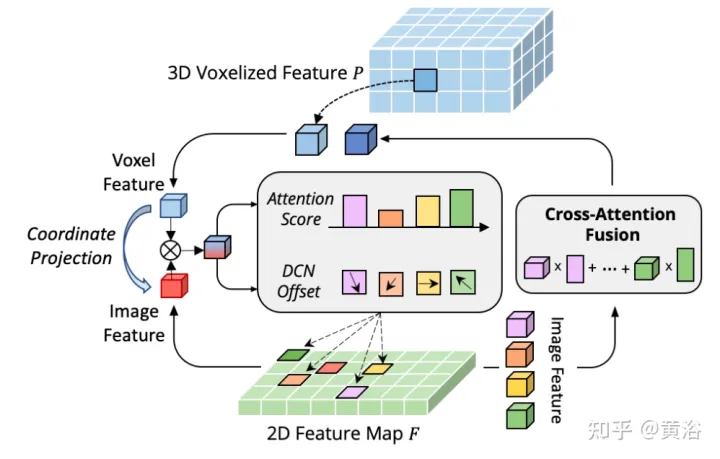
これまでの研究では、主にカメラ投影行列を利用して、画像とポイントの特徴を決定論的な方法で位置合わせしていました。このアプローチは効果的ですが、2 つの潜在的な問題が発生する可能性があります。1) ポイントは画像データのより広い視野を取得できない、2) 位置の一貫性のみが維持され、意味的な相関関係は無視されます。したがって、AutoAlign は、非準同型表現間で特徴を適応的に位置合わせするための Cross Attendant Feature Alignment (CAFA) モジュールを設計しました。 CAFA (クロスアテンション フィーチャ アライメント) このモジュールは 1 対 1 マッチング モードを使用しませんが、各ボクセルが画像全体を認識し、学習可能なアライメント マップに基づいてピクセル レベルに動的に焦点を当てます。 . 2D の特徴。
図に示すように: AutoAlign は 2 つのコア コンポーネントで構成されます。CAFA は画像平面上で特徴集約を実行し、各ボクセル特徴のきめ細かいピクセル レベルの情報を抽出します。SCFI (Self-supervised Cross) -モーダル機能インタラクション) クロスモーダル自己監視を実行し、インスタンスレベルのガイダンスを使用して CAFA モジュールのセマンティック一貫性を強化します。
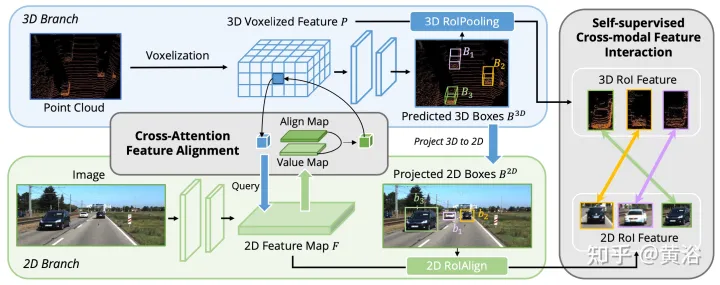
#CAFA は、画像の特徴を集約するためのきめ細かいパラダイムです。ただし、インスタンスレベルの情報を取得することはできません。対照的に、RoI ベースの特徴融合では、提案生成段階で大まかな特徴の集約や 2D 情報の欠落が発生する一方で、オブジェクトの完全性が維持されます。
ピクセル レベルとインスタンス レベルの融合の間のギャップを埋めるために、CAFA の学習をガイドする 自己監視クロスモーダル機能インタラクション (SCFI) モジュールが導入されました。 3D 検出器の最終予測を提案として直接利用し、画像とポイントの特徴を活用して正確な提案を生成します。さらに、バウンディング ボックスをさらに最適化するためにクロスモーダル フィーチャを連結する代わりに、フィーチャの位置合わせのためのインスタンス レベルのガイダンスとして、クロスモーダル フィーチャのペアに類似性制約が追加されます。
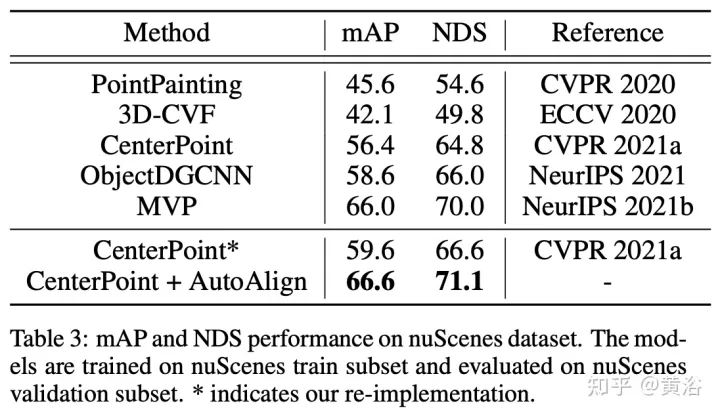
2D 特徴マップと対応する 3D ボクセル化特徴が与えられると、N 個の局所 3D 検出フレームがランダムにサンプリングされ、カメラ投影行列を使用して 2D 平面に投影され、それによって 2D フレーム ペアのセットが生成されます。ペアになったボックスが取得されると、2D および 3D 特徴空間で 2DRoIAlign および 3DRoIPooling が使用され、それぞれの RoI 特徴が取得されます。
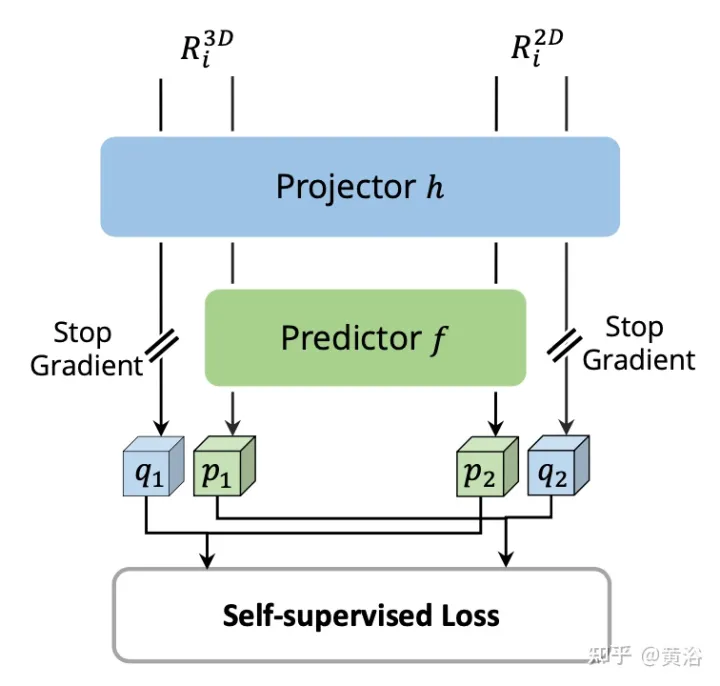
2D および 3D RoI フィーチャのペアごとに、画像ブランチからのフィーチャとポイント ブランチからボクセル化されたフィーチャに対して 自己教師ありクロスモーダルフィーチャ インタラクション (SCFI)## を実行します。 。両方の機能が投影ヘッドに入力され、一方のモダリティの出力が他方のモダリティに一致するように変換されます。 2 つの完全に接続された層を持つ予測ヘッドを導入します。図に示すように:
 ## AutoAlignV2これは、2022 年 7 月にアップロードされた「AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection」に由来しています。
## AutoAlignV2これは、2022 年 7 月にアップロードされた「AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection」に由来しています。
 要約
要約
AutoAlign は、グローバル アテンション メカニズムによってもたらされる高い計算コストに悩まされています。この目的を達成するために、著者は AutoAlign に基づいて構築された、より高速で強力なマルチモーダル 3D 検出フレームワークである AutoAlignV2 を提案します。計算コストの問題を解決するために、この記事では
Cross-domain DeformCAFA(Cross-Attendant Feature Alignment) モジュールを提案します。これは、クロスモーダル関係モデルのまばらな学習可能なサンプリング ポイントに焦点を当てており、これによりキャリブレーション エラーに対する耐性が強化され、モダリティ全体にわたる特徴の集約が大幅に高速化されます。マルチモーダル設定における複雑な GT-AUG を克服するために、深度情報が与えられた画像パッチに基づく凸結合用に、シンプルで効果的なクロスモーダル強化戦略が設計されています。さらに、画像レベルのドロップアウト トレーニング スキームを通じて、モデルは動的な方法で推論を実行できます。 コードはオープンソースになります:
https://github.com/zehuichen123/AutoAlignV2.注: GT-AUG (「
SECOND: まばらに埋め込まれた畳み込み検出」。Sensors、2018)、データ拡張手法背景
方法3D オブジェクト検出のための LIDAR とカメラの異種表現の効果的な組み合わせについては、十分に検討されていません。クロスモーダル検出器のトレーニングにおける現在の困難は 2 つの側面に起因しています。一方で、画像情報と空間情報を組み合わせる融合戦略は依然として最適とは言えません。 RGB イメージと点群の間の表現が異種であるため、フィーチャをクラスター化する前に慎重に位置合わせする必要があります。 AutoAlign は、自動登録のための学習可能なグローバル アライメント モジュールを提案し、優れたパフォーマンスを実現します。ただし、点と画像ピクセル間の内部位置一致関係を取得するには、CSFI モジュールを使用してトレーニングする必要があります。
さらに、スタイルの操作の複雑さは画像サイズの二次関数であるため、高解像度の特徴マップにクエリを適用するのは非現実的であることに注意してください。この制限により、FPN によってもたらされる階層表現の損失だけでなく、粗くて不正確な画像情報が発生する可能性があります。一方で、データ拡張、特に GT-AUG は、3D 検出器が競争力のある結果を達成するための重要なステップです。マルチモーダル アプローチの観点からは、カット アンド ペースト操作を実行するときに画像と点群間の同期をどのように維持するかが重要な問題となります。 MoCa は、2D ドメインで労働集約的なマスク アノテーションを使用して、正確な画像特徴を取得します。境界レベルの注釈も適していますが、高度なポイント フィルタリングが必要です。
AutoAlignV2 メソッド
AutoAlignV2 の目的は、画像特徴を効果的に集約して 3D オブジェクト検出器のパフォーマンスをさらに強化することです。 AutoAlign の基本アーキテクチャから始めます。ペアになった画像を軽量バックボーン ネットワーク ResNet に入力し、それを FPN に入力して特徴マップを取得します。次に、関連する画像情報が学習可能なアライメント マップを通じて集約され、ボクセル化段階で空ではないボクセルの 3D 表現が強化されます。最後に、強化された機能が後続の 3D 検出パイプラインに供給されて、インスタンス予測が生成されます。
図は、AutoAlignV1 と AutoAlignV2 の比較を示しています。AutoAlignV2 は、特徴集約位置を自動的に調整する機能を保持しながら、決定論的な射影行列によって保証される一般的なマッピング関係を持つように位置合わせモジュールに指示します。 AutoAlignV2 は計算コストが軽いため、階層的な画像情報の多層機能を集約できます。
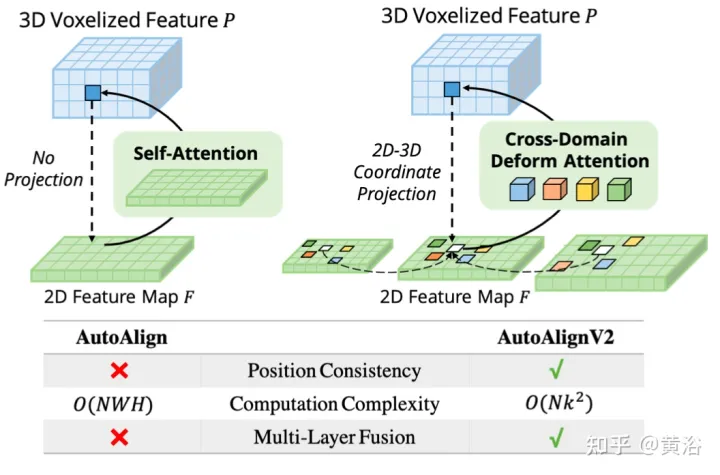
このパラダイムは、データ駆動型の方法で異種機能を集約できます。ただし、2 つの大きなボトルネックが依然としてパフォーマンスを妨げています。 1 つ目は、非効率的な特徴の集約です。グローバル アテンション マップは、RGB イメージと LIDAR ポイント間のフィーチャの位置合わせを自動的に実現しますが、計算コストは高くなります。 2 つ目は、画像とポイント間の複雑なデータ強化同期です。 GT-AUG は高性能 3D オブジェクト検出器にとって重要なステップですが、トレーニング中にポイントと画像の間でセマンティックな一貫性を維持する方法は依然として複雑な問題です。
図に示すように、AutoAlignV2 は クロスドメイン DeformCAFA モジュールと Depth-aware GT-AUG データ拡張戦略の 2 つの部分で構成されており、また、画像レベルのドロップアウト トレーニング戦略により、モデルはより動的な方法で推論を実行できるようになります。
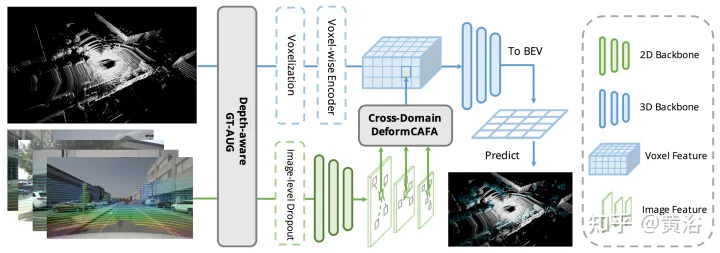
- 変形特徴の集約
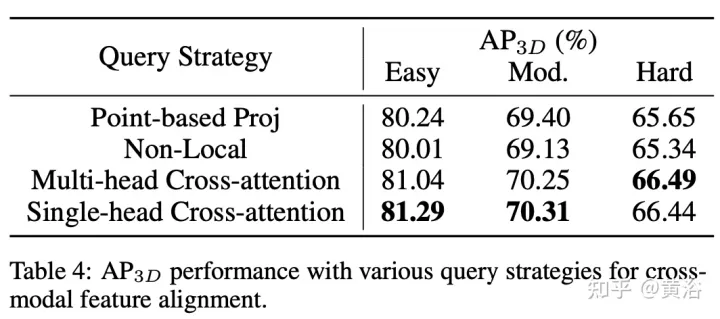
CAFA のボトルネックは、すべてのピクセルを可能な空間位置として扱うことです。 2D 画像の特性に基づいて、最も関連性の高い情報は主に幾何学的に隣接した場所に配置されます。したがって、すべての場所を考慮する必要はなく、いくつかの重要なポイント領域のみを考慮する必要があります。図に示すように、ここでは新しいクロスドメイン DeformCAFA 操作が導入されています。これにより、サンプリング候補が大幅に削減され、ボクセル クエリ特徴ごとに画像平面のキーポイント領域が動的に決定されます。
動的に生成されたサンプリング オフセットの助けを借りて、DeformCAFA は通常の操作よりも速くクロスドメインの関係をモデル化できます。マルチレイヤーの機能集約を実行できます。つまり、FPN レイヤーによって提供される階層情報を最大限に活用できます。 DeformCAFA のもう 1 つの利点は、カメラ投影行列との位置の一貫性を明示的に維持して参照点を取得できることです。したがって、DeformCAFA は、AutoAlign で提案されている CFSI モジュールを採用しなくても、意味的および位置的に一貫した位置合わせを生成できます。
通常の非ローカル操作と比較して、スパース スタイル DeformCAFA は効率を大幅に向上させます。ただし、ボクセルの特徴がトークンとして直接適用されてアテンション ウェイトと変形可能なオフセットが生成される場合、検出パフォーマンスは双線形補間とほぼ同等か、それよりも劣ります。注意深く分析した結果、トークン生成プロセスにクロスドメインの知識変換の問題があることがわかりました。通常単一モード設定で実行される元の変形操作とは異なり、クロスドメイン アテンションには両方のモードからの情報が必要です。ただし、ボクセルの特徴は空間領域の表現のみで構成されており、画像領域の情報を認識することは困難です。したがって、異なるモダリティ間の相互作用を減らすことが重要です。
各ターゲットの表現は、ドメイン固有の情報とインスタンス固有の情報という 2 つのコンポーネントに明確に分解できると仮定します。前者は、ドメイン特徴の組み込み属性を含む表現自体に関連するデータを指しますが、後者は、ターゲットがどのドメインでエンコードされているかに関係なく、ターゲットに関する ID 情報を表します。
- ディープアウェア GT-AUG
ほとんどのディープ ラーニング モデルにとって、データ拡張は競争力のある結果を達成するための重要な部分です。ただし、マルチモーダル 3D オブジェクト検出に関しては、点群と画像がデータ拡張で結合される場合、主にオブジェクトのオクルージョンや視点の変更が原因で、2 つの間の同期を維持することが困難になります。この問題を解決するために、深さを認識した GT-AUG と呼ばれる、シンプルかつ効果的なクロスモーダル データ拡張アルゴリズムが設計されました。この方法では、複雑な点群フィルタリング プロセスや画像ドメインのファイン マスク アノテーションの要件が放棄されます。代わりに、奥行き情報が 3D オブジェクトの注釈からミックスアップ画像領域に導入されます。
具体的には、貼り付けられる仮想ターゲット P が与えられた場合、GT-AUG の同じ 3D 実装に従います。画像領域に関しては、まず遠いものから近いものに分類されます。貼り付ける対象ごとに、元画像から同じ領域を切り出し、ブレンド率 α で対象画像上に合成します。詳細な実装は、以下のアルゴリズム 1 に示されています。

深度認識 GT-AUG は 3D ドメインでのみ拡張戦略に従いますが、同時にイメージ プレーンのミックスアップ ベースのカット アンド ペースト同期を通じてそれを維持します。重要な点は、元の 2D 画像に拡張パッチを貼り付けた後でも、MixUp テクノロジは対応する情報を完全には削除しないということです。代わりに、対応する点の特徴が存在することを保証するために、深度に対するそのような情報のコンパクトさを弱めます。具体的には、ターゲットが他のインスタンスによって n 回遮蔽されると、ターゲット領域の透明度は、深さの順序に従って係数 (1- α)^n だけ減衰します。
#図に示すように、いくつかの強化された例を示します。
- #画像レベルのドロップアウト トレーニング戦略
- 実際には、画像は通常、すべての 3D 検出システムでサポートされているわけではない入力オプションです。したがって、より現実的で適用可能なマルチモーダル検出ソリューションでは、動的融合アプローチを採用する必要があります。画像が利用できない場合、モデルは元の点群に基づいてターゲットを検出し、画像が利用可能な場合、モデルは特徴融合を実行し、より良い予測を生成します。この目標を達成するために、クラスター化された画像の特徴を画像レベルでランダムにドロップアウトし、トレーニング中にそれらをゼロで埋める、画像レベルのドロップアウト トレーニング戦略が提案されています。図に示すように: (a) 画像フュージョン、(b) 画像レベルのドロップアウト フュージョン。
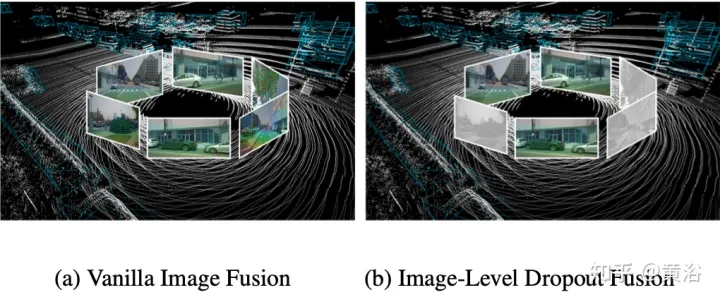 画像情報は断続的に失われるため、モデルは代替入力として 2D 特徴を使用することを徐々に学習する必要があります。 ######実験結果######################################### #
画像情報は断続的に失われるため、モデルは代替入力として 2D 特徴を使用することを徐々に学習する必要があります。 ######実験結果######################################### #
以上がマルチモーダルフュージョン BEV ターゲット検出方式 AutoAlign V1 および V2の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7444
7444
 15
1371
52
76
11
10
6
15
1371
52
76
11
10
6

 Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートのコスト/パフォーマンスを評価するには、次の手順が必要です。 必要な保証レベルとサービス レベル アグリーメント (SLA) 保証を決定します。研究サポートチームの経験と専門知識。アップグレード、トラブルシューティング、パフォーマンスの最適化などの追加サービスを検討してください。ビジネス サポートのコストと、リスクの軽減と効率の向上を比較検討します。
 PHP フレームワークの軽量オプションはアプリケーションのパフォーマンスにどのような影響を与えますか?
Jun 06, 2024 am 10:53 AM
PHP フレームワークの軽量オプションはアプリケーションのパフォーマンスにどのような影響を与えますか?
Jun 06, 2024 am 10:53 AM
軽量の PHP フレームワークは、サイズが小さくリソース消費が少ないため、アプリケーションのパフォーマンスが向上します。その特徴には、小型、高速起動、低メモリ使用量、改善された応答速度とスループット、および削減されたリソース消費が含まれます。 実際のケース: SlimFramework は、わずか 500 KB、高い応答性と高スループットの REST API を作成します。
 PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は、言語熟練度、フレームワークの複雑さ、ドキュメントの品質、コミュニティのサポートによって異なります。 PHP フレームワークの学習曲線は、Python フレームワークと比較すると高く、Ruby フレームワークと比較すると低くなります。 Java フレームワークと比較すると、PHP フレームワークの学習曲線は中程度ですが、開始までの時間は短くなります。
 Java フレームワークのパフォーマンス比較
Jun 04, 2024 pm 03:56 PM
Java フレームワークのパフォーマンス比較
Jun 04, 2024 pm 03:56 PM
ベンチマークによると、小規模で高性能なアプリケーションの場合、Quarkus (高速起動、低メモリ) または Micronaut (TechEmpower に優れた) が理想的な選択肢です。 SpringBoot は大規模なフルスタック アプリケーションに適していますが、起動時間とメモリ使用量が若干遅くなります。
 Golang フレームワークのドキュメントのベスト プラクティス
Jun 04, 2024 pm 05:00 PM
Golang フレームワークのドキュメントのベスト プラクティス
Jun 04, 2024 pm 05:00 PM
明確で包括的なドキュメントを作成することは、Golang フレームワークにとって非常に重要です。ベスト プラクティスには、Google の Go コーディング スタイル ガイドなど、確立されたドキュメント スタイルに従うことが含まれます。見出し、小見出し、リストなどの明確な組織構造を使用し、ナビゲーションを提供します。スタート ガイド、API リファレンス、概念など、包括的で正確な情報を提供します。コード例を使用して、概念と使用法を説明します。ドキュメントを常に最新の状態に保ち、変更を追跡し、新機能を文書化します。 GitHub の問題やフォーラムなどのサポートとコミュニティ リソースを提供します。 API ドキュメントなどの実践的なサンプルを作成します。
 さまざまなアプリケーションシナリオに最適な Golang フレームワークを選択する方法
Jun 05, 2024 pm 04:05 PM
さまざまなアプリケーションシナリオに最適な Golang フレームワークを選択する方法
Jun 05, 2024 pm 04:05 PM
アプリケーションのシナリオに基づいて最適な Go フレームワークを選択します。アプリケーションの種類、言語機能、パフォーマンス要件、エコシステムを考慮します。一般的な Go フレームワーク: Jin (Web アプリケーション)、Echo (Web サービス)、Fiber (高スループット)、gorm (ORM)、fasthttp (速度)。実際のケース: REST API (Fiber) の構築とデータベース (gorm) との対話。フレームワークを選択します。主要なパフォーマンスには fasthttp、柔軟な Web アプリケーションには Jin/Echo、データベース インタラクションには gorm を選択してください。
 golang フレームワーク開発の実践的な詳細な説明: 質疑応答
Jun 06, 2024 am 10:57 AM
golang フレームワーク開発の実践的な詳細な説明: 質疑応答
Jun 06, 2024 am 10:57 AM
Go フレームワーク開発における一般的な課題とその解決策は次のとおりです。 エラー処理: 管理にはエラー パッケージを使用し、エラーを一元的に処理するにはミドルウェアを使用します。認証と認可: サードパーティのライブラリを統合し、資格情報を確認するためのカスタム ミドルウェアを作成します。同時処理: ゴルーチン、ミューテックス、チャネルを使用してリソース アクセスを制御します。単体テスト: 分離のために getest パッケージ、モック、スタブを使用し、十分性を確保するためにコード カバレッジ ツールを使用します。デプロイメントとモニタリング: Docker コンテナを使用してデプロイメントをパッケージ化し、データのバックアップをセットアップし、ログ記録およびモニタリング ツールでパフォーマンスとエラーを追跡します。
 Golang フレームワークの学習プロセスでよくある誤解は何ですか?
Jun 05, 2024 pm 09:59 PM
Golang フレームワークの学習プロセスでよくある誤解は何ですか?
Jun 05, 2024 pm 09:59 PM
Go フレームワークの学習には、フレームワークへの過度の依存と柔軟性の制限という 5 つの誤解があります。フレームワークの規則に従わない場合、コードの保守が困難になります。古いライブラリを使用すると、セキュリティと互換性の問題が発生する可能性があります。パッケージを過度に使用すると、コード構造が難読化されます。エラー処理を無視すると、予期しない動作やクラッシュが発生します。
