

Soulインテリジェント音声技術実用化への道

著者 | Liu Zhongliang
Compilation| Lu Xinwang
Reviewer| Yun Zhao
## 近年、インテリジェント音声言語技術が急速に発展し、人々の生産方法や生活様式が徐々に変化し、ソーシャル分野においてもインテリジェント音声技術に対する要求が高まっています。
最近、51CTOが主催するAISummitグローバル人工知能技術カンファレンスで、ソウルボイスアルゴリズム責任者の劉忠良氏が「ソウルインテリジェントボイス技術の実践への道」という基調講演を行いました。 Soul のビジネス シナリオの一部は、インテリジェント音声テクノロジーにおける Soul の実践的な経験の一部を共有しています。
皆さんにインスピレーションを与えることを願い、講演内容を以下のように構成しました。
ソウルの音声アプリケーション シナリオ
ソウルは、インタレスト グラフに基づいて推奨される没入型のソーシャル シーンです。このシーンでは、多くの音声交換があるため、多くの過去の期間にわたって蓄積されたデータ。現在、1 日の時間は約数百万時間ですが、音声通話から無音やノイズなどを除いて、意味のある音声クリップだけを数えると、約 60 ~ 70 億の音声クリップがあることになります。 Soul の音声サービスの入り口は主に次のとおりです。
Voice Party
グループでルームを作成し、多くのユーザーが音声チャットを行うことができます。
ビデオ パーティー
実際、Soul プラットフォームのほとんどのユーザーは顔を見せたり、自分自身を露出したりしたくないため、独自に開発した 3D The Avatar を作成しました。ユーザーが自分自身をより良く表現したり、プレッシャーを感じずに表現したりできるように、画像やヘッドギアがユーザーに与えられます。
人狼ゲーム
は、多人数で一緒にゲームができるルームでもあります。
音声マッチング
より特徴的なシナリオは音声マッチングです。つまり、WeChat での通話と同じであり、1 対 1 でチャットできます。
これらのシナリオに基づいて、私たちは主に 2 つの主要な方向に焦点を当てて、自社開発の音声機能を構築しました。1 つ目は人間とコンピューターの自然な対話、2 つ目はコンテンツの理解と生成です。 。主要な側面は 4 つあります: 1 つ目は音声認識と音声合成、2 つ目は音声分析と音声アニメーションです。下の図は、主に音質、効果音、音響効果などの音声分析を含む、私たちが使用する一般的な音声ツールを示しています。音楽。次に、中国語認識、歌声認識、中国語と英語の混読などの音声認識です。 3つ目は音声合成に関するもので、エンターテイメント変換、音声変換、歌唱合成関連などです。 4 つ目は音声アニメーションで、主にテキスト駆動の口の形状、音声駆動の口の形状、その他の音声アニメーション テクノロジが含まれます。
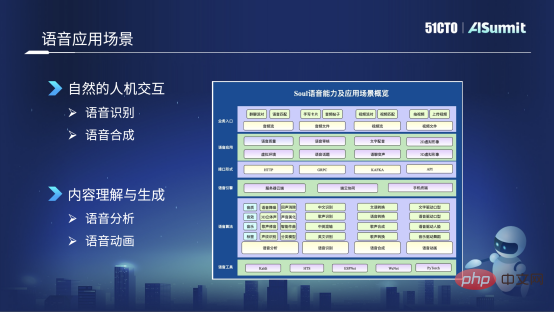
#これらの音声アルゴリズム機能に基づいて、強化、音声レビュー、テキスト吹き替えなどの音声品質検出など、多くの音声アプリケーション フォームを用意しています。 、音声トピック、これらの 3D 空間音響効果などの仮想環境サウンドなど。音声レビューとアバターの2つのビジネスシナリオで使用されるテクノロジーを紹介します。
音声コンテンツ レビュー
音声コンテンツ レビューは、政治、ポルノ、虐待、広告など、または個人情報に関連するコンテンツのオーディオ クリップにラベルを付けることです。これらの違反タグを検出してレビューし、ネットワークのセキュリティを確保します。ここで使用されるコアテクノロジーはエンドツーエンドの音声認識で、ユーザーの音声をテキストに変換するのを支援し、下流のレビュー担当者に二次的な品質検査を提供します。
エンドツーエンドの音声認識システム
下の図は、現在使用しているエンドツーエンドの音声認識フレームワークです。ユーザーの音声のフラグメント 特徴抽出には、現在多くの機能が使用されています。主に Alfa-Bank の機能を使用します。一部のシナリオでは、Wav2Letter などの事前トレーニングされた機能の使用を試みます。オーディオ特徴を取得した後、エンドポイント検出が実行され、人が話しているかどうか、およびオーディオ クリップに人の声が含まれているかどうかが検出されます。現在使用されているのは、基本的にいくつかの古典的なエネルギー VD とモデル DNVD です。
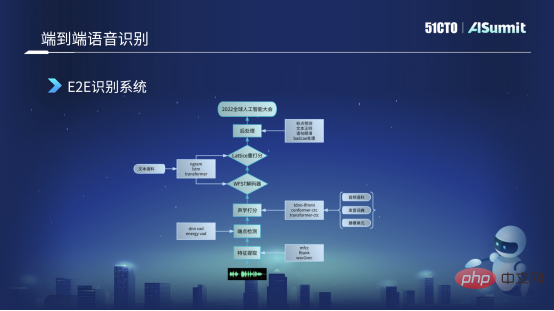
これらの特徴を取得した後、音響スコアリング モジュールに送信します。この音響モデルには最初に Transformer CDC を使用しましたが、現在は Conformer CDC に反復されています。この音響スコア付けの後、一連のシーケンス スコアをデコーダに送信します。デコーダはテキストのデコードを担当し、認識結果に基づいて 2 番目のスコア付けを実行します。このプロセスで使用するモデルは基本的に、従来の EngelM モデルなどのいくつかと、現在主流の再スコアリング用の Transformer 深層学習モデルのいくつかです。最後に、句読点の検出、テキストの正規化、文章の平滑化などの後処理も実行し、最終的に「2022 年世界人工知能会議」のような意味のある正確なテキスト認識結果を取得します。
エンドツーエンド音声認識システムでは、実際、ここで言うエンドツーエンドとは主に音響スコアリング部分のことです。テクノロジー、その他の部分は主に従来のディープラーニング手法といくつかの古典的なディープラーニング手法です。
上記のシステムを構築する過程で、実際には多くの問題に遭遇しました。主な問題は次の 3 つです。
- 教師付き音響データが少なすぎる これも、誰もがよく遭遇することです。主な理由は次のとおりです。 まず、注釈を付ける前に音声を聞く必要があります。第二に、ラベルのコストも非常に高いです。したがって、この部分のデータの欠如は誰にとっても共通の問題です。
- モデル認識効果が低い これには多くの理由があります。 1 つ目は、中国語と英語が混在している場合、または複数の分野を読んでいる場合、一般的なモデルを使用して識別するのは比較的不十分であるということです。
- モデルが遅い
これらの問題に対処するために、主に次の 3 つの方法を使用します。それを解決してください。
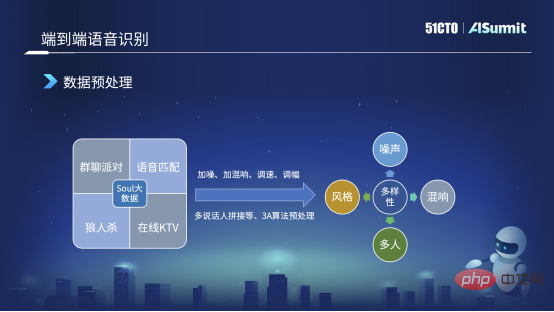
データの前処理
ソウルには多くの複雑なシナリオがあります。例えば、グループチャットパーティーでは複数人が重なっていたり、ABさんが話していたりする場面もあるでしょう。たとえば、オンライン KTV では、人々が同時に歌いながら話す状況が発生します。ただし、データにラベルを付ける場合は、比較的高価であるため、これらのシナリオの下で比較的クリーンなデータを選択してラベル付けします。たとえば、10,000 時間のクリーンなデータにラベルを付ける場合があります。ただし、クリーン データの複雑さは実際のシナリオのデータとは異なるため、これらのクリーン データに基づいてデータの前処理を行います。たとえば、いくつかの古典的なデータ前処理方法には、ノイズの追加、残響の追加、速度の調整、速度の高速化または低速化の調整、エネルギーの調整、エネルギーの増加または減少が含まれます。
これらの方法に加えて、ビジネス シナリオで発生するいくつかの問題に対処するために、対象を絞ったデータ前処理またはデータ拡張をいくつか実行します。たとえば、グループ チャット パーティーでは複数の発言者が重なりやすいと先ほど述べました。そのため、マルチ スピーカーのスプライス音声を作成します。つまり、3 人の発言者 ABC の音声クリップを切り取って、データの増強。
一部のオーディオおよびビデオ通話では、自動エコー キャンセル、インテリジェント ノイズ リダクションなど、オーディオ フロントエンド全体で基本的な 3D アルゴリズムの前処理が行われるため、オンラインの使用シナリオに適応するために、3D アルゴリズムの前処理も行います。
このようにデータを前処理することで、ノイズが入ったデータや残響のあるデータ、複数の人物や複数のスタイルのデータなど、多様なデータを取得できるようになります。例えば、10,000時間を50,000時間程度、あるいは80,000~90,000時間に拡張する場合、データの範囲と幅は非常に高くなります。
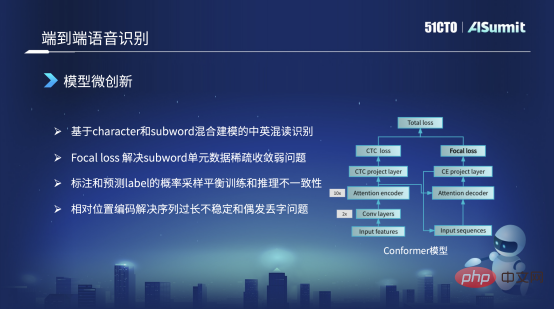
モデルのマイクロイノベーション
私たちが使用するモデルの主なフレームワークは依然として Conformer 構造です。この Conformer 構造の左側には、古典的な Encoder CDC フレームワークがあります。右側はアテンションデコーダです。しかし、右側の損失では、元の Conformer 構造は CE 損失であり、ここではそれを Focal Loss に置き換えたことに誰もが気づきました。主な理由は、フォーカルロスを使用して、スパースユニットとスパースデータトレーニングの非収束の問題、またはトレーニングが不十分である問題を解決できるためです。
たとえば、中国語と英語の混読の場合、学習データに含まれる英単語が非常に少ない場合、この単元はうまく学習できません。焦点損失を通じて、損失の重みを増やすことができます。これにより、量の問題や不十分なトレーニングの問題が軽減され、いくつかの悪いケースが解決されます。
2 番目のポイントは、トレーニング戦略が異なるということです。たとえば、トレーニング戦略ではいくつかの混合トレーニング方法も使用します。たとえば、初期のトレーニングでは、デコード部分をトレーニングするとき、入力として、依然として正確にラベル付けされたラベル シーケンス データを入力として使用します。しかし、トレーニング モデルが収束すると、後の段階で、予測されたラベルの一部をデコーダーの入力として一定の確率に従ってサンプリングして、いくつかのトリックを実行します。このトリックは主に何を解決しますか?学習モデルとオンライン推論モデルの入力特徴量が一致しない現象ですが、これにより一部解決できます。
しかし、もう一つ問題があり、実はオリジナルの Conformer モデルや Vnet や ESPnet が提供するモデルでは、デフォルトが絶対位置情報になっています。ただし、シーケンスが長すぎると絶対位置情報だけでは識別問題を解決できないため、絶対位置情報を相対位置符号化に変更してこの問題を解決します。このようにして、一部の単語の繰り返しや時折単語や単語が失われるなど、認識プロセス中に発生する問題も解決できます。
推論の高速化
最初のモデルは音響モデルで、自己回帰モデルをエンコーダー CDC に基づいてこれに変更します。 WFST デコード方法では、まず、NBest、10best、20best などの認識結果の一部を解決します。 20best に基づいて、Decorde Rescore に送信して 2 回目の再スコアリングを行います。これにより、タイミングの依存関係が回避され、GPT の並列計算や推論が容易になります。
古典的な加速方法に加えて、ハイブリッド量子化方法も使用します。つまり、深層学習の前向き推論のプロセスでは、計算の一部に 8 ビットを使用しますが、金融機能部分などのコア部分では、主に速度と精度の適切なバランスをとるため、引き続き 16 ビットを使用します。
これらの最適化後、全体の推論速度は比較的速くなります。しかし、実際にローンチする過程で、いくつかの小さな問題も発見しました。それはトリックとも言えると思います。
たとえば、言語モデル レベルでは、シーンにはチャット テキストがたくさんありますが、歌も含まれています。話すことと歌の解決の両方を解決するには、同じモデルが必要です。チャットテキストなどの言語モデルに関しては、断片的で短いことが多いため、実験の結果、3 要素モデルの方が優れていることがわかりましたが、5 要素モデルでは改善が見られませんでした。
しかし、たとえば、歌の場合、テキストが比較的長く、文構造と文法が比較的固定されているため、実験中は 3 元より 5 元の方が優れています。 。この場合、ハイブリッド文法を使用して、チャット テキストと歌唱テキストの言語モデルを共同でモデル化します。私たちは「3元と5元」の混合モデルを使用しましたが、この「3元と5元」の混合は、伝統的な意味での違いではありません。四元の文法 袁の歌と五元の文法を直接結合します。この方法で取得された ARPA は現在、サイズが小さく、デコード プロセスが高速であり、さらに重要なのは、ビデオ メモリの使用量が少ないことです。 GPU でデコードする場合、ビデオ メモリ サイズは固定されるためです。したがって、言語モデルによる認識効果をできるだけ高めるためには、言語モデルのサイズをある程度制御する必要があります。
音響モデルと言語モデルを最適化して工夫した結果、現在の推論速度も非常に高速になりました。リアルタイム レートは、基本的に 0.1 または 0.2 のレベルに達する可能性があります。

仮想シミュレーション
は主に、ユーザーが音、口の形、表情、姿勢などのコンテンツをより正確に生成するのに役立ちます。圧力をかけずに、より自然で自由に表現するために必要なコア技術の 1 つがマルチモーダル音声合成です。
マルチモーダル音声合成
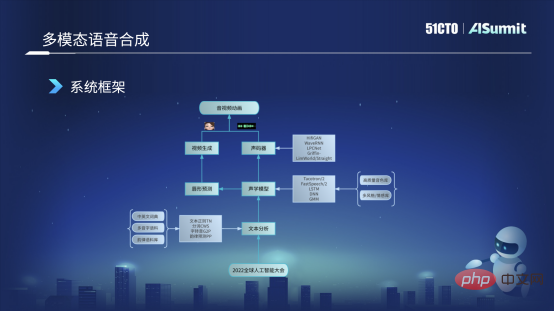
次の図は、現在使用されている音声合成システムの基本的な枠組みです。まず、「2022 Global Artificial Intelligence Conference」などのユーザーの入力テキストを取得し、それをテキスト分析モジュールに送信します。このモジュールは主に、テキストの正則化や単語などのさまざまな側面でテキストを分析します。セグメンテーションの中で最も重要なことは、自己転送、単語を音素に変換すること、および韻予測やその他の機能です。このテキスト分析の後、ユーザーの文章のいくつかの言語的特徴を取得することができ、これらの特徴は音響モデルに送信されます。音響モデルについては、現在主に FastSpeech フレームワークに基づいたいくつかのモデルの改善とトレーニングを使用しています。
音響モデルは、メル特徴、持続時間、エネルギーなどの音響特徴を取得し、その特徴の流れの方向は 2 つの部分に分かれます。その一部をボコーダーに送信します。ボコーダーは主に、聞くことができるオーディオ波形を生成するために使用されます。もう一方の流れ方向は口唇形状予測に送られ、口唇形状予測モジュールを通じて口唇形状に対応するBS係数を予測することができます。 BS 特徴量を取得した後、それをビデオ生成モジュールに送信します。このモジュールはビジュアル チームが担当し、口の形と表情を備えた仮想画像である仮想アバターを生成できます。最後に、仮想アバターとオーディオを結合し、最終的にオーディオとビデオのアニメーションを生成します。これがマルチモーダル音声合成全体の基本フレームワークと基本プロセスです。
マルチモーダル音声合成プロセスの主な問題:
- 音声ライブラリデータの品質は比較的悪いです。
- 合成された音質は悪いです。
- 音声と映像の遅延が大きく、口の形と声が一致していない
魂の処理方法が一致しているエンドツーエンドの音声が改善されています。認識システムも同様です。
データの前処理
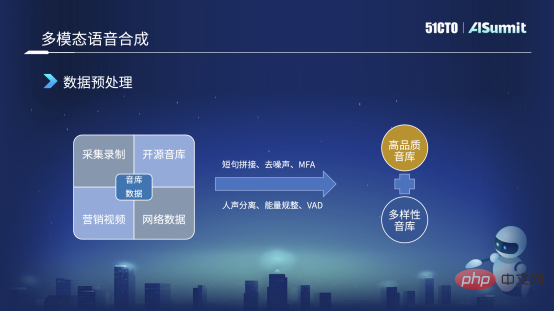
私たちのサウンド ライブラリは多くのソースから来ています。左側の画像は、収集して記録する最初の画像です。第 2 に、もちろん、いくつかのサウンド ライブラリをオープンソースにしてくれるオープン ソース データ会社に非常に感謝しています。また、それらを使用していくつかの実験を行う予定です。第三に、私たちのプラットフォームには企業レベルの公開マーケティングビデオがいくつかありますが、ビデオを作成する際に、質の高いアンカーを招待して作成したため、音質も非常に高品質です。 4 番目に、対話の過程など、一部のパブリック ネットワーク データは比較的高品質であるため、一部をクロールして事前アノテーションを行い、主に内部実験と事前トレーニングを行います。
これらのデータの複雑さに対応して、短い文をつなぎ合わせるなどのデータの前処理を行いましたが、先ほども述べたように、収集プロセス中に文が長かったり短かったりする可能性があります。サウンドライブラリの長さを増やすため、短い文章をカットし、途中で無音部分を削除しますが、無音部分が長すぎると影響が出る場合があります。
2 つ目はノイズ除去です。たとえば、取得したネットワーク データやマーケティング ビデオから、いくつかの音声強調方法を通じてノイズを除去します。
3 番目に、実際、現在のアノテーションのほとんどは音声から文字へのアノテーションですが、現在は基本的に音素の境界はアノテーションとして使用されないため、通常はこの MFA を使用して、音素境界情報を取得するためのアライメント方法を強制します。
次に、以下のボーカルの分離は非常に特殊です。マーケティング ビデオに BGM が含まれているため、ボーカルを分離して BGM を付けます。それを削除して、ドライなサウンドを取得します。データ。また、エネルギーの正則化と VAD も行います。VAD は主に対話データまたはネットワーク データに含まれます。VAD を使用して効果的な人間の音声を検出し、それらを使用して事前アノテーションまたは事前トレーニングを行います。
モデルのマイクロイノベーション
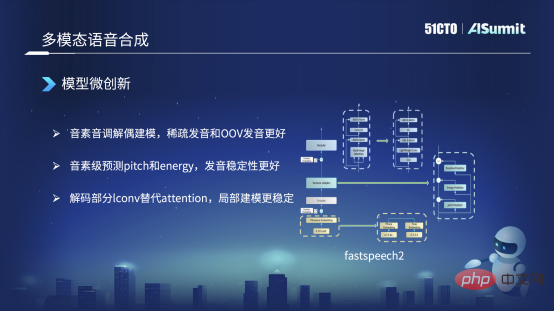
FastSpeech の作成プロセスでは、主に 3 つの側面で変更を加えました。左側の図の左側にあるタイプは、FastSpeech の基本モデルです。最初に行った変更は、モデリングのために音素とトーンを分離することです。つまり、通常の状況では、テキスト フロントエンドが変換するものはのような音素のシーケンス 左の図と同じ、「こんにちは」のような単調な音素のシーケンス。ただし、これを右側の 2 つの部分に分割します。つまり、左側の部分は音素のみを含み、トーンは含まれない音素シーケンスです。右側のものには声調のみがあり、音素はありません。この場合、それらをそれぞれ ProNet (サウンド) に送信し、2 つのエンベディングを取得します。 2 つの埋め込みは一緒に切り取られて、以前の埋め込み方法を置き換えます。この場合の利点は、発音がまばらである、または一部の発音がトレーニング コーパスにないという問題を解決できることですが、この種の問題は基本的に解決できます。
変更した 2 番目の方法は、元の方法では、最初に継続時間を予測し (右側の図)、次にこの継続時間に基づいてサウンド セットを拡張し、次に、エネルギーとピッチを予測します。ここで順序を変更し、音素レベルに基づいてピッチとエネルギーを予測し、予測後にフレーム レベルの継続時間まで拡張します。この利点は、完全な音素の発音プロセス全体を通じて発音が比較的安定していることです。これはシナリオの変更です。
3 つ目は、上部の Decoder 部分に別の変更を加えたことです。元の Decoder は Attender メソッドを使用していましたが、現在は Iconv または Convolution メソッドに切り替えられています。この利点は、セルフ アテンションは非常に強力な履歴情報とコンテキスト情報を取得できるものの、段階的にモデル化する能力が比較的低いためです。したがって、Convolution に切り替えた後は、この種のローカル モデリングを処理する能力が向上します。例えば、発音の場合、先ほど述べた、発音が比較的鈍い、あるいは曖昧になるという現象は、基本的には解決できます。これらは現在行われている主な変更の一部です。
共有音響モデル
左側は合成された口の形状、右側は合成された音声です。音響モデル情報の一部のエンコーダーとデュレーション。
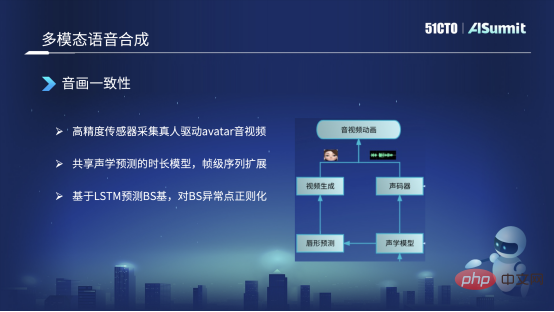
#主に 3 つのアクションを実行しました。 1 つ目は、実際に高精度のデータを収集することです。たとえば、予測したアバター画像を駆動し、高解像度のオーディオとビデオを取得し、いくつかの高精度センサーを装着している本物の人々を見つけます。注釈。このようにして、テキスト、オーディオ、ビデオの同期されたデータを取得します。
2 つ目は、音と映像の一貫性をどのように解決するかについても言及されるかもしれません。なぜなら、最初にテキスト合成で音声を合成し、音声を取得した後、音声から口の形状を予測することになるため、フレームレベルで非対称に見えてしまいます。現時点では、合成された口の形状と合成された音の間で音響モデルを共有するこの方法を使用しており、フレームレベルのシーケンスが拡張された後にそれを実行しています。現時点では、フレーム レベルでの位置合わせが保証されており、オーディオとビデオの一貫性が保証されています。
最後に、現在、口の形状や BS 塩基の予測に配列ベースの方法は使用しておらず、LSTM に基づいて BS 塩基を予測しています。 BS係数を予測した後、何らかの異常を予測する可能性がありますが、BS基底が大きすぎたり小さすぎたりすると、口の形が開きすぎてしまうなど、正則化などの後処理も行います。範囲は大きすぎてはならず、妥当な範囲内で制御されます。現時点では、基本的に音声と映像の整合性を確保することは可能です。
1つ目はマルチモーダル認識で、騒音の多い状況では音声と口の形を組み合わせて認識します。マルチモーダル認識により、認識精度が向上します。
2 つ目は、マルチモーダル音声合成とリアルタイム音声変換です。これは、ユーザーの感情とスタイルの特徴を保持できますが、ユーザーの音色を別の音色に変換するだけです。
以上がSoulインテリジェント音声技術実用化への道の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7814
7814
 15
1646
14
1402
52
1300
25
1238
29
15
1646
14
1402
52
1300
25
1238
29

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
8月1日の本サイトのニュースによると、SKハイニックスは本日(8月1日)ブログ投稿を発表し、8月6日から8日まで米国カリフォルニア州サンタクララで開催されるグローバル半導体メモリサミットFMS2024に参加すると発表し、多くの新世代の製品。フューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) の紹介。以前は主に NAND サプライヤー向けのフラッシュ メモリ サミット (FlashMemorySummit) でしたが、人工知能技術への注目の高まりを背景に、今年はフューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) に名前が変更されました。 DRAM およびストレージ ベンダー、さらに多くのプレーヤーを招待します。昨年発売された新製品SKハイニックス
