

GitHub オープンソース 130+Stars: PPYOLO シリーズに基づいたターゲット検出アルゴリズムを再現する方法を段階的に教えます

物体検出はコンピュータ ビジョンの分野における基本的なタスクですが、適切な Model Zoo がなければどうやってそれを行うことができるでしょうか?
今日は、シンプルで使いやすいターゲット検出アルゴリズム モデル ライブラリ miemiedetection を紹介します。現在、GitHub で 130 個のスターを獲得しています
コードリンク: https://github.com/miemie2013/miemiedetection
miemiedetection は、YOLOX をベースに開発された個人検出ライブラリで、PPYOLO、PPYOLOv2、PPYOLOE、FCOS などのアルゴリズムもサポートしています。
YOLOX の優れたアーキテクチャのおかげで、miemiedetection でのアルゴリズムのトレーニング速度は非常に速く、データの読み取りがトレーニング速度のボトルネックになることはなくなりました。
コード開発で使用される深層学習フレームワークは pyTorch です。これは、変形可能な畳み込み DCNv2、行列 NMS、およびその他の難しい演算子を実装し、単一マシンのシングルカード、単一マシンのマルチカード、およびマルチマシン マルチカード トレーニング モード (マルチカード トレーニング モードには Linux システムを推奨)、Windows および Linux システムをサポートします。
miemiedetection はインストール不要の検出ライブラリであるため、コードを直接変更して実行ロジックを変更できるため、ライブラリに新しいアルゴリズムを追加することも簡単です。
著者は、将来的にはさらに多くのアルゴリズムのサポート (および女性用の衣類) が追加される予定であると述べています。

モデルを再現するために最も重要なことは、基本的に精度がオリジナルのものと同じです。
まず、PPYOLO、PPYOLOv2、PPYOLOE の 3 つのモデルを見てみましょう。著者はすべて、損失アライメントと勾配アライメントの実験を受けています。
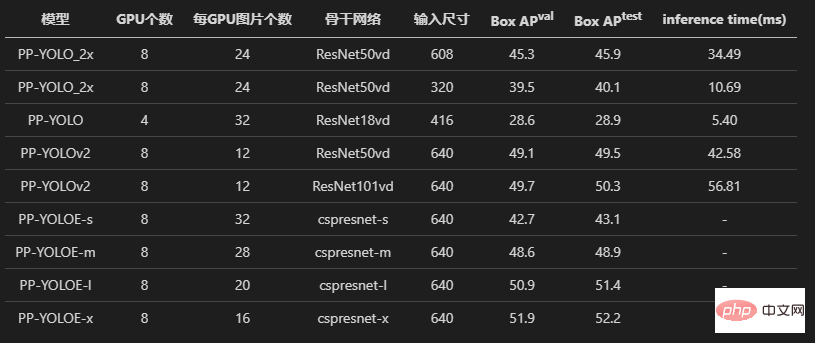
証拠を保存するために、ソース コード内の *.npz の読み取りと書き込みの部分がコメント化されており、すべて残されています。アライメント実験のコードから。
また、著者はパフォーマンス調整のプロセスを詳細に記録しました。初心者にとって、この道に従うことは良い学習プロセスでもあります。
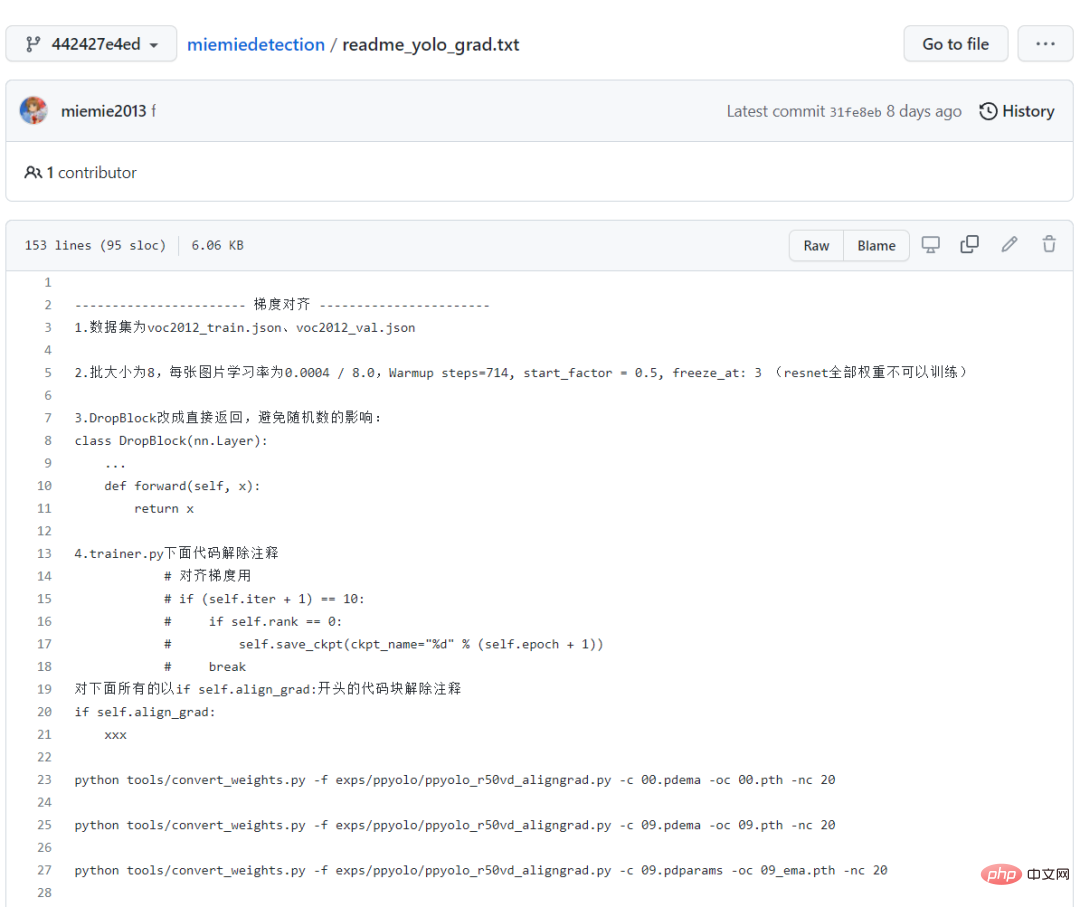
すべてのトレーニング ログも記録され、ウェアハウスに保存されます。これは、PPYOLO シリーズ アルゴリズムの再現が正確であることを証明するのに十分です。
最終的なトレーニング結果は、再現された PPYOLO アルゴリズムが元のウェアハウスと同じ損失と勾配を持っていることを示しています。
さらに、著者は、元のウェアハウスと miemiedetection 転移学習 voc2012 データセットの使用も試みましたが、(同じハイパーパラメータを使用して) 同じ精度も得られました。
元の実装と同じで、同じ学習率、同じ学習率減衰戦略 Warm_piecewisedecay (PPYOLO および PPYOLOv2 で使用) および Warm_cosinedecay (PPYOLOE で使用) を使用し、同じ指数移動平均 EMA 、同じデータ前処理方法、同じパラメータ L2 重み減衰、同じ損失、同じ勾配、同じ事前学習モデル、同じ精度が得られた転移学習。
誰もが素晴らしい体験をできるよう、十分な実験を行い、多くのテストを行いました。
998 または 98 はありません。スターをクリックするだけで、すべてのターゲット検出アルゴリズムを無料で持ち帰ることができます。
モデルのダウンロードと変換モデルを実行したい場合、パラメーターは非常に重要です。作成者は、変換された事前トレーニング pth 重みファイルを提供します。 Baidu Netdisk から直接ダウンロードできます。
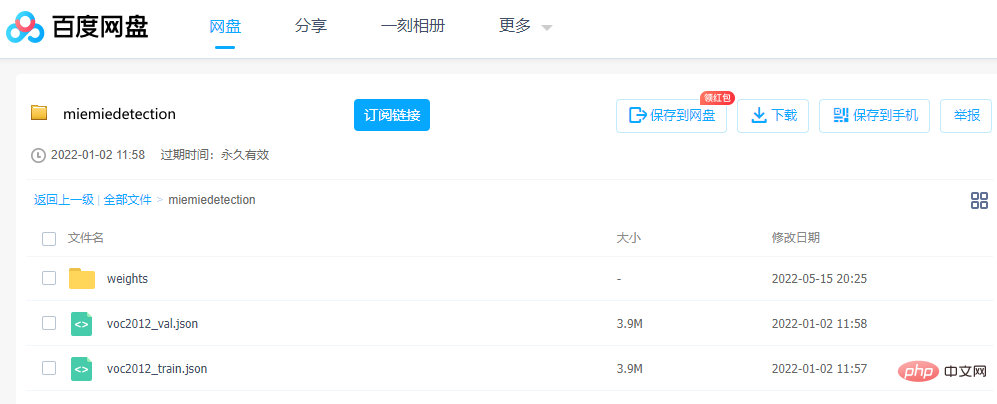 リンク: https://pan.baidu.com/s/1ehEqnNYKb9Nz0XNeqAcwDw
リンク: https://pan.baidu.com/s/1ehEqnNYKb9Nz0XNeqAcwDw
抽出コード: qe3i
または、以下の手順に従って取得します。最初の手順では、重みファイルをダウンロードし、プロジェクトのルート ディレクトリで実行します (つまり、ファイルをダウンロードします。Windows ユーザーは次の手順を使用できます)。 wget をダウンロードするには Thunder またはブラウザを使用します。リンクは、美しさを示すためにここにあります。ppyoloe_crn_l_300e_coco のみが例として使用されています):

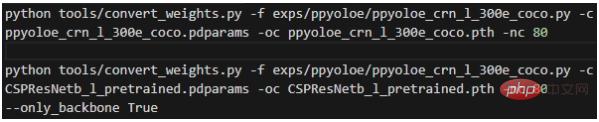
2 番目のステップである重みの変換は、プロジェクトのルート ディレクトリで実行します:
各パラメータの意味は次のとおりです: - -f は使用される構成ファイルを表します。 - -c は読み取りソース重みファイルを表します; - -oc は出力 (保存された) pytorch 重みファイルを表します; - -nc はデータ セット内のカテゴリの数を表します; - --only_backbone True の場合、バックボーン ネットワークの重みのみを変換することを意味します ; 実行後、変換された *.pth 重みファイルがプロジェクトのルート ディレクトリに取得されます。 次のコマンドのほとんどはモデルの構成ファイルを使用するため、最初に構成ファイルについて詳しく説明する必要があります。 。 mmdet.exp.base_exp.BaseExp は構成ファイルの基本クラスであり、モデルの取得方法を示す get_model() などの一連の抽象メソッドを宣言する抽象クラスです。モデルの取得方法を示すget_data_loader()、学習済みデータローダの取得方法、オプティマイザの取得方法を示すget_optimizer()など。 mmdet.exp.datasets.coco_base.COCOBaseExp はデータ セットの構成であり、BaseExp を継承しており、データ セットの構成のみを提供します。このウェアハウスは、COCO アノテーション形式のデータセットのトレーニングのみをサポートしています。 他のアノテーション形式のデータセットは、トレーニング前に COCO アノテーション形式に変換する必要があります (サポートされるアノテーション形式が多すぎると、作業負荷が大きくなりすぎます)。カスタマイズされたデータセットは、miemieLabels を通じて COCO ラベル形式に変換できます。すべての検出アルゴリズム構成クラスは COCOBaseExp を継承します。これは、すべての検出アルゴリズムが同じデータ セット構成を共有することを意味します。 COCOBaseExp の設定項目は次のとおりです。 このうち - self.num_classes はデータ セット内のカテゴリの数を表します; - self.data_dir はデータ セットのルート ディレクトリを表します; - self.cls_names はデータセットのカテゴリ名ファイルパスを表し、txt ファイルで 1 行がカテゴリ名を表します。カスタム データ セットの場合は、新しい txt ファイルを作成してカテゴリ名を編集し、それを指すように self.cls_names を変更する必要があります。 - self.ann_folder は次のことを表します。データセットのアノテーションファイル ルートディレクトリは self.data_dir ディレクトリにある必要があります; - self.train_ann はデータセットのトレーニングセットのアノテーションファイル名を表します - self.val_ann は、データ セットの検証セットのアノテーション ファイル名を表し、self.ann_folder ディレクトリに配置する必要があります。 .ann_folder ディレクトリ; - self.train_image_folder は、データ セットのトレーニング セットの画像フォルダー名を表し、self.data_dir ディレクトリに配置する必要があります。 VOC 2012 データ セットの場合、データ セットの構成を次のように変更する必要があります。 前述のモデルをダウンロードした後、VOC2012 データ セットの self.data_dir ディレクトリに新しいフォルダー annotations2 を作成し、voc2012_train.json と voc2012_val.json をこのファイル フォルダーに配置します。 最後に、COCO データ セット、VOC2012 データ セット、およびこのプロジェクトの配置場所は次のようになります。
mmdet.exp.ppyolo.ppyolo_method_base.PPYOLO_Method_Exp は、特定のアルゴリズムのすべての抽象メソッドを実装するクラスで、すべての抽象メソッドを実装する COCOBaseExp を継承します。 exp.ppyolo.ppyolo_r50vd_2x.Exp は、PPYOLO アルゴリズムの Resnet50Vd モデルの最終構成クラスであり、PPYOLO_Method_Exp を継承します。 # PPYOLOE設定ファイルも同様の構造です。 まず、入力データが画像の場合は、プロジェクトのルート ディレクトリで実行します。 各パラメータの意味は次のとおりです: - -f は使用される構成ファイルを表します; - -c は重みファイルを表します読み取り; - --path は画像のパスを表します; - --conf はスコアのしきい値を表し、予測ボックスのみがそれより高くなりますこのしきい値よりも描画されます; ##- --tsize は、予測中に画像を --tsize にサイズ変更する解像度を表します。予測が完了すると、コンソールには結果画像の保存パスが出力され、ユーザーはそれを開いて表示できます。トレーニング カスタム データ セットに保存されたモデルを予測用に使用している場合は、-c をモデルのパスに変更するだけです。 予測がフォルダー内のすべての画像を対象とする場合は、プロジェクトのルート ディレクトリで実行します: ImageNet 事前トレーニング バックボーン ネットワーク トレーニング COCO データ セットを読み取った場合は、プロジェクトのルート ディレクトリで実行します。 1 つのコマンドで、単一マシン 8 カードのトレーニングが直接開始されます もちろん、実際に単一マシン 8 カードのスーパーコンピューターがあることが前提となります。 -f は使用される構成ファイルを表します; #-b はトレーニング中のバッチ サイズ (すべてのカード) を表します。 -eb評価中のバッチ サイズ (すべてのカード) を表します; -c は読み取り重みファイルを表します; --fp16、自動混合精密トレーニング; --num_machines、マシンの数。単一マシン上で複数のカードを使用してトレーニングすることをお勧めします; - - 再開はトレーニングを再開するかどうかを示します; トレーニング カスタム データ セット 収束が速いため、トレーニングのために COCO 事前トレーニング重みを読み取ることをお勧めします。
トレーニングが何らかの理由で中断され、以前に保存したモデルを読み取ってトレーニングを再開したい場合は、 -c を読みたいモデルへのパスに変更するだけです。 --resume パラメータを追加できます。 2 台のマシンと 2 枚のカード、つまり各マシンに 1 枚のカードがある場合は、マシン 0 で次のコマンドを入力します。 そして、マシン 1 で次のコマンドを入力します。 上記の 192.168.0.107 を変更するだけです。 0 への 2 つのコマンド マシンの LAN IP で十分です。 マシン 1 台とカード 2 枚の場合は、次のコマンドを入力してトレーニングを開始します:
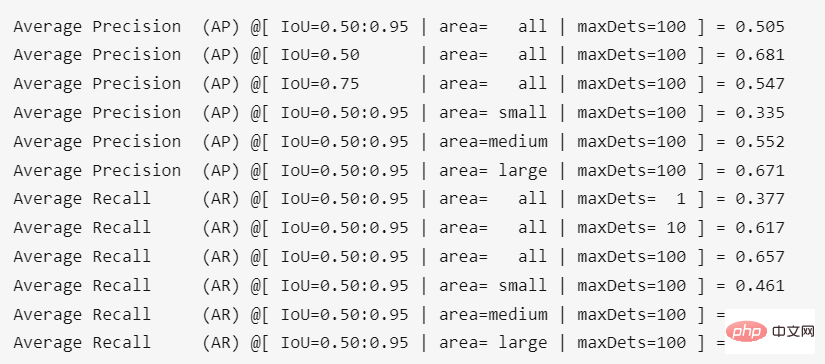
転移学習 VOC2012 データセットでは、ppyolo_r50vd_2x の測定 AP (0.50:0.95) は 0.59、AP (0.50) は 0.82、AP (小) は 0.18 に達する可能性があります。一枚のカードでも複数のカードでもこの結果が得られます。 ppyoloe_l モデルの場合は、単一マシンで次のコマンドを入力してトレーニングを開始します (バックボーン ネットワークがフリーズします)
転移学習 VOC2012 データセットでは、ppyoloe_l の測定 AP (0.50:0.95) は 0.66、AP (0.50) は 0.85、AP (小) は 0.28 に達する可能性があります。 プロジェクトのルート ディレクトリで実行した結果は次のとおりです。 実行後の精度重みに換算すると0.4%程度の若干のロスになります。 
ステップバイステップ チュートリアル


予測

 #トレーニング COCO2017 データ セット
#トレーニング COCO2017 データ セット



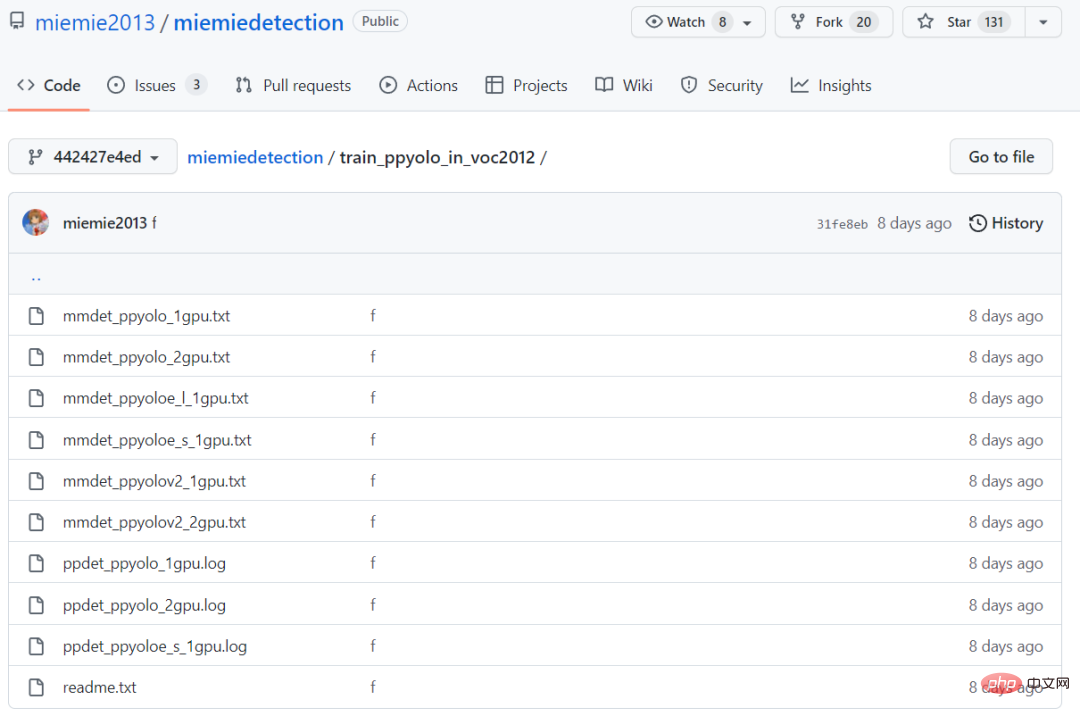
 転移学習中は PaddleDetection と同等の精度と収束速度を実現しており、両方の学習ログは train_ppyolo_in_voc2012 フォルダーにあります。
転移学習中は PaddleDetection と同等の精度と収束速度を実現しており、両方の学習ログは train_ppyolo_in_voc2012 フォルダーにあります。 


以上がGitHub オープンソース 130+Stars: PPYOLO シリーズに基づいたターゲット検出アルゴリズムを再現する方法を段階的に教えますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
テキスト注釈は、テキスト内の特定のコンテンツにラベルまたはタグを対応させる作業です。その主な目的は、特に人工知能の分野で、より深い分析と処理のためにテキストに追加情報を提供することです。テキスト注釈は、人工知能アプリケーションの教師あり機械学習タスクにとって非常に重要です。これは、自然言語テキスト情報をより正確に理解し、テキスト分類、感情分析、言語翻訳などのタスクのパフォーマンスを向上させるために AI モデルをトレーニングするために使用されます。テキスト アノテーションを通じて、AI モデルにテキスト内のエンティティを認識し、コンテキストを理解し、新しい同様のデータが出現したときに正確な予測を行うように教えることができます。この記事では主に、より優れたオープンソースのテキスト注釈ツールをいくつか推奨します。 1.LabelStudiohttps://github.com/Hu
 オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
画像の注釈は、ラベルまたは説明情報を画像に関連付けて、画像の内容に深い意味と説明を与えるプロセスです。このプロセスは機械学習にとって重要であり、画像内の個々の要素をより正確に識別するために視覚モデルをトレーニングするのに役立ちます。画像に注釈を追加することで、コンピュータは画像の背後にあるセマンティクスとコンテキストを理解できるため、画像の内容を理解して分析する能力が向上します。画像アノテーションは、コンピュータ ビジョン、自然言語処理、グラフ ビジョン モデルなどの多くの分野をカバーする幅広い用途があり、車両が道路上の障害物を識別するのを支援したり、障害物の検出を支援したりするなど、幅広い用途があります。医用画像認識による病気の診断。この記事では主に、より優れたオープンソースおよび無料の画像注釈ツールをいくつか推奨します。 1.マケセンス
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
 リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
最新の AIGC オープンソース プロジェクト、AnimagineXL3.1 をご紹介します。このプロジェクトは、アニメをテーマにしたテキストから画像へのモデルの最新版であり、より最適化された強力なアニメ画像生成エクスペリエンスをユーザーに提供することを目的としています。 AnimagineXL3.1 では、開発チームは、モデルのパフォーマンスと機能が新たな高みに達することを保証するために、いくつかの重要な側面の最適化に重点を置きました。まず、トレーニング データを拡張して、以前のバージョンのゲーム キャラクター データだけでなく、他の多くの有名なアニメ シリーズのデータもトレーニング セットに含めました。この動きによりモデルの知識ベースが充実し、さまざまなアニメのスタイルやキャラクターをより完全に理解できるようになります。 AnimagineXL3.1 では、特別なタグと美学の新しいセットが導入されています
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
