

Meituan は、小規模サンプル学習リスト FewCLUE! で 1 位にランクされています。即時学習+自己訓練実践

著者: Luo Ying、Xu Jun、Xie Rui 他
1 概要
CLUE(中国語理解評価)[ 1] は、中国語理解に関する権威ある評価リストです。テキスト分類、文間の関係、読解など、多くの意味分析と意味理解サブタスクが含まれています。学術界と産業界の両方に多大な影響を与えています。

図 1 FewCLUE リスト (2022 年 4 月 18 日現在)
FewCLUE [2,3] は、中国語の小規模サンプル学習の評価に特に使用される CLUE のサブリストです。事前トレーニングされた言語モデルの普遍的で強力な一般化機能を組み合わせて、最良の小規模サンプル学習モデルとそのアプリケーションを探索することを目的としています。中国語、練習してください。 FewCLUE のデータ セットには、100 を超えるラベル付きサンプルしか含まれていないものもあり、非常に少数のラベル付きサンプルの下でモデルの汎化パフォーマンスを測定できます。リリース後、NetEase、WeChat AI、Alibaba、IDEA Research Institute などの注目を集めました。 Inspur 人工知能研究: 同研究所をはじめ多くの企業や研究機関が参加しました。少し前に、Meituan プラットフォーム検索および NLP 部門の NLP センターの意味理解チームの小規模サンプル学習モデル FSL が、SOTA レベルに達する優れたパフォーマンスで FewCLUE リストの 1 位を獲得しました。
2 方法の紹介
大規模な事前トレーニング モデルはさまざまな主要なタスクで非常に良い結果を達成しましたが、特定のタスクには依然として大量のラベル付きデータが必要です。タスク。 Meituan のさまざまなビジネスには豊富な NLP シナリオがあり、多くの場合、手作業でのラベル付けに多額のコストがかかります。ビジネス開発の初期段階、または新しいビジネスを迅速に開始する必要がある場合、ラベル付きサンプルが不十分であることがよくあります。微調整) 学習およびトレーニング方法は、理想的なインデックス要件を満たさないことがよくあるため、小さなサンプル シナリオでモデルのトレーニングの問題を研究することが非常に必要になります。 この記事では、モデル構造の最適化、大規模な事前トレーニング、サンプルの強化などのモデル最適化戦略を組み合わせた、大規模なモデルと小規模なサンプルのための一連の共同トレーニング ソリューション、FSL を提案します。 、アンサンブル学習、および自己トレーニングを行い、最終的には中国語理解の権威ある評価ベンチマークである FewCLUE リストで優れた結果を達成し、そのパフォーマンスは一部のタスクでは人間のレベルを超えましたが、一部のタスクでは (
CLUEWSC など)) まだ改善の余地があります。 FewCLUE のリリース後、NetEase Fuxi は自社開発の EET モデル
[4]を使用し、二次トレーニングを通じてモデルの意味的理解を強化しました。次に、マルチタスク学習用のテンプレートを追加しました。IDEA Research Institute の Erlangshen モデル [5] は、より高度な事前トレーニング テクノロジを使用して、BERT モデルに基づいて大規模なモデルをトレーニングし、そのプロセスで動的なマスク戦略を使用したマスクを使用します。下流タスクの微調整の補助タスクとしての言語モデル (MLM)。これらの手法はすべて、基本的なタスク構造としてプロンプト学習を使用していますが、これらの自社開発の大規模モデルと比較して、私たちの手法は主にサンプル強化、アンサンブル学習、プロンプト学習フレームワークに基づく自己学習などのモデル最適化戦略を追加しており、大幅に改善されています。タスクのパフォーマンスとモデルの堅牢性が向上すると同時に、この方法はさまざまな事前トレーニング モデルに適用できるため、より柔軟で便利になります。 FSL の全体的なモデル構造を以下の図 2 に示します。 FewCLUE データセットは、タスクごとに 160 のラベル付きデータと約 20,000 のラベルなしデータを提供します。この FewCLUE の実践では、まず微調整ステージでマルチテンプレートのプロンプト学習を構築し、敵対的トレーニング、対照学習、ラベル付きデータのミックスアップなどの強化戦略を使用しました。これらのデータ強化戦略は異なる強化原理を使用しているため、これらのモデル間の違いは比較的大きく、統合学習後にはより良い結果が得られると考えられます。したがって、トレーニングにデータ拡張戦略を使用した後、複数の弱教師モデルを用意し、これらの弱教師モデルを使用してラベルなしデータを予測し、ラベルなしデータの擬似ラベル分布を取得します。その後、さまざまなデータ拡張モデルによって予測されたラベルなしデータの複数の擬似ラベル分布を統合して、ラベルなしデータの全体的な擬似ラベル分布を取得します。その後、マルチテンプレートのプロンプト学習を再構築して、そのデータを再度使用します。戦略を強化して、最適な戦略。現在、実験では 1 回の反復のみを実行していますが、複数回の反復を試すこともできますが、反復回数が増えると、改善は明らかではなくなります。
図 2 FSL モデルのフレームワーク
2.1 強化された事前トレーニング
事前トレーニング言語モデルは、ラベルのない巨大なコーパスでトレーニングされます。たとえば、RoBERTa[6] は、百科事典、ニュース記事、文学作品、Web コンテンツなど、160 GB を超えるテキストでトレーニングされています。これらのモデルによって学習された表現は、複数のソースからのさまざまなサイズのデータセットを含むタスクで優れたパフォーマンスを実現します。
FSL モデルは、RoBERTa-large モデルを基本モデルとして使用し、ドメイン適応型事前トレーニング (DAPT)[7]## を採用しています。 #タスク知識を組み込んだ #事前トレーニング手法とタスク適応型事前トレーニング (TAPT)[7]。 DAPT は、フィールドに大量のラベルなしテキストを追加して、事前トレーニングされたモデルに基づいて言語モデルのトレーニングを継続し、指定されたタスクのデータセットに基づいて言語モデルを微調整することを目的としています。
ターゲット テキスト ドメインで事前トレーニングを続けると、特にターゲット テキスト ドメインに関連する下流タスクで、言語モデルのパフォーマンスを向上させることができます。さらに、事前トレーニングテキストとタスクドメイン間の相関が高いほど、改善は大きくなります。この演習では、エンターテインメント番組、スポーツ、健康、国際情勢、映画、有名人など、さまざまな分野のコーパスを含む 100G CLUE Vocab[8] で事前トレーニングされた RoBERTa Large を最終的に使用しました。などのモデル。 TAPTとは、事前学習用の事前学習済みモデルをベースに、タスクに直接関係するラベルなしコーパスを少量追加することを指します。 TAPT タスクの場合、使用することを選択した事前トレーニング データは、各タスクの FewCLUE リストによって提供されるラベルのないデータです。
さらに、中国語の自然言語推論タスク OCNLI や中国語の対話短文マッチング タスク BUSTM などの文間関係タスクの実践では、他の文間関係を使用します。中国語の自然言語推論データセット CMNLI や中国語の短文類似性データセット LCQMC などのタスクの場合、中国語短文類似性データセット LCQMC で事前トレーニングされたモデル パラメーターが初期パラメーターとして使用されます。モデルを使用してタスクを完了すると、効果をある程度向上させることもできます。
2.2 モデル構造FewCLUE にはさまざまなタスク フォームが含まれており、各タスクに適切なモデル構造が選択されています。テキスト分類タスクと機械読解 (MRC) タスクのカテゴリ ワードはそれ自体に情報が含まれているため、マスク言語モデル (MLM) の形式でモデル化するのがより適しています。 2 つの文の関連性を判断するタスクは、次の文の予測(NSP)[9] タスク フォームによく似ています。したがって、分類タスクと読解タスクには PET[10] モデルを選択し、文間関係タスクには EFL[11] モデルを選択します。グローバル サンプリングを通じて負のサンプルを構築し、より堅牢な分類器を学習します。
2.2.1 プロンプト学習プロンプト学習の主な目標は、トレーニング前のターゲットと下流の微調整ターゲットの間のギャップを最小限に抑えることです。通常、既存の事前トレーニング タスクには MLM 損失関数が含まれていますが、下流タスクでは MLM を使用せず、新しい分類器が導入されているため、事前トレーニング タスクと下流タスクの間で不一致が発生します。プロンプト学習では、追加の分類子やその他のパラメーターは導入されませんが、テンプレート (Template、入力データの言語フラグメントの結合を意味します) とタグ ワード マッピング (Verbalizer、つまり、各ラベルの語彙内で対応する単語を見つけて、MLM タスクの予測ターゲット ) を設定することで、サンプル数が少ない下流タスクでモデルを使用できるようになります。
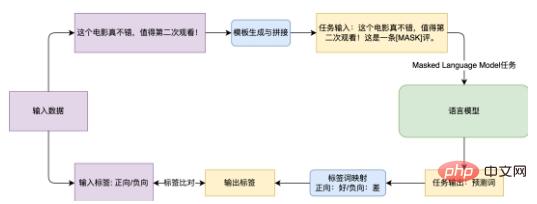

図 3 に示す電子商取引評価センチメント分析タスク EPRSTMT を例に挙げます。 「この映画は本当に良いので、もう一度見る価値があります!」というテキストが与えられた場合、従来のテキスト分類では、分類子を CLS 部分の埋め込みに接続し、それを 0-1 分類にマッピングします (0: ネガティブ) 、1: 転送 )。この方法では、小さなサンプル シナリオで新しい分類器をトレーニングする必要があり、良好な結果を達成するのは困難です。プロンプト学習に基づく方法は、「これは [MASK] コメントです。」というテンプレートを作成し、そのテンプレートと元のテキストをつなぎ合わせるというもので、学習中に言語モデルが [MASK] の位置にある単語を予測してマッピングします。対応するカテゴリに移動します (Good: ポジティブ、Bad: ネガティブ)。
十分なデータが不足しているため、最もパフォーマンスの高いテンプレートとタグ ワード マッピングを決定することが困難な場合があります。したがって、マルチテンプレートおよびマルチラベルワードマッピングの設計も採用できます。複数のテンプレートを設計することにより、最終結果には複数のテンプレートの結果が統合されるか、1 つのタグが複数の単語に対応するように 1 対多のタグ単語マッピングが設計されます。上記の例と同様に、次のテンプレートの組み合わせを設計できます (左: 同じ文に対する複数のテンプレート、右: 複数のタグ マッピング)。

#図 4 PET マルチテンプレートとマルチラベルのマッピング
タスク サンプル

表 1 FewCLUE データセットでの PET テンプレートの構築
2.2.2 EFL
EFL モデルは 2 つの文を結合し、出力レイヤーの [CLS] 位置で埋め込みを使用し、続いて分類器を使用して予測を完了します。 EFL のトレーニング プロセスでは、トレーニング セット内のサンプルに加えて、ネガティブ サンプルも構築されます。トレーニング プロセスでは、各バッチで他のデータ内の文がネガティブ サンプルとしてランダムに選択され、ネガティブ サンプルを構築することでデータ強化が行われます。サンプル。 EFL モデルは新しい分類器をトレーニングする必要がありますが、現在、CMNLI、LCQMC などの多くのパブリック テキスト含意/文間関係データ セットがあり、これらのサンプルで継続的に学習できます (Continue-train) )、学習したパラメータを小さなサンプル シナリオに移行し、FewCLUE のタスク データ セットを使用してさらに微調整します。
#タスクの例

表 2 FewCLUE データセット EFL テンプレート構築 2.3 データ拡張
2.3 データ拡張
#データ拡張方法には、主にサンプル拡張と埋め込み拡張が含まれます。 NLP の分野では、データ拡張の目的は、セマンティクスを変更せずにテキスト データを拡張することです。主な方法としては、単純なテキスト置換、言語モデルを使用した類似文の生成などが挙げられます。テキストデータを拡張するためにEDAなどの手法も試してきましたが、単語を変更すると文全体の意味が反転し、置換された文が入れ替わってしまう場合があります。テキストには多くのノイズが含まれるため、単純なルール サンプルの変更では十分な拡張データを生成することは困難です。ただし、エンベディング強化は入力ではなくエンベディング レベルで動作し、エンベディングに摂動または補間を追加することでモデルのロバスト性を向上させることができます。
したがって、この演習では主に Embedding 拡張を実行します。私たちが使用するデータ強化戦略には、Mixup
[12]、Manifold-Mixup[13]、および敵対的トレーニング (Adversarial training、AT) [ 14] と対照学習 R-drop[15]。
 表 3 データ拡張戦略の簡単な説明
表 3 データ拡張戦略の簡単な説明
Mixup は、入力データに対して単純な線形変換を実行することにより、新しい結合サンプルと結合ラベルを構築します。モデルの汎化能力。さまざまな教師ありタスクまたは半教師ありタスクで、Mixup を使用すると、モデルの汎化能力が大幅に向上します。 Mixup 法は正則化操作とみなすことができ、特徴レベルでモデルによって生成された結合特徴が線形制約を満たすことを要求し、この制約を使用してモデルを正則化します。直感的には、モデルの入力が他の 2 つの入力の線形結合である場合、その出力も 2 つのデータをモデルに別々に入力した後に得られる出力の線形結合になります。線形システム。
Manifold Mixup は、上記の Mixup 操作を機能に一般化したものです。フィーチャには高次のセマンティック情報があるため、そのディメンション全体にわたる補間により、より意味のあるサンプルが生成される可能性があります。 BERT[9] や RoBERTa[6] と同様のモデルでは、層の数 k がランダムに選択され、この層の特徴表現に対してミックスアップ補間が実行されます。通常の Mixup の補間は出力層の Embedding 部分で行われ、Manifold Mixup はこの一連の補間操作を言語モデル内の Transformers 構造のランダム層に追加することに相当します。
敵対的トレーニングは、入力サンプルに小さな摂動を追加することでモデルの損失を大幅に改善します。敵対的トレーニングとは、元のサンプルと敵対的サンプルを効果的に識別できるモデルをトレーニングすることです。基本原理は、摂動を追加することによっていくつかの敵対的サンプルを構築し、それらをトレーニング用のモデルに与えることにより、敵対的サンプルに遭遇したときのモデルの堅牢性を向上させ、同時にモデルのパフォーマンスと汎化機能を向上させることです。敵対的な例には、次の 2 つの特性が必要です。
- 追加される摂動は、元の入力に比べて最小限です。
- モデルが間違いを犯す可能性があります。敵対的トレーニングには 2 つの機能があります。1 つは悪意のある攻撃に対するモデルの堅牢性の向上、もう 1 つはモデルの汎化能力の向上です。
#R-Drop は、同じ文に対して Dropout を 2 回実行し、Dropout によって生成されたさまざまなサブモデルの出力確率が一貫性を保つように強制します。 Dropout の導入はうまく機能しますが、トレーニングと推論のプロセスで不整合の問題が発生する可能性があります。このトレーニング推論プロセスの不一致を軽減するために、R-Drop はドロップアウトを正則化し、2 つのサブモデルによって生成された出力の出力データ分布に制限を追加し、データ分布測定の KL 発散損失を導入します。バッチ内 同じサンプルによって生成された 2 つのデータ分布は可能な限り近く、分布の一貫性がなければなりません。具体的には、各トレーニング サンプルについて、R-Drop は、異なるドロップアウトによって生成されたサブモデルの出力確率間の KL 発散を最小限に抑えます。トレーニングのアイデアとして、R-Drop はほとんどの教師ありトレーニングまたは半教師ありトレーニングで使用でき、非常に汎用性があります。
私たちが使用する 3 つのデータ拡張戦略のうち、Mixup は、出力層の 2 つのサンプルの線形変更です。言語モデルの埋め込みと、内部のトランスフォーマーのランダム層の出力層です。敵対的トレーニングでは、サンプルに小さな摂動を追加しますが、対照的学習では、同じ文に対してドロップアウトを 2 回実行して正のサンプル ペアを形成し、次に KL ダイバージェンスを使用して 2 つのサブモデルが一致するように制限します。 3 つの戦略はすべて、埋め込みでいくつかの操作を完了することによってモデルの一般化を強化します。異なる戦略を通じて取得されたモデルには異なる設定があり、アンサンブル学習の次のステップの条件が提供されます。
2.4 アンサンブル学習と自己トレーニング
アンサンブル学習では、より優れた包括的な強教師モデルを取得するために、複数の弱教師モデルを組み合わせることができます。アンサンブル学習の基本的な考え方は、弱分類器が間違った予測を行ったとしても、他の弱分類器が誤りを修正できるというものです。組み合わせるモデル間の違いが大きい場合は、通常、アンサンブル学習の方がより良い結果が得られます。
セルフ トレーニングでは、少量のラベル付きデータと大量のラベルなしデータを使用してモデルを共同トレーニングします。まず、トレーニング済みの分類器を使用してすべてのラベルなしデータのラベルを予測します。次に、信頼度を選択します。より高い次数のラベルが擬似ラベル データとして使用され、擬似ラベル付きデータが手動でラベル付けされたトレーニング データと結合されて、分類器が再トレーニングされます。
アンサンブル学習セルフトレーニングは、複数のモデルとラベルなしのデータを利用できるソリューションです。その中で、アンサンブル学習の一般的な手順は次のとおりです。複数の異なる弱教師モデルをトレーニングし、各モデルを使用してラベルなしデータのラベル確率分布を予測し、ラベル確率分布の加重和を計算し、ラベルなしデータの擬似ラベル確率分布を取得します。データ。 。自己トレーニングとは、他のモデルを組み合わせるためにモデルをトレーニングすることを指します。一般的な手順は次のとおりです: 複数の Teacher モデルをトレーニングし、Student モデルは擬似ラベルの確率分布で信頼性の高いサンプルのソフト予測を学習し、Student モデルは最後の強力な学習者。
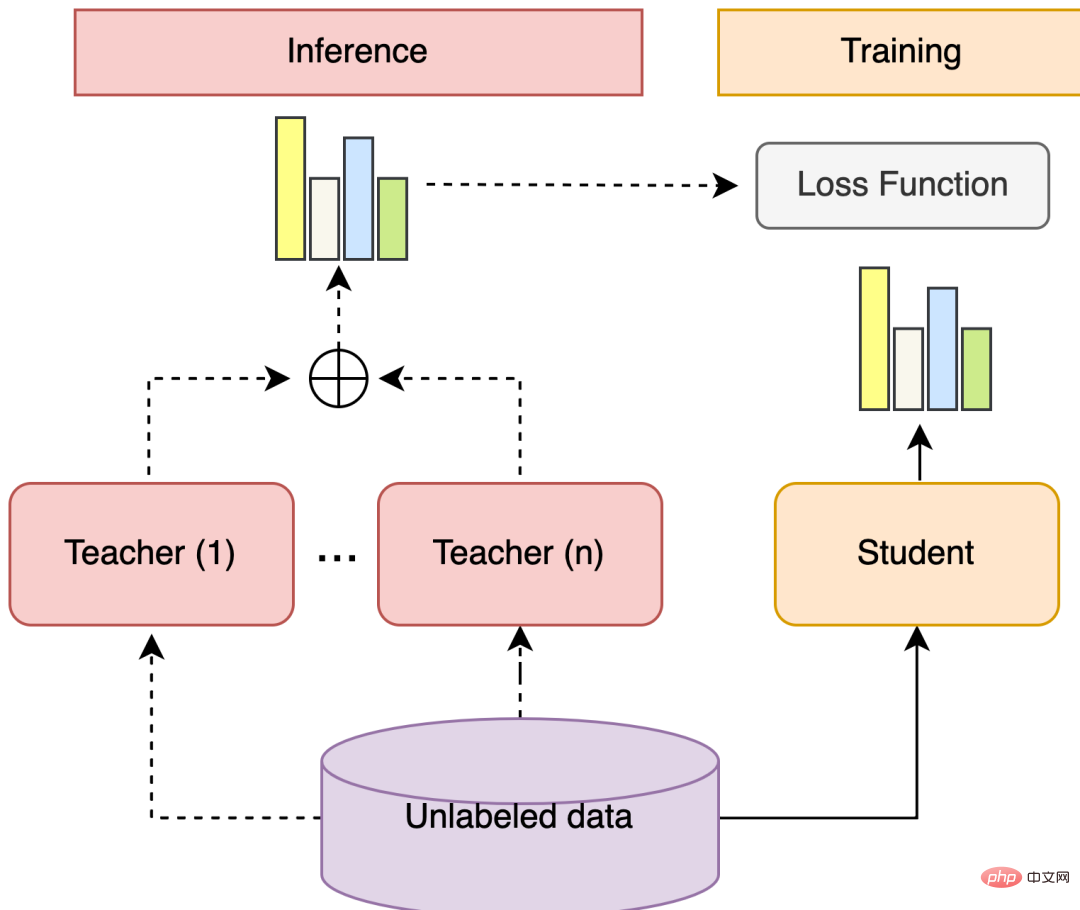
 #図 5 統合学習セルフトレーニング構造
#図 5 統合学習セルフトレーニング構造
この FewCLUE の実践では、まず、微調整ステージでマルチテンプレートのプロンプト学習を構築し、敵対的トレーニング、対照学習、ラベル付きデータのミックスアップなどの強化戦略を使用します。これらのデータ強化戦略は異なる強化原理を使用しているため、これらのモデル間の違いは比較的大きく、統合学習後にはより良い結果が得られると考えられます。
トレーニングにデータ拡張戦略を使用した後、複数の弱教師モデルがあり、これらの弱教師モデルを使用してラベルなしデータを予測し、擬似ラベルなしデータを取得します。その後、さまざまなデータ拡張モデルによって予測されたラベルなしデータの複数の擬似ラベル分布を統合して、ラベルなしデータの擬似ラベル分布全体を取得します。擬似ラベル データをスクリーニングするプロセスでは、必ずしも最も高い信頼度を持つサンプルを選択する必要はありません。各データ拡張モデルによって与えられる信頼度が非常に高い場合、このサンプルは学習しやすいサンプルである可能性があることを意味するためです。必ずしも大きな値をもつわけではありません。
複数のデータ拡張モデルによって与えられる信頼性を組み合わせて、より高い信頼性を持つが学習が容易ではないサンプルの選択を試みます (たとえば、複数のモデルはすべての一貫した予測を行うわけではありません )。次に、ラベル付きデータと擬似ラベル付きデータのセットを使用してマルチ テンプレート プロンプト学習が再構築され、データ拡張戦略が再度使用され、最適な戦略が選択されます。現在、実験では 1 回の反復のみを実行していますが、複数回の反復を試すこともできますが、反復回数が増えると改善は減少し、有意ではなくなります。
3 実験結果3.1 データセットの紹介FewCLUE リストには、4 つのテキスト分類タスクと 2 つの 1 文間関係タスクを含む 9 つのタスクが含まれています。そして3つの読解課題。テキスト分類タスクには、電子商取引評価センチメント分析、科学文書分類、ニュース分類、アプリ アプリケーション説明トピック分類タスクが含まれます。主に短文の分類、短文の多重分類、長文の多重分類の2つに分類されます。一部のタスクには 100 を超える多くのカテゴリがあり、カテゴリの不均衡の問題が発生します。文間の関係タスクには、自然言語推論と短いテキストのマッチング タスクが含まれます。読解課題には、熟語読解、選択的穴埋め、要約判断、キーワード識別、代名詞曖昧さ回避課題が含まれます。各タスクでは、約 160 個のラベル付きデータと約 20,000 個のラベルなしデータが提供されます。長いテキストの分類タスクにはカテゴリが多く、難易度が高すぎるため、より多くのラベル付きデータも提供されます。詳細なタスク データを表 4 に示します。

3.2 実験の比較
表 5 は、さまざまなモデルとパラメータ量の実験結果の比較を示しています。 RoBERTa Base 実験では、PET/EFL モデルを使用すると、従来の直接 Fine-Tune モデルの結果を 2 ~ 28PP 上回ります。 PET/EFLモデルに基づいて、小規模なサンプルシナリオにおける大規模モデルの効果を調査するために、RoBERTa Largeで実験を実施しました.RoBERTa Baseと比較して、大規模モデルはモデルを0.5〜13PP改善することができ、より効果的に利用することができますドメイン知識に加えて、CLUE データセットで事前トレーニングされた RoBERTa Large Clue モデルで実験をさらに実施しました。ドメイン知識を組み込んだ大規模モデルでは、結果がさらに 0.1 ~ 9 pp 向上しました。これを踏まえて、今後の実験ではRoBERTa Large Clueの実験を行っていきます。表 5 さまざまなモデルとパラメーター量の実験結果の比較 (赤い太字は最良の結果を示します) 表 6 PET/EFLモデルでのデータ強化と統合学習の実験結果を示しています.大規模モデルでデータ強化戦略を使用した場合でも、モデルは0.8〜9PPの改善をもたらし、さらに統合学習をもたらすことができることがわかります&自己トレーニング 今後もモデル性能は0.4~4PP向上していきます。 #表 6 基本モデルのデータ強化アンサンブル学習の実験結果 (赤色の太字は最良の結果を示します) 統合学習の自己トレーニング ステップでは、いくつかのスクリーニング戦略を試しました: Meituan のさまざまなビジネスには豊富な NLP シナリオがあり、いくつかのタスクは分類できます。カテゴリはテキスト分類タスクと文間関係タスクです。上記の小規模サンプル学習戦略は、美団点評のさまざまなシナリオに適用されています。データ リソースが不足している場合でも、より良いモデルをトレーニングできることが期待されます。さらに、小規模サンプル学習戦略は、Meituan の内部自然言語処理 (NLP) プラットフォームのさまざまな NLP アルゴリズム機能で広く使用されており、多くのビジネス シナリオに実装され、大きなメリットを達成しています。このプラットフォームを使用して、NLP センターに関連する機能を体験できます。 テキスト分類タスク 医療美容テーマの分類: Meituan と Dianping の場合メモの内容は、主題に応じて、好奇心探求、店舗探索、評価、実際の事例、治療プロセス、落とし穴回避、効果比較、ポピュラーサイエンスの 8 つのカテゴリーに分類されます。ユーザーが特定のトピックをクリックすると、対応するノートコンテンツが返され、美団と点評アプリのメディカルビューティーチャンネルの百科事典ページとプランページで体験の共有が行われます 2,989 個のトレーニングデータを使用した小規模サンプル学習の精度1.8PP増加し、89.24%に達しました。 戦略識別: UGC とメモから旅行戦略をマイニングし、旅行戦略のコンテンツを提供し、景勝地検索の下の戦略モジュールに適用され、コンテンツをリコールします。旅行戦略を説明するメモの場合、小規模サンプル学習では 384 個のトレーニング データを使用して精度が 2PP 向上し、87% に達します。 Xuecheng テキスト分類: Xuecheng (Meituan Internal Knowledge Base) には多数のユーザー テキストがあり、誘導後、テキストは分割されます。 17のカテゴリに対して既存モデルを700個のデータで学習し、小規模サンプル学習によりモデル精度が既存モデルより2.5PP向上し、84%に達しました。 プロジェクトのスクリーニング: LE ライフサービス/ビューティーとその他の事業の現在の評価リスト ページでは、ユーザーが意思決定の情報をすぐに見つけるのが不便な方法で評価が混在しているため、詳細を確認します。ユーザーのニーズを満たすために、これら 2 つのビジネスでは 300 ~ 500 個のデータを使用して小規模サンプル学習で 95% の精度を達成しました (複数のデータセットはそれぞれ 1.5 ~ 4PP 増加しました) 。 文間関係タスク 医療美容有効性マーキング: Meituan と Dianping の場合noteの内容は効能に応じて呼び出されます。効能の種類には、水分補給、美白、小顔、シワ取りなどが含まれます。オンラインのメディカルビューティーチャンネルページにあります。マークする必要がある効能の種類は110種類あります。トレーニングは2909のみです。データは小規模サンプルの学習に使用され、正解率は 91.88% に達しました ( 2.8PP 増加)。 メディカル ビューティー ブランド マーキング: ブランドの上流企業は自社製品のブランド プロモーションとマーケティングに対する需要があり、コンテンツ マーケティングが現在の主流で効果的なマーケティング手法です。 。ブランドマーキングとは、「ヨーロッパ」や「シュワイケ」など、各ブランドの詳細を記したメモを呼び出すことです。メディカルビューティーブランド館にオンラインで販売されている合計103のブランドがあります。少量のサンプルに必要なトレーニング項目はわずか1,676個ですデータ精度は 88.59% に達しました ( 2.9PP 増加)。 このリストの提出では、RoBERTa と強化された予測トレーニング、PET/EFL モデルに基づいて意味理解モデルを構築しました。データ拡張、アンサンブル学習、自己トレーニングによりモデルのパフォーマンスを向上させます。このモデルは、テキスト分類、文間の関係推論タスク、およびいくつかの読解タスクを完了できます。 この評価タスクに参加することで、小規模なサンプル シナリオにおける自然言語理解分野のアルゴリズムと研究についての理解が深まり、中国語についての理解も深まりました。最先端のアルゴリズムの言語実装機能 さらなるアルゴリズムの研究とアルゴリズム実装の基礎を築くために徹底的なテストが実施されました。さらに、このデータセットのタスク シナリオは Meituan Search および NLP 部門のビジネス シナリオと非常に似ており、このモデルの戦略の多くは実際のビジネスにも直接適用され、ビジネスに直接力を与えます。 Luo Ying、Xu Jun、Xie Rui、Wu Wei はいずれも Meituan Search および NLP 部門の出身です。 /NLPセンター。 

4 Meituan のシナリオにおける小規模サンプル学習戦略の適用
5 概要
6 この記事の著者
以上がMeituan は、小規模サンプル学習リスト FewCLUE! で 1 位にランクされています。即時学習+自己訓練実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7548
7548
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 Meituanの持ち帰りカウンターの入手方法
Apr 08, 2024 pm 03:41 PM
Meituanの持ち帰りカウンターの入手方法
Apr 08, 2024 pm 03:41 PM
1. 配達員が食事をキャビネットに入れると、テキスト メッセージ、電話、または Meituan メッセージを通じて、顧客に食事を受け取るように通知します。 2. 顧客は WeChat または Meituan APP を通じて食品キャビネットの QR コードをスキャンして、スマート食品キャビネット アプレットに入ることができます。 3. ピックアップコードを入力するか、「ワンクリックキャビネットオープン」機能を使用して、簡単にキャビネットのドアを開けてテイクアウトを取り出すことができます。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 美団の支払いパスワードを忘れた場合の回復方法_美団の支払いパスワードを忘れた場合の回復方法
Mar 28, 2024 pm 03:29 PM
美団の支払いパスワードを忘れた場合の回復方法_美団の支払いパスワードを忘れた場合の回復方法
Mar 28, 2024 pm 03:29 PM
1. まず、Meituan ソフトウェアに入り、[マイ メニュー] ページで [設定] を見つけ、クリックして [設定] に入ります。 2. 次に、設定ページで支払い設定を見つけ、クリックして支払い設定を入力します。 3. 支払いセンターに入り、支払いパスワード設定を見つけて、クリックして支払いパスワード設定を入力します。 4. 支払いパスワード設定ページで、支払いパスワードの取得を見つけ、クリックしてページ オプションを入力します。 5. 取得したい支払いパスワード情報を入力し、「確認」をクリックすると、パスワードを通過すると支払いパスワードを取得できます。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
