

大きなモデルは小さなモデルに正確にフィードバックし、知識の蒸留は AI アルゴリズムのパフォーマンスの向上に役立ちます。

01 知識蒸留誕生の背景
それ以来、ディープ ニューラル ネットワーク (DNN) は産業界と学術界の両方で、特に コンピューター ビジョン タスク で大きな成功を収めてきました。深層学習の成功は主に、数十億のパラメータを使用してデータをエンコードするためのスケーラブルなアーキテクチャによるものです。そのトレーニングの目標は、既存のトレーニング データセットで入力と出力の間の関係をモデル化することです。パフォーマンスはネットワークの複雑さに大きく依存し、ラベル付きトレーニング データの量と質。
コンピューター ビジョンの分野における従来のアルゴリズムと比較して、ほとんどの DNN ベースのモデルは、過剰なパラメーター化により、強力な 一般化機能を備えています。モデルへの影響は、トレーニング データ、テスト データ、問題に属する未知のデータなど、特定の問題に入力されるすべてのデータに対してモデルがより良い予測結果を与えることができるという事実に反映されています。
現在の深層学習の状況では、ビジネス アルゴリズムの予測効果を向上させるために、アルゴリズム エンジニアは 2 つの解決策を用意していることがよくあります:
パラメータ化されたより複雑なネットワークを使用します。能力は非常に強力ですが、訓練に多くのコンピューティングリソースを必要とし、推論速度が遅いです。
統合モデルは、通常、パラメーターの統合と結果の統合を含む、効果の弱い多くのモデルを統合します。
これら 2 つのソリューションは既存のアルゴリズムの効果を大幅に向上させることができますが、どちらもモデルの規模が増大し、計算負荷が増大し、大規模なコンピューティング リソースとストレージ リソースが必要になります。
仕事において、さまざまなアルゴリズム モデルの最終的な目的は、特定のアプリケーションに役立つことです。売買と同じように、収入と支出をコントロールする必要があります。産業用アプリケーションでは、モデルが適切な予測を行う必要があることに加えて、コンピューティング リソースの使用も厳密に制御する必要があり、効率を考慮せずに結果だけを考慮することはできません。入力データのエンコード量が多いコンピュータ ビジョンの分野では、コンピューティング リソースはさらに限られており、制御アルゴリズムのリソース占有がさらに重要になります。
一般に、モデルが大きいほど予測結果は向上しますが、トレーニング時間が長く推論速度が遅いため、モデルをリアルタイムでデプロイすることが困難になります。特に、ビデオ監視、自動運転車、高スループットのクラウド環境など、コンピューティング リソースが限られているデバイスでは、応答速度が明らかに十分ではありません。小さいモデルは推論速度が速くなりますが、パラメーターが不十分であるため、推論効果と汎化パフォーマンスがそれほど良くない可能性があります。大規模モデルと小規模モデルをどのように比較するかは常にホットなトピックであり、現在のソリューションのほとんどは、展開環境の端末デバイスのパフォーマンスに基づいて適切なサイズの DNN モデルを 選択することです。
高速な推論速度を維持しながら、大規模なモデルと同じまたはそれに近い効果を達成できる小規模なモデルを作成したい場合、どうすればよいでしょうか?
機械学習では、入力と出力の間に潜在的なマッピング関数の関係があると仮定することがよくありますが、新しいモデルを最初から学習することは、入力データと対応するラベルの間にほぼ未知のマッピング関数があることを前提としています。入力データが変更されないという前提では、小さなモデルを最初からトレーニングすることは、経験的な観点から大規模なモデルの効果に近づくことが困難です。小規模モデル アルゴリズムのパフォーマンスを向上させるために、一般的に最も効果的な方法は、より多くの入力データにラベルを付けること、つまりより多くの監視情報を提供することです。これにより、学習されたマッピング関数がより堅牢になり、パフォーマンスが向上します。 2 つの例を挙げると、コンピューター ビジョンの分野では、インスタンス セグメンテーション タスクは追加のマスク情報を提供することでターゲット バウンディング ボックス検出の効果を向上させることができ、転移学習タスクはより大規模な事前トレーニング済みモデルを提供することで新しいタスクを大幅に改善できます。データセットの予測効果。したがって、より多くの監視情報を提供するが、小規模モデルと大規模モデルの間のギャップを縮める鍵となる可能性があります。
前の記述によると、より多くの監視情報を取得するには、より多くのトレーニング データにラベルを付ける必要があり、多くの場合、莫大なコストが必要になります。では、監視情報を取得する低コストで効率的な方法はありますか? 2006 年の記事 [1] は、新しいモデルを元のモデルに近似するように作成できることを指摘しました (モデルは関数です)。元のモデルの機能は既知であるため、新しいモデルをトレーニングするときにより多くの監視情報が自然に追加され、これは明らかにより実現可能です。
さらに考えると、元のモデルによってもたらされる監視情報には、さまざまな次元の知識が含まれている可能性があります。これらの固有の情報は、新しいモデル自体では捕捉できない可能性があります。これは、ある程度、新しいモデルにとって重要です。モデルも一種の「クロスドメイン」学習です。
2015 年、ヒントンは論文「ニューラル ネットワークでの知識の蒸留」[2] の近似の考え方に従い、「知識の蒸留 (知識の蒸留)」という概念を提案する主導権を握りました。 、KD)」: まずトレーニングできます。大規模で強力なモデルを構築し、次にそのモデルに含まれる知識を小さなモデルに転送することで、「小規模モデルの高速推論速度を維持しながら、同等またはそれに近い効果を達成する」という目的を達成できます。大型モデル並みの性能を実現します。最初にトレーニングされる大きなモデルを教師モデル、後でトレーニングされる小さなモデルを生徒モデルと呼び、トレーニング プロセス全体を「教師と生徒の学習」に例えることができます。その後数年間で、大量の知識の蒸留と教師と生徒による学習作業が生まれ、業界にさらに新しいソリューションが提供されました。現在、KD は、モデル圧縮と知識伝達という 2 つの異なる分野で広く使用されています [3]。

02 知識の蒸留
はじめに
知識の蒸留は、「教師-学生 「ネットワーク」の考え方に基づいたモデル圧縮手法は、そのシンプルさと有効性から業界で広く使用されています。その目的は、トレーニングされた大規模モデル - Distill (蒸留) - に含まれる知識を別の小さなモデルに抽出することです。では、大規模モデルの知識や一般化能力を小規模モデルに移すにはどうすればよいでしょうか? KD 論文では、大規模モデルのサンプル出力の確率ベクトルをソフト ターゲットとして小規模モデルに提供することで、小規模モデルの出力がこのソフト ターゲットにできるだけ近づくようにしています (本来はワンホットです)エンコーディング)を使用して、大規模なモデルの学習、モデルの動作を近似します。
従来のハードラベルトレーニングプロセスでは、すべてのネガティブラベルが均一に扱われますが、この方法ではカテゴリ間の関係が分離されます。たとえば、手書きの数字を認識したい場合、「3」と同じラベルが付いたいくつかの絵は「8」に似ている場合もあれば、「2」に似ている絵もあります。ハードラベルではこの情報を区別できませんが、よく訓練された大きなモデルが出すことができます。大規模モデルのソフトマックス層の出力には、正の例に加えて、負のラベルにも多くの情報が含まれています。たとえば、一部の負のラベルに対応する確率は、他の負のラベルよりもはるかに大きくなります。近似学習の動作により、各サンプルは従来のトレーニング方法よりも多くの情報を学生ネットワークにもたらすことができます。
したがって、作成者はスチューデント ネットワークをトレーニングするときに損失関数を変更し、トレーニング データのグラウンド トゥルース ラベルをフィッティングしながら、小さなモデルが大規模モデルの出力の確率分布にフィットできるようにしました。この方法は知識蒸留トレーニング、KDトレーニングと呼ばれます。知識の蒸留プロセスで使用されるトレーニング サンプルは、大規模モデルのトレーニングに使用されるサンプルと同じである場合もあれば、独立した転送セットが見つかる場合もあります。
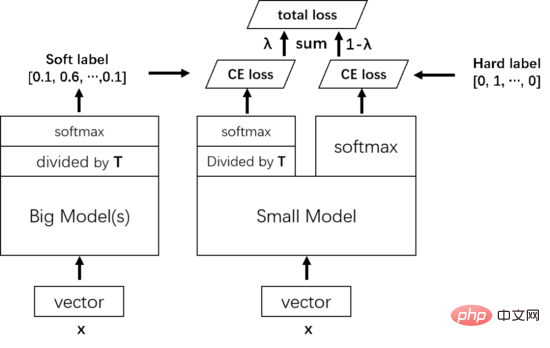 方法の詳細な説明
方法の詳細な説明
具体的には、教師-生徒モデルを使用して知識を蒸留します。教師は「知識」の出力者であり、生徒は「知識」の受け手です。知識の。知識蒸留のプロセスは 2 つの段階に分かれています:
- 教師モデルのトレーニング:
- トレーニング Net-T と呼ばれる「教師モデル」は、比較的複雑なモデルによって特徴付けられます。個別にトレーニングされた複数のモデルを統合できます。モデルを展開する必要がないため、モデル アーキテクチャ、パラメータの数、および「教師モデル」を統合するかどうかに制限はありません。唯一の要件は、入力 X に対して Y を出力できることです。ここで、Y はSoftmax によってマッピングされ、出力の値は、対応するカテゴリの確率値に対応します。 スチューデント モデルのトレーニング:
- トレーニング Net-S と呼ばれる「スチューデント モデル」は、少数のパラメーターと比較的単純なモデル構造を持つ単一のモデルです。同様に、入力 X に対して Y を出力することができ、Y はソフトマックス マッピング後の対応するカテゴリに対応する確率値を出力することもできます。 ソフトマックスを使用したネットワークの結果は、特定のクラスの信頼度が非常に高く、他のクラスの信頼度が非常に低いという極端な結果になりやすいためです。学生モデルが注目する肯定的なクラス情報 おそらく、それはまだ特定のカテゴリにのみ属している可能性があります。さらに、さまざまなカテゴリーのネガティブな情報にも相対的な重要性があるため、すべてのネガティブなスコアが類似することは好ましくなく、知識の蒸留の目的を達成できません。この問題を解決するために、温度 (Temperature) の概念が導入され、小さな確率値によってもたらされる情報を抽出するために高温が使用されます。具体的には、ソフトマックス関数を通過する前に、ロジットを温度 T で割ります。
トレーニング中、教師モデルによって学習された知識は、まず小さなモデルに抽出されます。具体的には、サンプル X については、まず大きなモデルの最後から 2 番目の層が温度 T で除算され、次にソフト ターゲットが予測されます。モデルについても同じことが言えます。最後から 2 番目の層は同じ温度 T で除算され、ソフトマックスを通じて結果を予測し、この結果とソフト ターゲットのクロス エントロピーをトレーニングの総損失の一部として使用します。次に、小規模モデルの正規出力と真の値ラベル (ハード ターゲット) のクロス エントロピーが、トレーニングの総損失の別の部分として使用されます。合計損失は、小規模モデルをトレーニングするための最終損失として 2 つの損失を合わせて重み付けします。
小規模モデルがトレーニングされ、予測する必要がある場合、温度 T は必要なくなり、従来のソフトマックスに従って直接出力できます。
03 FitNet
はじめに
FitNet の論文では、学生モデルのトレーニングをガイドするための、蒸留中の中間レベルのヒントが紹介されています。広くて浅い教師モデルを使用して、狭くて深い生徒モデルをトレーニングします。ヒント ガイダンスを実行する場合、ヒント レイヤーとガイド付きレイヤーの出力形状を一致させるレイヤーを使用することが提案されており、これは将来の世代の研究ではアダプテーション レイヤーと呼ばれることがよくあります。
一般に、知識の蒸留を行う際に、教師モデルのロジット出力だけでなく、教師モデルの中間層の特徴マップも教師情報として使用することに相当します。想像できるのは、小さなモデルが出力端で大きなモデルを直接模倣するのは非常に困難であるということです (モデルが深くなるほど、トレーニングが難しくなり、監視信号の最後の層を送信するのは非常に面倒です)モデルがトレーニング中に最も難しいマッピング関数を直接学習するのではなく、より難しいマッピング関数を層ごとに学習できるように、途中にいくつかの監視信号を追加する方が良いです。さらに、ヒント ガイダンスにより収束が加速されます。非凸問題でより適切な局所最小値を見つけると、生徒のネットワークがより深くなり、より速くトレーニングできるようになります。大学の入試問題をやらせるのが目的のような気がするので、まずは中学校の問題を教えます(まず小さいモデルにモデルの前半を使って画像の根底にある特徴を抽出する方法を学習させます)。そして、本来の目的である大学入試問題の学習に戻ります(KDを使用して小型モデルのすべてのパラメータを調整します)。
この記事は、提案された蒸留中間特徴マップの祖先であり、提案されたアルゴリズムは非常に単純ですが、アイデアは画期的です。
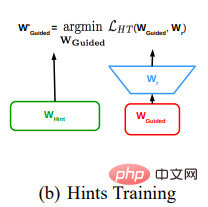
方法の詳細な説明
FitNets の具体的な方法は次のとおりです:
- 教師ネットワークを決定する 成熟してトレーニングし、教師ネットワークの中間特徴層からヒントを抽出します。
- 生徒のネットワークを設定します。このネットワークは通常、教師のネットワークより狭くて深いです。学生ネットワークは、学生ネットワークの中間特徴層が教師モデルのヒントと一致するようにトレーニングされます。生徒ネットワークの中間特徴層と教師のヒント サイズが異なるため、特徴の次元を強化してヒント層のサイズと一致させるために、生徒ネットワークの中間特徴層の後にリグレッサーを追加する必要があります。教師ネットワークのヒント層とリグレッサーによって変換された生徒ネットワークの中間特徴層と一致する損失関数は、平均二乗誤差損失関数です。
実際のトレーニングでは、前セクションの KD トレーニングと組み合わせて使用されることが多く、トレーニングには 2 段階の方法が使用されます。まずヒント トレーニングを使用して前半のパラメーターを事前トレーニングします。小さなモデルを作成し、KD トレーニングを使用してパラメーター全体をトレーニングします。蒸留プロセスではより多くの監視情報が使用されるため、中間特徴マップに基づく蒸留方法は、結果ロジットに基づく蒸留方法よりもパフォーマンスが高くなりますが、トレーニング時間は長くなります。
04 概要
知識の蒸留は、アンサンブルまたは高度に正規化された大規模モデルから小規模なモデルに知識を移すのに非常に効果的です。蒸留モデルのトレーニングに使用される移行データセットに 1 つ以上のクラスのデータが欠落している場合でも、蒸留は非常にうまく機能します。古典的な KD と FitNet が提案された後、さまざまな蒸留方法が登場しました。将来的には、モデル圧縮と知識伝達の分野でもさらに探求していきたいと考えています。
著者について
Ma Jialiang は、NetEase Yidun のシニア コンピュータ ビジョン アルゴリズム エンジニアであり、主にコンテンツ分野におけるコンピュータ ビジョン アルゴリズムの研究、開発、最適化、革新を担当しています。安全。
以上が大きなモデルは小さなモデルに正確にフィードバックし、知識の蒸留は AI アルゴリズムのパフォーマンスの向上に役立ちます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7700
7700
 15
1640
14
1393
52
1287
25
1230
29
15
1640
14
1393
52
1287
25
1230
29

 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 「ブラックマンデーセル」は、暗号通貨業界にとって厳しい日です
Apr 21, 2025 pm 02:48 PM
「ブラックマンデーセル」は、暗号通貨業界にとって厳しい日です
Apr 21, 2025 pm 02:48 PM
暗号通貨市場での突入は投資家の間でパニックを引き起こし、Dogecoin(Doge)は最も困難なヒット分野の1つになりました。その価格は急激に下落し、分散財務財務(DEFI)(TVL)の総価値が激しく減少しました。 「ブラックマンデー」の販売波が暗号通貨市場を席巻し、ドゲコインが最初にヒットしました。そのdefitVLは2023レベルに低下し、通貨価格は過去1か月で23.78%下落しました。 DogecoinのDefitVLは、主にSOSO値指数が26.37%減少したため、272万ドルの安値に低下しました。退屈なDAOやThorchainなどの他の主要なDefiプラットフォームも、それぞれ24.04%と20減少しました。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
2025年のレバレッジド取引、セキュリティ、ユーザーエクスペリエンスで優れたパフォーマンスを持つプラットフォームは次のとおりです。1。OKX、高周波トレーダーに適しており、最大100倍のレバレッジを提供します。 2。世界中の多通貨トレーダーに適したバイナンス、125倍の高いレバレッジを提供します。 3。Gate.io、プロのデリバティブプレーヤーに適し、100倍のレバレッジを提供します。 4。ビットゲットは、初心者やソーシャルトレーダーに適しており、最大100倍のレバレッジを提供します。 5。Kraken、安定した投資家に適しており、5倍のレバレッジを提供します。 6。Altcoinエクスプローラーに適したBybit。20倍のレバレッジを提供します。 7。低コストのトレーダーに適したKucoinは、10倍のレバレッジを提供します。 8。ビットフィネックス、シニアプレイに適しています
 Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Binanceは、グローバルデジタルアセット取引エコシステムの大君主であり、その特性には次のものが含まれます。1。1日の平均取引量は1,500億ドルを超え、500の取引ペアをサポートし、主流の通貨の98%をカバーしています。 2。イノベーションマトリックスは、デリバティブ市場、Web3レイアウト、教育システムをカバーしています。 3.技術的な利点は、1秒あたり140万のトランザクションのピーク処理量を伴うミリ秒のマッチングエンジンです。 4.コンプライアンスの進捗状況は、15か国のライセンスを保持し、ヨーロッパと米国で準拠した事業体を確立します。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
