

PySpark ML を使用して機械学習モデルを構築する

Spark は、対話型クエリ、機械学習、およびリアルタイム ワークロード用に設計されたオープン ソース フレームワークであり、PySpark は Spark を使用する Python 用のライブラリです。
PySpark は、探索的データ分析を大規模に実行し、機械学習パイプラインを構築し、データ プラットフォーム用の ETL を作成するための優れた言語です。すでに Python や Pandas などのライブラリに精通している場合、PySpark は学習し、よりスケーラブルな分析やパイプラインを作成するのに最適な言語です。
この記事の目的は、PySpark を使用して機械学習モデルを構築する方法を示すことです。
Conda は Python 仮想環境を作成します
Conda は、Python や conda 自体も含め、ほとんどすべてのツールとサードパーティのパッケージをパッケージとして管理します。 Anaconda はパッケージ化されたコレクションであり、conda、特定のバージョンの Python、さまざまなパッケージなどがプリインストールされています。
1. Anaconda をインストールします。
コマンド ラインを開いて conda -V と入力し、インストールされているかどうかと現在の conda バージョンを確認します。
Anaconda を介して Python のデフォルト バージョンをインストールします。3.6 は Anaconda3 ~ 5.2 に対応し、5.3 以降は Python 3.7 です。
(https://repo.anaconda.com/archive/)
2. 一般的に使用される conda コマンド
1) どのパッケージがインストールされているかを確認する
conda list
2) 現在存在する仮想環境を確認します
conda env list <br>conda info -e
3) 現在の conda を確認して更新します
conda update conda
3. Python は仮想環境を作成します
conda create -n your_env_name python=x.x
anaconda コマンドはx.x の Python バージョン、 your_env_name という名前の仮想環境。 your_env_name ファイルは、Anaconda インストール ディレクトリの envs ファイルの下にあります。
4. 仮想環境のアクティブ化または切り替え
コマンド ラインを開いて python --version と入力し、現在の Python バージョンを確認します。
Linux:source activate your_env_nam<br>Windows: activate your_env_name
5. 仮想環境に追加のパッケージをインストールします
conda install -n your_env_name [package]
6. 仮想環境を閉じます
(つまり、現在の環境を終了し、デフォルトの Python バージョンの使用に戻ります) PATH環境内)
deactivate env_name<br># 或者`activate root`切回root环境<br>Linux下:source deactivate
7.仮想環境の削除
conda remove -n your_env_name --all
8.環境クロックのパッケージ削除
conda remove --name $your_env_name$package_name
9.国内ミラーの設定
http:/ /Anaconda.org のサーバーは海外にあるため、複数のパッケージをインストールすると、conda のダウンロード速度が非常に遅くなることがよくあります。 Tsinghua TUNA ミラー ソースには Anaconda ウェアハウスのミラーがあり、それを conda 構成に追加するだけです:
# 添加Anaconda的TUNA镜像<br>conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/<br><br># 设置搜索时显示通道地址<br>conda config --set show_channel_urls yes
10. デフォルトのミラーを復元します
conda config --remove-key channels
PySpark のインストール
PySpark のインストールプロセス 他の Python パッケージ (Pandas、Numpy、scikit-learn など) と同じくらい単純です。
重要なことの 1 つは、まず Java がマシンにインストールされていることを確認することです。その後、jupyter ノートブックで PySpark を実行できます。

データの探索
国立糖尿病・消化器・腎臓病研究所の糖尿病データセットを使用します。分類の目標は、患者が糖尿病であるかどうか (はい/いいえ) を予測することです。
from pyspark.sql import SparkSession<br>spark = SparkSession.builder.appName('ml-diabetes').getOrCreate()<br>df = spark.read.csv('diabetes.csv', header = True, inferSchema = True)<br>df.printSchema()データセットは、いくつかの医療予測変数とターゲット変数「結果」で構成されます。予測変数には、患者の妊娠数、BMI、インスリンレベル、年齢などが含まれます。
- 妊娠: 妊娠数
- グルコース: 2 時間以内の経口ブドウ糖負荷試験中の血糖濃度
- 血圧: 拡張期血圧 (mm Hg)
- SkinThickness: 上腕三頭筋の皮膚のひだの厚さ (mm)
- インスリン: 2 時間血清インスリン (μ U/ml)
- BMI: BMI: BMI (体重単位 kg/(身長)単位 m) )²)
- diabespedigreefunction: 糖尿病血統関数
- Age: 年齢 (年)
- 結果: クラス変数 (0 または 1)
- 入力変数: グルコース、血圧、BMI、年齢、妊娠、インスリン、皮膚の厚さ、糖尿病スペクトラム関数。
- 出力変数: 結果。
最初の 5 つの観察を見てください。 Pandas データフレームは、Spark DataFrame.show() よりも優れています。
import pandas as pd<br>pd.DataFrame(df.take(5), <br> columns=df.columns).transpose()
PySpark では、Pandas の DataFrame toPandas() を使用してデータを表示できます。
df.toPandas()

クラスのバランスが完全に取れていることを確認してください。
df.groupby('Outcome').count().toPandas()
記述統計
numeric_features = [t[0] for t in df.dtypes if t[1] == 'int']<br>df.select(numeric_features)<br>.describe()<br>.toPandas()<br>.transpose()
独立変数間の相関関係
from pandas.plotting import scatter_matrix<br>numeric_data = df.select(numeric_features).toPandas()<br><br>axs = scatter_matrix(numeric_data, figsize=(8, 8));<br><br># Rotate axis labels and remove axis ticks<br>n = len(numeric_data.columns)<br>for i in range(n):<br>v = axs[i, 0]<br>v.yaxis.label.set_rotation(0)<br>v.yaxis.label.set_ha('right')<br>v.set_yticks(())<br>h = axs[n-1, i]<br>h.xaxis.label.set_rotation(90)<br>h.set_xticks(())
データ準備と特徴エンジニアリング
このパートでは、不要な列を削除し、欠落している値を埋めます。最後に、機械学習モデルの特徴が選択されます。これらの機能は、トレーニングとテストの 2 つの部分に分かれています。
欠損データの処理
from pyspark.sql.functions import isnull, when, count, col<br>df.select([count(when(isnull(c), c)).alias(c)<br> for c in df.columns]).show()
このデータ セットは優れており、欠損値はありません。
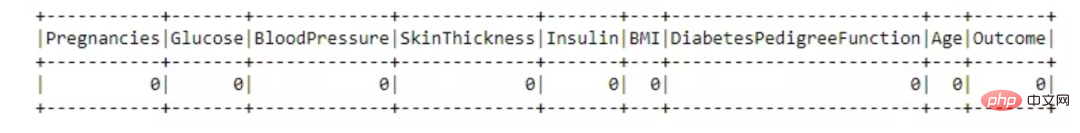
不必要的列丢弃
dataset = dataset.drop('SkinThickness')<br>dataset = dataset.drop('Insulin')<br>dataset = dataset.drop('DiabetesPedigreeFunction')<br>dataset = dataset.drop('Pregnancies')<br><br>dataset.show()
特征转换为向量
VectorAssembler —— 将多列合并为向量列的特征转换器。
# 用VectorAssembler合并所有特性<br>required_features = ['Glucose',<br>'BloodPressure',<br>'BMI',<br>'Age']<br><br>from pyspark.ml.feature import VectorAssembler<br><br>assembler = VectorAssembler(<br>inputCols=required_features, <br>outputCol='features')<br><br>transformed_data = assembler.transform(dataset)<br>transformed_data.show()
现在特征转换为向量已完成。
训练和测试拆分
将数据随机分成训练集和测试集,并设置可重复性的种子。
(training_data, test_data) = transformed_data.randomSplit([0.8,0.2], seed =2020)<br>print("训练数据集总数: " + str(training_data.count()))<br>print("测试数据集总数: " + str(test_data.count()))训练数据集总数:620<br>测试数据集数量:148
机器学习模型构建
随机森林分类器
随机森林是一种监督学习算法,用于分类和回归。但是,它主要用于分类问题。众所周知,森林是由树木组成的,树木越多,森林越茂盛。类似地,随机森林算法在数据样本上创建决策树,然后从每个样本中获取预测,最后通过投票选择最佳解决方案。这是一种比单个决策树更好的集成方法,因为它通过对结果进行平均来减少过拟合。
from pyspark.ml.classification import RandomForestClassifier<br><br>rf = RandomForestClassifier(labelCol='Outcome', <br>featuresCol='features',<br>maxDepth=5)<br>model = rf.fit(training_data)<br>rf_predictions = model.transform(test_data)
评估随机森林分类器模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', metricName = 'accuracy')<br>print('Random Forest classifier Accuracy:', multi_evaluator.evaluate(rf_predictions))Random Forest classifier Accuracy:0.79452
决策树分类器
决策树被广泛使用,因为它们易于解释、处理分类特征、扩展到多类分类设置、不需要特征缩放,并且能够捕获非线性和特征交互。
from pyspark.ml.classification import DecisionTreeClassifier<br><br>dt = DecisionTreeClassifier(featuresCol = 'features',<br>labelCol = 'Outcome',<br>maxDepth = 3)<br>dtModel = dt.fit(training_data)<br>dt_predictions = dtModel.transform(test_data)<br>dt_predictions.select('Glucose', 'BloodPressure', <br>'BMI', 'Age', 'Outcome').show(10)评估决策树模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', <br>metricName = 'accuracy')<br>print('Decision Tree Accuracy:', <br>multi_evaluator.evaluate(dt_predictions))Decision Tree Accuracy: 0.78767
逻辑回归模型
逻辑回归是在因变量是二分(二元)时进行的适当回归分析。与所有回归分析一样,逻辑回归是一种预测分析。逻辑回归用于描述数据并解释一个因二元变量与一个或多个名义、序数、区间或比率水平自变量之间的关系。当因变量(目标)是分类时,使用逻辑回归。
from pyspark.ml.classification import LogisticRegression<br><br>lr = LogisticRegression(featuresCol = 'features', <br>labelCol = 'Outcome', <br>maxIter=10)<br>lrModel = lr.fit(training_data)<br>lr_predictions = lrModel.transform(test_data)
评估我们的逻辑回归模型。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Logistic Regression Accuracy:', <br>multi_evaluator.evaluate(lr_predictions))Logistic Regression Accuracy:0.78767
梯度提升树分类器模型
梯度提升是一种用于回归和分类问题的机器学习技术,它以弱预测模型(通常是决策树)的集合形式生成预测模型。
from pyspark.ml.classification import GBTClassifier<br>gb = GBTClassifier(<br>labelCol = 'Outcome', <br>featuresCol = 'features')<br>gbModel = gb.fit(training_data)<br>gb_predictions = gbModel.transform(test_data)
评估我们的梯度提升树分类器。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Gradient-boosted Trees Accuracy:',<br>multi_evaluator.evaluate(gb_predictions))Gradient-boosted Trees Accuracy:0.80137
结论
PySpark 是一种非常适合数据科学家学习的语言,因为它支持可扩展的分析和 ML 管道。如果您已经熟悉 Python 和 Pandas,那么您的大部分知识都可以应用于 Spark。总而言之,我们已经学习了如何使用 PySpark 构建机器学习应用程序。我们尝试了三种算法,梯度提升在我们的数据集上表现最好。
以上がPySpark ML を使用して機械学習モデルを構築するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7517
7517
 15
1378
52
79
11
21
66
15
1378
52
79
11
21
66

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
平たく言えば、機械学習モデルは、入力データを予測された出力にマッピングする数学関数です。より具体的には、機械学習モデルは、予測出力と真のラベルの間の誤差を最小限に抑えるために、トレーニング データから学習することによってモデル パラメーターを調整する数学関数です。機械学習には、ロジスティック回帰モデル、デシジョン ツリー モデル、サポート ベクター マシン モデルなど、多くのモデルがあります。各モデルには、適用可能なデータ タイプと問題タイプがあります。同時に、異なるモデル間には多くの共通点があったり、モデル進化の隠れた道が存在したりすることがあります。コネクショニストのパーセプトロンを例にとると、パーセプトロンの隠れ層の数を増やすことで、それをディープ ニューラル ネットワークに変換できます。パーセプトロンにカーネル関数を追加すると、SVM に変換できます。これです
 学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
この記事では、学習曲線を通じて機械学習モデルの過学習と過小学習を効果的に特定する方法を紹介します。過小適合と過適合 1. 過適合 モデルがデータからノイズを学習するためにデータ上で過学習されている場合、そのモデルは過適合していると言われます。過学習モデルはすべての例を完璧に学習するため、未確認の新しい例を誤って分類してしまいます。過適合モデルの場合、完璧/ほぼ完璧なトレーニング セット スコアとひどい検証セット/テスト スコアが得られます。若干修正: 「過学習の原因: 複雑なモデルを使用して単純な問題を解決し、データからノイズを抽出します。トレーニング セットとしての小さなデータ セットはすべてのデータを正しく表現できない可能性があるため、2. 過学習の Heru。」
 宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
1950 年代に人工知能 (AI) が誕生しました。そのとき、研究者たちは、機械が思考などの人間と同じようなタスクを実行できることを発見しました。その後、1960 年代に米国国防総省は人工知能に資金を提供し、さらなる開発のために研究所を設立しました。研究者たちは、宇宙探査や極限環境での生存など、多くの分野で人工知能の応用を見出しています。宇宙探査は、地球を超えた宇宙全体を対象とする宇宙の研究です。宇宙は地球とは条件が異なるため、極限環境に分類されます。宇宙で生き残るためには、多くの要素を考慮し、予防策を講じる必要があります。科学者や研究者は、宇宙を探索し、あらゆるものの現状を理解することが、宇宙の仕組みを理解し、潜在的な環境危機に備えるのに役立つと信じています。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
