

この論文は、攻撃に抵抗するための深層強化学習の取り組みについて説明しています。この論文では、著者はロバスト最適化の観点から、敵対的攻撃に対する深層強化学習戦略のロバスト性を研究します。ロバストな最適化の枠組みの下では、戦略の期待利益を最小限に抑えることで最適な敵対的攻撃が与えられ、それに応じて最悪のシナリオに対処する戦略のパフォーマンスを向上させることで優れた防御メカニズムが実現されます。
攻撃者は通常、トレーニング環境では攻撃できないことを考慮して、環境と対話することなく戦略の期待利益を最小限に抑えようとする貪欲な攻撃アルゴリズムを提案します。さらに、著者は、最大最小ゲームを使用して深層強化学習アルゴリズムの敵対的トレーニングを実行する防御アルゴリズム。
Atari ゲーム環境での実験結果は、著者が提案した敵対的攻撃アルゴリズムが既存の攻撃アルゴリズムよりも効果的であり、戦略の返還率が低いことを示しています。この論文で提案されている敵対的防御アルゴリズムによって生成される戦略は、既存の防御方法よりもさまざまな敵対的攻撃に対して堅牢です。
任意のサンプル (x, y) とニューラル ネットワーク f が与えられた場合、敵対的サンプルを生成する最適化目標は次のとおりです。
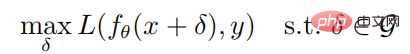
は x を中心とし、半径。 PGD 攻撃を通じて敵対的サンプルを生成するための計算式は次のとおりです: 
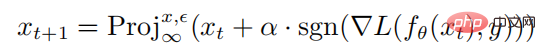
は投影演算を表します。入力が標準球の外側にある場合、入力はx を中心とし、半径として球上に投影されることは、PGD 攻撃の 1 ステップの外乱サイズを表します。 
の 5 つ組として定義できます。ここで、S は状態空間、A はアクション空間、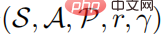 は状態遷移確率、r は割引係数を表します。強学習学習の目標は、値関数
は状態遷移確率、r は割引係数を表します。強学習学習の目標は、値関数 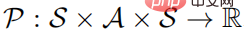

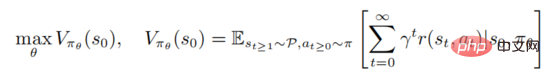 を最大化するパラメータ ポリシー分布を学習することです。ここで、 は初期状態を表します。強力な学習には、アクション価値関数の評価が含まれます。
を最大化するパラメータ ポリシー分布を学習することです。ここで、 は初期状態を表します。強力な学習には、アクション価値関数の評価が含まれます。
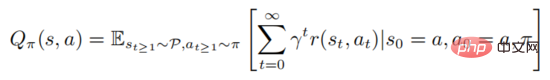 上記の式は、状態が実行された後にポリシーに従うという数学的な期待を表します。この定義から、価値関数と行動価値関数が次の関係を満たすことがわかります。
上記の式は、状態が実行された後にポリシーに従うという数学的な期待を表します。この定義から、価値関数と行動価値関数が次の関係を満たすことがわかります。
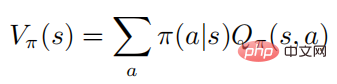 #表現を容易にするため、著者は主にマルコフ過程に焦点を当てています。ただし、すべてのアルゴリズムと結果は、連続する設定に直接適用できます。
#表現を容易にするため、著者は主にマルコフ過程に焦点を当てています。ただし、すべてのアルゴリズムと結果は、連続する設定に直接適用できます。
03 論文法
のフレームワークに基づいています。
ここで、 は、敵対的な摂動シーケンスのセットを表します
は、敵対的な摂動シーケンスのセットを表します  、すべての
、すべての  について、満足のいく
について、満足のいく 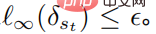 上記の式は、攻撃と防御に対抗するための深層強化学習のための統一フレームワークを提供します。
上記の式は、攻撃と防御に対抗するための深層強化学習のための統一フレームワークを提供します。
一方、内部最小化最適化は、現在の戦略に誤った決定をさせる対立的な摂動シーケンスを見つけようとします。一方、外部最大化の目的は、摂動戦略の下で期待される収益を最大化するための戦略分布パラメータを見つけることです。上記の敵対的攻撃と防御ゲームの後、トレーニング プロセス中の戦略パラメーターは敵対的攻撃に対する耐性が高くなります。
目的関数の内部最小化の目的は敵対的摂動を生成することですが、強化学習アルゴリズムが最適な敵対的摂動を学習するには非常に時間と労力がかかり、またトレーニング環境が脅威となるためです。ブラックボックスであるため、この論文では、攻撃者がさまざまな状態で摂動を注入するという実際的な設定を検討します。教師あり学習攻撃シナリオでは、攻撃者は分類器モデルを騙して誤分類させ、間違ったラベルを生成するだけで済みます。強化学習攻撃シナリオでは、アクション値関数が追加情報、つまり小さな動作値を攻撃者に提供します。その結果、期待される収益はわずかになります。これに対応して、著者は、深層強化学習における最適な敵対的摂動を次のように定義します。
定義 1: 状態 s に対する最適な敵対的摂動は、状態の期待されるリターンを最小限に抑えることができます
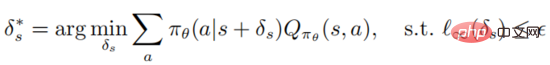
上記の式の最適化と解決は非常に難しいことに注意してください。攻撃者がエージェントをだまして最悪の意思決定動作を選択できるようにする必要があります。ただし、攻撃者にとって、エージェントのアクション値は関数は不可知論的であるため、摂動に対して最適であるという保証はありません。次の定理は、政策が最適であれば、アクション値関数
にアクセスせずに最適な敵対的摂動を生成できることを示しています。 定理 1: 制御戦略 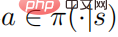 が最適な場合、アクション値関数と戦略は次の関係を満たす
が最適な場合、アクション値関数と戦略は次の関係を満たす
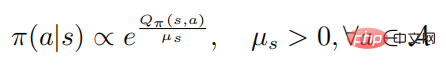
# ここで、 はポリシーのエントロピーを表し、 は状態に依存する定数で、 0 に変化すると、それも 0 に変化します。 さらに、次の式
は次のことを証明します。ランダム戦略 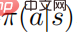 が最適に達すると、価値関数
が最適に達すると、価値関数 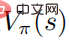 も最適に達します。これは、各状態で、次のような他の行動分布を見つけることは不可能であることを意味します。価値関数
も最適に達します。これは、各状態で、次のような他の行動分布を見つけることは不可能であることを意味します。価値関数 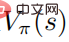 が増加すること。同様に、最適なアクション値関数
が増加すること。同様に、最適なアクション値関数 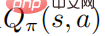 が与えられた場合、制約付き最適化問題を解くことで最適な戦略を取得できます。
が与えられた場合、制約付き最適化問題を解くことで最適な戦略を取得できます。
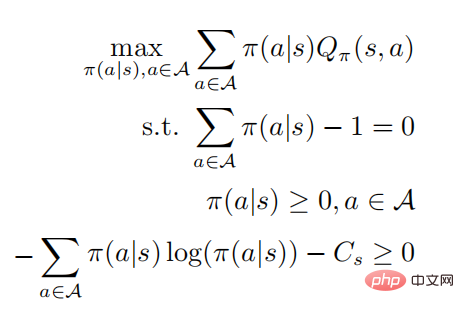
2 行目と 3 行目は確率を表します。 KKT 条件に従って、上記の最適化問題は次の形式に変換できます:
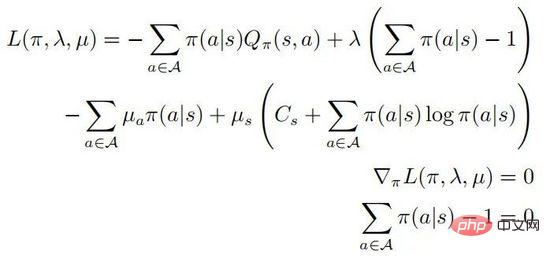
がすべてのアクション 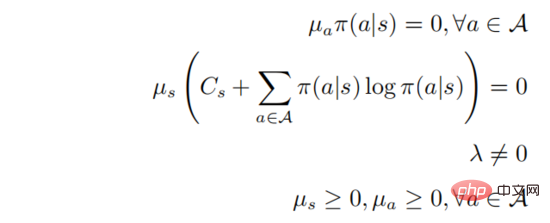 に対して正定であると仮定すると、次のようになります。
に対して正定であると仮定すると、次のようになります。
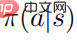
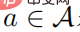
が存在し、その後に任意の ' が存在する必要があります。 s 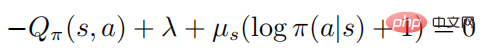 、次に
、次に
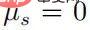
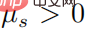
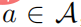
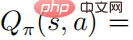
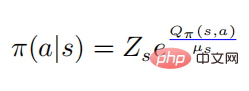
 上の最初の方程式を 2 番目の方程式に組み込むと、
上の最初の方程式を 2 番目の方程式に組み込むと、
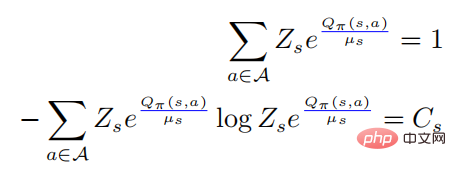
ここで
## になります。 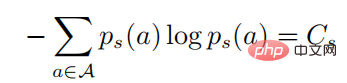
はソフトマックス形式の確率分布を表し、そのエントロピーは に等しい。が 0 に等しいときは 0 になります。この場合、 は 0 より大きいので、この時点では
になります。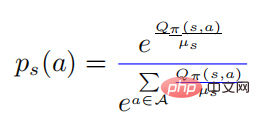 定理 1 は、戦略が最適であれば、摂動戦略と元の戦略のクロスエントロピーを最大化することで最適な摂動を取得できることを示しています。議論を簡単にするため、著者は定理 1 の攻撃を戦略的攻撃と呼び、PGD アルゴリズム フレームワークを使用して最適な戦略的攻撃を計算します。具体的なアルゴリズムのフローチャートを以下のアルゴリズム 1 に示します。
定理 1 は、戦略が最適であれば、摂動戦略と元の戦略のクロスエントロピーを最大化することで最適な摂動を取得できることを示しています。議論を簡単にするため、著者は定理 1 の攻撃を戦略的攻撃と呼び、PGD アルゴリズム フレームワークを使用して最適な戦略的攻撃を計算します。具体的なアルゴリズムのフローチャートを以下のアルゴリズム 1 に示します。

はポリシーのトレーニングを支援するために推定されます。
具体的な詳細は、価値関数が減少することが保証されていないにもかかわらず、著者が最初に戦略的攻撃を使用してトレーニング段階で摂動を生成していることです。トレーニングの初期段階では、ポリシーはアクション価値関数に関連していない可能性がありますが、トレーニングが進むにつれて、それらは徐々にソフトマックス関係を満たすようになります。 
摂動ポリシーを実行することで軌跡が収集され、これらのデータを使用してアクション価値関数を推定するため、扱いが困難です。動揺しない方針は非常に不正確である可能性があります。 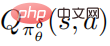
PPO を使用した最適化された摂動戦略 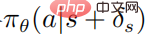 の目的関数は
の目的関数は
であり、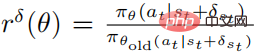 は摂動戦略の平均関数
は摂動戦略の平均関数 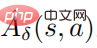 の推定値です。実際には、
の推定値です。実際には、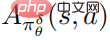 は GAE 手法によって推定されます。具体的なアルゴリズムのフローチャートを下図に示します。
は GAE 手法によって推定されます。具体的なアルゴリズムのフローチャートを下図に示します。 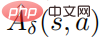


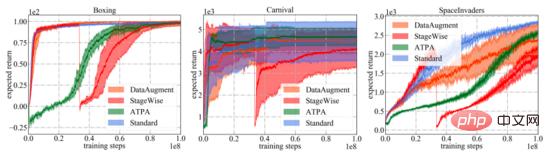
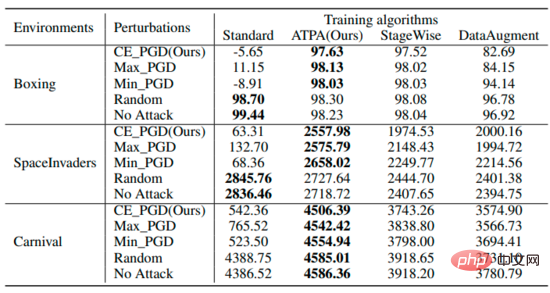
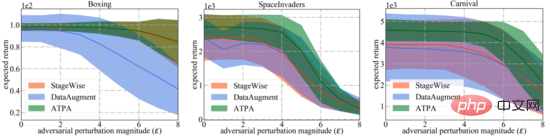
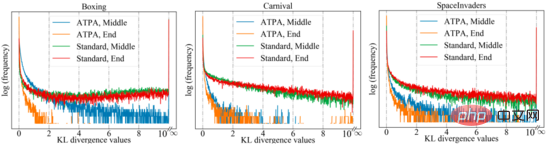
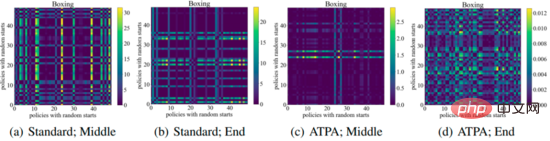
以上が深層強化学習における敵対的な攻撃と防御の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



