

VAE から拡散モデルへ: テキストを使用して図を生成する新しいパラダイムを説明する記事

1 はじめに
DALL・E のリリースから 15 か月後、OpenAI はこの春、続編の DALL・E 2 を発表し、より素晴らしいエフェクトと豊かなプレイアビリティですぐに市場を占領しました。コミュニティ。近年、敵対的生成ネットワーク (GAN)、変分オートエンコーダー (VAE)、拡散モデルの出現により、深層学習はその強力な画像生成機能を世界に実証しており、GPT-3 や BERT とともにその成功が待たれています。 NLP モデルにより、人間はテキストと画像の間の情報の境界を徐々に打ち破っています。
DALL・E 2では、簡単なテキスト(プロンプト)を入力するだけで、1024*1024の高解像度画像を複数生成できます。これらの画像は、型破りなセマンティクスを表現して、図 1 の「写実的なスタイルで馬に乗る宇宙飛行士」など、超現実的な形式で想像力豊かな視覚効果を作成することもできます。
 図 1. DALL・E 2 世代の例
図 1. DALL・E 2 世代の例
この記事では、DALL・E などの新しいパラダイムがテキストを通じてどのように多くの素晴らしい画像を作成できるかについて詳しく説明します。この記事では多くの背景知識を取り上げており、基本的なテクノロジの紹介は、画像生成の分野に初めて携わる読者にも適しています。
2 画像生成
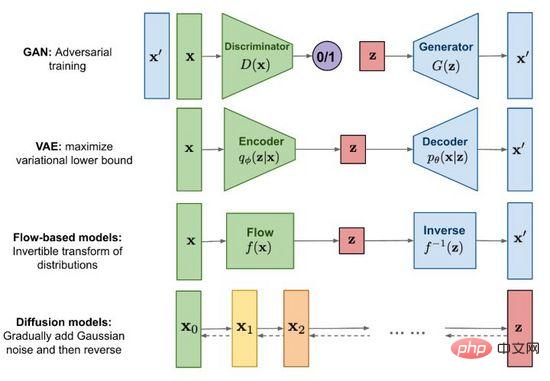
図 2. 主流の画像生成方法
2014 年に敵対的生成ネットワーク (GAN) が誕生して以来、画像 生成研究はディープラーニング、さらには人工知能の分野全体においても重要なフロンティアトピックとなっており、技術開発は現段階で偽物と本物が混同されるレベルに達しています。よく知られている敵対的生成ネットワーク (GAN) に加えて、主流の手法には、変分オートエンコーダー (VAE) やフローベース モデル (フローベース モデル)、さらには最近注目を集めている拡散モデル (拡散モデル) も含まれます。 。図 2 を使用して、各方法の特徴と違いを調べます。
2.1 敵対的生成ネットワーク (GAN)
GAN の正式名は G enerative A dversarial N etworks の名前から、「Adversarial」がその成功の本質であることを読み取るのは難しくありません。対決のアイデアはゲーム理論からインスピレーションを得ており、生成器 (Generator) を学習させると同時に、入力が実画像であるか生成された画像であるかを判断する識別子 (Discriminator) を学習させ、両者が互いに競い合います。ミニマックスゲームをすると強くなる、式(1)のような。ランダムノイズから「騙す」のに十分な画像が生成される場合、実際の画像のデータ分布はよく適合していると考えられ、サンプリングにより多数のリアルな画像を生成できると考えられます。
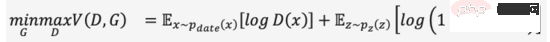
GAN は、生成モデルで最も広く使用されているテクノロジーであり、画像、ビデオ、音声、NLP などの多くのデータ合成シナリオで威力を発揮します。ランダム ノイズから直接コンテンツを生成することに加えて、ジェネレーターとディスクリミネーターへの入力として条件 (分類ラベルなど) を追加することもできます。これにより、生成された結果が条件付き入力の属性に準拠し、生成されたコンテンツを制御できるようになります。 。 GANは優れた効果を持っていますが、ゲームメカニズムの存在により学習の安定性が悪くモード崩壊を起こしやすく、モデルをいかにスムーズにゲーム平衡点に到達させるかがGANにおける注目の研究テーマとなっています。
2.2 変分オートエンコーダ (VAE)
変分オートエンコーダ (変分オートエンコーダ) は、オートエンコーダの変種です。従来のオートエンコーダは、教師なしで動作するように設計されています。ニューラル ネットワークをトレーニングする方法元の入力を中間表現に圧縮して復元するというもので、前者は元の高次元入力をエンコーダ(Encoder)を通して低次元の隠れ層符号化に変換し、後者はデコーダ(Decoder)を通過するという2つの処理に分けて行われます。 ).) エンコーディングからデータを再構築します。オートエンコーダの目標が恒等関数を学習することであることは理解できます。クロスエントロピー (クロスエントロピー) または平均二乗誤差 (平均二乗誤差) を使用して再構成損失を構築し、エンコーダ間の差を定量化できます。入力と出力。図 3 に示すように、上記のプロセス中に、元のデータの潜在的な属性をキャプチャし、データ圧縮や特徴表現に使用できる低次元の隠れ層エンコードが取得されます。
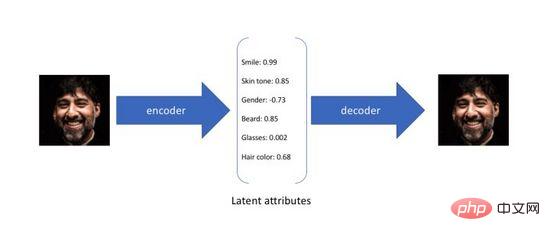
図 3. オートエンコーダーの潜在属性エンコーディング
オートエンコーダーは隠れ層エンコーディングの再構築能力のみに焦点を当てているため、その隠れ層の空間分布は多くの場合、コードのセットを取得するために連続隠れ層空間でランダム サンプリングまたは補間を行うと、通常は無意味で解釈できない生成結果が生成されます。通常の隠れ層空間を構築して、さまざまな潜在的な属性をランダムにサンプリングしてスムーズに補間し、最終的にデコーダーを通じて意味のある画像を生成できるようにするために、研究者らは 2014 年に変分オートエンコーダーを提案しました。
変分オートエンコーダは、入力を隠れ層空間の固定エンコーディングにマッピングしなくなりましたが、それを隠れ層空間の確率分布推定に変換します。表現の便宜上、事前分布は標準ガウス分布であると仮定します。分布。同様に、隠れ層の空間分布から実際のデータ分布にマッピングするために確率的デコーダ モデルをトレーニングします。入力が与えられると、事後分布を通じて分布のパラメータ (多変量ガウス モデルの平均と共分散) を推定し、この分布からサンプリングします。再パラメータ化手法を使用して、サンプリングを (確率変数として) 微分可能にすることができます。 、そして最後に、図 4 に示すように、確率デコーダを通じて約の分布が出力されます。生成された画像をできるだけ現実的にするには、実際の画像の対数尤度を最大化することを目的として事後分布を解く必要があります。
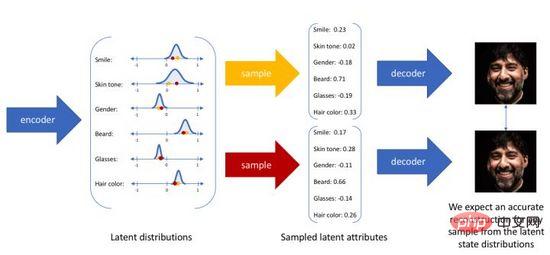
図 4. 変分オートエンコーダのサンプリング生成プロセス
残念ながら、ベイジアン モデルによる真の事後分布には連続空間上の積分が含まれており、直接解くことはできません。 。上記の問題を解決するために、変分オートエンコーダは変分推論法を使用し、学習可能な確率エンコーダを導入して実際の事後分布を近似し、KL 発散を使用して 2 つの分布の差を測定し、真の事後分布からこの問題を解決します。これは、2 つの分布間の距離を縮める方法に変換されます。
KL 発散は負ではないので、中間の導出プロセスを省略し、上記の方程式を拡張して式 (2) を取得します。最大値を変換する 目的は式 (3) に変換されます。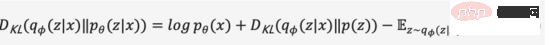
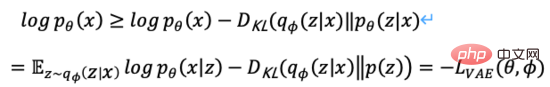 2.3 フローベースのモデル
2.3 フローベースのモデル
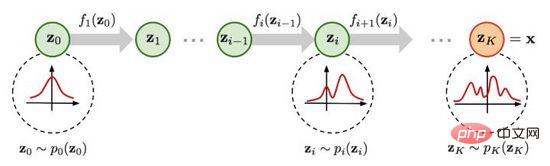 図 5 に示すように、元のデータ分布は、一連の可逆変換関数を通じて既知の分布から取得できます。ヤコブ行列の行列式と変数変更ルールを通じて、実データの確率密度関数 (式 (4)) を直接推定し、計算可能な対数尤度を最大化することができます。
図 5 に示すように、元のデータ分布は、一連の可逆変換関数を通じて既知の分布から取得できます。ヤコブ行列の行列式と変数変更ルールを通じて、実データの確率密度関数 (式 (4)) を直接推定し、計算可能な対数尤度を最大化することができます。
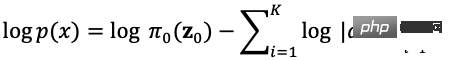
 2.4 拡散モデル
2.4 拡散モデル
 拡散モデルは順方向を定義します。前方処理と拡散処理の 2 つの処理があり、実際のデータ分布からサンプリングし、ガウス ノイズをサンプルに徐々に追加してノイズ サンプル列を生成します。ノイズの追加処理は分散パラメータによって制御できます。 、ガウス分布とほぼ同等になります。拡散処理はあらかじめ設定された制御可能な処理であり、ノイズ付加処理は条件付き分布により式(5)のように表すことができます。任意のステップ サイズでのサンプリングに上記の式を使用すると、
拡散モデルは順方向を定義します。前方処理と拡散処理の 2 つの処理があり、実際のデータ分布からサンプリングし、ガウス ノイズをサンプルに徐々に追加してノイズ サンプル列を生成します。ノイズの追加処理は分散パラメータによって制御できます。 、ガウス分布とほぼ同等になります。拡散処理はあらかじめ設定された制御可能な処理であり、ノイズ付加処理は条件付き分布により式(5)のように表すことができます。任意のステップ サイズでのサンプリングに上記の式を使用すると、
拡散モデルの最適化目標には多くの選択肢があります。たとえば、トレーニング プロセス中、フォワード プロセスから直接計算できるため、予測されたモデルからサンプリングできます。画像分類とテキストラベルを条件入力として使用し、平均二乗誤差を最小にして再構成損失を最適化するオートエンコーダに相当する処理です。
デノイズ拡散確率モデルDDPMでは、再パラメータ化技術によりノイズ予測モデル損失の簡易版(式(8))を構築し、ステップサイズでノイズを含むデータを入力した  ノイズを予測するようにモデルをトレーニングします
ノイズを予測するようにモデルをトレーニングします  、
、
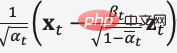
を使用します推論プロセス中に、顔画像のノイズ除去を実現するために、ノイズ除去されたデータのガウス分布平均を予測します。 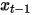 3 マルチモーダル表現学習
3 マルチモーダル表現学習
3.1 Transformer の NLP
図 7. BERT GPT
BERT と GPT は、近年の NLP 分野における非常に強力な事前トレーニング済み言語モデルであり、記事生成、コード生成、機械翻訳、Q&A などの下流タスクで大きな進歩を遂げました。 。どちらもアルゴリズムの主要なフレームワークとして Transformer を使用しており、実装の詳細は若干異なります (図 7)。 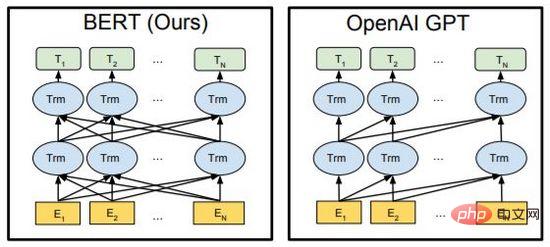
図 8. ViT
現在、Transformer は画像処理分野の新しい研究対象となっており、その強力な可能性で常に CNN の地位に挑戦しています。 。 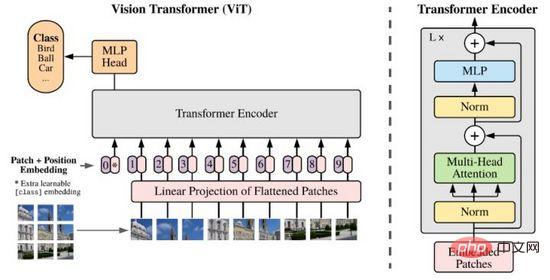
図 9. クリップ
CLIPは、テキストと画像の特徴表現を同一空間にマッピングするもので、クロスモーダルな情報伝達は実現しませんが、特徴圧縮、類似度測定、クロスモーダル表現学習の手法として非常に有効です。直感的には、特に画像とラベルのデータ分布が確立されていない場合、ラベル範囲で生成されたすべてのテキスト プロンプトの中で最も類似した特徴を持つ画像トークンを出力します。つまり、画像分類が完了します (図 9 (2))。トレーニング セット 以前にも登場しましたが、CLIP にはゼロショット学習の機能がまだあります。
4 クロスモーダル画像生成
これまでの 2 章で紹介した後、画像生成とマルチモーダル表現学習に関連する基礎技術を体系的に確認しました。 3 つの最新のクロスモーダル画像生成方法を紹介し、これらの基礎となる技術を使用してモデル化する方法を説明します。
4.1 DALL·E
DALL·E は、2021 年初頭に OpenAI によって提案され、入力テキストから出力画像まで自己回帰デコーダーをトレーニングすることを目的としています。 CLIP の成功した経験から、テキストの特徴と画像の特徴は同じ特徴空間でエンコードできることがわかっているため、Transformer を使用してテキストと画像の特徴を単一のデータ ストリームとして自己回帰的にモデル化できます (「テキストと画像を自己回帰的にモデル化する)」単一のデータ ストリームとしてのトークン")。データのストリーム")。
DALL·E のトレーニング プロセスは 2 つの段階に分かれています。最初は、画像のエンコードとデコード用に変分自動エンコーダーをトレーニングすることです。2 つ目は、テキストと画像の自己回帰デコーダーをトレーニングして、画像のトークンを予測することです。図 10 に示すように、生成された画像。
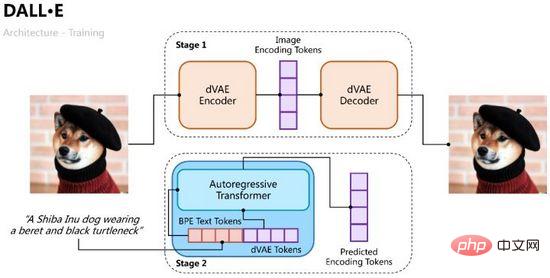
図 10. DALL·E のトレーニング プロセス
推論プロセスはより直感的であり、自己回帰トランスフォーマーを使用して、テキスト トークンを画像トークンに徐々にデコードします。このプロセスでは、図 11 に示すように、分類確率を通じて複数のサンプル グループをサンプリングし、複数のサンプル トークン グループを変分自動エンコーディングに入力して、生成された複数の画像をデコードし、CLIP 類似度計算を通じて最良のものを並べ替えて選択できます。
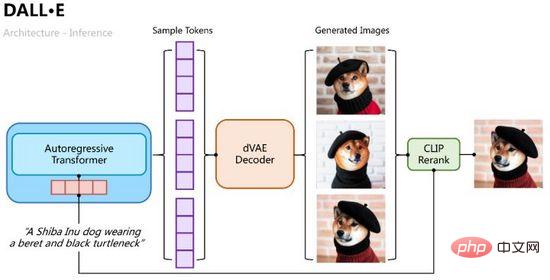
図 11. DALL・E の推論プロセス
VAE と同様に、確率的エンコーダーと確率的デコーダーを使用してそれぞれ隠れ層の特徴をモデル化します。生成された画像の事後確率分布と尤度確率分布は、Transformer によってアプリオリに予測されたテキストと画像の同時確率分布を使用してモデル化されます (最初の段階で一様分布に初期化されます)。 ,
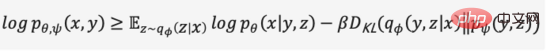
トレーニングの最初の段階では、DALL・E は dVAE と呼ばれる離散変分オートエンコーダー (離散 VAE) を使用しました。ベクトル量子化 VAE (VQ -VAE) のアップグレード バージョンです。 VAE では、確率分布を使用して連続隠れ層空間を記述し、ランダム サンプリングを通じて隠れ層コードを取得しますが、このコードは離散言語文字ほど決定論的ではありません。画像の隠れ層空間の「言語」を学習するために、VQ-VAE は学習可能なベクトル量子化のセットを使用して隠れ層空間を表現します。この定量化された隠れ層空間は、埋め込み空間またはコードブック/語彙と呼ばれます。 VQ-VAE のトレーニング プロセスと予測プロセスは、画像エンコード ベクトルに最も近い隠れ層ベクトルを見つけて、マッピングされたベクトル言語を画像にデコードすることを目的としています (図 12)。損失関数は 3 つの部分で構成され、それぞれ最適化されます。再構成損失、埋め込みスペースの更新、エンコーダーの更新が行われ、勾配が終了します。
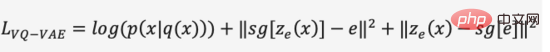
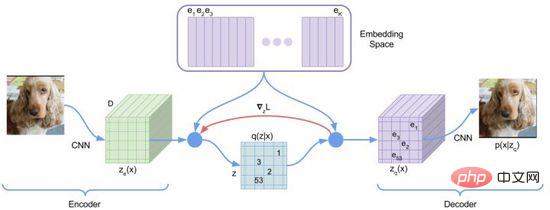
図 12. VQ-VAE
VQ-VAE には、最近傍選択の仮定により、一定の事後確率があります。最も近い距離 隠れ層ベクトルの確率は 1 で残りは 0 であり、これはランダムではありません。最も近いベクトルの選択プロセスは微分可能ではなく、直線推定法を使用して勾配を に渡します。
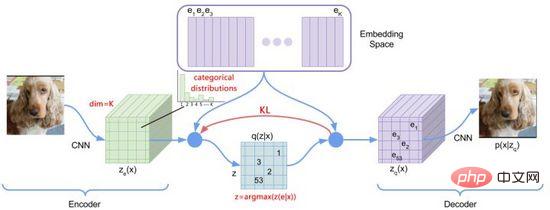
図 13. dVAE
上記の問題を最適化するために、DALL・E は Gumbel-Softmax を使用して新しい dVAE を構築しました (図 13)。出力は、埋め込み空間上の 32*32 K=8192 次元の分類確率になります。トレーニング プロセス中に、分類確率のソフトマックス計算にノイズが追加されてランダム性が導入され、徐々に低下する温度が使用されます。確率分布近似ワンホット エンコーディング層ベクトルが選択され、微分可能になるように再パラメータ化され (式 (11))、推論プロセス中に最近傍が引き続き取得されます。
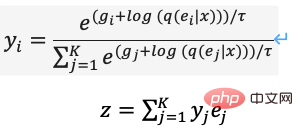
PyTorch 実装では、hard=True を設定して近似ワンホット エンコーディングを出力することができ、同時に y_hard = y_hard - y_soft.detach( ) y_soft 派生可能にしておきます。
トレーニングの最初の段階が完了したら、テキストと画像のペアごとに予測ターゲットの画像トークンを生成するように dVAE を修正できます。トレーニングの第 2 フェーズでは、DALL・E は BPE メソッドを使用して、最初にテキストを画像トークンと同じ次元 d=3968 のテキスト トークンにエンコードし、次にテキスト トークンと画像トークンを連結し、位置エンコーディングとパディング エンコーディングを追加しました。 、図 14 に示すように、Transformer Encoder を使用して自己回帰予測を実行します。計算速度を向上させるために、DALL・E は行、列、畳み込みという 3 つのスパース アテンション マスク メカニズムも使用します。
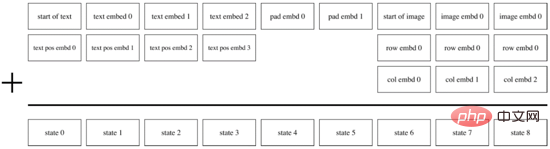
図 14. DALL・E の自己回帰デコーダ
上記の実装に基づいて、DALL・E は「実際の」画像を生成するだけでなく、統合することもできます図 15 に示すように、作成、シーンの理解、スタイルの変換につながります。さらに、ゼロサンプルや専門分野では DALL・E の効果が悪化する可能性があり、生成される画像の解像度 (256*256) が低くなります。

図 15. DALL・E のさまざまな生成シナリオ
4.2 DALL・E 2
画像生成品質をさらに向上させるにはテキスト画像特徴空間の解釈可能性を探るため、OpenAI は拡散モデルと CLIP を組み合わせて、2022 年 4 月に DALL・E 2 を提案しました。生成サイズが 1024*1024 に増加しただけでなく、補間演算を通じてテキストを視覚化しました。特徴空間の移行 - 画像特徴空間の移行プロセス。
図 16 に示すように、DALL・E 2 は、CLIP 比較学習によって得られたテキスト埋め込みと画像埋め込みをモデル入力および予測対象として使用し、具体的なプロセスは事前事前学習と対応する画像埋め込みの予測です。本文より、この記事では、自己回帰トランスフォーマーと拡散モデルの 2 つのトレーニング方法を使用しており、後者は各データセットでより優れたパフォーマンスを発揮し、その後、CLIP 画像エンコーダーの逆プロセスとみなすことができる拡散モデル デコーダー UnCLIP を学習します。取得した画像の埋め込みは制御を達成するための条件として追加され、テキストの埋め込みとテキストのコンテンツはオプションの条件として使用され、解像度を向上させるために、UnCLIP はまた、2 つのアップサンプリング デコーダ (CNN ネットワーク) を追加して、より大きな画像を逆生成します。サイズ画像。
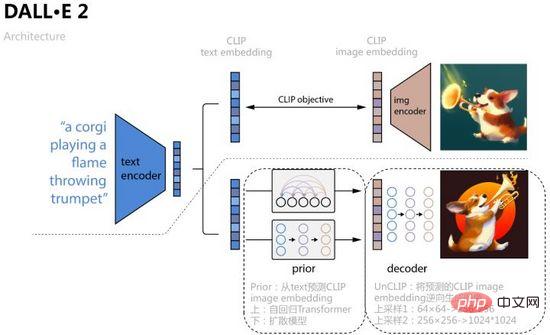
図 16. DALL・E 2
Prior の拡散モデルのトレーニングでは、DALL・E 2 は Transformer Decoder を使用して拡散プロセスを予測します。シーケンスは BPE エンコードされたテキスト テキスト埋め込みタイムステップ埋め込みです。現在のノイズ付き画像埋め込み、予測されたノイズ除去画像埋め込みは、MSE を使用して損失関数を構築します。
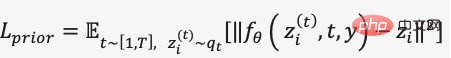
DALL·E 2 は次のとおりです。これにより、モデルが特定のテキスト ラベルに対して方向性のあるタイプの生成結果を生成することを回避し、特徴の豊富さを減らし、拡散モデルの予測条件に制限を追加し、分類子なしのガイダンスを保証します。例えば、PriorやUnCLIPの拡散モデル学習では、テキスト埋め込みの追加などの条件にドロップ確率が設定されているため、生成処理で依存条件の入力が完了しません。したがって、逆生成プロセスでは、基本的な特徴を維持したまま、画像埋め込みサンプリングを通じて同じ画像の異なるバリアントを生成することができ、画像埋め込みとテキスト埋め込みでそれぞれ補間することもでき、補間率を制御することで、次のようなスムーズな移行可視化結果を生成できます。図17に示されています。

図 17. DALL·E 2 によって実現可能な画像特徴の保存と移行
DALL·E 2 は、Prior および例えば、UnCLIP 検証実験は、1) UnCLIP 生成モデルにテキストコンテンツのみを入力する、2) UnCLIP 生成モデルにテキストコンテンツとテキスト埋め込みのみを入力する、3) 上記の方法に基づいて事前予測画像埋め込みを追加する 3 つの方法で検証します。 、3 つの方法 生成効果の段階的な改善により、Prior の有効性が検証されます。さらに、DALL・E 2 は PCA を使用して隠れ層空間の埋め込み次元を削減しますが、次元が削減されるにつれて、生成される画像の意味的特徴は徐々に弱まります。最後に、DALL・E 2 は MS-COCO データセットで他の方法と比較し、FID= 10.39 で最高の生成品質を達成しました (図 18)。
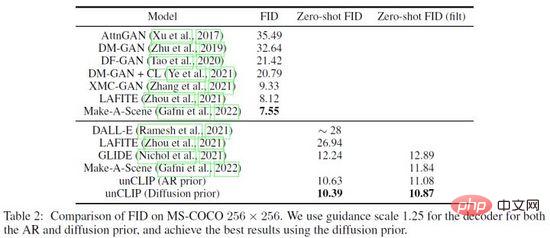
図 18. MS-COCO データセットでの DALL・E 2 の比較結果
4.3 ERNIE-VILG
ERNIE-VILG は Baidu です2022 年初頭に Wen Xin によって提案された中国シーンのテキストと画像の双方向生成モデル。
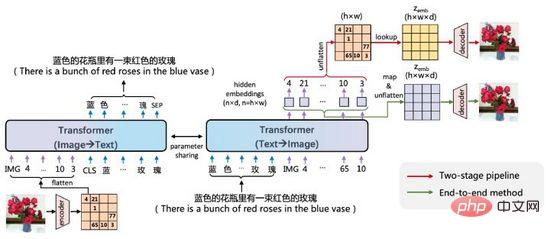
図 19. ERNIE-VILG
ERNIE-VILG のアイデアは DALL·E に似ており、事前トレーニングされた変分オートエンコーダーを通じて画像特徴をエンコードします。 . 、Transformer を使用してテキスト トークンと画像トークンを自己回帰的に予測します。主な違いは次のとおりです:
- ERNIE-VILG は Baidu Wenxin プラットフォーム テクノロジに依存しており、中国語のシーンを処理できます。テキストから画像への自動回帰プロセスは、画像からテキストへの方向プロセスもモデル化し、双方向プロセス パラメータが共有されます;
- テキストから画像への自動回帰プロセス中、画像からテキストへの自動回帰プロセスの間、マスク処理は行われません。テキスト トークン ;
- 画像のエンコードとデコードには VQ-VAE と VQ-GAN が使用され、画像のデコード プロセスは、map& flatten を介して自己回帰プロセスと接続され、エンドツーエンドのトレーニングを実現します。
- ERNIE-VILG のもう 1 つの強力な機能は、図 20 に示すように、中国のシーンにおける複数のオブジェクトと複雑な位置関係の生成を処理できることです。
 図 20. ERNIE-VILG 生成の例
図 20. ERNIE-VILG 生成の例
4. 概要
この記事では、最新のテキストベースのグラフ生成方法を解釈します。新しいパラダイムには、変分オートエンコーダや拡散モデルなどの生成手法、CLIP などのテキスト画像の潜在空間表現学習手法、離散化や再パラメータ化などのモデリング手法の適用が含まれます。
現在、テキストから画像への生成技術は敷居が高く、そのトレーニングコストは顔認識、機械翻訳、音声合成などのシングルモーダル手法のコストをはるかに超えています。たとえば、OpenAI は 2 億 5,000 万ペアのサンプルを収集して注釈を付け、1,024 台の V100 GPU を使用して 120 億のパラメーターを含むモデルをトレーニングしました。さらに、画像生成の分野では、人種差別、暴力的なポルノ、機密性の高いプライバシーなどの問題が常に存在します。 2020 年以降、ますます多くの AI チームがクロスモーダル生成の研究に投資しており、近い将来、現実世界と生成された世界の偽物と区別がつかなくなるかもしれません。
以上がVAE から拡散モデルへ: テキストを使用して図を生成する新しいパラダイムを説明する記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7548
7548
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 ソニーは、PS5 Proで特別なGPUを使用してAMDを使用してAIを開発する可能性を確認しています
Apr 13, 2025 pm 11:45 PM
ソニーは、PS5 Proで特別なGPUを使用してAMDを使用してAIを開発する可能性を確認しています
Apr 13, 2025 pm 11:45 PM
Sony InteractiveEntertainmentのチーフアーキテクト(SIE、Sony Interactive Entertainment)のMark Cernyは、パフォーマンスアップグレードAMDRDNA2.xアーキテクチャGPU、およびAMDとの機械学習/人工知能プログラムコードノームの「Amethylst」を含む、次世代ホストPlayStation5Pro(PS5PRO)のハードウェアの詳細をリリースしました。 PS5PROパフォーマンスの改善の焦点は、より強力なGPU、高度なレイトレース、AI搭載のPSSRスーパー解像度関数を含む3つの柱に依然としてあります。 GPUは、SonyがRDNA2.xと名付けたカスタマイズされたAMDRDNA2アーキテクチャを採用しており、RDNA3アーキテクチャがあります。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CENTOSでのZookeeperパフォーマンスチューニングは、ハードウェア構成、オペレーティングシステムの最適化、構成パラメーターの調整、監視、メンテナンスなど、複数の側面から開始できます。特定のチューニング方法を次に示します。SSDはハードウェア構成に推奨されます。ZookeeperのデータはDISKに書き込まれます。十分なメモリ:頻繁なディスクの読み取りと書き込みを避けるために、Zookeeperに十分なメモリリソースを割り当てます。マルチコアCPU:マルチコアCPUを使用して、Zookeeperが並行して処理できるようにします。
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 最後に変わった! Microsoft Windows検索機能は新しいアップデートの先導
Apr 13, 2025 pm 11:42 PM
最後に変わった! Microsoft Windows検索機能は新しいアップデートの先導
Apr 13, 2025 pm 11:42 PM
MicrosoftのWindows検索機能に対する改善は、EUのWindows Insiderチャネルでテストされています。以前は、統合されたWindows検索機能はユーザーによって批判されており、経験が不十分でした。この更新は、検索機能を2つの部分に分割します。ローカル検索とBingベースのWeb検索でユーザーエクスペリエンスを向上させます。検索インターフェイスの新しいバージョンは、デフォルトでローカルファイル検索を実行します。オンラインで検索する必要がある場合は、[Microsoft BingWebsearch]タブをクリックして切り替える必要があります。切り替え後、検索バーには「Microsoft BingWebsearch:」が表示され、ユーザーはキーワードを入力できます。この動きにより、ローカル検索結果とBing検索結果の混合が効果的に回避されます
