

教師なし機械学習は産業オートメーションにどのようなメリットをもたらしますか?

現代の産業環境にはセンサーやスマート コンポーネントが数多く搭載されており、これらすべてのデバイスが連携して大量のデータを生成します。このデータは、今日ほとんどの工場で活用されておらず、さまざまなエキサイティングな新しいアプリケーションを強化します。実際、IBM によると、平均的な工場では毎日 1TB の生産データが生成されます。ただし、実用的な洞察に変換されるのはデータの約 1% のみです。

機械学習 (ML) は、このデータを活用して大量の価値を引き出すために設計された基本的なテクノロジーです。機械学習システムは、トレーニング データを使用して、明示的な指示なしで特定のタスクを実行するようにシステムに教える数学的モデルを構築できます。
ML は、データに基づいて動作するアルゴリズムを使用して、人間の介入をほとんど必要とせずに意思決定を行います。産業オートメーションにおける機械学習の最も一般的な形式は教師あり機械学習です。これは、人間によってラベル付けされた大量の履歴データを使用してモデルをトレーニングします (つまり、人間が教師付きアルゴリズムをトレーニングします)。
これは、ベアリングの欠陥、潤滑不良、製品の欠陥などのよく知られた問題に役立ちます。教師あり機械学習が不十分となるのは、十分な履歴データが利用できない場合、ラベル付けに時間がかかりすぎるか費用がかかりすぎる場合、またはユーザーがデータの中で何を探しているのか正確にわかっていない場合です。ここで教師なし機械学習が登場します。
教師なし機械学習は、パターンの認識とデータ内の異常の特定に優れたアルゴリズムを使用して、ラベルのないデータを操作することを目的としています。教師なし機械学習を適切に適用すると、状態監視やパフォーマンス テストからサイバーセキュリティや資産管理に至るまで、さまざまな産業オートメーションのユースケースに役立ちます。
教師あり学習と教師なし学習
教師あり機械学習は、教師なし機械学習よりも実行が簡単です。適切にトレーニングされたモデルを使用すると、非常に一貫性のある信頼性の高い結果が得られます。教師あり機械学習には、関連するすべてのケースを含める必要があるため、大量の履歴データが必要になる場合があります。つまり、製品の欠陥を検出するには、データに十分な数の欠陥製品のケースが含まれている必要があります。これらの大量のデータセットにラベルを付けるには、時間と費用がかかる場合があります。さらに、モデルのトレーニングは芸術です。良い結果を生み出すには、適切に編成された大量のデータが必要です。
現在、さまざまな ML アルゴリズムのベンチマークを行うプロセスは、AutoML などのツールを使用して大幅に簡素化されています。同時に、トレーニング プロセスを過度に制約すると、モデルがトレーニング セットでは良好にパフォーマンスするものの、実際のデータではパフォーマンスが低下する可能性があります。もう 1 つの重要な欠点は、教師あり機械学習が、データの予期せぬ傾向を特定したり、新しい現象を発見したりするのにあまり効果的ではないことです。このような種類のアプリケーションでは、教師なし機械学習の方がより良い結果が得られます。
一般的な教師なし機械学習手法
教師あり機械学習と比較して、教師なし機械学習はラベルのない入力に対してのみ動作します。これは、人間の助けを借りずに未知のパターンや相関関係を発見するためのデータ探索用の強力なツールを提供します。ラベルのないデータを操作できるため、時間と費用が節約され、入力が生成されるとすぐに教師なし機械学習がデータを操作できるようになります。
欠点は、教師なし機械学習は教師あり機械学習よりも複雑であることです。より高価で、より高度な専門知識が必要であり、多くの場合、より多くのデータが必要になります。その出力は教師あり ML よりも信頼性が低くなる傾向があり、最適な結果を得るには最終的に人間の監督が必要になります。
教師なし機械学習技術の 3 つの重要な形式は、クラスタリング、異常検出、データの次元削減です。
クラスタリング
名前が示すように、クラスタリングには、データセットを分析してデータ間の共有特性を特定し、類似したインスタンスをグループ化することが含まれます。クラスタリングは教師なし ML 手法であるため、(人間ではなく) アルゴリズムがランキング基準を決定します。したがって、クラスタリングは驚くべき発見につながる可能性があり、優れたデータ探索ツールです。
簡単な例を挙げると、生産部門で 3 人の人が果物の仕分けを依頼されていると想像してください。柑橘類、核果、トロピカル フルーツなどの果物の種類で並べ替える場合もあれば、色で並べ替える場合もあり、形状で並べ替える場合も考えられます。各方法では、異なる一連の特性が強調表示されます。
#クラスタリングはさまざまなタイプに分類できます。最も一般的なものは次のとおりです。相互排他的クラスタリング (排他的クラスタリング): データ インスタンスは、クラスタに排他的に割り当てられます。
ファジー クラスタリングまたはオーバーラップ クラスタリング (ファジー クラスタリング): データ インスタンスを複数のクラスターに割り当てることができます。たとえば、オレンジは柑橘類であると同時にトロピカル フルーツでもあります。ラベルなしデータを操作する教師なし ML アルゴリズムの場合、データ ブロックがグループ A とグループ B に正しく属する確率を割り当てることができます。
階層クラスタリング: この手法には、クラスターのセットではなく、クラスター化されたデータの階層構造の構築が含まれます。オレンジは柑橘類ですが、より大きな球形の果物グループにも含まれており、すべての果物グループでさらに吸収されます。
最も一般的なクラスタリング アルゴリズムのセットを見てみましょう:
- K-mean
K-平均 (K 平均) アルゴリズムはデータを K 個のクラスターに分類します。K の値はユーザーによって事前に設定されます。プロセスの開始時に、アルゴリズムは K 個のデータ ポイントを K 個のクラスターの重心としてランダムに割り当てます。次に、各データ ポイントとそのクラスターの重心の間の平均を計算します。これにより、データがクラスターに再割り当てされます。この時点で、アルゴリズムは重心を再計算し、平均の計算を繰り返します。重心を計算し、クラスターを並べ替えるプロセスを、一定の解に到達するまで繰り返します (図 1 を参照)。

図 1: K 平均法アルゴリズムはデータセットを K 個のクラスターに分割し、最初に K 個のデータポイントを重心としてランダムに選択します。を実行し、残りのインスタンスをクラスター全体にランダムに分散します。
K 平均法アルゴリズムはシンプルで効率的です。パターン認識やデータマイニングに非常に役立ちます。欠点は、セットアップを最適化するためにデータセットに関する高度な知識が必要なことです。また、異常値の影響も不均衡に受けます。
- K-median
K-median アルゴリズムは K-means に近いものです。基本的に同じプロセスを使用しますが、各データ ポイントの平均を計算する代わりに中央値を計算する点が異なります。したがって、アルゴリズムは外れ値の影響を受けにくくなります。
クラスター分析の一般的な使用例をいくつか示します。
- クラスター化は、セグメンテーションなどの使用例に非常に効果的です。これは多くの場合、顧客分析に関連しています。また、資産クラスに適用して、製品の品質とパフォーマンスを分析するだけでなく、製品のパフォーマンスと耐用年数に影響を与える可能性のある使用パターンを特定することもできます。これは、スマート倉庫内の自動移動ロボットや検査やデータ収集用のドローンなどの資産の「フリート」を管理する OEM 企業にとって役立ちます。
- 画像処理操作の一部として画像のセグメンテーションに使用できます。
- クラスター分析は、教師あり ML アプリケーション用のデータを準備する前処理ステップとしても使用できます。
異常検出
異常検出は、欠陥検出から状態監視、サイバーセキュリティまで、さまざまなユースケースにとって重要です。これは教師なし機械学習における重要なタスクです。教師なし機械学習で使用される異常検出アルゴリズムはいくつかあります。最も一般的な 2 つのアルゴリズムを見てみましょう:
- Isolation Forest Algorithm
異常検出の標準的な方法は、一連の正常値を確立し、各データを分析して正常値から逸脱しているかどうか、またどの程度逸脱しているかを確認することです。 ML で使用される種類の大量のデータ セットを操作する場合、これは非常に時間のかかるプロセスです。分離フォレスト アルゴリズムは逆のアプローチを採用します。外れ値は、一般的でもなく、データセット内の他のインスタンスと大きく異なるものでもないと定義されます。したがって、それらは他のインスタンス上のデータセットの残りの部分からより簡単に分離されます。
分離フォレスト アルゴリズムのメモリ要件は最小限であり、必要な時間はデータ セットのサイズに直線的に関係します。無関係な属性が含まれる場合でも、高次元データを処理できます。
- 局所外れ値係数 (LOF)
重心からの距離だけで外れ値を特定するという課題の 1 つはい、小さなクラスターから近い距離にあるデータ ポイントは外れ値である可能性がありますが、大きなクラスターから遠く離れているように見えるデータ ポイントは外れ値ではない可能性があります。 LOF アルゴリズムは、この区別を行うように設計されています。
LOF は、近隣のデータ ポイントよりもはるかに大きい局所的な密度偏差を持つデータ ポイントとして外れ値を定義します (図 2 を参照)。 K-means と同様に、事前にユーザーによるセットアップが必要ですが、非常に効果的です。半教師ありアルゴリズムとして使用し、通常のデータのみでトレーニングした場合は、新規性の検出にも適用できます。
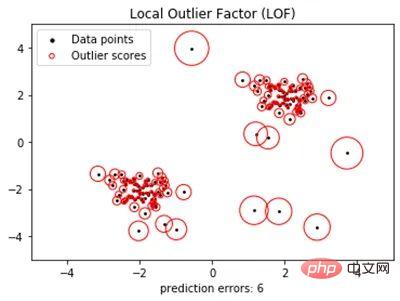
図 2: 局所外れ値係数 (LOF) は、各データ ポイントの局所密度偏差を使用して異常スコアを計算します。 、それによって正常なデータポイントを外れ値から区別します。
次に、異常検出の使用例をいくつか示します:
- 予知保全: ほとんどの産業用機器は、最小限のダウンタイムで持続するように設計されています。したがって、利用できる履歴データは限られていることがよくあります。教師なし ML は限られたデータセットであっても異常な動作を検出できるため、このような場合には発達上の欠陥を特定できる可能性があります。ここでもフリート管理に使用でき、レビューが必要なデータの量を最小限に抑えながら欠陥を早期に警告します。
- 品質保証/検査: 機械が不適切に操作されると、規格外の製品が生産される可能性があります。教師なし機械学習を使用して、機能とプロセスを監視し、異常を報告できます。標準の QA プロセスとは異なり、ラベル付けやトレーニングなしでこれを実行できます。
- 画像異常の特定: これは、危険な病状を特定するための医療画像処理で特に役立ちます。
- サイバーセキュリティ: サイバーセキュリティにおける最大の課題の 1 つは、脅威が常に変化していることです。この場合、教師なし ML による異常検出は非常に効果的です。標準的なセキュリティ手法の 1 つは、データ フローを監視することです。通常は他のコンポーネントにコマンドを送信している PLC が、異常なデバイスまたは IP アドレスからのコマンドの安定したストリームを突然受信し始めた場合、これは侵入を示している可能性があります。しかし、悪意のあるコードが信頼できるソースから来た場合 (または悪意のある者が信頼できるソースを偽装した場合) はどうなるでしょうか?教師なし学習では、コマンドを受信するデバイスの異常な動作を探すことで、不正行為を検出できます。
- テスト データ分析: テストは、設計と生産の両方において重要な役割を果たします。 2 つの最大の課題は、関係する膨大な量のデータと、固有のバイアスを導入せずにデータを分析する能力です。教師なし機械学習は両方の課題を解決できます。これは、テスト チームが何を探しているのかさえわからない開発プロセスや運用環境のトラブルシューティング中に特に有益です。
- データ前処理: 機械学習に関して、よく言われる哲学は、多ければ多いほど良いというものです。とはいえ、特に無関係または冗長なデータの場合は、多いほど良い場合もあります。このような場合、教師なし機械学習を使用して不要な特徴 (データ次元) を削除し、処理時間を短縮し、結果を向上させることができます。ビジュアル システムの場合、教師なし機械学習をノイズ低減に使用できます。
- 画像圧縮: PCA は、意味のある情報を保持しながらデータ セットの次元を削減することに非常に優れています。これにより、アルゴリズムは画像圧縮に非常に優れたものになります。
- パターン認識: 上で説明したのと同じ機能により、PCA は顔認識やその他の複雑な画像認識などのタスクに役立ちます。
- 質問は何ですか?
- ビジネスケースとは何ですか?定量化の目的は何ですか?プロジェクトはどれくらい早く投資収益率をもたらしますか?これは教師あり学習や他の従来のソリューションとどう違うのでしょうか?
- どのような種類の入力データが利用可能ですか?いくら持っていますか?それはあなたが答えたい質問と関連していますか?ラベル付きデータをすでに生成するプロセスはありますか? たとえば、不良品を特定する QA プロセスはありますか?機器の故障を記録するメンテナンスデータベースはありますか?
- 教師なし機械学習に適していますか?
- プロジェクトを開始する前に、下調べをして戦略を立ててください。
- 小規模から始めて、より小規模なエラーを修正してください。
- ソリューションがスケーラブルであることを確認してください。パイロット プロジェクトが煉獄に陥ることは避けるべきです。
- パートナーと協力することを検討してください。あらゆる種類の機械学習には専門知識が必要です。自動化する適切なツールとパートナーを見つけてください。車輪の再発明はしないでください。お金を払って必要なスキルを社内で構築することも、パートナーやエコシステムに面倒な作業を任せながら、自分が最も得意とする製品やサービスの提供にリソースを振り向けることもできます。
産業環境で収集されたデータは貴重なリソースになりますが、それは適切に活用された場合に限られます。教師なし機械学習は、データセットを分析して実用的な洞察を抽出するための強力なツールとなり得ます。このテクノロジーの導入は困難を伴う場合がありますが、困難な世界では大きな競争上の優位性をもたらす可能性があります。
以上が教師なし機械学習は産業オートメーションにどのようなメリットをもたらしますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7552
7552
 15
1382
52
83
11
22
95
15
1382
52
83
11
22
95

 WordPressのインストールの複雑さを解決する方法とComposerを使用して更新する
Apr 17, 2025 pm 10:54 PM
WordPressのインストールの複雑さを解決する方法とComposerを使用して更新する
Apr 17, 2025 pm 10:54 PM
WordPress Webサイトを管理する場合、インストール、更新、マルチサイト変換などの複雑な操作に遭遇することがよくあります。これらの操作は時間がかかるだけでなく、エラーになりやすく、ウェブサイトを麻痺させます。 WP-CRIコアコマンドと作曲家を組み合わせることで、これらのタスクを大幅に簡素化し、効率と信頼性を向上させることができます。この記事では、作曲家を使用してこれらの問題を解決し、WordPress管理の利便性を向上させる方法を紹介します。
 PHPコード検査の加速:Overtrue/Phplintライブラリを使用した経験と練習
Apr 17, 2025 pm 11:06 PM
PHPコード検査の加速:Overtrue/Phplintライブラリを使用した経験と練習
Apr 17, 2025 pm 11:06 PM
開発プロセス中に、コードの正確性と保守性を確保するために、PHPコードで構文チェックを実行する必要があることがよくあります。ただし、プロジェクトが大きい場合、シングルスレッドの構文チェックプロセスが非常に遅くなる可能性があります。最近、私は自分のプロジェクトでこの問題に遭遇しました。複数の方法を試した後、最終的にライブラリがOvertrue/Phplintを見つけました。これにより、並列処理によりコード検査の速度が大幅に向上します。
 SQL解析の問題を解決する方法は? Greenlion/PHP-SQL-Parserを使用してください!
Apr 17, 2025 pm 09:15 PM
SQL解析の問題を解決する方法は? Greenlion/PHP-SQL-Parserを使用してください!
Apr 17, 2025 pm 09:15 PM
SQLステートメントの解析を必要とするプロジェクトを開発するとき、私はトリッキーな問題に遭遇しました:MySQLのSQLステートメントを効率的に解析し、重要な情報を抽出する方法。多くの方法を試した後、Greenlion/PHP-SQL-Parserライブラリが私のニーズを完全に解決できることがわかりました。
 Laravelの複雑な属性の関係の問題を解決する方法は? Composerを使用してください!
Apr 17, 2025 pm 09:54 PM
Laravelの複雑な属性の関係の問題を解決する方法は? Composerを使用してください!
Apr 17, 2025 pm 09:54 PM
Laravel Developmentでは、特にマルチレベルの属する関係に関しては、複雑なモデル関係に対処することは常に課題でした。最近、私はこの問題に、従来のHasManyThrough関係がニーズを満たすことができず、データクエリが複雑で非効率的になることになっているマルチレベルモデル関係を扱うプロジェクトでこの問題に遭遇しました。いくつかの探索の後、私は図書館がStaudenmeir/属していることを発見しました。
 ウェブサイトのパフォーマンスを最適化する方法:Minifyライブラリの使用から学んだ経験とレッスン
Apr 17, 2025 pm 11:18 PM
ウェブサイトのパフォーマンスを最適化する方法:Minifyライブラリの使用から学んだ経験とレッスン
Apr 17, 2025 pm 11:18 PM
Webサイトの開発の過程で、ページの読み込みを改善することは常に私の最優先事項の1つです。かつて、Webサイトのパフォーマンスを向上させるために、Miniifyライブラリを使用してCSSファイルとJavaScriptファイルを圧縮およびマージしようとしました。しかし、私は使用中に多くの問題と課題に遭遇しました。最終的には、Miniifyがもはや最良の選択ではない可能性があることに気付きました。以下では、私の経験と、Composerを通じてMinifyをインストールして使用する方法を共有します。
 CSSプレフィックス問題を解く作曲家を使用して:Padaliyajay/PHP-Autoprefixerライブラリの実践
Apr 17, 2025 pm 11:27 PM
CSSプレフィックス問題を解く作曲家を使用して:Padaliyajay/PHP-Autoprefixerライブラリの実践
Apr 17, 2025 pm 11:27 PM
フロントエンドプロジェクトを開発する際には、トリッキーな問題があります。CSSプロパティにブラウザプレフィックスを手動で追加して、互換性を確保する必要があります。これは時間がかかるだけでなく、エラーが発生しやすいものでもあります。いくつかの調査の後、私はPadaliyajay/PHP-Autoprefixerライブラリを発見しました。
 Typo3CMSのインストールと構成の問題を解決する方法は?作曲家と簡単に行うことができます!
Apr 17, 2025 pm 10:51 PM
Typo3CMSのインストールと構成の問題を解決する方法は?作曲家と簡単に行うことができます!
Apr 17, 2025 pm 10:51 PM
Webサイト開発にTypo3CMSを使用する場合、インストールと構成の拡張機能に問題が発生することがよくあります。特に初心者にとっては、Typo3とその拡張機能を適切にインストールして構成する方法は頭痛の種になります。私は実際のプロジェクトで同様の困難を抱えており、ComposerとTypo3CMSComposerInstallersを使用してこれらの問題を解決することになりました。
 PHPのphar://ストリーム処理セキュリティの問題を解決する方法は? typo3/phar-stream-wrapperを使用してください!
Apr 17, 2025 pm 08:24 PM
PHPのphar://ストリーム処理セキュリティの問題を解決する方法は? typo3/phar-stream-wrapperを使用してください!
Apr 17, 2025 pm 08:24 PM
PHPプロジェクトを扱う際には深刻な問題があります。Phar://ストリーム処理にはセキュリティの脆弱性があり、悪意のあるコードの実行につながる可能性があります。いくつかの研究と試験の後、私は効果的な解決策を見つけました - Typo3/Phar-Stream-Wrapperライブラリを使用しています。このライブラリは、私のセキュリティの問題を解決するだけでなく、柔軟なインターセプターメカニズムを提供し、PhARファイルの管理をより安全で制御可能にします。
