

画像認識について話しましょう: リカレント ニューラル ネットワーク

この記事は WeChat 公開アカウント「情報時代に生きる」から転載したものであり、著者は情報時代に生きています。この記事を転載するには、情報時代の暮らしの公開アカウントまでご連絡ください。
リカレント ニューラル ネットワーク (RNN) は、主にシーケンス データの問題を解決するために使用されます。これがリカレント ニューラル ネットワークである理由は、シーケンスの現在の出力が前の出力にも関連しているためです。 RNN ネットワークは、直前の瞬間の情報を記憶し、現在の出力計算に適用します。畳み込みニューラル ネットワークとは異なり、リカレント ニューラル ネットワークの隠れ層のニューロンは相互に接続されています。隠れ層のニューロンの入力は、層は入力によって決定されます。層の出力は、前の瞬間の隠れたニューロンの出力で構成されます。 RNN ネットワークはいくつかの顕著な成果を達成しましたが、トレーニングの難易度が高い、精度が低い、効率が低い、時間がかかるなどのいくつかの欠点と制限があります。そのため、RNN に基づくいくつかの改良されたネットワーク モデルが徐々に開発されています。として: Long Short-Term Memory (LSTM)、双方向 RNN、双方向 LSTM、GRU など。これらの改良された RNN モデルは、画像認識の分野で優れた結果を示し、広く使用されています。 LSTM ネットワークを例として、その主なネットワーク構造を紹介します。
Long Short-Term Memory (LSTM) は、RNN における勾配消失または勾配爆発の問題を解決し、長期依存問題を学習できます。その構造は次のとおりです。
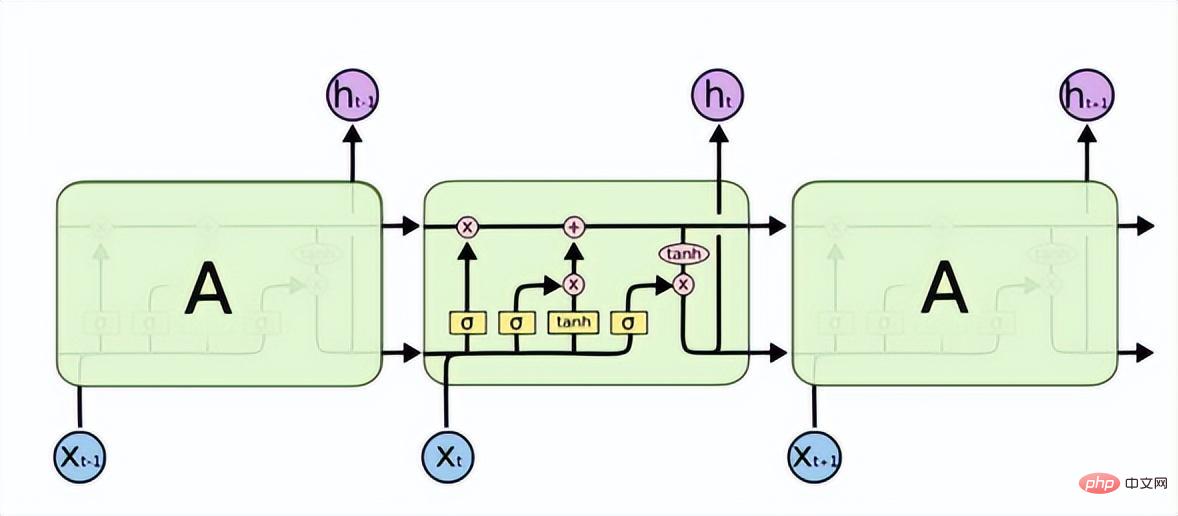
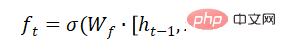
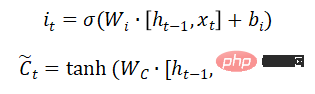
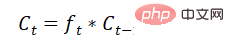
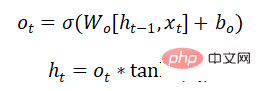
以上が画像認識について話しましょう: リカレント ニューラル ネットワークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
20
15
1376
52
77
11
18
20

 Windows スポットライトの壁紙画像を PC にダウンロードする方法
Aug 23, 2023 pm 02:06 PM
Windows スポットライトの壁紙画像を PC にダウンロードする方法
Aug 23, 2023 pm 02:06 PM
窓は決して美観を無視するものではありません。 XP の牧歌的な緑の野原から Windows 11 の青い渦巻くデザインに至るまで、デフォルトのデスクトップの壁紙は長年にわたってユーザーの喜びの源でした。 Windows スポットライトを使用すると、ロック画面やデスクトップの壁紙に使用する美しく荘厳な画像に毎日直接アクセスできるようになります。残念ながら、これらの画像は表示されません。 Windows スポットライト画像の 1 つが気に入った場合は、その画像をダウンロードして、しばらく背景として保存できるようにする方法を知りたいと思うでしょう。知っておくべきことはすべてここにあります。 Windowsスポットライトとは何ですか? Window Spotlight は、設定アプリの [個人設定] > から利用できる自動壁紙アップデーターです。
 YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
現在の深層学習手法は、モデルの予測結果が実際の状況に最も近くなるように、最適な目的関数を設計することに重点を置いています。同時に、予測に十分な情報を取得するには、適切なアーキテクチャを設計する必要があります。既存の方法は、入力データがレイヤーごとの特徴抽出と空間変換を受けると、大量の情報が失われるという事実を無視しています。この記事では、ディープネットワークを介してデータを送信する際の重要な問題、つまり情報のボトルネックと可逆機能について詳しく説明します。これに基づいて、深層ネットワークが複数の目的を達成するために必要なさまざまな変化に対処するために、プログラマブル勾配情報 (PGI) の概念が提案されています。 PGI は、目的関数を計算するためのターゲット タスクに完全な入力情報を提供することで、ネットワークの重みを更新するための信頼できる勾配情報を取得できます。さらに、新しい軽量ネットワーク フレームワークが設計されています。
 マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
視覚タスク (画像分類など) の深層学習モデルは、通常、単一の視覚領域 (自然画像やコンピューター生成画像など) からのデータを使用してエンドツーエンドでトレーニングされます。一般に、複数のドメインのビジョン タスクを完了するアプリケーションは、個別のドメインごとに複数のモデルを構築し、それらを個別にトレーニングする必要があります。データは異なるドメイン間で共有されません。推論中、各モデルは特定のドメインの入力データを処理します。たとえそれらが異なる分野を指向しているとしても、これらのモデル間の初期層のいくつかの機能は類似しているため、これらのモデルの共同トレーニングはより効率的です。これにより、遅延と消費電力が削減され、各モデル パラメーターを保存するためのメモリ コストが削減されます。このアプローチはマルチドメイン学習 (MDL) と呼ばれます。さらに、MDL モデルは単一モデルよりも優れたパフォーマンスを発揮します。
 Python で画像セマンティック セグメンテーション テクノロジを使用するにはどうすればよいですか?
Jun 06, 2023 am 08:03 AM
Python で画像セマンティック セグメンテーション テクノロジを使用するにはどうすればよいですか?
Jun 06, 2023 am 08:03 AM
人工知能技術の継続的な発展に伴い、画像セマンティックセグメンテーション技術は画像分析分野で人気の研究方向となっています。画像セマンティック セグメンテーションでは、画像内のさまざまな領域をセグメント化し、各領域を分類して、画像の包括的な理解を実現します。 Python はよく知られたプログラミング言語であり、その強力なデータ分析機能とデータ視覚化機能により、人工知能技術研究の分野で最初に選択されます。この記事では、Python で画像セマンティック セグメンテーション技術を使用する方法を紹介します。 1. 前提知識が深まる
 1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
論文のアドレス: https://arxiv.org/abs/2307.09283 コードのアドレス: https://github.com/THU-MIG/RepViTRepViT は、モバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。記事では、主にモデルがグローバル表現を学習できるようにするマルチヘッド セルフ アテンション モジュール (MSHA) のおかげで、軽量 ViT は一般的に視覚タスクにおいて軽量 CNN よりも優れたパフォーマンスを発揮すると述べられています。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。この研究では、著者らは軽量の ViT を効果的なシステムに統合しました。
 C++ で音声認識と音声合成を実装するにはどうすればよいですか?
Aug 26, 2023 pm 02:49 PM
C++ で音声認識と音声合成を実装するにはどうすればよいですか?
Aug 26, 2023 pm 02:49 PM
C++ で音声認識と音声合成を実装するにはどうすればよいですか?音声認識と音声合成は、今日の人工知能の分野で人気のある研究方向の 1 つであり、多くの応用シナリオで重要な役割を果たしています。この記事では、C++ を使用して Baidu AI オープン プラットフォームに基づいた音声認識および音声合成機能を実装する方法を紹介し、関連するコード例を示します。 1. 音声認識 音声認識は人間の音声をテキストに変換する技術であり、音声アシスタント、スマートホーム、自動運転などの分野で広く利用されています。以下は C++ を使用した音声認識の実装です。
 iOS 17: 写真でワンクリックトリミングを使用する方法
Sep 20, 2023 pm 08:45 PM
iOS 17: 写真でワンクリックトリミングを使用する方法
Sep 20, 2023 pm 08:45 PM
iOS 17 の写真アプリを使用すると、Apple は写真を仕様に合わせて簡単にトリミングできるようになります。その方法については、読み続けてください。以前の iOS 16 では、写真アプリで画像をトリミングするにはいくつかの手順が必要でした。編集インターフェイスをタップし、トリミング ツールを選択し、ピンチでズームするジェスチャまたはトリミング ツールの角をドラッグしてトリミングを調整します。 iOS 17 では、Apple がありがたいことにこのプロセスを簡素化し、写真ライブラリで選択した写真を拡大すると、画面の右上隅に新しい切り抜きボタンが自動的に表示されるようになりました。クリックすると、選択したズームレベルで完全なトリミングインターフェイスが表示されるので、画像の好きな部分をトリミングしたり、画像を回転したり、画像を反転したり、画面比率を適用したり、マーカーを使用したりできます。
 Javaを使用して実装された顔検出および認識テクノロジー
Jun 18, 2023 am 09:08 AM
Javaを使用して実装された顔検出および認識テクノロジー
Jun 18, 2023 am 09:08 AM
人工知能技術の継続的な発展に伴い、顔検出および認識技術は日常生活でますます広く使用されるようになりました。顔検出および認識技術は、顔アクセス制御システム、顔決済システム、顔検索エンジンなど、さまざまな場面で広く使用されています。広く使用されているプログラミング言語である Java は、顔の検出および認識テクノロジを実装することもできます。この記事では、Java を使用して顔検出および認識テクノロジを実装する方法を紹介します。 1. 顔検出技術 顔検出技術とは、画像や動画から顔を検出する技術のことです。 Jで
