

Alipay の検索エクスペリエンスを向上させるために、Ant と北京大学は階層型比較学習テキスト生成フレームワークを使用しています

テキスト生成タスクは、通常、教師強制を使用してトレーニングされます。このトレーニング方法を使用すると、モデルはトレーニング プロセス中にポジティブなサンプルのみを確認できます。ただし、生成ターゲットと入力の間には通常、特定の制約があり、これらの制約は通常、文の主要な要素に反映されます。たとえば、クエリ書き換えタスクでは、「マクドナルドを注文」を「KFC を注文」に変更することはできません。抑制の重要な要素はブランドのキーワードです。対照学習を導入し、生成プロセスに負のサンプル パターンを追加することにより、モデルはこれらの制約を効果的に学習できます。
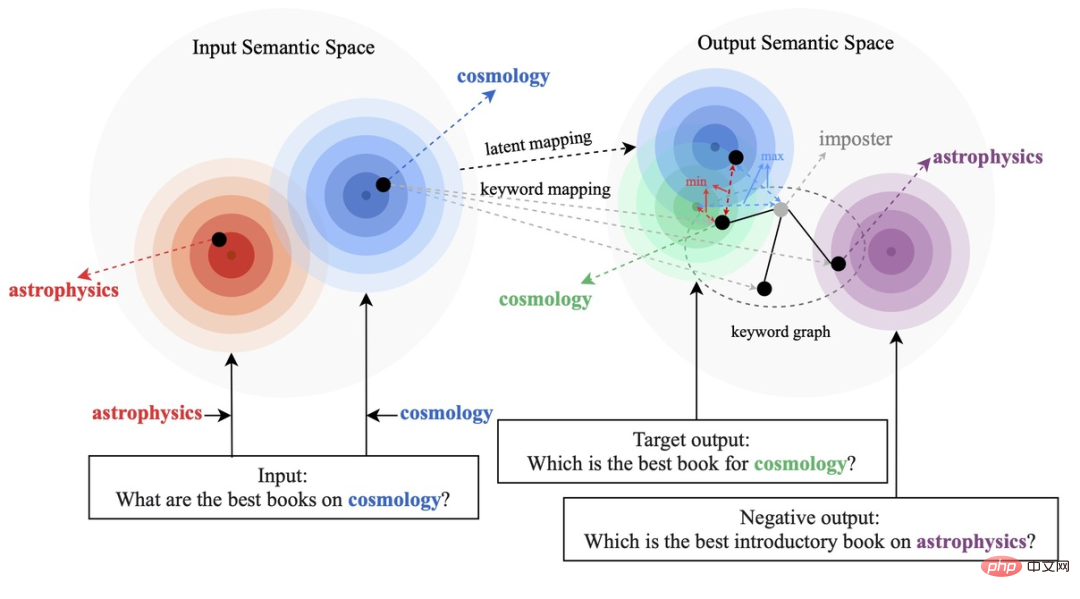
既存の比較学習方法は、主に文全体のレベル [1][2] に焦点を当てており、文内の単語単位のエンティティは無視されています。下図の例は、文中のキーワードの重要な意味を示しています。入力文の場合、そのキーワードが置き換えられると (例: 宇宙論 -> 天体物理学)、文の意味が変化するため、意味空間における ( の位置)分布で表される)も変化します。文内で最も重要な情報であるキーワードは、意味分布の点に対応し、文の分布の位置を大部分決定します。同時に、場合によっては、既存の対照的な学習目標がモデルにとって簡単すぎるため、モデルが肯定的な例と否定的な例の間の重要な情報を真に学習できなくなることがあります。
これに基づいて、Ant Group、北京大学などの研究者は、多粒度の比較生成方法を提案し、階層的な比較構造を設計しました。学習レベルで実行され、文の粒度で学習の全体的な意味論が強化され、単語の粒度で局所的な重要な情報が強化されます。研究論文がACL 2022に採択されました。

論文アドレス: https://aclanthology.org/2022.acl-long.304.pdf
メソッド
私たちのメソッドは古典的なものに基づいています。 CVAE テキスト生成フレームワーク [3][4] では、各文をベクトル空間の分布にマッピングすることができ、文内のキーワードをこの分布からサンプリングされた点とみなすことができます。文の粒度の比較を通じて潜在空間ベクトル分布の表現を強化する一方で、構築されたグローバルキーワードグラフを通じてキーワードポイントの粒度の表現を強化し、最後にマハラノビス距離を使用して比較します。キーワードポイントとセンテンスの分布 構成レベル間のコントラストにより、2 つの粒度で情報表現を強化します。最終的な損失関数は、3 つの異なる対照的な学習損失を追加することによって取得されます。
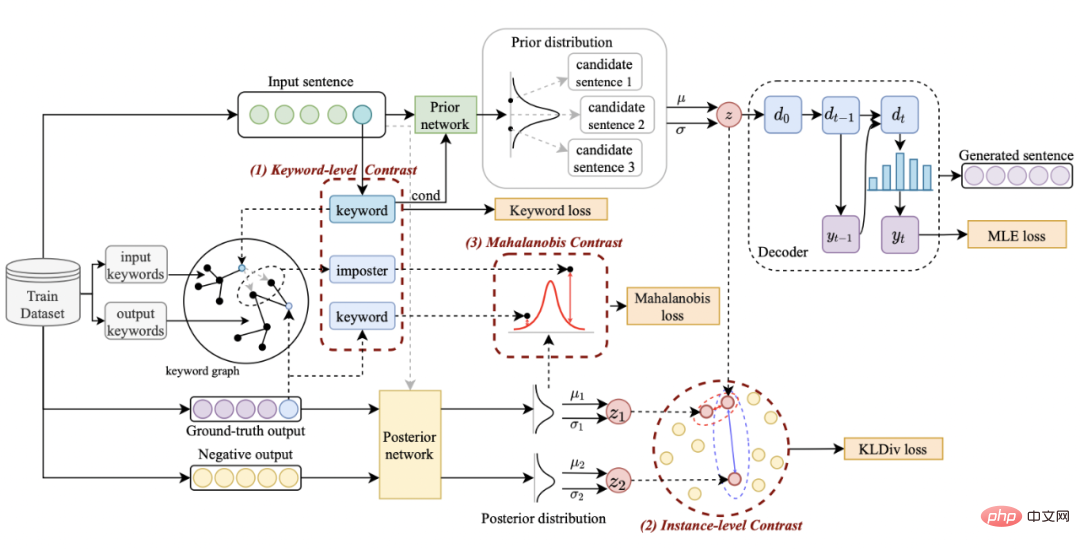
文の詳細な比較学習
atインスタンス レベルでは、元の入力 x、ターゲット出力

、および対応する出力負のサンプルを使用して、文の粒度 ペア
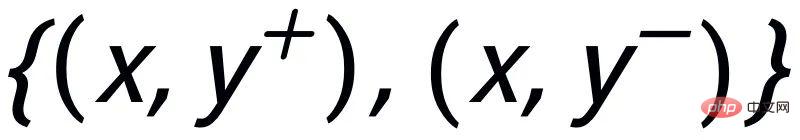
# を比較します。以前のネットワークを使用して、以前の分布
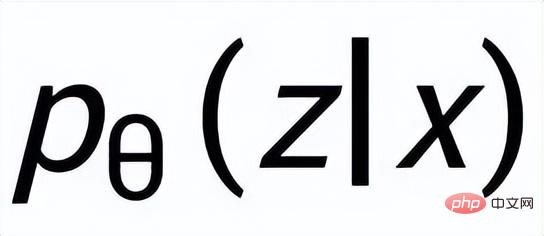
## ( ## として記録) を学習します。
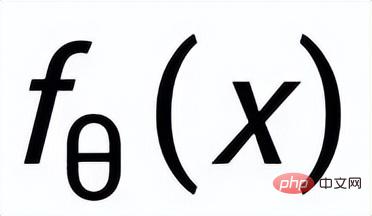
と
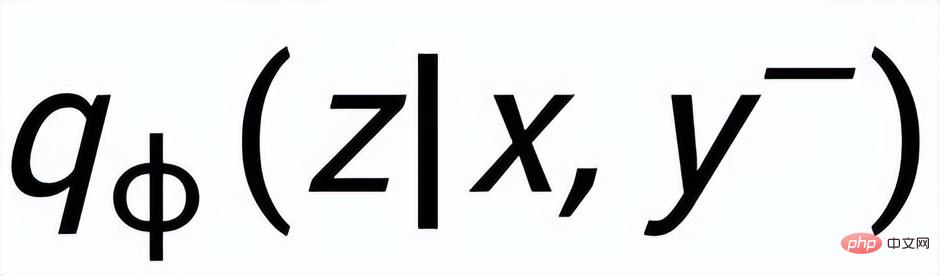
## はそれぞれ # として記録されます。 #################そして###########################。文粒度比較学習の目標は、事前分布と正の事後分布の間の距離をできる限り小さくすると同時に、事前分布と負の事後分布の間の距離を最大化することです。対応する損失関数は次のとおりです。次のようになります。
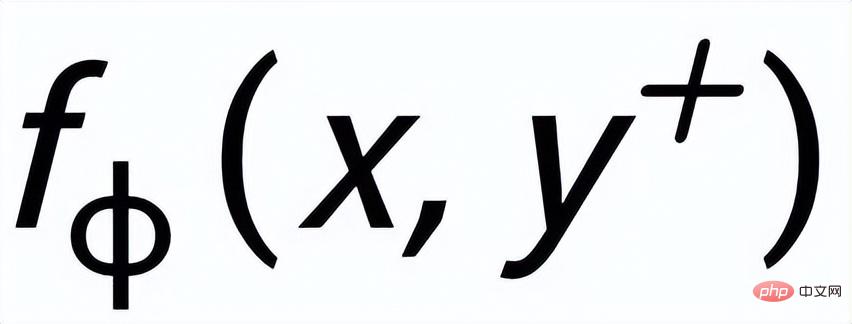
ここで、 は陽性サンプルまたは陰性サンプル、 は温度係数です。ここでは、KL ダイバージェンス (カルバック・ライブラーダイバージェンス)[5] を使用して、2 つの分布間の直接距離を測定します。
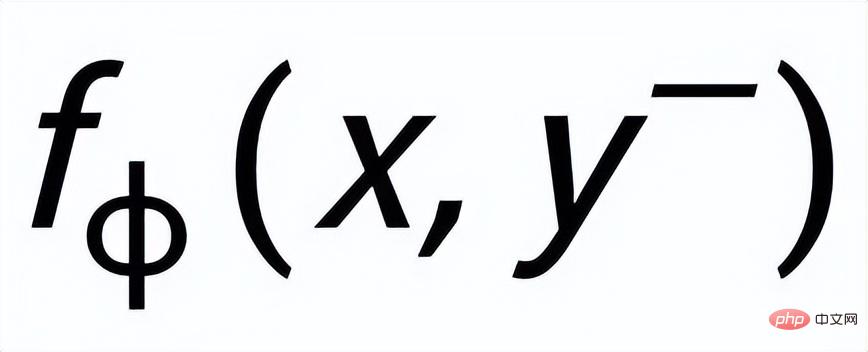
#キーワードの詳細な比較学習
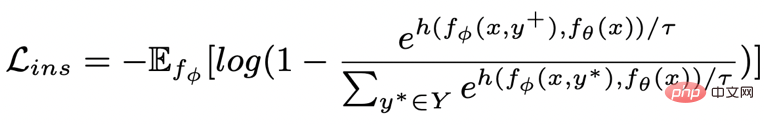
キーワード粒度の対照学習を使用して、モデルが文内の重要な情報にさらに注意を払うようにします。この目標を達成するために、出力テキストに対応する否定的な関係が構築されてキーワード グラフが構築されます。具体的には、与えられた文のペア
- # に従って、そこからキーワード ## をそれぞれ決定できます # #####################そして######################## ### (キーワード抽出には古典的な TextRank アルゴリズム [6] を使用します);
## という文には、他の文がある可能性があります。はキーワード

と同じであり、これらの文は集合
を形成します。
、この

#のすべての文は肯定的な出力例と否定的な出力文のペアです。

それぞれに肯定的なキーワードの例
# があります。 ##############################と除外キーワードの例
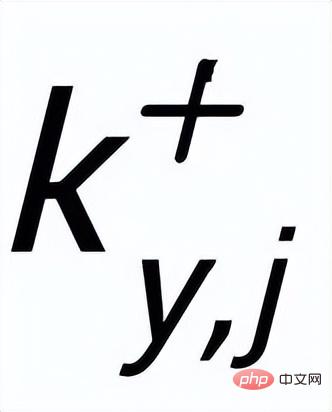
##。このようにして、コレクション全体で、任意の出力文

について、対応するキーワード # と見なすことができます。

## とその周囲のすべての

(文間の正と負の関係を通じて関連付けられている)
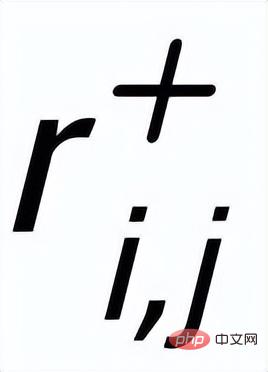
の間の正のエッジです。周囲の

# の間に負のエッジ ## があります
 。これらのキーワード ノードとその直接エッジに基づいて、キーワード グラフを構築できます
。これらのキーワード ノードとその直接エッジに基づいて、キーワード グラフを構築できます

各ノードの初期化として BERT embedding[7] を使用します
 、MLP 層を使用して学習します各エッジの表現
、MLP 層を使用して学習します各エッジの表現
#。グラフ アテンション (GAT) レイヤーと MLP レイヤーを通じて、キーワード ネットワーク内のノードとエッジを繰り返し更新します。各反復では、最初に次の方法でエッジ表現を更新します: 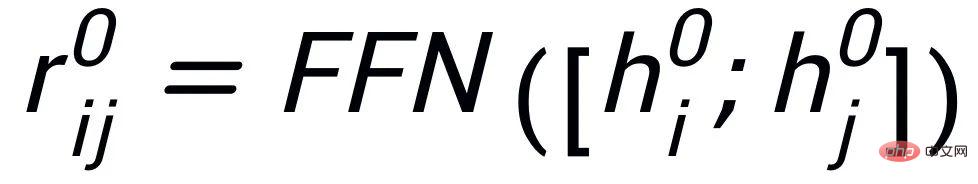
#ここで
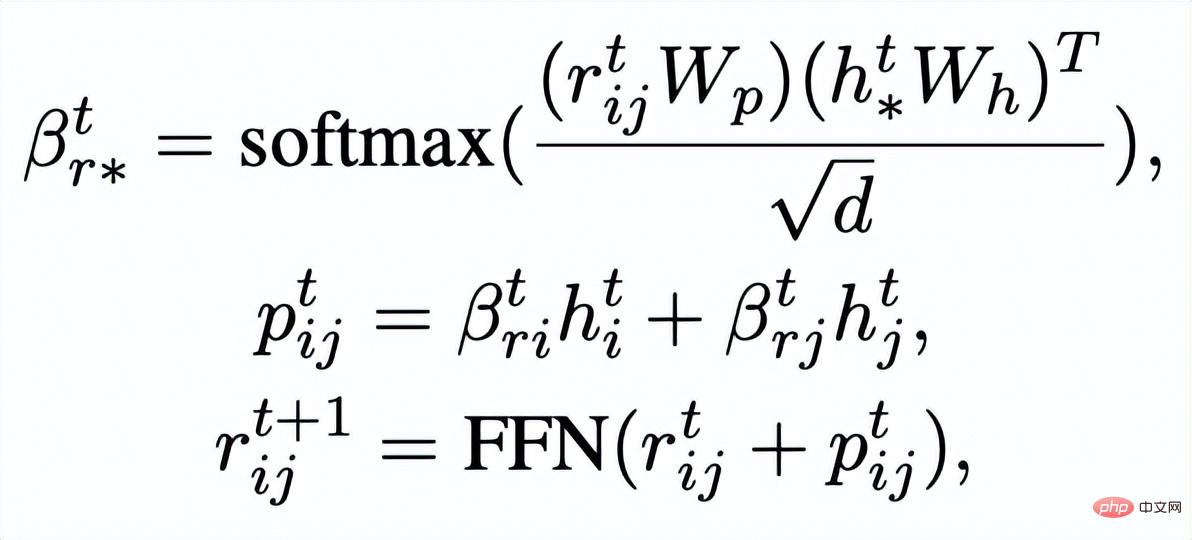
## は
になります。 #####################または######################## ###。 
次に、更新されたエッジに基づいて 

、グラフ アテンション レイヤーを通じて各ノードの表現を更新します。
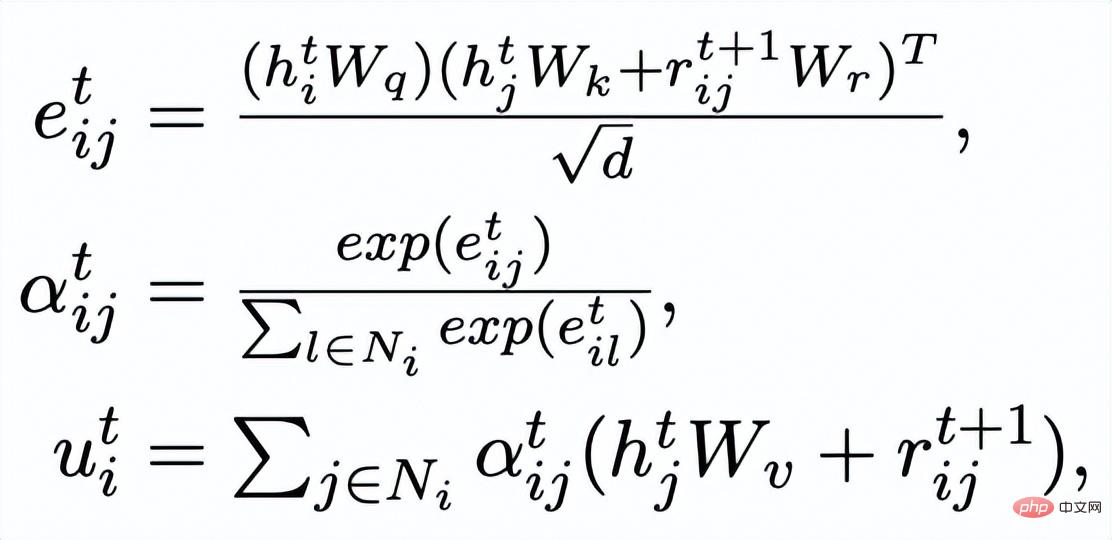
#ここで
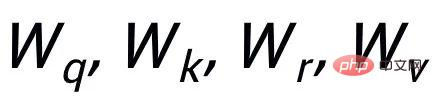
# はすべて学習可能なパラメータです。


# を取得しました。 ###########################最後の反復のノード表現をキーワードの表現として使用し、u として示します。
 #キーワード比較
#キーワード比較
- キーワード粒度の比較は、入力文のキーワード
から得られます。




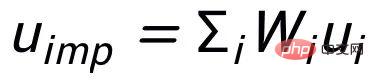 ## ここで、
## ここで、
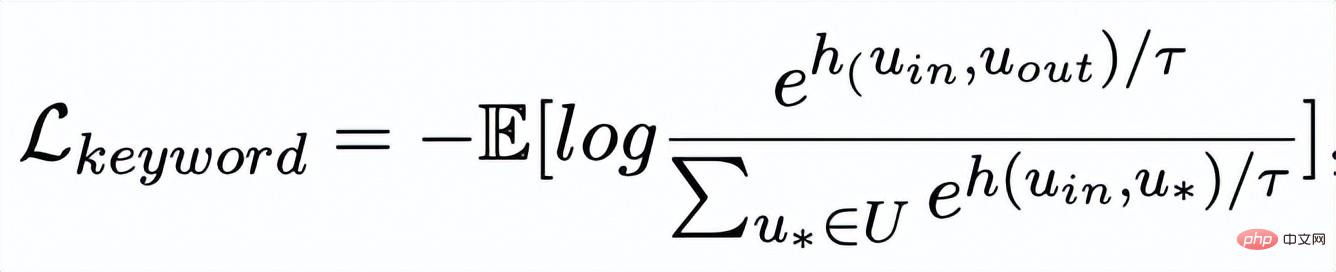 は
は
を参照するために使用されます。 ### #########または################## , h(・) は距離の尺度を表すために使用されます。キーワード粒度の比較学習では、コサイン類似度を選択して 2 点間の距離を計算します。 ## 上記の文粒度とキーワード粒度のコントラスト学習はそれぞれ分布とポイントで実装されるため、2 つの粒度を独立して比較すると、差が小さいため強調効果が弱まる可能性があることに注意してください。この点において、我々は、点と分布の間のマハラノビス距離 [8] に基づいて、異なる粒度間の比較関連を構築し、対象の出力キーワードと文の分布の間の距離が可能な限り小さくなり、偽者間の距離が小さくなるようにします。粒径を独立して比較するため、コントラストが消えてしまうという欠点を補い、その分布を可能な限り小さくしています。具体的には、クロス粒度マハラノビス距離対比学習は、文の事後意味分布を可能な限り狭めることを望んでいます。 との間の距離をできるだけ広げながら、
# を参照するためにも使用されます。
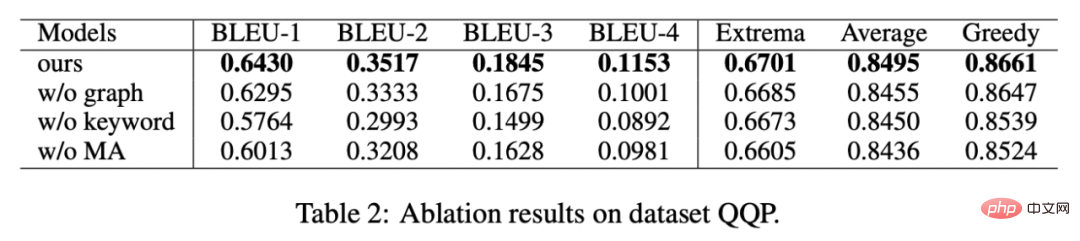
##、h(・) はマハラノビスです距離 。 #実験と分析 私たちは、Douban (対話) [9]、QQP (言い換え) [10][11]、RocStories (ストーリーテリング) [12] の 3 つの公開データセットで実験を行い、すべて SOTA 効果を達成しました。私たちが比較するベースラインには、従来の生成モデル (例: CVAE[13]、Seq2Seq[14]、Transformer[15])、事前トレーニング済みモデルに基づく手法 (例: Seq2Seq-DU[16]、DialoGPT[17]、BERT-GEN) が含まれます。 [7]、T5[18])および対照学習に基づく方法(例:グループごと[9]、T5-CLAPS[19])。自動評価指標として、BLEU スコア[20]と文ペア間の BOW 埋め込み距離 (極値/平均/貪欲)[21]を計算し、その結果を次の図に示します。 キーワードを使用するかどうか、キーワードネットワークを使用するかどうか、マハラノビス距離を使用するかどうかを分析しました。アブレーション解析実験が実施され、その結果、これら 3 つの設計が最終結果において重要な役割を果たしていることがわかりました。実験結果を下の図に示します。 階層的対照学習の役割に関して、ランダムにサンプリングされたケースを視覚化し、t-sne による次元削減後に次の図を得ました [22]。この図から、入力文の表現は抽出されたキーワードの表現に近いことがわかり、文中の最も重要な情報としてのキーワードが通常、意味分布の位置を決定することがわかります。さらに、対照学習では、トレーニング後、入力文の分布が正のサンプルに近づき、負のサンプルから遠ざかることがわかります。これは、対照学習が意味分布の修正に役立つことを示しています。 最後に、さまざまなキーワードをサンプリングすることの影響を調査します。以下の表に示すように、入力された質問に対して、TextRank抽出法とランダム選択法により意味分布を制御するための条件としてキーワードを与え、生成されたテキストの品質をチェックします。キーワードは文の中で最も重要な情報単位です。キーワードが異なると意味分布も異なり、異なるテストが生成されます。選択したキーワードが多いほど、生成される文はより正確になります。一方、他のモデルで生成された結果も下の表に示します。 #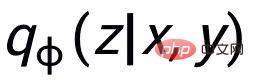


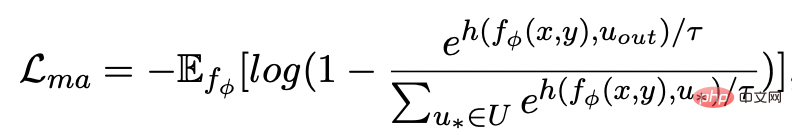
 ## または
## または 
 ##実験結果
##実験結果## QQP データセットに対して手動評価も使用しました。3 人のアノテーターがそれぞれ T5-CLAPS、DialoGPT、Seq2Seq-DU、および私たちのモデルの結果を生成しました。結果は次のとおりです。マークが付けられ、結果は以下のようになります:
アブレーション分析
#視覚分析
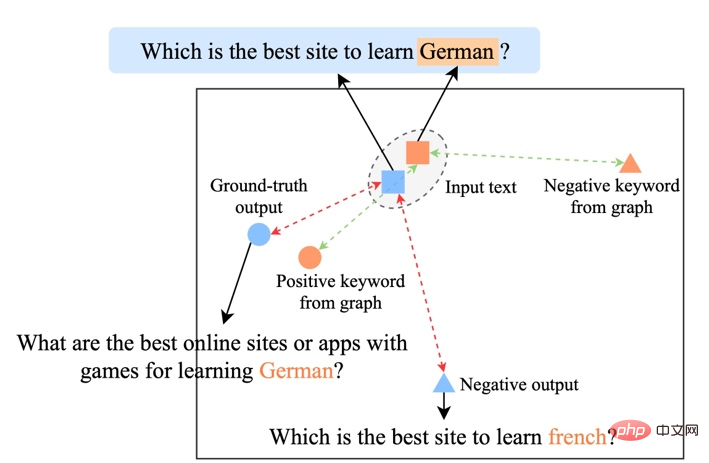
#キーワード重要度分析

この記事複数のテキスト生成データセットに対する競合ベースライン作業を上回る、粒度を超えた階層的対比学習メカニズムを提案します。この研究に基づいたクエリ書き換えモデルは、Alipay 検索の実際のビジネス シナリオに正常に実装され、顕著な結果を達成しました。 Alipay の検索サービスは広範な領域をカバーしており、ドメイン特性が顕著です。ユーザーの検索クエリ表現とサービス表現の間には文字どおりの大きな違いがあり、キーワードに基づいて直接照合することで望ましい効果を達成することは困難です (たとえば、ユーザーが「新車発売クエリ」というクエリを入力すると、「新車発売クエリ」というサービスを呼び出すことができません)、クエリ書き換えの目標は、ユーザーが入力したクエリを次のような方法に書き換えることです。ターゲット サービスによりよく一致するように、クエリの意図を変更せずにサービス式に近づけます。いくつかの言い換え例を次に示します。
以上がAlipay の検索エクスペリエンスを向上させるために、Ant と北京大学は階層型比較学習テキスト生成フレームワークを使用していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
81
11
21
75
15
1378
52
81
11
21
75

 Windows 11 の検索からニュースやトレンド コンテンツを削除する方法
Oct 16, 2023 pm 08:13 PM
Windows 11 の検索からニュースやトレンド コンテンツを削除する方法
Oct 16, 2023 pm 08:13 PM
Windows 11 で検索フィールドをクリックすると、検索インターフェイスが自動的に開きます。左側に最近のプログラムのリストが表示され、右側に Web コンテンツが表示されます。 Microsoft はそこにニュースやトレンドのコンテンツを表示します。今日のチェックでは、Bing の新しい DALL-E3 画像生成機能、「Chat Dragons with Bing」オファー、ドラゴンに関する詳細情報、Web セクションのトップ ニュース、ゲームの推奨事項、およびトレンド検索セクションを宣伝しています。項目のリスト全体は、コンピューター上でのアクティビティとは無関係です。一部のユーザーはニュースを表示できることに感謝しているかもしれませんが、これらはすべて他の場所で豊富に利用できます。直接的または間接的にそれをプロモーションまたは広告として分類する人もいます。 Microsoft はインターフェイスを使用して自社のコンテンツを宣伝しています。
 モデル、データ、フレームワークの詳細: 効率的な大規模言語モデルの 54 ページにわたる徹底的なレビュー
Jan 14, 2024 pm 07:48 PM
モデル、データ、フレームワークの詳細: 効率的な大規模言語モデルの 54 ページにわたる徹底的なレビュー
Jan 14, 2024 pm 07:48 PM
大規模言語モデル (LLM) は、自然言語理解、言語生成、複雑な推論などの多くの重要なタスクにおいて説得力のある能力を実証し、社会に大きな影響を与えてきました。ただし、これらの優れた機能には、大量のトレーニング リソース (左の図に示す) と長い推論時間 (右の図に示す) が必要です。したがって、研究者は効率の問題を解決するための効果的な技術的手段を開発する必要があります。さらに、図の右側からわかるように、Mistral-7B などのいくつかの効率的な LLM (LanguageModel) が、LLM の設計と展開にうまく使用されています。これらの効率的な LLM は、LLaMA1-33B と同様の精度を維持しながら、推論メモリを大幅に削減できます。
 Xianyu でユーザーを検索する方法
Feb 24, 2024 am 11:25 AM
Xianyu でユーザーを検索する方法
Feb 24, 2024 am 11:25 AM
Xianyu はどのようにしてユーザーを検索しますか?ソフトウェア Xianyu では、ソフトウェア内で通信したいユーザーを直接見つけることができます。しかし、ユーザーを検索する方法がわかりません。検索後にユーザー間で表示するだけです。次は編集部からユーザーへの検索方法についてご紹介しますので、興味のある方はぜひご覧ください! Xianyu でユーザーを検索するには? 回答: 検索されたユーザーの詳細を表示します はじめに: 1. ソフトウェアを入力し、検索ボックスをクリックします。 2. ユーザー名を入力し、「検索」をクリックします。 3. 検索ボックスの下の[ユーザー]を選択して、該当するユーザーを検索します。
 Baidu の高度な検索の使用方法
Feb 22, 2024 am 11:09 AM
Baidu の高度な検索の使用方法
Feb 22, 2024 am 11:09 AM
Baidu 詳細検索の使用方法 Baidu 検索エンジンは現在中国で最も一般的に使用されている検索エンジンの 1 つであり、豊富な検索機能を提供しており、その 1 つが詳細検索です。高度な検索は、ユーザーが必要な情報をより正確に検索し、検索効率を向上させるのに役立ちます。では、Baidu の高度な検索を使用するにはどうすればよいでしょうか?最初のステップは、Baidu 検索エンジンのホームページを開くことです。まず、Baidu の公式 Web サイト (www.baidu.com) を開く必要があります。ここが百度検索の入り口です。 2 番目のステップでは、「詳細検索」ボタンをクリックします。 Baidu の検索ボックスの右側に、
 WPS テーブルで検索しているデータが見つかりません。検索オプションの場所を確認してください。
Mar 19, 2024 pm 10:13 PM
WPS テーブルで検索しているデータが見つかりません。検索オプションの場所を確認してください。
Mar 19, 2024 pm 10:13 PM
インテリジェンスが支配する時代では、オフィス ソフトウェアも普及し、Wps フォームはその柔軟性により大多数のオフィス ワーカーに採用されています。仕事では、単純な帳票作成や文字入力だけでなく、実際の業務を遂行するためにより高度な操作スキルを習得することが求められており、データ付きの帳票や帳票を利用することで、より便利で明確、正確なものとなります。今日の教訓は、「WPS テーブルでは、検索しているデータが見つかりません。検索オプションの場所を確認してください。なぜですか?」です。 1. まず Excel テーブルを選択し、ダブルクリックして開きます。次に、このインターフェイスですべてのセルを選択します。 2. 次に、このインターフェースで、上部ツールバーの「ファイル」の「編集」オプションをクリックします。 3. 次に、このインターフェースで「」をクリックします。
 H100 を粉砕、Nvidia の次世代 GPU が明らかに!最初の 3nm マルチチップ モジュール設計、2024 年に発表
Sep 30, 2023 pm 12:49 PM
H100 を粉砕、Nvidia の次世代 GPU が明らかに!最初の 3nm マルチチップ モジュール設計、2024 年に発表
Sep 30, 2023 pm 12:49 PM
3nmプロセス、H100を超える性能!最近、海外メディア DigiTimes が、Nvidia が人工知能 (AI) およびハイパフォーマンス コンピューティング (HPC) アプリケーション向けの製品として、コードネーム「Blackwell」という次世代 GPU である B100 を開発しているというニュースを伝えました。 , B100はTSMCの3nmプロセスと、より複雑なマルチチップモジュール(MCM)設計を採用し、2024年の第4四半期に登場する予定だ。人工知能 GPU 市場の 80% 以上を独占している Nvidia にとって、B100 を使用して鉄は熱いうちに攻撃し、この AI 導入の波において AMD や Intel などの挑戦者をさらに攻撃することができます。 NVIDIA の推定によると、2027 年までに、この分野の生産額は約
 モバイルタオバオで店舗を探す方法 店舗名の検索方法
Mar 13, 2024 am 11:00 AM
モバイルタオバオで店舗を探す方法 店舗名の検索方法
Mar 13, 2024 am 11:00 AM
タオバオのモバイルアプリには良い商品がたくさんあります。いつでもどこでも購入でき、すべて正規品です。各商品の価格は明確です。複雑な操作は一切なく、より便利にお買い物をお楽しみいただけます。自由に検索して購入できます さまざまなカテゴリの商品セクションがすべてオープンしています 個人の配送先住所と連絡先番号を追加すると、運送会社から連絡があり、最新の物流動向をリアルタイムで確認できます初めて利用する方、商品の検索方法が分からない方でも、もちろん検索バーにキーワードを入力するだけですべての商品が表示されますので、お買い物はもうやめられません。モバイルタオバオユーザーが店舗名を検索するための詳細なオンライン方法を提供します。 1.まず携帯電話でタオバオアプリを開きます。
 マルチモーダル大型モデルの最も包括的なレビューがここにあります。 7 人のマイクロソフト研究者が精力的に協力、5 つの主要テーマ、119 ページの文書
Sep 25, 2023 pm 04:49 PM
マルチモーダル大型モデルの最も包括的なレビューがここにあります。 7 人のマイクロソフト研究者が精力的に協力、5 つの主要テーマ、119 ページの文書
Sep 25, 2023 pm 04:49 PM
マルチモーダル大型モデルの最も包括的なレビューがここにあります。マイクロソフトの中国人研究者7名が執筆した119ページで、すでに完成し、現在も最前線にある2種類のマルチモーダル大規模モデル研究の方向性から始まり、視覚理解と視覚生成という5つの具体的な研究テーマを包括的にまとめている。統合ビジュアル モデル LLM によってサポートされるマルチモーダル大規模モデル マルチモーダル エージェントは、マルチモーダル基本モデルが特殊なモデルから汎用的なモデルに移行したという現象に焦点を当てています。 Ps. 著者が論文の冒頭に直接ドラえもんの絵を描いたのはこのためである。このレビュー (レポート) は誰が読むべきですか? Microsoft の原文では次のようになります。プロの研究者でも学生でも、マルチモーダル基本モデルの基礎知識と最新の進歩を学ぶことに興味がある限り、このコンテンツは参加するのに非常に適しています。
