

スマートデータベースに基づくセルフサービス機械学習


翻訳者|Zhang Yi
改訂|Liang Ce Sun Shujuan
1. IDO になるには?
IDO(洞察駆動型組織)とは、洞察駆動型(情報指向)の組織を指します。 IDO になるには、まずデータと、データを操作および分析するためのツールが必要です。次に、適切な経験を持つデータ アナリストまたはデータ サイエンティストが必要です。最後に、洞察に基づく意思決定を実装するためのテクノロジーまたは方法を見つける必要があります。会社全体のプロセスです。
機械学習は、データの利点を最大限に活用できる技術です。 ML プロセスでは、まずデータを使用して予測モデルをトレーニングし、トレーニングが成功した後にデータ関連の問題を解決します。その中で、人工ニューラル ネットワークは最も効果的なテクノロジーであり、その設計は人間の脳がどのように機能するかについての現在の理解に基づいています。現在、人々が自由に使える膨大なコンピューティング リソースを考慮すると、大量のデータでトレーニングされた信じられないほどのモデルを生成できます。
企業は、人的エラーを避けるために、さまざまなセルフサービス ソフトウェアやスクリプトを使用してさまざまなタスクを完了できます。同様に、人的エラーを避けるためにデータに基づいて意思決定を行うことができます。
2. なぜ企業は人工知能の導入が遅れているのでしょうか?
データ処理に人工知能または機械学習を使用している企業は少数です。米国勢調査局は、2020年の時点で機械学習を導入している米国企業は10%未満(ほとんどが大企業)だと発表した。
ML 導入の障壁は次のとおりです。
- 人工知能が人間に取って代わられるようになるまでには、やるべきことはまだたくさんあります。 1つ目は、多くの企業には専門家が不足しており、専門家を雇う余裕がないということです。データサイエンティストはこの分野で高く評価されていますが、雇用コストも最も高くなります。
- 利用可能なデータの欠如、データのセキュリティ、時間のかかる ML アルゴリズムの実装。
- 企業がデータとその利点を実現できる環境を構築することは困難です。この環境には、関連するツール、プロセス、戦略が必要です。
3. 機械学習の推進には自動 ML (AutoML) ツールだけでは十分ではありません
自動 ML プラットフォームには明るい未来がありますが、現在その対象範囲はかなり限られています。自動化された ML が近いうちにデータ サイエンティストに取って代わるかどうかについても議論があります。
セルフサービス機械学習を社内にうまく導入したい場合、AutoML ツールは確かに重要ですが、プロセス、方法、戦略にも注意を払う必要があります。 AutoML プラットフォームは単なるツールであり、ほとんどの ML 専門家は、これでは十分ではないと考えています。
4. 機械学習プロセスを分析する

あらゆる ML プロセスはデータから始まります。データの準備が ML プロセスの最も重要な側面であり、モデリング部分はデータ パイプライン全体の一部にすぎず、AutoML ツールによって簡素化されることが一般的に受け入れられています。完全なワークフローでは、データを変換してモデルにフィードするために、依然として多くの作業が必要です。データの準備とデータ変換は、仕事の中で最も時間がかかり、不快な部分になる可能性があります。
さらに、ML モデルのトレーニングに使用されるビジネス データも定期的に更新されます。したがって、企業は複雑なツールやプロセスを使いこなすことができる複雑な ETL パイプラインを構築する必要があるため、ML プロセスの継続性とリアルタイム性を確保することも困難な作業となります。
5. ML とアプリケーションの統合
ML モデルを構築し、それをデプロイする必要があると仮定します。従来のデプロイメント アプローチでは、以下に示すように、これをアプリケーション層コンポーネントとして扱います。
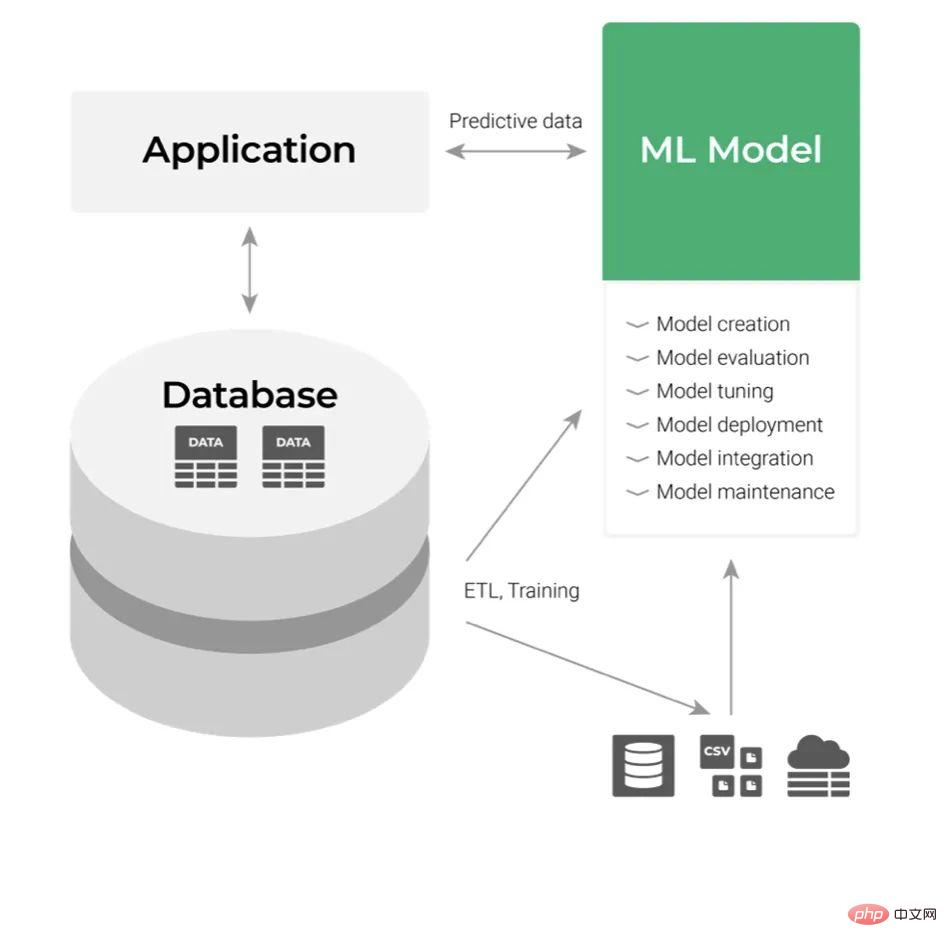
その入力はデータであり、その出力は取得した予測です。これらのアプリケーションの API を統合することで、ML モデルの出力を利用します。開発者の観点から見るとこれはすべて簡単に思えますが、プロセスを考えるとそうではありません。大規模な組織では、ビジネス アプリケーションとの統合とメンテナンスが非常に面倒になることがあります。企業がテクノロジーに精通している場合でも、コード変更のリクエストは複数のレベルの部門にわたる特定のレビューとテストのプロセスを通過する必要があります。これは柔軟性に悪影響を及ぼし、ワークフロー全体の複雑さを増大させます。
さまざまな概念やアイデアをテストする際に十分な柔軟性があれば、ML ベースの意思決定がはるかに容易になるため、人々はセルフサービス機能を備えた製品を好むようになるでしょう。
6. セルフサービスの機械学習/インテリジェント データベース?
上で見たように、データは ML プロセスの中核であり、既存の ML ツールはデータを取得して予測を返し、これらの予測はそれはデータの形式でもあります。
ここで疑問が生じます:
- なぜ ML をスタンドアロン アプリケーションとして扱い、ML モデル、アプリケーション、データベース間の複雑な統合を実装したいのですか?
- なぜML をデータベースの中核機能にしませんか?
- 標準のデータベース構文 (SQL など) を通じて ML モデルを利用できるようにしてはどうでしょうか?
上記の問題とその課題を分析してみましょう。 ML ソリューションを見つけます。
課題 #1: 複雑なデータ統合と ETL パイプライン
ML モデルとデータベース間の複雑なデータ統合と ETL パイプラインを維持することは、ML プロセスが直面する最大の課題の 1 つです。
SQL は優れたデータ操作ツールであるため、ML モデルをデータ層に導入することでこの問題を解決できます。つまり、ML モデルはデータベースで学習し、予測を返します。
課題 #2: ML モデルとアプリケーションの統合
API を介して ML モデルとビジネス アプリケーションを統合することも、直面している課題です。
ビジネス アプリケーションと BI ツールはデータベースと密接に結合されています。したがって、AutoML ツールがデータベースの一部になれば、標準 SQL 構文を使用して予測を行うことができます。次に、モデルはデータベース内に存在するため、ML モデルとビジネス アプリケーション間の API 統合は不要になります。
解決策: データベースに AutoML を埋め込む
AutoML ツールをデータベースに埋め込むと、次のような多くのメリットが得られます。
- データを操作し、SQL を理解している人なら誰でも誰でも (データ アナリストまたはデータ サイエンティスト)、機械学習の力を活用できます。
- ソフトウェア開発者は、ML をビジネス ツールやアプリケーションにより効率的に組み込むことができます。
- データとモデル間、およびモデルとビジネス アプリケーション間で複雑な統合は必要ありません。
このようにして、上記の比較的複雑な統合図は次のように変更されます。
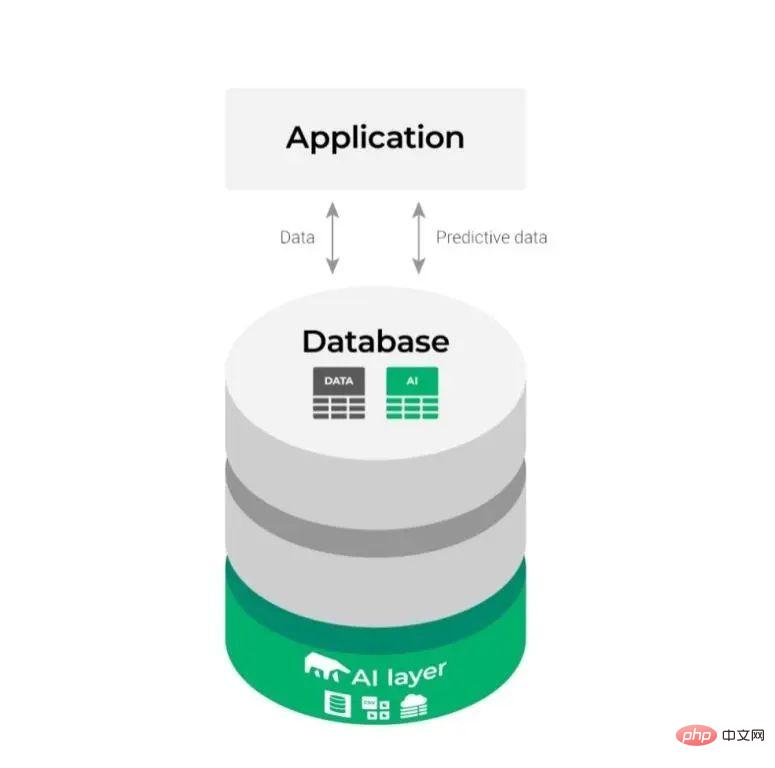
見た目がよりシンプルになり、ML プロセスがよりスムーズかつ効率的になります。 . .
7. モデルを仮想データベース テーブルとして使用してセルフサービス ML を実装する方法
ソリューションを見つけるための次のステップは、それを実装することです。
これを行うには、AI テーブルと呼ばれる構造を使用します。これは、仮想テーブルの形式でデータ プラットフォームに機械学習をもたらします。他のデータベース テーブルと同様に作成し、アプリケーション、BI ツール、DB クライアントに公開できます。データをクエリするだけで予測を行います。
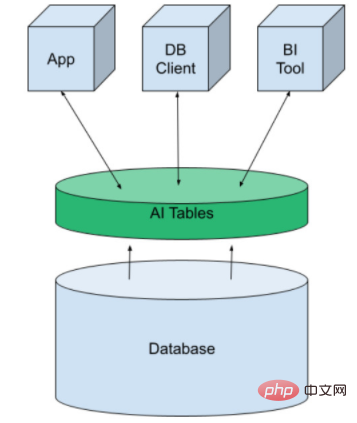
AI Tables はもともと MindsDB によって開発され、オープンソースまたはマネージド クラウド サービスとして利用できます。これらは、Kafka や Redis などの従来の SQL データベースと NoSQL データベースを統合します。
8. AI テーブルの使用
AI テーブルの概念により、データベース内で ML プロセスを実行できるようになり、ML プロセスのすべてのステップ (つまり、データの準備、モデルのトレーニング、予測) を実行できるようになります。データベースにすることができます。
- AI テーブルのトレーニング
まず、ユーザーは独自のニーズに従って AI テーブルを作成する必要があります。これは機械学習モデルに似ており、ソース テーブルの列が含まれています。などの機能を追加し、残りのモデリング タスクを AutoML エンジンを通じて単独で完了します。例は後で示します。
- 予測を行う
AI テーブルが作成されると、それ以上の展開を行わなくても使用できるようになります。予測を行うには、AI テーブルに対して標準 SQL クエリを実行するだけです。
予測は 1 つずつまたはバッチで行うことができます。 AI テーブルは、多変量時系列、異常の検出など、多くの複雑な機械学習タスクを処理できます。
9.AI テーブルの動作例
小売業者にとって、適切なタイミングで製品の在庫を確保することは複雑な作業です。需要が増えると供給も増えます。このデータと機械学習に基づいて、特定の商品が特定の日にどのくらいの在庫を持つべきかを予測することができ、その結果、小売業者の収益が増加します。
最初に、次の情報を追跡し、AI テーブルを作成する必要があります:
- 製品販売日 (date_of_sale)
- 製品販売店舗 (ショップ)
- 販売された特定の製品 (product_code)
- 販売された製品の数量 (金額)
以下に示すように:
(1) AI テーブルのトレーニング
AI テーブルを作成してトレーニングするには、まず MindsDB がデータにアクセスできるようにする必要があります。詳細な手順については、MindsDB のドキュメントを参照してください。
AI テーブルは ML モデルのようなもので、トレーニングするには履歴データが必要です。
次の例では、単純な SQL コマンドを使用して AITable をトレーニングしています:

このクエリを分析してみましょう:
- MindsDB を使用しますの CREATE PREDICTOR ステートメント。
- 履歴データに基づいてソース データベースを定義します。
- 履歴データ テーブル (historyal_table) に基づいて AI テーブルをトレーニングします。選択された列 (column_1 と column_2) は予測に使用される特徴です。
- AutoML は残りのモデリング タスクを自動的に完了します。
- MindsDB は、各列のデータ型を識別し、正規化してエンコードし、ML モデルを構築してトレーニングします。
同時に、各予測の全体的な精度と信頼性を確認し、結果にとってどの列 (特徴) がより重要であるかを推定することができます。
データベースでは、カーディナリティの高い多変量時系列データを含むタスクを処理する必要があることがよくあります。従来の方法を使用してこのような ML モデルを作成するには、かなりの労力が必要です。データをグループ化し、特定の時刻、日付、またはタイムスタンプ データ フィールドに基づいて並べ替える必要があります。
たとえば、金物店で販売されるハンマーの数を予測します。データは店舗と製品ごとにグループ化されており、さまざまな店舗と製品の組み合わせごとに予測が行われます。これにより、各グループの時系列モデルを作成するという問題が生じます。
これは大規模なプロジェクトのように聞こえますが、MindsDB は、GROUP BY ステートメントを使用して単一の ML モデルを作成し、多変量時系列データを一度にトレーニングする方法を提供します。たった 1 つの SQL コマンドを使用してそれがどのように行われるかを見てみましょう:

stock_forecaster 予測子は、特定の店舗が将来販売するアイテムの数を予測するために作成されます。データは発売日順に並べ替えられ、店舗ごとにグループ化されています。したがって、各店舗の売上高を予測することができます。
(2) バッチ予測
次のクエリを使用して売上データ テーブルを予測子に接続すると、JOIN 操作によって予測数量がレコードに追加されるため、一度に多数の数量を取得できます。バッチ予測を記録しました。

BI ツールでの予測の分析と視覚化について詳しくは、この記事をご覧ください。
(3) 実用的なアプリケーション
従来のアプローチでは、ML モデルを独立したアプリケーションとして扱い、データベースへの ETL パイプラインとビジネス アプリケーションへの API 統合のメンテナンスが必要です。 AutoML ツールを使用すると、モデリング部分が簡単かつ簡単になりますが、完全な ML ワークフローを管理するには、依然として経験豊富な専門家が必要です。実際、データベースはすでにデータ準備に好まれているツールであるため、ML にデータを導入するよりも、データベースに ML を導入する方が合理的です。 AutoML ツールはデータベース内に存在するため、MindsDB から構築された AI Tables はデータ実務者にセルフサービス AutoML を提供し、機械学習ワークフローを合理化します。
元のリンク: https://dzone.com/articles/self-service-machine-learning-with-intelligent-dat
翻訳者の紹介
Zhang Yi、51CTO コミュニティ編集者、中級エンジニア。主に人工知能アルゴリズムとシナリオアプリケーションの実装を研究し、機械学習アルゴリズムと自動制御アルゴリズムを理解して熟知しており、国内外の人工知能技術の開発動向、特に人工知能の応用に引き続き注目していきます。インテリジェント コネクテッド カーやスマート ホームにおけるインテリジェンス テクノロジー、他の分野での具体的な実装と応用。

以上がスマートデータベースに基づくセルフサービス機械学習の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7677
7677
 15
1393
52
1207
24
91
11
15
1393
52
1207
24
91
11

 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ では、機械学習アルゴリズムの実装には以下が含まれます。 線形回帰: 連続変数を予測するために使用されるステップには、データの読み込み、重みとバイアスの計算、パラメーターと予測の更新が含まれます。ロジスティック回帰: 離散変数の予測に使用されます。このプロセスは線形回帰に似ていますが、予測にシグモイド関数を使用します。サポート ベクター マシン: サポート ベクターの計算とラベルの予測を含む強力な分類および回帰アルゴリズム。
 iOS 18では、紛失または破損した写真を復元するための新しい「復元」アルバム機能が追加されます
Jul 18, 2024 am 05:48 AM
iOS 18では、紛失または破損した写真を復元するための新しい「復元」アルバム機能が追加されます
Jul 18, 2024 am 05:48 AM
Apple の最新リリースの iOS18、iPadOS18、および macOS Sequoia システムでは、さまざまな理由で紛失または破損した写真やビデオをユーザーが簡単に回復できるように設計された重要な機能が写真アプリケーションに追加されました。この新機能では、写真アプリのツール セクションに「Recovered」というアルバムが導入され、ユーザーがデバイス上に写真ライブラリに含まれていない写真やビデオがある場合に自動的に表示されます。 「Recovered」アルバムの登場により、データベースの破損、カメラ アプリケーションが写真ライブラリに正しく保存されない、または写真ライブラリを管理するサードパーティ アプリケーションによって失われた写真やビデオに対する解決策が提供されます。ユーザーはいくつかの簡単な手順を実行するだけで済みます
 PHP で MySQLi を使用してデータベース接続を確立するための詳細なチュートリアル
Jun 04, 2024 pm 01:42 PM
PHP で MySQLi を使用してデータベース接続を確立するための詳細なチュートリアル
Jun 04, 2024 pm 01:42 PM
MySQLi を使用して PHP でデータベース接続を確立する方法: MySQLi 拡張機能を含める (require_once) 接続関数を作成する (functionconnect_to_db) 接続関数を呼び出す ($conn=connect_to_db()) クエリを実行する ($result=$conn->query()) 閉じる接続 ( $conn->close())
 PHP でデータベース接続エラーを処理する方法
Jun 05, 2024 pm 02:16 PM
PHP でデータベース接続エラーを処理する方法
Jun 05, 2024 pm 02:16 PM
PHP でデータベース接続エラーを処理するには、次の手順を使用できます。 mysqli_connect_errno() を使用してエラー コードを取得します。 mysqli_connect_error() を使用してエラー メッセージを取得します。これらのエラー メッセージをキャプチャしてログに記録することで、データベース接続の問題を簡単に特定して解決でき、アプリケーションをスムーズに実行できるようになります。
 Golang 機械学習アプリケーション: インテリジェントなアルゴリズムとデータ駆動型ソリューションの構築
Jun 02, 2024 pm 06:46 PM
Golang 機械学習アプリケーション: インテリジェントなアルゴリズムとデータ駆動型ソリューションの構築
Jun 02, 2024 pm 06:46 PM
Golang で機械学習を使用して、インテリジェントなアルゴリズムとデータ駆動型ソリューションを開発します。機械学習アルゴリズムとユーティリティ用の Gonum ライブラリをインストールします。 Gonum の LinearRegression モデル、教師あり学習アルゴリズムを使用した線形回帰。入力変数とターゲット変数を含むトレーニング データを使用してモデルをトレーニングします。新しい特徴に基づいて住宅価格を予測し、モデルはそこから線形関係を抽出します。
