

ViP3D: 3D エージェント クエリによるエンドツーエンドの視覚的軌道予測

arXiv 論文「ViP3D: 3D Agent Queries によるエンドツーエンドの視覚軌跡予測」、22 年 8 月 2 日にアップロード、清華大学、上海 (八尾) 斉志研究所、CMU、復旦、李汽車、MIT など. 共同作業。

既存の自動運転パイプラインは、認識モジュールと予測モジュールを分離しています。 2 つのモジュールは、エージェント ボックスや軌跡などの手動で選択された機能をインターフェイスとして介して通信します。この分離により、予測モジュールは認識モジュールから部分的な情報のみを受け取ります。さらに悪いことに、認識モジュールからのエラーが伝播および蓄積し、予測結果に悪影響を与える可能性があります。
この研究では、元のビデオの豊富な情報を使用してシーン内のエージェントの将来の軌道を予測する視覚的な軌道予測パイプラインである ViP3D を提案します。 ViP3D はパイプライン全体でスパース エージェント クエリを使用するため、完全に微分可能で解釈可能になります。さらに、エンドツーエンドの視覚軌跡予測タスクに対して、知覚を総合的に考慮した新しい評価指標 End-to-end Prediction Accuracy (EPA、End-to-end Prediction Accuracy) が提案されています。同時に、予測された軌道と地上の真実の軌道がスコアリングされます。
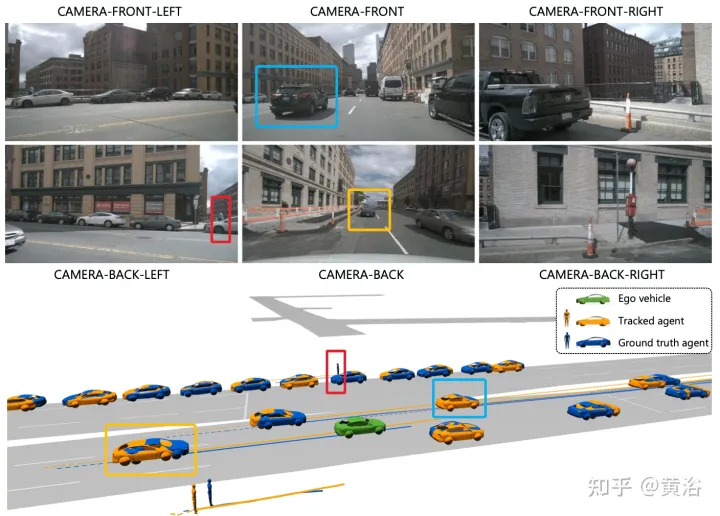
この図は、従来のマルチステップ カスケード パイプラインと ViP3D の比較を示しています。従来のパイプラインには、検出、追跡、予測などの複数の微分不可能なモジュールが含まれており、ViP3D はマルチビュー ビデオを入力として受け取ります。エンドツーエンド方式で車両の方向指示器などの視覚情報を効果的に活用した予測軌道を生成します。
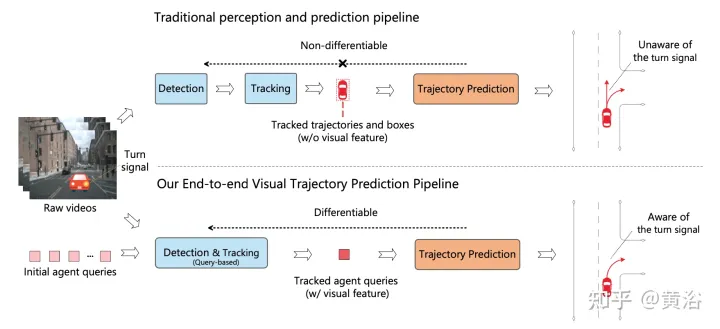
ViP3D は、元のビデオの軌跡予測の問題をエンドツーエンドで解決することを目的としています。具体的には、マルチビュー ビデオと高解像度マップが与えられると、ViP3D はシーン内のすべてのエージェントの将来の軌跡を予測します。
ViP3D の全体的なプロセスを図に示します。まず、クエリベースのトラッカーが周囲のカメラからのマルチビュー ビデオを処理して、視覚的特徴を持つ追跡対象エージェントのクエリを取得します。エージェント クエリの視覚的特徴は、エージェント間の関係だけでなく、エージェントの動きのダイナミクスと視覚的特徴もキャプチャします。その後、軌道予測器は追跡エージェントのクエリを入力として受け取り、それを HD マップの特徴に関連付け、最終的に予測された軌道を出力します。
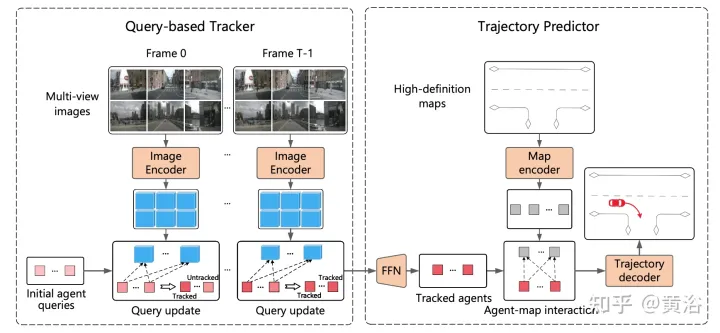
# クエリベースのトラッカーは、周囲のカメラの生のビデオから視覚的特徴を抽出します。具体的には、フレームごとに、DETR3Dに従って画像の特徴が抽出されます。時間領域特徴集約の場合、クエリベースのトラッカーは MOTR (「Motr: End-to-end multiple-object tracking with transmer」。arXiv 2105.03247, 2021) に従って設計されており、次の 2 つの主要な手順が含まれます。クエリ機能の更新とクエリの監視。エージェントのクエリは、エージェントの動きのダイナミクスをモデル化するために時間の経過とともに更新されます。
既存の軌道予測方法のほとんどは、エージェントのエンコード、マップのエンコード、および軌道デコードの 3 つの部分に分けることができます。クエリベースの追跡の後、追跡されたエージェントのクエリが取得されます。これは、エージェントのエンコードを通じて取得されたエージェントの特性と見なすことができます。したがって、残りのタスクは地図のエンコードと軌跡のデコードです。
予測エージェントと真値エージェントをそれぞれ順序なしセット S^ と S として表します。ここで、各エージェントは現在のタイム ステップのエージェント座標と K 個の可能な将来の軌跡で表されます。エージェント タイプ c ごとに、Sc ^ と Sc の間の予測精度を計算します。予測エージェントと真実エージェントの間のコストを次のように定義します。

#Sc^ と Sc の間の EPA は、次のように定義されます。

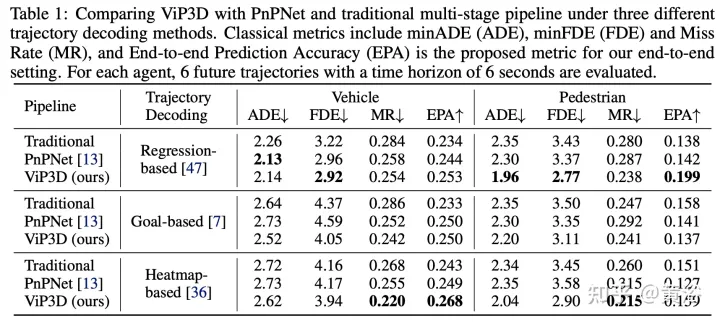
実験結果は次のとおりです:
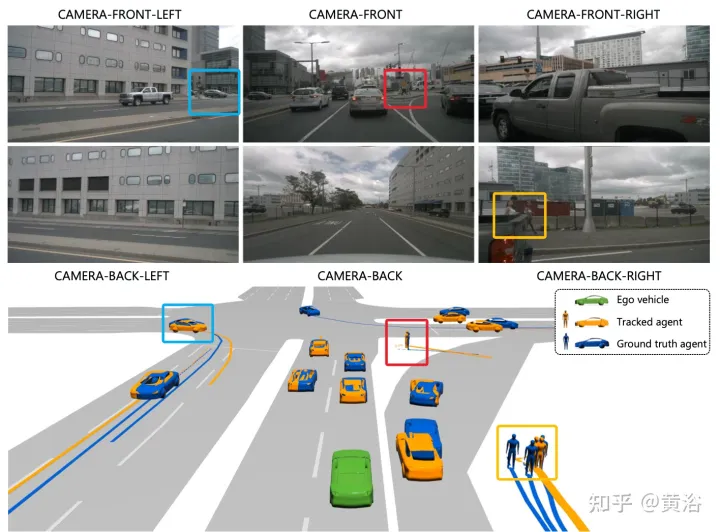
以上がViP3D: 3D エージェント クエリによるエンドツーエンドの視覚的軌道予測の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7940
7940
 15
1652
14
1412
52
1303
25
1250
29
15
1652
14
1412
52
1303
25
1250
29

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 飛び回ったり、口を開けたり、見つめたり、眉毛を上げたりする顔の特徴をAIが完璧に模倣し、ビデオ詐欺を防ぐことは不可能
Dec 14, 2023 pm 11:30 PM
飛び回ったり、口を開けたり、見つめたり、眉毛を上げたりする顔の特徴をAIが完璧に模倣し、ビデオ詐欺を防ぐことは不可能
Dec 14, 2023 pm 11:30 PM
これほど強力なAIの模倣能力では、それを防ぐことは本当に不可能です。 AIの発展は今ここまで進んでいるのか?前足で顔の特徴を浮き上がらせ、後ろ足で全く同じ表情を再現し、見つめたり、眉を上げたり、口をとがらせたり、どんなに大袈裟な表情でも完璧に真似しています。難易度を上げて、眉毛を高く上げ、目を大きく開き、口の形も歪んでいるなど、バーチャルキャラクターアバターで表情を完璧に再現できます。左側のパラメータを調整すると、右側の仮想アバターもそれに合わせて動きが変化し、口や目の部分がアップになります。同じです(右端)。この研究は、GaussianAvatars を提案するミュンヘン工科大学などの機関によるものです。
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
 MotionLM: マルチエージェント動作予測のための言語モデリング技術
Oct 13, 2023 pm 12:09 PM
MotionLM: マルチエージェント動作予測のための言語モデリング技術
Oct 13, 2023 pm 12:09 PM
この記事は自動運転ハート公式アカウントより許可を得て転載しておりますので、転載については出典元までご連絡ください。原題: MotionLM: Multi-Agent Motion Forecasting as Language Modeling 論文リンク: https://arxiv.org/pdf/2309.16534.pdf 著者の所属: Waymo 会議: ICCV2023 論文のアイデア: 自動運転車の安全計画のために、将来の動作を確実に予測するロードエージェントの数は非常に重要です。この研究では、連続的な軌跡を離散的なモーション トークンのシーケンスとして表現し、マルチエージェントのモーション予測を言語モデリング タスクとして扱います。私たちが提案するモデル MotionLM には次の利点があります。
 LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
上記と著者の個人的な理解: この論文は、自動運転アプリケーションにおける現在のマルチモーダル大規模言語モデル (MLLM) の主要な課題、つまり MLLM を 2D 理解から 3D 空間に拡張する問題の解決に特化しています。自動運転車 (AV) は 3D 環境について正確な決定を下す必要があるため、この拡張は特に重要です。 3D 空間の理解は、情報に基づいて意思決定を行い、将来の状態を予測し、環境と安全に対話する車両の能力に直接影響を与えるため、AV にとって重要です。現在のマルチモーダル大規模言語モデル (LLaVA-1.5 など) は、ビジュアル エンコーダーの解像度制限や LLM シーケンス長の制限により、低解像度の画像入力しか処理できないことがよくあります。ただし、自動運転アプリケーションには次の要件が必要です。
 クロスモーダル占有知識の学習: レンダリング支援蒸留技術を使用した RadOcc
Jan 25, 2024 am 11:36 AM
クロスモーダル占有知識の学習: レンダリング支援蒸留技術を使用した RadOcc
Jan 25, 2024 am 11:36 AM
原題: Radocc: LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation 論文リンク: https://arxiv.org/pdf/2312.11829.pdf 著者単位: FNii、CUHK-ShenzhenSSE、CUHK-Shenzhen Huawei Noah's Ark Laboratory Conference: AAAI2024 Paper Idea: 3D Occupancy Prediction isこれは、マルチビュー画像を使用して 3D シーンの占有状態とセマンティクスを推定することを目的とした新たなタスクです。ただし、幾何学的事前分布が欠如しているため、画像ベースのシナリオは
