

繰り返される困難な気象条件におけるデータセットと運転認識

arXiv 論文「Ithaca365: 繰り返される厳しい気象条件下でのデータセットと運転認識」 (22 年 8 月 1 日にアップロード)、コーネル大学とオハイオ州立大学の研究。

近年、特定の場所や良好な気象条件下で収集されることが多い大規模なデータセットの使用により、自動運転車の認識能力が向上しています。 。ただし、高度な安全要件を満たすために、これらのセンシング システムは、雪や雨の状態を含むさまざまな気象条件において堅牢に動作する必要があります。
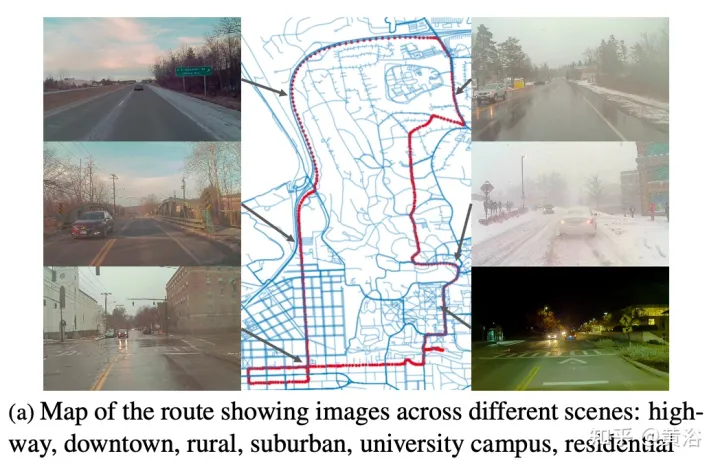
この記事では、新しいデータ収集プロセス、つまりさまざまなシナリオ (都市、高速道路、田園地帯、キャンパス)、天候 (雪、雨、太陽) を使用して、堅牢な自動運転を実現するためのデータセットを提案します。 、時間 データは、(昼夜)および交通状況(歩行者、自転車、自動車)の下で、15 km のルートに沿って繰り返し記録されました。
データセットには、カメラや LIDAR センサーからの画像と点群のほか、ルート全体での対応を確立するための高精度 GPS/INS が含まれています。データセットには、道路とオブジェクトの注釈、ローカル オクルージョン、アモーダル マスクでキャプチャされた 3D 境界ボックスが含まれています。
パスを繰り返すことで、ターゲットの発見、継続的な学習、異常検出のための新しい研究の方向性が開かれます。
Ithaca365 リンク: 新しいデータ収集プロセスを介して堅牢な自動運転を可能にする新しいデータセット
写真はデータ収集のセンサー構成を示しています:
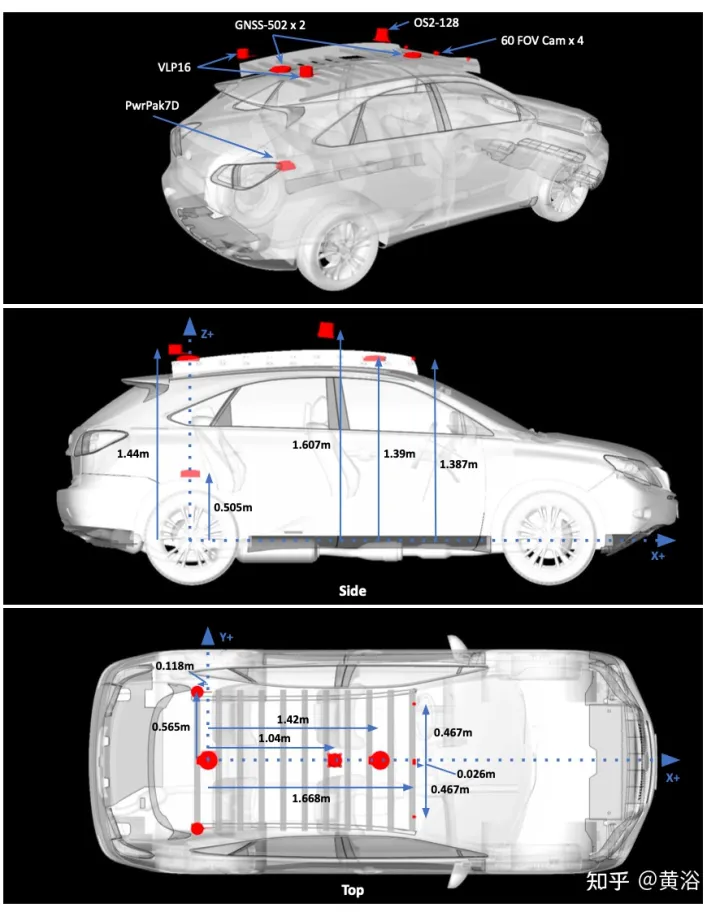
図 a は、複数の場所で撮影された画像を含むルート マップを示しています。ドライブは、夜間を含む 1 日のさまざまな時間にデータを収集するようにスケジュールされました。道路除雪の前後の大雪状況を記録します。
データセットの重要な特徴は、同じ場所が異なる条件下でも観察できることです。例を図 b に示します。

図は、さまざまな条件下でのトラバーサル解析を示しています。
カスタム マーキング ツールを開発し、使用します。道路や物体のアモーダルマスクを取得します。雪に覆われた道路など、異なる環境条件での道路ラベルの場合は、同じルートを繰り返し通過します。具体的には、GPS 姿勢データと LIDAR データから構築された点群道路マップにより、道路ラベルの「好天」が「悪天候」に変換されます。
ルート/データは 76 の間隔に分割されます。点群を BEV に投影し、ポリゴン アノテーターを使用して道路にラベルを付けます。道路が BEV でマークされると (2 次元の道路境界が生成されます)、ポリゴンは平均高さ 1.5 m のしきい値を使用して、より小さな 150 m^2 のポリゴンに分解され、ポリゴン内の点に対して平面フィットが行われます。道路の高さを決める境界線。
RANSAC とリグレッサーを使用してこれらの点に平面を当てはめ、推定された地表平面を使用して境界に沿った各点の高さを計算します。道路のポイントを画像に投影し、深度マスクを作成して道路の非モーダル ラベルを取得します。 GPS を使用して位置をマークされた地図に照合し、ICP を使用してルートを最適化することで、新しい収集ルート上の特定の位置に地上面を投影できます。
道路ラベルの平均投影グラウンド トゥルース マスクが、同じ場所にある他のすべてのグラウンド トゥルース マスクと 80% の mIOU に適合することを検証することで、ICP ソリューションの最終チェックを行います。適合しない場合は、位置データをクエリします。回収されない。
非モーダル ターゲットには、自動車、バス、トラック (貨物、消防車、ピックアップ トラック、救急車を含む)、歩行者、自転車、オートバイの 6 つの前景ターゲット カテゴリに対して Scale AI のラベルが付けられます。
このラベル付けパラダイムには 3 つの主なコンポーネントがあります。まず、オブジェクトの可視インスタンスを識別し、次にオクルージョンされたインスタンスのセグメンテーション マスクを推測し、最後に各オブジェクトのオクルージョン順序をラベル付けします。マーキングは、前方カメラビューの左端で実行されます。 KINS と同じ標準に従います (「Amodal instancesegmentation with kins dataset」。CVPR、2019)。
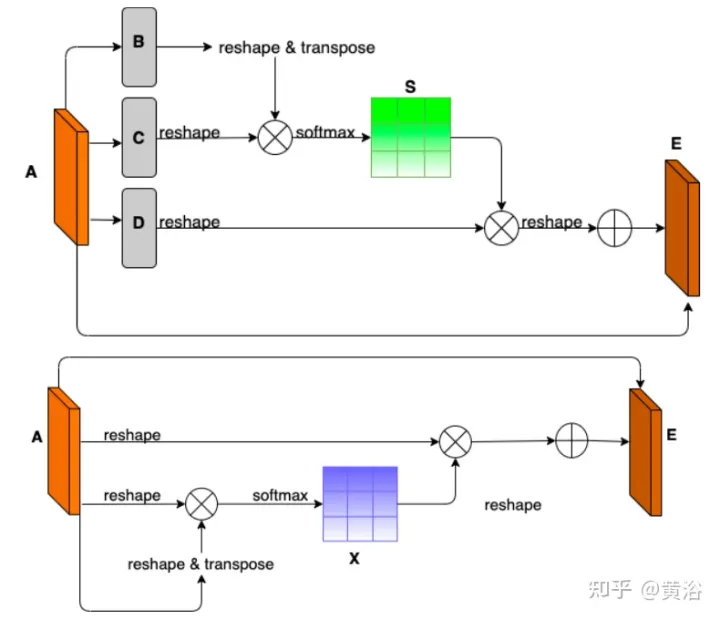
環境の多様性とデータセットのアモーダルな品質を実証するために、ピクセル レベルでアモーダルな道路を識別するために 2 つのベースライン ネットワークがトレーニングおよびテストされ、道路が雪や車で覆われている場合でも機能します。最初のベースライン ネットワークは Semantic Foreground Inpainting (SFI) です。図に示すように、2 番目のベースラインでは、SFI を改善するために次の 3 つの革新が採用されています。
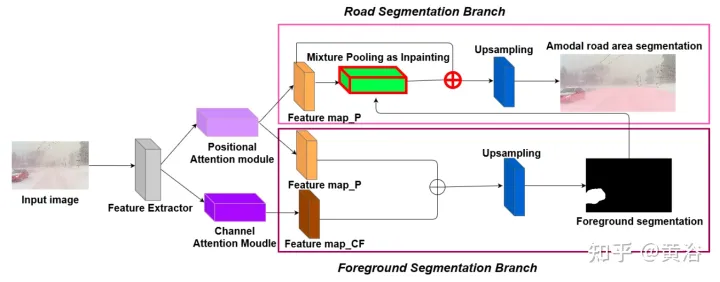
- ポジションとチャネル 注: アモーダル セグメンテーションは主に目に見えないものを推測するため、コンテキストは非常に重要な手がかりとなります。 DAN (「シーン セグメンテーションのためのデュアル アテンション ネットワーク」、CVPR’2019) は、2 つの異なる背景をキャプチャするための 2 つのイノベーションを紹介しています。位置注意モジュール (PAM) は、ピクセル特徴を使用して画像の他のピクセルに焦点を合わせ、実際に画像の他の部分からコンテキストをキャプチャします。チャネル アテンション モジュール (CAM) は、同様のアテンション メカニズムを使用してチャネル情報を効率的に集約します。ここでは、これら 2 つのモジュールがバックボーン特徴抽出器に適用されます。 CAM と PAM を組み合わせて、微細なマスク境界の位置特定を改善します。最終的な前景インスタンス マスクは、アップサンプリング レイヤーを通じて取得されます。
- 修復としてのハイブリッド プーリング: 最大プーリングはパッチ操作として使用され、重なり合う前景フィーチャを近くの背景フィーチャに置き換え、非モーダル道路フィーチャの復元に役立ちます。ただし、背景の特徴は通常スムーズに分散されるため、最大プーリング操作は追加のノイズの影響を非常に受けやすくなります。対照的に、平均的なプーリング操作ではノイズが自然に軽減されます。この目的のために、平均プーリングと最大プーリングを組み合わせてパッチを適用します。これは、混合プーリングと呼ばれます。
- Sum 操作: 最後のアップサンプリング層の前に、ハイブリッド プーリング モジュールからの機能は直接渡されませんが、PAM モジュールの出力からの残りのリンクが含まれます。道路セグメンテーション ブランチ内の 2 つの特徴マップを共同で最適化することにより、PAM モジュールは遮蔽された領域の背景の特徴も学習できます。これにより、バックグラウンドの特徴をより正確に回復できるようになります。
この図は、PAM と CAM のアーキテクチャ図を示しています。
ハイブリッド プーリング パッチ適用アルゴリズムの疑似コードは次のとおりです。

非モーダル道路セグメンテーションのトレーニング コードとテスト コードは次のとおりです: https://github##.com/coolgrasshopper/amodal_road_segmentation
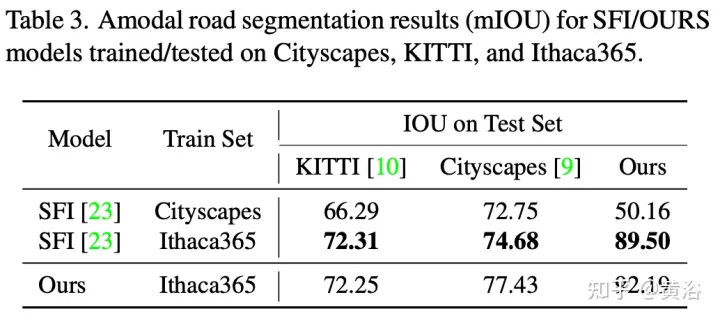
実験結果は次のとおりです: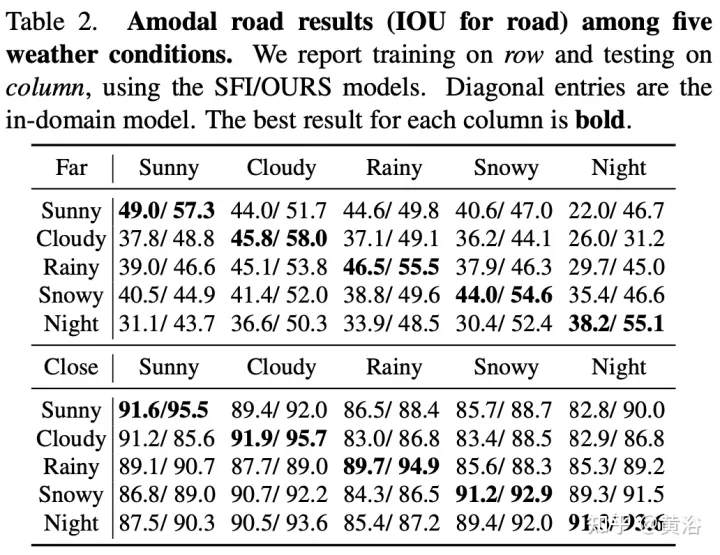
以上が繰り返される困難な気象条件におけるデータセットと運転認識の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 Windows 11 のスマート アプリ コントロール: オンまたはオフにする方法
Jun 06, 2023 pm 11:10 PM
Windows 11 のスマート アプリ コントロール: オンまたはオフにする方法
Jun 06, 2023 pm 11:10 PM
インテリジェント アプリ コントロールは、ランサムウェアやスパイウェアなど、データに損害を与える可能性のある不正なアプリから PC を保護する Windows 11 の非常に便利なツールです。この記事では、スマート アプリ コントロールとは何か、その仕組み、および Windows 11 でスマート アプリ コントロールをオンまたはオフにする方法について説明します。 Windows 11 のスマート アプリ コントロールとは何ですか? Smart App Control (SAC) は、Windows 1122H2 更新プログラムで導入された新しいセキュリティ機能です。 Microsoft Defender またはサードパーティのウイルス対策ソフトウェアと連携して、デバイスの速度を低下させたり、予期しない広告を表示したり、その他の予期しないアクションを実行したりする可能性のある不要なアプリをブロックします。スマートなアプリケーション
 飛び回ったり、口を開けたり、見つめたり、眉毛を上げたりする顔の特徴をAIが完璧に模倣し、ビデオ詐欺を防ぐことは不可能
Dec 14, 2023 pm 11:30 PM
飛び回ったり、口を開けたり、見つめたり、眉毛を上げたりする顔の特徴をAIが完璧に模倣し、ビデオ詐欺を防ぐことは不可能
Dec 14, 2023 pm 11:30 PM
これほど強力なAIの模倣能力では、それを防ぐことは本当に不可能です。 AIの発展は今ここまで進んでいるのか?前足で顔の特徴を浮き上がらせ、後ろ足で全く同じ表情を再現し、見つめたり、眉を上げたり、口をとがらせたり、どんなに大袈裟な表情でも完璧に真似しています。難易度を上げて、眉毛を高く上げ、目を大きく開き、口の形も歪んでいるなど、バーチャルキャラクターアバターで表情を完璧に再現できます。左側のパラメータを調整すると、右側の仮想アバターもそれに合わせて動きが変化し、口や目の部分がアップになります。同じです(右端)。この研究は、GaussianAvatars を提案するミュンヘン工科大学などの機関によるものです。
 MotionLM: マルチエージェント動作予測のための言語モデリング技術
Oct 13, 2023 pm 12:09 PM
MotionLM: マルチエージェント動作予測のための言語モデリング技術
Oct 13, 2023 pm 12:09 PM
この記事は自動運転ハート公式アカウントより許可を得て転載しておりますので、転載については出典元までご連絡ください。原題: MotionLM: Multi-Agent Motion Forecasting as Language Modeling 論文リンク: https://arxiv.org/pdf/2309.16534.pdf 著者の所属: Waymo 会議: ICCV2023 論文のアイデア: 自動運転車の安全計画のために、将来の動作を確実に予測するロードエージェントの数は非常に重要です。この研究では、連続的な軌跡を離散的なモーション トークンのシーケンスとして表現し、マルチエージェントのモーション予測を言語モデリング タスクとして扱います。私たちが提案するモデル MotionLM には次の利点があります。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
「ComputerWorld」誌はかつて、IBM がエンジニアが必要な数式を書いて提出できる新しい言語 FORTRAN を開発したため、「プログラミングは 1960 年までに消滅するだろう」という記事を書きました。コンピューターを実行すればプログラミングは終了します。画像 数年後、私たちは新しいことわざを聞きました: ビジネスマンは誰でもビジネス用語を使って問題を説明し、コンピュータに何をすべきかを伝えることができます。COBOL と呼ばれるこのプログラミング言語を使用することで、企業はもはやプログラマーを必要としません。その後、IBM は従業員がフォームに記入してレポートを作成できるようにする RPG と呼ばれる新しいプログラミング言語を開発したと言われており、会社のプログラミング ニーズのほとんどはこれで完了できます。
 カスタム データセットへの OpenAI CLIP の実装
Sep 14, 2023 am 11:57 AM
カスタム データセットへの OpenAI CLIP の実装
Sep 14, 2023 am 11:57 AM
2021 年 1 月、OpenAI は DALL-E と CLIP という 2 つの新しいモデルを発表しました。どちらのモデルも、テキストと画像を何らかの方法で接続するマルチモーダル モデルです。 CLIP の正式名は Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training) で、対照的なテキストと画像のペアに基づく事前トレーニング方法です。なぜCLIPを導入するのか?なぜなら、現在人気のStableDiffusionは単一のモデルではなく、複数のモデルで構成されているからです。重要なコンポーネントの 1 つはテキスト エンコーダで、ユーザーのテキスト入力をエンコードするために使用されます。このテキスト エンコーダは、CLIP モデルのテキスト エンコーダ CL です。
 フーリエ知能万能ヒューマノイドロボット「GR-1」の予約販売が始まります!
Sep 27, 2023 pm 08:41 PM
フーリエ知能万能ヒューマノイドロボット「GR-1」の予約販売が始まります!
Sep 27, 2023 pm 08:41 PM
この人型ロボットは身長 1.65 メートル、体重 55 キログラム、体に 44 の自由度があり、素早く歩き、障害物を素早く回避し、斜面を着実に上り下りし、衝撃干渉に耐えることができます。フーリエインテリジェンスの汎用人型ロボット GR-1 の予約販売が開始されました ロボット講堂 フーリエインテリジェンスの汎用人型ロボット フーリエ GR-1 の予約販売が開始されました。 GR-1 は、高度にバイオニックな体幹構成と擬人化された動作制御を備えており、全身 44 度の自由度を持ち、歩行、障害物を回避、障害物を横切り、坂道を上り下りし、干渉に耐え、さまざまな道路に適応する能力を備えています。一般的な人工知能システムであり、理想的なキャリアです。公式ウェブサイトの先行販売ページ: www.fftai.cn/order#FourierGR-1# フーリエ知能を書き直す必要があります。
 歩行者軌跡予測に有効な手法と一般的なBase手法は何ですか?トップカンファレンスの論文を共有!
Oct 17, 2023 am 11:13 AM
歩行者軌跡予測に有効な手法と一般的なBase手法は何ですか?トップカンファレンスの論文を共有!
Oct 17, 2023 am 11:13 AM
軌道予測はここ 2 年間で注目を集めていますが、そのほとんどは車両の軌道予測の方向に焦点を当てています。本日、自動運転ハートは、歩行者軌道予測のアルゴリズムを NeurIPS - SHENet で共有します。制限されたシーンでは、人間の行動パターンは通常、ある程度、限られたルールに従っています。この仮定に基づいて、SHENet は暗黙のシーン ルールを学習することで人の将来の軌道を予測します。この記事は自動運転ハート様よりオリジナル記事として認定されました!著者の個人的な理解では、人間の動きにはランダム性と主観性があるため、現時点では人の将来の軌道を予測することは依然として困難な問題です。ただし、制約のあるシーンでの人間の動きのパターンは、シーンの制約 (フロア プラン、道路、障害物など) や人間対人間、または人間対オブジェクトの対話性によって異なることがよくあります。
