

Xishanju AI 技術専門家 Huang Honbo 氏: ゲームにおける強化学習と動作ツリーの実践的な統合

2022 年 8 月 6 日と 7 日、 AISummit グローバル人工知能技術カンファレンス は予定通り開催されます。 7日午後に開催された「人工知能フロンティア探索」サブフォーラムでは、西山州のAI技術専門家である黄紅波氏が「ゲームにおける強化学習と行動ツリーの実践的な組み合わせ」をテーマに、詳細を共有した。ゲーム分野における強化学習の影響。
Huang Honbo 氏は、強化学習テクノロジーの実装は、アルゴリズムをより強力にするために変更することではなく、強化学習テクノロジーを深層学習およびゲーム プランニングと組み合わせて、完全なソリューション セットを形成し、それを実現することにあると述べました。起こる。
強化学習によりゲームがよりスマートになります
ゲームに強化学習を実装すると、ゲームがよりスマートになり、よりプレイしやすくなります。これが強化学習を使用する主な目的です。ゲームで。
「強化学習は、一連の意思決定ができるようにエージェントの戦略を訓練する機械学習パラダイムです。」 ファン・ホンボ氏は、エージェントの目的は環境の観察に基づいてアクションを出力することであると述べました。これらのアクションは、より多くの観察と報酬につながります。トレーニングでは、エージェントが環境と対話する際に多くの試行錯誤が必要となり、反復ごとに戦略を改善できます。
ゲームでは、アクションを実行したり、動作を実行したりするエージェントがゲーム エージェントです。ゲーム内のキャラクターやロボットを考えてみましょう。ゲームの状態、つまりプレイヤーがどこにいるのかを理解し、その観察に基づいてゲームの状況に基づいて意思決定を行う必要があります。強化学習では、意思決定は報酬によって決まります。報酬はゲーム内でハイスコアとして提供されたり、特定の目標を達成するために新しいレベルに到達したりすることで提供されます。
Huang Honbo 氏は、この試合の状況で最も素晴らしい点は、エージェントの戦略が試合のプレッシャーの下で訓練されていることだと述べました。たとえば、攻撃に対処する方法や、特定の目標を達成するためにどのように行動するかを学習することができます。
ゲームにおけるビヘイビア ツリーの役割
ビヘイビア ツリーは、論理ノードとビヘイビア ノードを含むツリー構造です。通常、各状況をノードのタイプに抽象化し、仕様に従ってノードを記述し、これらのノードをツリーに接続します。ユーザーが動作を検索するたびに、ツリーのルート ノードから開始して、各ノードの現在のデータと一致する動作を見つけます。
簡単に言うと、各AIモジュールの結合度が高く粒度が大きい場合、変更箇所が多くなり、重複コードが大量に発生しやすくなります。 。ビヘイビア ツリーの出現により、大多数のゲーム開発者にとって「正方形のノートブック」が提供され、AI 開発者は再利用可能で拡張と保守が容易な一連の AI フレームワークをより便利に構築できるようになりました。強化学習はトレーニングによって得られるものであり、動作ツリーはいくつかの else ステートメントと if ステートメントの組み合わせであると言えます。
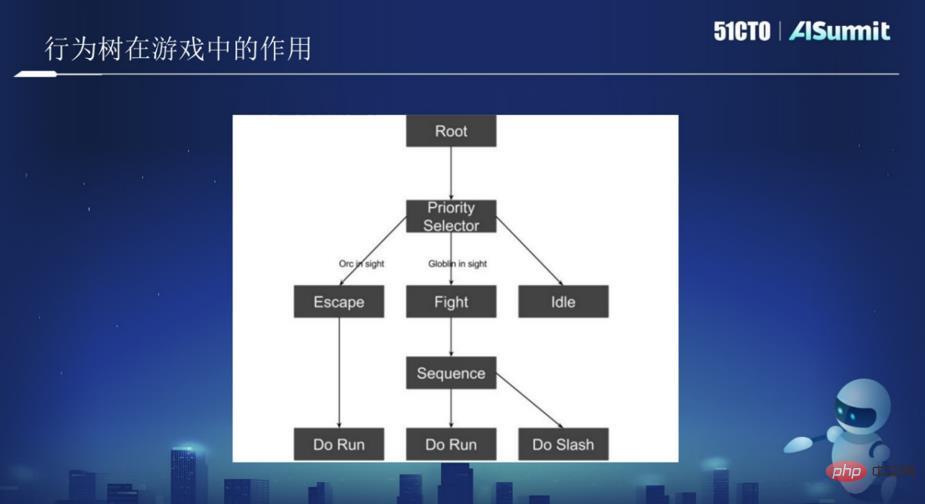
上の図のように、図の中にルートノードがあり、その下にツリーノードがあり、ツリーノードには脱出、攻撃、徘徊などが含まれます。 。上の写真を AI またはロボットとして考えて、ジャングルを巡回させてください。 AIがORCオークを見てORCを倒すことができないと判断した場合、この条件が発動するとAIは逃走し、逃走時にRunアクションを実行します。戦いやすいと判断した場合はファイト操作が行われます。
上の図には 2 つのノードがあり、1 つはルート ノードである Root、もう 1 つは論理ノードである Selector ノードです。すべてのノードが左から右へ特定の順序で実行される、これがビヘイビア ツリーです。したがって、各ノードに対応するロジックを記述するだけで、AI がいくつかの関連アクションを実行できるようになります。いくつかのビヘイビア ツリーが最終的にゲームを形成します。
強化学習とビヘイビア ツリーの組み合わせによりゲームがよりリッチになります
強化学習とビヘイビア ツリーを組み合わせてゲームをよりリッチにするにはどうすればよいでしょうか?これは多くのゲームで議論される必要がある難しいアプリケーションです。
その前に、いつ強化学習を使用するのが良いのか、またどのような状況でビヘイビアツリーを使用するのが良いのかについて議論したほうが良いかもしれません。黄紅波氏は、ビヘイビアツリーを使って目標を達成する方法がない場合は、強化学習を利用すればよいと述べ、例えばFPS(一人称視点シューティングゲーム)において、どのくらいの火力を使うべきか、誰にどのような射撃をすべきかなどを検討することができると述べた。ビヘイビア ツリーを通じて意思決定を行うのはより困難であるため、一般的には強化学習を使用する方が良いと考えられます。
ビヘイビア ツリーをいつ使用するか?たとえば、ゲーム内で障害物に遭遇し、それを飛び越える必要がある場合、強化学習を使用してそれを実行するか、ビヘイビア ツリーを使用してそれを実行するかを選択できます。しかし、それを強化学習でやろうとすると、訓練が非常に面倒になります。この状況ではオプションはスキップする 1 つだけであるため、ビヘイビア ツリーを使用する方が簡単です。
強化学習とビヘイビアツリーを組み合わせてゲームに使用すれば、より良いソリューションであることを見つけるのは難しくありません。 Huang Honbo 氏は、強化学習とビヘイビア ツリーを組み合わせる比較的大規模な実装方法が 2 つあると述べました: 1 つは強化学習に基づいてビヘイビア ツリーによって補足されるもの、もう 1 つはビヘイビア ツリーに基づいて強化学習によって補足されるものです。
ビヘイビア ツリー側: ビヘイビア ツリーを主な AI 移動方法として使用すると、ビヘイビア ツリーはゲーム クライアントからの obs 入力を受け取り、自身のターゲット状況に応じて obs に対応するビヘイビア ツリーの動作を書き込みます。ビヘイビア ツリーの各動作では、意思決定に強化学習が必要ないくつかのノードが強化学習に引き渡され、ここで強化学習は、いくつかの特定のシナリオに対応するトレーニングを実行する必要があります。
強化学習側: 全体的な戦略は、複数のモデルをトレーニングすることになり、各モデルは戦略を実行し、その後、動作ツリーに埋め込まれます。
Huang Honbo 氏は、これら 2 つの異なる実装方法のうち、どちらが優れているかは、さまざまな状況、さまざまなアプリケーション、さまざまなゲームに基づいてさまざまな考慮が必要なため、一般化することはできないと述べました。
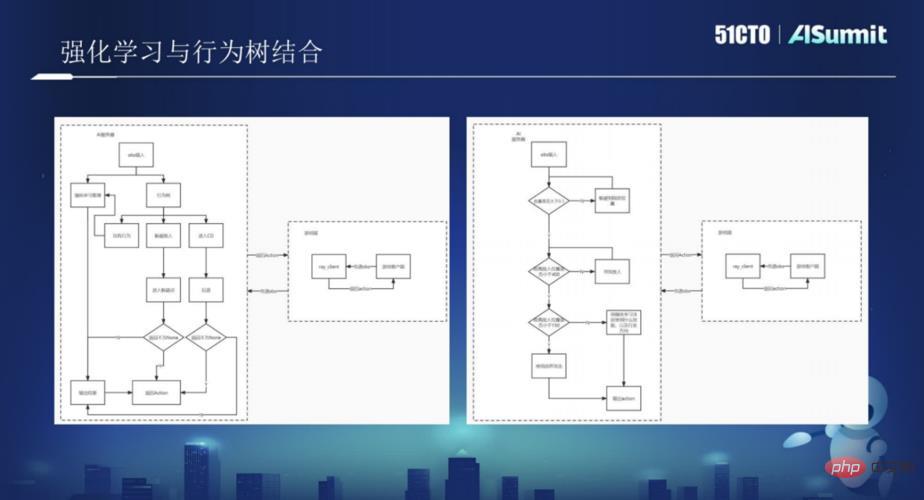
次回は、黄紅波氏が、Xishanju が強化学習と動作ツリーで採用した技術フレームワークを、「詳細 ビヘイビアー ツリーと強化学習をゲーム内で組み合わせて、ゲームをより豊かにする方法。事例の実践に興味のあるユーザーは、AISummit グローバル人工知能技術カンファレンスの素晴らしい共有ビデオに注目するとよいでしょう。 (https://www.php.cn/link/53253027fef2ab5162a602f2acfed431)
以上がXishanju AI 技術専門家 Huang Honbo 氏: ゲームにおける強化学習と動作ツリーの実践的な統合の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7674
7674
 15
1393
52
1207
24
91
11
15
1393
52
1207
24
91
11

 強化学習における報酬関数設計の問題
Oct 09, 2023 am 11:58 AM
強化学習における報酬関数設計の問題
Oct 09, 2023 am 11:58 AM
強化学習における報酬関数設計の問題 はじめに 強化学習は、エージェントと環境の間の相互作用を通じて最適な戦略を学習する方法です。強化学習では、報酬関数の設計がエージェントの学習効果にとって重要です。この記事では、強化学習における報酬関数の設計の問題を調査し、具体的なコード例を示します。報酬関数の役割と目標報酬関数は強化学習の重要な部分であり、特定の状態でエージェントが取得する報酬値を評価するために使用されます。その設計は、エージェントが最適なアクションを選択することで長期的な疲労を最大化するようにガイドするのに役立ちます。
 C++ の深層強化学習テクノロジー
Aug 21, 2023 pm 11:33 PM
C++ の深層強化学習テクノロジー
Aug 21, 2023 pm 11:33 PM
深層強化学習技術は、人工知能の分野の一つとして大きな注目を集めており、複数の国際コンペティションで優勝しており、パーソナルアシスタント、自動運転、ゲームインテリジェンスなどの分野でも広く利用されています。深層強化学習を実現するプロセスにおいて、ハードウェア リソースが限られている場合、効率的で優れたプログラミング言語である C++ が特に重要になります。深層強化学習は、その名前が示すように、深層学習と強化学習の 2 つの分野のテクノロジーを組み合わせたものです。簡単に理解すると、ディープ ラーニングとは、多層のニューラル ネットワークを構築することでデータから特徴を学習し、意思決定を行うことを指します。
 Panda-Gym のロボット アーム シミュレーションを使用した Deep Q-learning 強化学習
Oct 31, 2023 pm 05:57 PM
Panda-Gym のロボット アーム シミュレーションを使用した Deep Q-learning 強化学習
Oct 31, 2023 pm 05:57 PM
強化学習 (RL) は、エージェントが試行錯誤を通じて環境内でどのように動作するかを学習できる機械学習手法です。エージェントは、望ましい結果につながるアクションを実行すると、報酬または罰を受けます。時間の経過とともに、エージェントは期待される報酬を最大化するアクションを取ることを学習します。RL エージェントは通常、逐次的な決定問題をモデル化するための数学的フレームワークであるマルコフ決定プロセス (MDP) を使用してトレーニングされます。 MDP は 4 つの部分で構成されます。 状態: 環境の可能な状態のセット。アクション: エージェントが実行できる一連のアクション。遷移関数: 現在の状態とアクションを考慮して、新しい状態に遷移する確率を予測する関数。報酬機能:コンバージョンごとにエージェントに報酬を割り当てる機能。エージェントの目標は、ポリシー機能を学習することです。
 Go 言語を使用して深層強化学習の研究を行うにはどうすればよいですか?
Jun 10, 2023 pm 02:15 PM
Go 言語を使用して深層強化学習の研究を行うにはどうすればよいですか?
Jun 10, 2023 pm 02:15 PM
深層強化学習(DeepReinforcementLearning)は、深層学習と強化学習を組み合わせた高度な技術で、音声認識、画像認識、自然言語処理などの分野で広く利用されています。 Go 言語は、高速、効率的、信頼性の高いプログラミング言語として、深層強化学習の研究に役立ちます。この記事では、Go言語を使用して深層強化学習の研究を行う方法を紹介します。 1. Go 言語と関連ライブラリをインストールし、深層強化学習に Go 言語の使用を開始します。
 Actor-Critic の DDPG 強化学習アルゴリズムを使用した二重関節ロボット アームの制御
May 12, 2023 pm 09:55 PM
Actor-Critic の DDPG 強化学習アルゴリズムを使用した二重関節ロボット アームの制御
May 12, 2023 pm 09:55 PM
この記事では、UnityML-Agents ツールキットを使用して開発された Unity ベースのシミュレーション プログラムである Reacher 環境で二重関節ロボット アームを制御するインテリジェント エージェントのトレーニングを紹介します。私たちの目標は、高精度でターゲット位置に到達することなので、ここでは、連続状態およびアクション空間用に設計された最先端の DeepDeterministicPolicyGradient (DDPG) アルゴリズムを使用できます。現実世界のアプリケーション ロボット アームは、製造、生産施設、宇宙探査、捜索救助活動において重要な役割を果たします。ロボットアームを高精度かつ柔軟に制御することが非常に重要です。強化学習技術を採用することで、これらのロボット システムはリアルタイムで動作を学習し、調整できるようになります。
 強化学習のもう一つの革命! DeepMind が提案する「アルゴリズム蒸留」: 探索可能な事前トレーニング済み強化学習 Transformer
Apr 12, 2023 pm 06:58 PM
強化学習のもう一つの革命! DeepMind が提案する「アルゴリズム蒸留」: 探索可能な事前トレーニング済み強化学習 Transformer
Apr 12, 2023 pm 06:58 PM
現在のシーケンス モデリング タスクにおいて、Transformer は最も強力なニューラル ネットワーク アーキテクチャであると言えます。また、事前トレーニングされた Transformer モデルは、プロンプトを条件として使用したり、コンテキスト内学習を使用して、さまざまな下流タスクに適応したりできます。大規模な事前トレーニング済み Transformer モデルの汎化能力は、テキスト補完、言語理解、画像生成などの複数の分野で検証されています。昨年以来、オフライン強化学習 (オフライン RL) をシーケンス予測問題として扱うことで、モデルがオフライン データからポリシーを学習できることを証明する関連研究が行われてきました。しかし、現在のアプローチは、学習を含まないデータからポリシーを学習するか、
 Kuaishou ユーザー維持率を向上させるために強化学習を使用する方法は?
May 07, 2023 pm 06:31 PM
Kuaishou ユーザー維持率を向上させるために強化学習を使用する方法は?
May 07, 2023 pm 06:31 PM
短編ビデオ レコメンデーション システムの中核的な目標は、ユーザー維持率を向上させて DAU の増加を促進することです。したがって、リテンションは各 APP の中核となるビジネス最適化指標の 1 つです。しかし、リテンションはユーザーとシステムの間の複数のインタラクションを経た長期的なフィードバックであり、それを単一の項目または単一のリストに分解することは困難であるため、従来のポイント単位とリストを使用してリテンションを直接最適化することは困難です。賢いモデルたち。強化学習 (RL) 手法は、環境と対話することで長期的な報酬を最適化し、ユーザー維持率を直接最適化するのに適しています。この研究では、保持最適化問題を、無限のホライズン要求粒度を備えたマルコフ決定プロセス (MDP) としてモデル化しています。ユーザーが推奨システムにアクションを決定するよう要求するたびに、複数の異なる短期フィードバック推定値 (視聴時間、視聴時間、
 20 分で回路基板の組み立てを学びましょう!オープンソースの SERL フレームワークは 100% の精度制御成功率を誇り、人間の 3 倍高速です
Feb 21, 2024 pm 03:31 PM
20 分で回路基板の組み立てを学びましょう!オープンソースの SERL フレームワークは 100% の精度制御成功率を誇り、人間の 3 倍高速です
Feb 21, 2024 pm 03:31 PM
現在、ロボットは精密な工場制御タスクを学習できるようになりました。近年、ロボットの強化学習技術の分野では、四足歩行や掴み、器用な操作など大きな進歩が見られますが、その多くは実験室での実証段階にとどまっています。ロボット強化学習テクノロジーを実際の運用環境に広く適用するには、依然として多くの課題があり、実際のシナリオでの適用範囲がある程度制限されます。強化学習技術の実用化の過程では、報酬メカニズムの設定、環境のリセット、サンプル効率の向上、行動の安全性の保証など、複数の複雑な問題を克服する必要があります。業界の専門家は、強化学習テクノロジーの実際の実装における多くの問題を解決することは、アルゴリズム自体の継続的な革新と同じくらい重要であると強調しています。この課題に直面して、カリフォルニア大学バークレー校、スタンフォード大学、ワシントン大学、および
