

データの予測と分析に機械学習モデルが普及するにつれて、ランダム フォレスト アルゴリズムの使用が勢いを増しています。ランダム フォレストは、機械学習の分野で回帰および分類タスクに使用される教師あり学習アルゴリズムです。これは、トレーニング時に多数の決定木を構築し、クラスのモード (分類) または単一ツリーの平均予測 (回帰) のいずれかのクラスを出力することによって機能します。
#この記事では、オンラインの実世界データ セットを使用してランダム フォレスト アルゴリズムを実装する方法について説明します。また、詳細なコードの説明と各ステップの説明、モデルのパフォーマンスと視覚化の評価も提供します。
使用するデータセットは「ウィスコンシン州乳がん (診断) データセット」です。これは一般に公開されており、UCI Machine Learning リポジトリを通じてアクセスできます。データセットには、30 の属性と 2 つのカテゴリ (悪性と良性) を持つ 569 のインスタンスがあります。私たちの目標は、これらの症例を 30 の属性に基づいて分類し、良性か悪性かを判断することです。データセットは https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data からダウンロードできます。
まず、必要なライブラリをインポートします:
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
次に、データセットを読み込みます:
df = pd.read_csv(r"C:UsersUserDownloadsdatabreast_cancer_wisconsin_diagnostic_dataset.csv") df
出力:
##モデルを構築する前に、データを前処理する必要があります。 「id」列と「Unnamed: 32」列はモデルには役に立たないので、削除します。
df = df.drop([ 'id' , 'Unnamed: 32' ], axis=1) df
出力:
次に、「Diagnostic」列をターゲット変数に割り当て、機能から削除します。
target = df['diagnosis']
features = df.drop('diagnosis', axis=1)データセットをトレーニング セットとテスト セットに分割します。データの 70% をトレーニングに使用し、30% をテストに使用します。
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42)
データを前処理してトレーニング セットとテスト セットに分割すると、次のことが可能になります。ランダム フォレスト モデルを構築します。
rf = RandomForestClassifier(n_estimators=100, random_state=42) rf.fit(X_train, y_train)
ここでは、フォレスト内のデシジョン ツリーの数を 100 に設定し、ランダム状態を [結果の再現性を確保] に設定します。
これで、モデルのパフォーマンスを評価できます。精度スコア、混同行列、分類レポートを評価に使用します:
y_pred = rf.predict(X_test)
# 准确度分数
print("Accuracy Score:", accuracy_score(y_test, y_pred))
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:n", conf_matrix)
# Classification Report
class_report = classification_report(y_test, y_pred)
print("Classification Report:n", class_report)出力:
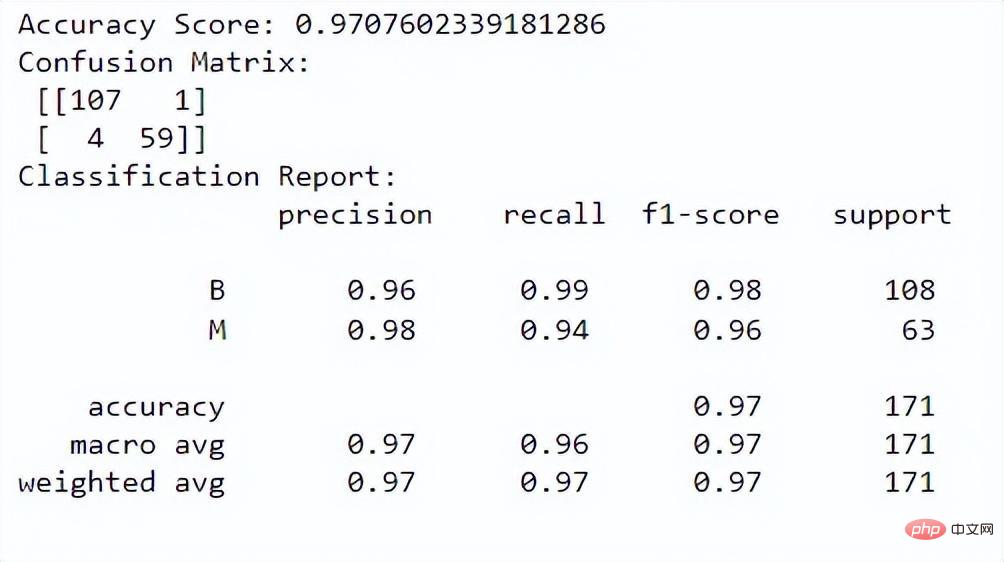
精度スコアは、インスタンスを正しく分類する際にモデルがどの程度うまく機能するかを示します。混同行列により、モデルの分類パフォーマンスをより深く理解できるようになります。分類レポートは、両方のクラスの適合率、再現率、f1 スコア、およびサポート値を提供します。
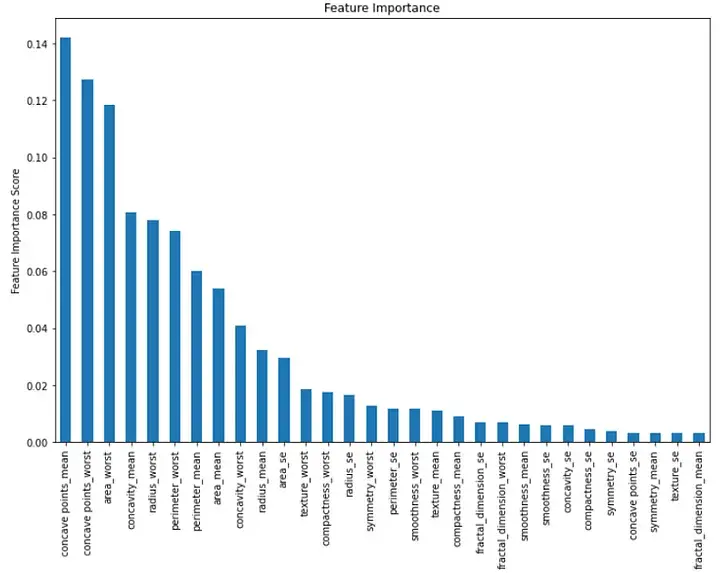
最後に、モデル内の各機能の重要性を視覚化できます。これを行うには、特徴の重要度の値を示す棒グラフを作成します。
importance = rf.feature_importances_ feat_imp = pd.Series(importance, index=features.columns) feat_imp = feat_imp.sort_values(ascending=False)
plt.figure(figsize=(12,8))
feat_imp.plot(kind='bar')
plt.ylabel('Feature Importance Score')
plt.title("Feature Importance")
plt.show()出力:
要約すると、機械学習でのランダム フォレスト アルゴリズムの実装は、分類タスクのための強力なツールです。これを使用して、複数の特徴に基づいてインスタンスを分類し、モデルのパフォーマンスを評価できます。このペーパーでは、オンラインの実世界データセットを使用し、詳細なコードの説明と各ステップの説明、モデルのパフォーマンスと視覚化の評価を提供します。
以上が機械学習でランダム フォレスト アルゴリズムを実装するためのガイドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



