

PyTorch を使用した少数ショット学習による画像分類

近年、深層学習ベースのモデルは、ターゲット検出や画像認識などのタスクで優れたパフォーマンスを発揮しています。 1,000 種類の異なるオブジェクト分類を含む ImageNet のような難しい画像分類データセットでは、一部のモデルが人間のレベルを超えています。しかし、これらのモデルは教師ありトレーニング プロセスに依存しており、ラベル付きトレーニング データの利用可能性に大きく影響され、モデルが検出できるクラスはトレーニングされたクラスに限定されます。
トレーニング中にすべてのクラスに十分なラベル付き画像がないため、これらのモデルは現実の設定ではあまり役に立たない可能性があります。そして、すべての潜在的なオブジェクトの画像でトレーニングすることはほぼ不可能であるため、モデルがトレーニング中に認識しなかったクラスを認識できるようにしたいと考えています。少数のサンプルから学習する問題は、Few-Shot 学習と呼ばれます。
少数ショット学習とは何ですか?

少数ショット学習は、機械学習のサブフィールドです。これには、わずかなトレーニング サンプルと監視データのみを使用して新しいデータを分類することが含まれます。私たちが作成したモデルは、少数のトレーニング サンプルだけでもかなり良好に動作します。
次のシナリオを考えてみましょう。医療分野では、まれな病気の場合、トレーニングに十分な X 線画像がない可能性があります。このようなシナリオでは、数ショット学習分類器を構築することが完璧なソリューションです。
小規模サンプルにおける変化
一般に、研究者は次の 4 つのタイプを特定しています。
- N ショット学習 (NSL)
- フューショット学習 (FSL)
- ワンショット学習 (OSL)
- ゼロショット学習 (ZSL)
FSL について話すとき、通常はN-way-K-Shot 分類。 N はクラスの数を表し、K は各クラスでトレーニングされるサンプルの数を表します。したがって、N ショット学習は、他のすべての概念よりも広い概念として考えられます。フューショット、ワンショット、ゼロショットは NSL のサブフィールドであると言えます。一方、ゼロショット学習は、トレーニング例を使用せずに、目に見えないクラスを分類することを目的としています。
ワンショット学習では、各クラスにサンプルは 1 つだけあります。 Few-Shot にはクラスごとに 2 ~ 5 個のサンプルがあります。つまり、Few-Shot は One-Shot Learning のより柔軟なバージョンです。
小規模サンプル学習方法
一般に、少数ショット学習問題を解決する場合は、次の 2 つの方法を考慮する必要があります。
データ レベル アプローチ (DLA)
これ戦略は非常に単純です。ソリッド モデルを作成し、過小適合や過適合を防ぐのに十分なデータがない場合は、さらにデータを追加する必要があります。このため、多くの FSL 問題は、より大きな基礎となるデータ セットからより多くのデータを活用することで解決できます。基本データセットの注目すべき特徴は、Few-Shot チャレンジのサポート セットを構成するクラスが欠けていることです。たとえば、特定の種類の鳥を分類したい場合、基礎となるデータ セットには他の多くの鳥の写真が含まれている可能性があります。
パラメータ レベルのアプローチ (PLA)
パラメータ レベルの観点から見ると、少数ショット学習サンプルは通常、大きな高次元空間を持っているため、比較的容易に過学習されます。パラメータ空間を制限し、正則化を使用し、適切な損失関数を使用すると、この問題の解決に役立ちます。モデルは一般化するために少数のトレーニング サンプルを使用します。
モデルを広いパラメーター空間に誘導することでパフォーマンスを向上させることができます。通常の最適化方法では、トレーニング データが不足しているため、正確な結果が得られない場合があります。
上記の理由により、パラメーター空間を通じて最適なパスを見つけるようにモデルをトレーニングすると、最良の予測結果が得られます。このアプローチはメタ学習と呼ばれます。
小サンプル学習画像分類アルゴリズム
一般的な小サンプル学習方法は 4 つあります。
モデルに依存しないメタ学習モデルに依存しないメタ学習
勾配ベースのメタ学習 (GBML) 原理は MAML の基礎です。 GBML では、メタ学習者は、基本モデルでトレーニングし、すべてのタスク表現にわたる共有特徴を学習することで、事前の経験を積みます。学習すべき新しいタスクが存在するたびに、メタ学習器は、既存の経験と、新しいタスクによって提供される最小限の新しいトレーニング データを使用して微調整されます。
一般に、パラメータをランダムに初期化し、数回更新すると、アルゴリズムは良好なパフォーマンスに収束しません。 MAML はこの問題の解決を試みます。 MAML は、わずか数の勾配ステップでメタパラメータ学習器の信頼性の高い初期化を提供し、過剰学習がないことを保証するため、新しいタスクを最適かつ迅速に学習できます。
手順は次のとおりです:
- メタ学習者は各エピソードの開始時に独自のコピー C を作成します。
- C はこのエピソードでトレーニングされます (ベースモデル) の助けを借りて、
- C はクエリ セットに対して予測を行います。
- これらの予測から計算された損失は、C を更新するために使用されます。
- これは続きますトレーニングのすべてのエピソードが完了するまで。

この手法の最大の利点は、メタ学習アルゴリズムの選択とは独立していると考えられることです。したがって、MAML 手法は、迅速な適応を必要とする多くの機械学習アルゴリズム、特にディープ ニューラル ネットワークで広く使用されています。
マッチング ネットワーク
FSL 問題を解決するために作成された最初のメトリクス学習方法は、マッチング ネットワーク (MN) でした。
マッチング ネットワーク法を使用してフューショット学習問題を解決する場合は、大規模なベース データ セットが必要です。 。
データセットをいくつかのエピソードに分割した後、エピソードごとに、マッチング ネットワークは次の処理を実行します。
- サポート セットとクエリ セットからのすべての画像が CNN に供給され、特徴の埋め込みを出力します
- サポート セットでトレーニングされたモデルを使用して画像をクエリし、埋め込まれた特徴のコサイン距離を取得し、ソフトマックスで分類します
- CNN バックプロパゲーションによる分類結果のクロス エントロピー損失特徴埋め込みモデルの更新
マッチング ネットワークは、この方法で画像埋め込みの構築を学習できます。 MN は、カテゴリに関する特別な事前知識がなくても、この方法を使用して写真を分類できます。彼は単にクラスのいくつかのインスタンスを比較するだけです。
カテゴリはエピソードごとに異なるため、マッチング ネットワークはカテゴリの区別に重要な画像属性 (特徴) を計算します。標準分類を使用する場合、アルゴリズムは各カテゴリに固有の特徴を選択します。
プロトタイプ ネットワーク
マッチング ネットワークに似ているのが、プロトタイプ ネットワーク (PN) です。いくつかの微妙な変更により、アルゴリズムのパフォーマンスが向上します。 PN は MN よりも優れた結果を達成しますが、トレーニング プロセスは基本的に同じで、サポート セットからのいくつかのクエリ画像埋め込みを比較するだけですが、プロトタイプ ネットワークは異なる戦略を提供します。
PN でクラスのプロトタイプを作成する必要があります。これは、クラス内の画像の埋め込みを平均することによって作成されるクラスの埋め込みです。次に、これらのクラス プロトタイプのみがクエリ画像の埋め込みを比較するために使用されます。単一サンプルの学習問題に使用すると、マッチング ネットワークに匹敵します。
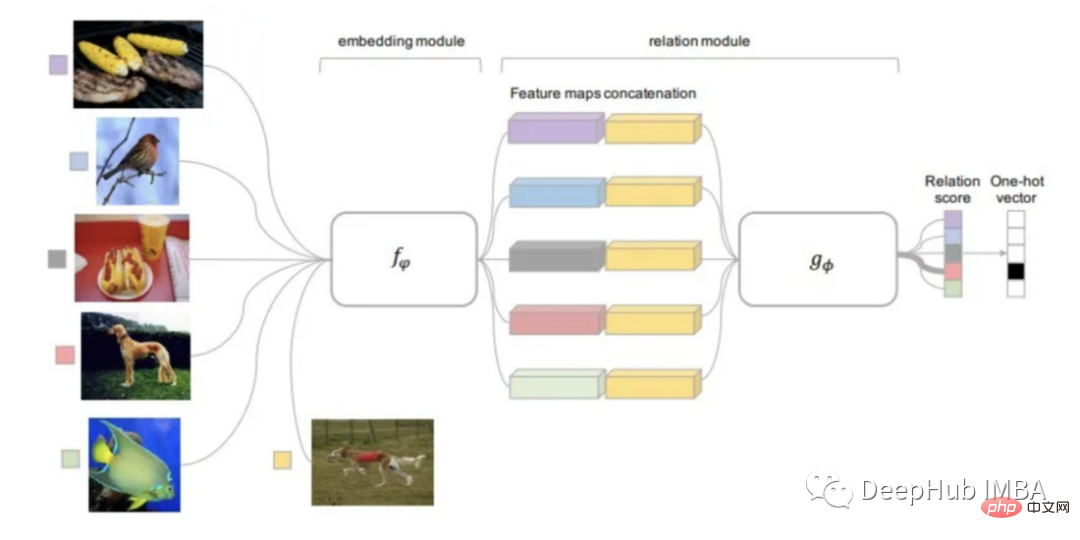
リレーションネットワーク Relation Network
リレーションシップネットワークは、上記のすべての手法の研究成果を継承していると言えます。 RN は PN のアイデアに基づいていますが、アルゴリズムに大幅な改良が加えられています。
この方法で使用される距離関数は、以前の研究のように事前に定義するのではなく、学習可能です。リレーション モジュールは、入力イメージからエンベディングとクラス プロトタイプを計算する部分であるエンベディング モジュールの上に位置します。
トレーニング可能な関係モジュール (距離関数) の入力は、クエリ画像と各クラスのプロトタイプの埋め込みであり、出力は各クラス一致の関係スコアです。予測を取得するために関係スコアが Softmax に渡されます。
Open-AI Clip を使用したゼロサンプル学習
CLIP (Contrastive Language-Image Pre-Training) は、さまざまな用途に使用できる手法です。 (画像、テキスト) 訓練されたニューラル ネットワーク上。タスクに直接最適化することなく、特定の画像に最も関連性のあるテキストの断片を予測できます (GPT-2 および 3 のゼロショット機能と同様)。
CLIP は、ImageNet の「ゼロ サンプル」でオリジナルの ResNet50 のパフォーマンスを達成でき、ラベル付けされたサンプルを使用する必要がありません。これにより、コンピュータ ビジョンにおけるいくつかの大きな課題が克服されます。以下では、Pytorch を使用して簡単なサンプルを実装します。分類モデル。
導入パッケージ
! pip install ftfy regex tqdm
! pip install git+https://github.com/openai/CLIP.gitimport numpy as np
import torch
from pkg_resources import packaging
print("Torch version:", torch.__version__)モデルの読み込み
import clipclip.available_models() # it will list the names of available CLIP modelsmodel, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
print("Model parameters:", f"{np.sum([int(np.prod(p.shape)) for p in model.parameters()]):,}")
print("Input resolution:", input_resolution)
print("Context length:", context_length)
print("Vocab size:", vocab_size)画像前処理
8つのサンプル画像とそのテキスト説明をモデルに入力し、対応関係を比較します。機能の間。
トークナイザーでは大文字と小文字が区別されないため、適切なテキスト説明を自由に入力できます。
import os
import skimage
import IPython.display
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from collections import OrderedDict
import torch
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# images in skimage to use and their textual descriptions
descriptions = {
"page": "a page of text about segmentation",
"chelsea": "a facial photo of a tabby cat",
"astronaut": "a portrait of an astronaut with the American flag",
"rocket": "a rocket standing on a launchpad",
"motorcycle_right": "a red motorcycle standing in a garage",
"camera": "a person looking at a camera on a tripod",
"horse": "a black-and-white silhouette of a horse",
"coffee": "a cup of coffee on a saucer"
}original_images = []
images = []
texts = []
plt.figure(figsize=(16, 5))
for filename in [filename for filename in os.listdir(skimage.data_dir) if filename.endswith(".png") or filename.endswith(".jpg")]:
name = os.path.splitext(filename)[0]
if name not in descriptions:
continue
image = Image.open(os.path.join(skimage.data_dir, filename)).convert("RGB")
plt.subplot(2, 4, len(images) + 1)
plt.imshow(image)
plt.title(f"{filename}n{descriptions[name]}")
plt.xticks([])
plt.yticks([])
original_images.append(image)
images.append(preprocess(image))
texts.append(descriptions[name])
plt.tight_layout()結果の視覚化は次のとおりです:

画像を正規化し、各テキスト入力にラベルを付け、モデルの順方向伝播を実行します。テキストのイメージと特徴を取得します。
image_input = torch.tensor(np.stack(images)).cuda() text_tokens = clip.tokenize(["This is " + desc for desc in texts]).cuda() with torch.no_grad():
特徴を正規化し、各ペアのドット積を計算し、コサイン類似度計算を実行します
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
count = len(descriptions)
plt.figure(figsize=(20, 14))
plt.imshow(similarity, vmin=0.1, vmax=0.3)
# plt.colorbar()
plt.yticks(range(count), texts, fontsize=18)
plt.xticks([])
for i, image in enumerate(original_images):
plt.imshow(image, extent=(i - 0.5, i + 0.5, -1.6, -0.6), origin="lower")
for x in range(similarity.shape[1]):
for y in range(similarity.shape[0]):
plt.text(x, y, f"{similarity[y, x]:.2f}", ha="center", va="center", size=12)
for side in ["left", "top", "right", "bottom"]:
plt.gca().spines[side].set_visible(False)
plt.xlim([-0.5, count - 0.5])
plt.ylim([count + 0.5, -2])
plt.title("Cosine similarity between text and image features", size=20)
ゼロサンプル画像分類
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
plt.figure(figsize=(16, 16))
for i, image in enumerate(original_images):
plt.subplot(4, 4, 2 * i + 1)
plt.imshow(image)
plt.axis("off")
plt.subplot(4, 4, 2 * i + 2)
y = np.arange(top_probs.shape[-1])
plt.grid()
plt.barh(y, top_probs[i])
plt.gca().invert_yaxis()
plt.gca().set_axisbelow(True)
plt.yticks(y, [cifar100.classes[index] for index in top_labels[i].numpy()])
plt.xlabel("probability")
plt.subplots_adjust(wspace=0.5)
plt.show()
分類効果が依然として非常に優れていることがわかります。
以上がPyTorch を使用した少数ショット学習による画像分類の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7487
7487
 15
1377
52
77
11
19
39
15
1377
52
77
11
19
39

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
平たく言えば、機械学習モデルは、入力データを予測された出力にマッピングする数学関数です。より具体的には、機械学習モデルは、予測出力と真のラベルの間の誤差を最小限に抑えるために、トレーニング データから学習することによってモデル パラメーターを調整する数学関数です。機械学習には、ロジスティック回帰モデル、デシジョン ツリー モデル、サポート ベクター マシン モデルなど、多くのモデルがあります。各モデルには、適用可能なデータ タイプと問題タイプがあります。同時に、異なるモデル間には多くの共通点があったり、モデル進化の隠れた道が存在したりすることがあります。コネクショニストのパーセプトロンを例にとると、パーセプトロンの隠れ層の数を増やすことで、それをディープ ニューラル ネットワークに変換できます。パーセプトロンにカーネル関数を追加すると、SVM に変換できます。これです
 学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
この記事では、学習曲線を通じて機械学習モデルの過学習と過小学習を効果的に特定する方法を紹介します。過小適合と過適合 1. 過適合 モデルがデータからノイズを学習するためにデータ上で過学習されている場合、そのモデルは過適合していると言われます。過学習モデルはすべての例を完璧に学習するため、未確認の新しい例を誤って分類してしまいます。過適合モデルの場合、完璧/ほぼ完璧なトレーニング セット スコアとひどい検証セット/テスト スコアが得られます。若干修正: 「過学習の原因: 複雑なモデルを使用して単純な問題を解決し、データからノイズを抽出します。トレーニング セットとしての小さなデータ セットはすべてのデータを正しく表現できない可能性があるため、2. 過学習の Heru。」
 宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
1950 年代に人工知能 (AI) が誕生しました。そのとき、研究者たちは、機械が思考などの人間と同じようなタスクを実行できることを発見しました。その後、1960 年代に米国国防総省は人工知能に資金を提供し、さらなる開発のために研究所を設立しました。研究者たちは、宇宙探査や極限環境での生存など、多くの分野で人工知能の応用を見出しています。宇宙探査は、地球を超えた宇宙全体を対象とする宇宙の研究です。宇宙は地球とは条件が異なるため、極限環境に分類されます。宇宙で生き残るためには、多くの要素を考慮し、予防策を講じる必要があります。科学者や研究者は、宇宙を探索し、あらゆるものの現状を理解することが、宇宙の仕組みを理解し、潜在的な環境危機に備えるのに役立つと信じています。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
