

星を数え、月を望みながら、何千人ものジェイ ファンが 6 年間待っていました。つい最近、ジェイ チョウがついに新しいアルバムをリリースしました。それがオンラインに公開されると、インターネット上で議論が巻き起こりました。
誰もがその豊かな日々の美しい思い出に浸っている中、バイラル音声を投稿した友人は次のように言いました。 この会話は実際には音声合成でした。
「音声合成」というと、次のようなことが頭に浮かぶかもしれません:
• ナビゲーションの種類は豊富ですが、「この先の交差点を左折してください」という機械的なトーンです。
•クレジット カード センター「#」 ## •
信信、10本の解説動画は同じ音が同じで、見たらすぐに引き離したくなります。 ##多くの人々の固定概念を直接覆す音声合成テクノロジーは、上記のオーディオと同じ完璧で自然な効果をすでに実現できています。この音声の発行者 - Volcano Voice、ByteDance
AI Lab Speech & Audio Intelligent Speech and Audio Team と 2 つの音声を通じて、一般向けに技術的なハイライトをより詳しく理解することができます。 これらの文に入力されているテキストはまったく同じです。つまり、「南部料理はディップソースを好みます。たとえば、バーベキューでは野菜が使われることを初めて上海で知りました」ただし、合成された音声効果は明らかに異なります。つまり、2 番目の音声は、今回 Volcano Voice チームが発表した新しい超自然対話音声合成技術から派生したものです。
人々の日常の表情の状態を思い出してください。脳は情報を処理するために思考時間を必要とします。言語に関しては、人は思わずためらったり、発音したり、倒置したり、文の途中で言葉を変えたり、どもって繰り返したり、表現したい重要な情報を強調するために意図的に発音を強調したりすることがあります。これにより、観察するのが難しい微妙な表現が数多く生まれます。これらの現象は、従来の TTS ではキャプチャして復元することが困難です。この微妙な部分を完璧に再現することが、音の真贋を見分けることを困難にする謎の根源であり、上述のオーディオの謎でもある。具体的には、
Volcano Voice チームがリリースした最新の超自然対話音声合成技術
は、従来の TTS よりもリアルで自然です。 、モーダル粒子 吸気音、ためらいのポーズ、発音の発音などの細部まで完璧に再現そして、従来のサウンドライブラリのデータの1/4だけで、微妙なリズムの特徴や発音を完全に復元することができます。現実の人々の習慣を利用して、合成効果をより現実的にすることができます。 専門家の評価結果によると、この火山音声の新技術と実際の人物の録音との間には基本的に違いがなく、審査員がそれを区別するのは困難です。 また、この技術はビデオダビングや電話接客など多くのシーンで活用されており、近日中にボルケーノエンジン音声技術の公式サイトでも公開される予定です。 #このような強力なテクノロジーは一体どのようにして実現されたのでしょうか?
上記の困難を踏まえ、Volcano Voice の超自然音声合成技術は、テキストと 音声モデリング
の 2 つのレベルからブレークスルーを実現しました。 :# • テキスト レベルでは、火山の声は 成分スタイル移行モデル
を使用し、人々がテキストを話すことをシミュレートする方法を使用します。制御された口語音訳により、テキストが口語表現をより適切に取り入れ、最終的な書きすぎを回避できます。• 音声レベルでは、チームはテキスト分析モデルで画期的な進歩を遂げ、パラ言語予測
を追加しました。 TTS の入力側で、実際の人の発音特性を模倣して、自然で自発的な音声効果を実現します。チームが教師なし機能を備えた TTS モデリング ソリューションを使用し、従来のサウンド ライブラリのデータ スケールの 1/4 のみを使用することで、モデルの安定性と表現力を効果的に向上させたことは言及する価値があります。非常に自然で変化のあるリズミカルな効果を実現できます。素晴らしいと思いませんか? ##• •
#原文
南部料理の場合は 、たとえば初めてのときえっと、初めて上海に行きましたが、バーベキューの野菜にはディップソースも添えないといけないことに気付きました
、北部の人たちは、私がカート半分のキャベツを持ってきたと言っています 、そして #実際、南部料理では調味料の味がより重視されます。つまり、シェフは調味料を使用して腕を発揮します。 ##はい、実際、南部料理は調味料の味にもっと注意を払っています。つまり、シェフは調味料を使って味を表現します。彼のスキル 実際の人物をより適切に復元するには、音声合成技術に関して、Huoshan Speech は、パラ言語モデリングと韻律の多様性についてそれぞれ詳細な研究も行っています。パラ言語モデリングに関しては、チームが導入した合成技術により、自然表現に現れる吸気、笑い、ためらい、修正などのさまざまなパラ言語現象を音響モデルでモデル化し、テキストの意味情報と組み合わせることが可能です。は、パラ言語現象 に自動的に挿入されます。挿入プロセス中に 合理性とランダム性 を同時に考慮し、パフォーマンスをより自然でリアルなものにします。 #############################################文章####
実は体にとても良いのです。 #オーディオ C.wav ##現在の仕事、午前中 #>>基本的に私は朝食をあまり食べません。 #オーディオ D.wav ## 僕らの朝のように基本的に #豆乳と揚げ生地のスティックパンです。 オーディオE.wav # スリップ修正##>>##,本当はお肉が食べたいのです。 ## のコピー #.wav 韻律の多様化の探求において、私たちは教師なし表現学習技術を組み合わせ、表現力の高い音響モデル フレームワークを独自に開発しました。発音、リズム、音色の分離を通じて、データ量の需要を削減するだけでなく、 「超低周波数の発音現象の効率的なモデリングを実現します。同時に、教師なし表現の特徴を使用し、音素レベルの基本周波数とエネルギー情報を組み合わせて、韻律の自然な変化を実現し、高品質の対話を促進します。音声生成」と結論付けています。ボルケーノボイスチーム。 Huoshuo Voice、ByteDance AI Lab Speech&Audio インテリジェント音声およびオーディオ チームは、Douyin、Jianying、Tomato Novels、Feishu に長年サービスを提供してきました。最先端の AI 音声テクノロジー機能とフルスタック音声製品ソリューション、および Volcano Engine を通じて外部企業に技術サービスをオープンします。 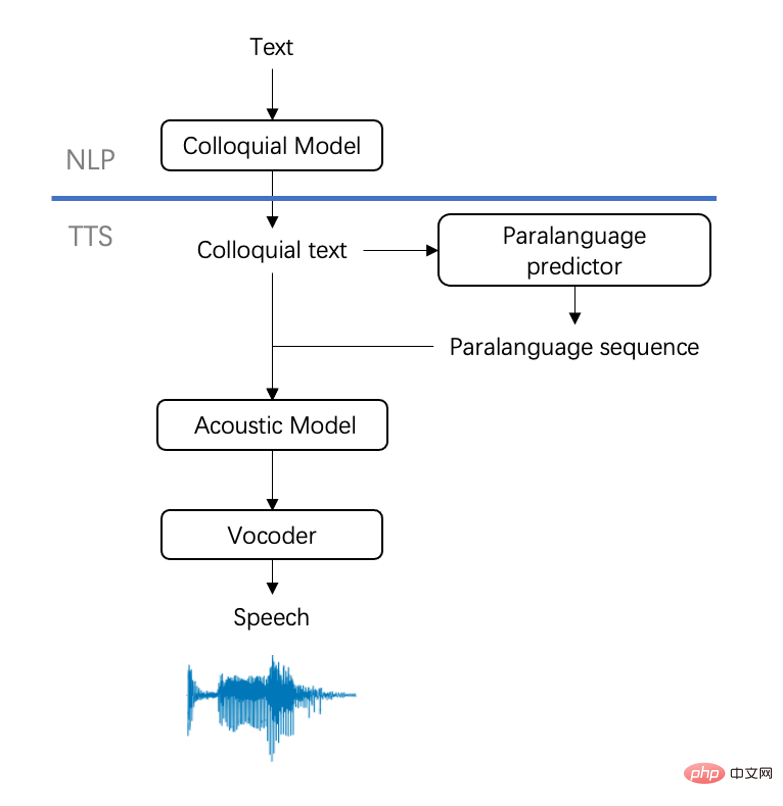
ページ上で「実際の人の表現」が生き生きと表現されるよう、口語的なテキストにこだわります。 テキストは音声合成技術の入力であり、その文体が現実の人物の表現に近いかどうかが合成効果を高める第一歩ですが、根深い文章習慣により、ほとんどの合成前のテキストは十分自然ではない、または多大な労力と継続的な調整が必要であり、時間と労力がかかります。
このような問題を解決するために、Huoshan Voice チームは 2 段階のソリューションを採用し、良好な結果を達成しました。
自動予測後のテキスト ##南部料理では、私のようなディップソースが好まれます。私は初めてでした。上海に行ったとき、バーベキューでは野菜にもディップソースを付ける必要があることを学びました
、私はディップソース
通りにキャベツを買いに行くとき
まあこれは、まるで 、
南部の人がキャベツ半分ほしいと言い、
北部の人キャベツ半分欲しいって言った
パラ言語モデリングのリズミカルな多様性は注目に値し、音声のリアリズムは完全にアップグレードされました
私はそう思います
吸入
延長
以上がVolcano Voice の最新の超自然対話音声合成技術を使用して、実際の音声の 100% の詳細を復元するのに使用されるデータ量はわずか 1/4 です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



