

Graph-DETR3D: マルチビュー 3D オブジェクト検出における重複領域の再考

arXiv 論文「Graph-DETR3D: マルチビュー 3D オブジェクト検出のための重複領域の再考」、6 月 22 日、中国科学技術大学、ハルビン工業大学、および SenseTime の研究。

複数の画像ビューから 3D オブジェクトを検出することは、視覚的なシーンを理解する上で基本的ですが困難なタスクです。マルチビュー 3D 物体検出は、その低コストと高効率により、幅広い応用の可能性を示しています。ただし、奥行き情報が不足しているため、3 次元空間で遠近法を通じてオブジェクトを正確に検出することは非常に困難です。最近、DETR3D は、3D オブジェクト検出のためにマルチビュー画像を集約するための新しい 3D-2D クエリ パラダイムを導入し、最先端のパフォーマンスを実現します。
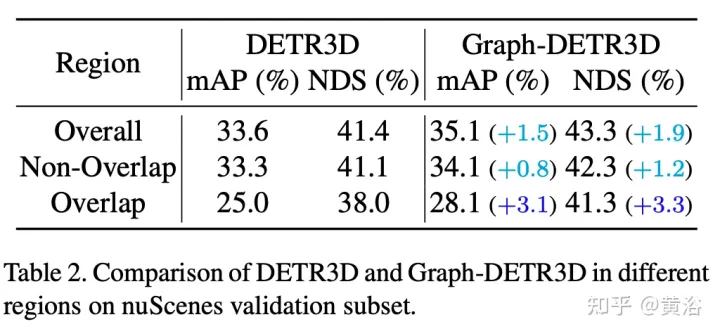
この論文では、集中的なガイド付き実験を通じて、さまざまな領域にあるターゲットを定量化し、「切り詰められたインスタンス」(つまり、各画像の境界領域) が DETR3D のパフォーマンスを妨げる主なボトルネックであることを発見しました。 DETR3D は、重なり合う領域で 2 つの隣接するビューからの複数の特徴を結合しているにもかかわらず、依然として特徴の集約が不十分であるため、検出パフォーマンスを完全に向上させる機会を逃しています。
この問題を解決するために、グラフ構造学習(GSL)によって多視点画像情報を自動的に集約するGraph-DETR3Dが提案されています。動的 3D マップは、特に境界領域でのターゲット表現を強化するために、各ターゲット クエリと 2D 特徴マップの間に構築されます。さらに、Graph-DETR3D は、画像サイズとターゲット深度を同時にスケーリングすることで視覚的な深度の一貫性を維持する、新しい深度不変マルチスケール トレーニング戦略の恩恵を受けています。
Graph-DETR3D の違いは、図に示すように、(1) 動的グラフ特徴の集約モジュール、(2) 深さ不変のマルチスケール トレーニング戦略の 2 点にあります。 DETR3D の基本構造に従い、画像エンコーダー、トランスフォーマー デコーダー、ターゲット予測ヘッドの 3 つのコンポーネントで構成されます。一連の画像 I = {I1, I2,…,IK} (N 個のペリビュー カメラで撮影) が与えられた場合、Graph-DETR3D は、対象の境界ボックスの位置とカテゴリを予測することを目的としています。まず、画像エンコーダ (ResNet や FPN を含む) を使用して、これらの画像を比較的 L 個の特徴マップレベルの特徴 F のセットに変換します。次に、動的 3-D グラフが構築され、動的グラフ機能集約 (DGFA) モジュールを通じて 2-D 情報が広範囲に集約され、ターゲット クエリの表現が最適化されます。最後に、強化されたターゲット クエリを利用して最終予測を出力します。
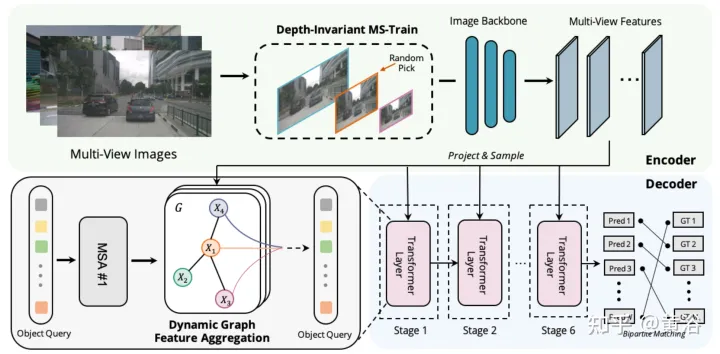
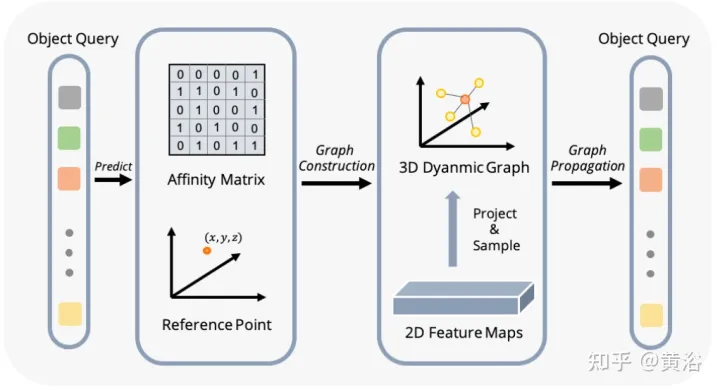
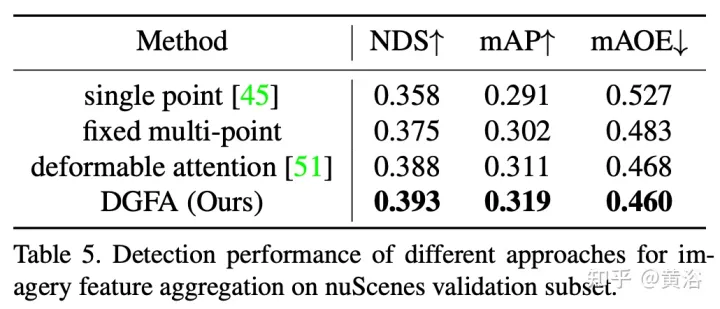
図は、動的グラフ特徴集約 (DFGA) プロセスを示しています。まず、ターゲット クエリごとに学習可能な 3-D グラフを構築し、次に学習可能な 3-D グラフを構築します。 2D 画像平面からのサンプリング特性。最後に、ターゲット クエリの表現は、グラフ接続を通じて強化されます。この相互接続されたメッセージ伝播スキームは、グラフ構造の構築と機能強化の反復的な改良をサポートします。
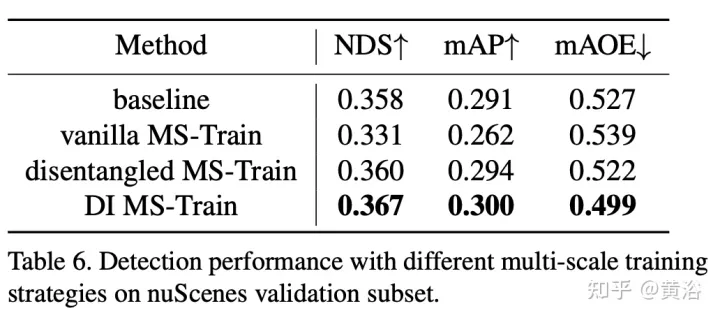
マルチスケール トレーニングは、2D および 3D の物体検出タスクで一般的に使用されるデータ拡張戦略であり、効果的で低コストの推論であることが証明されています。ただし、視覚ベースの 3D 検査方法ではほとんど表示されません。さまざまな入力画像サイズを考慮すると、画像サイズを調整し、カメラの内部パラメータを変更して共通のマルチスケール トレーニング戦略を実装しながら、モデルの堅牢性を向上させることができます。
興味深い現象は、最終的なパフォーマンスが急激に低下することです。入力データを注意深く分析することにより、単に画像を再スケールすると遠近の曖昧さの問題が生じることがわかりました。ターゲットのサイズをより大きい/より小さいスケールに変更すると、その絶対的なプロパティ (ターゲットのサイズ、自我までの距離など)ポイント)変更しないでください。
具体例として、(a)と(b)の選択領域の絶対的な3次元位置は同じであるが、画像のピクセル数が異なるという曖昧な問題を図に示します。深度予測ネットワークは、画像の占有領域に基づいて深度を推定する傾向があります。したがって、図のこのトレーニング パターンは深さ予測モデルを混乱させ、最終的なパフォーマンスをさらに低下させる可能性があります。

この目的のために、ピクセルの観点から深度を再計算します。アルゴリズムの疑似コードは次のとおりです。

デコード操作は次のとおりです。

再計算されたピクセル サイズは次のとおりです:
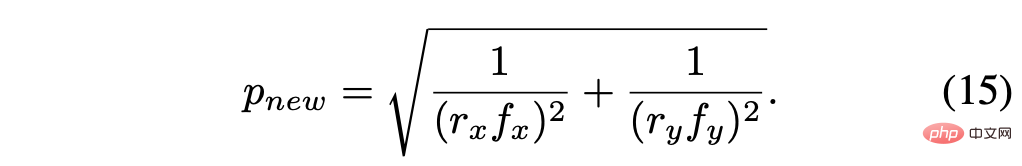
スケール係数 r = rx = ry と仮定すると、単純化して次のようになります:
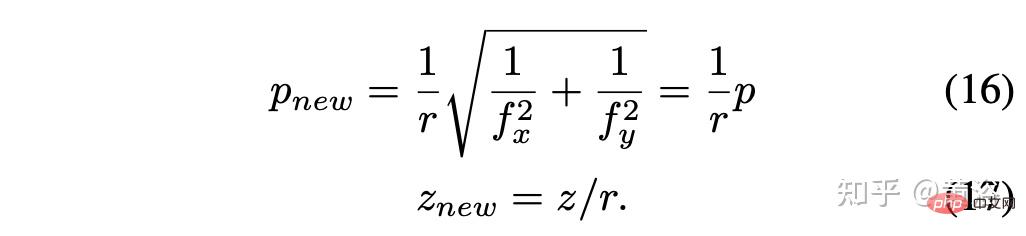
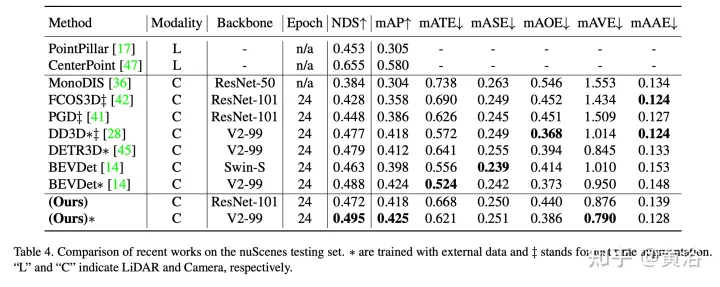
#実験結果は次のとおりです。
以上がGraph-DETR3D: マルチビュー 3D オブジェクト検出における重複領域の再考の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7725
7725
 15
1643
14
1397
52
1290
25
1233
29
15
1643
14
1397
52
1290
25
1233
29

 座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
最初のパイロットおよび重要な記事では、主に自動運転技術で一般的に使用されるいくつかの座標系と、それらの間の相関と変換を完了し、最終的に統合環境モデルを構築する方法を紹介します。ここでの焦点は、車両からカメラの剛体への変換 (外部パラメータ)、カメラから画像への変換 (内部パラメータ)、および画像からピクセル単位への変換を理解することです。 3D から 2D への変換には、対応する歪み、変換などが発生します。要点:車両座標系とカメラ本体座標系を平面座標系とピクセル座標系に書き換える必要がある 難易度:画像の歪みを考慮する必要がある 歪み補正と歪み付加の両方を画面上で補正する2. はじめに ビジョンシステムには、ピクセル平面座標系 (u, v)、画像座標系 (x, y)、カメラ座標系 ()、世界座標系 () の合計 4 つの座標系があります。それぞれの座標系には関係性があり、
 正確なオブジェクト検出のためのマルチグリッド冗長境界ボックス注釈
Jun 01, 2024 pm 09:46 PM
正確なオブジェクト検出のためのマルチグリッド冗長境界ボックス注釈
Jun 01, 2024 pm 09:46 PM
1. はじめに 現在、主要なオブジェクト検出器は、深層 CNN のバックボーン分類器ネットワークを再利用した 2 段階または 1 段階のネットワークです。 YOLOv3 は、入力画像を受け取り、それを等しいサイズのグリッド マトリックスに分割する、よく知られた最先端の 1 段階検出器の 1 つです。ターゲット中心を持つグリッド セルは、特定のターゲットの検出を担当します。今日私が共有するのは、各ターゲットに複数のグリッドを割り当てて正確なタイトフィット境界ボックス予測を実現する新しい数学的手法です。研究者らはまた、ターゲット検出のための効果的なオフラインのコピー&ペーストデータの強化も提案しました。新しく提案された方法は、現在の最先端の物体検出器の一部よりも大幅に性能が優れており、より優れたパフォーマンスが期待されます。 2. バックグラウンドターゲット検出ネットワークは、次のように設計されています。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 ターゲット検出用の新しい SOTA: YOLOv9 が登場し、新しいアーキテクチャにより従来の畳み込みが復活します
Feb 23, 2024 pm 12:49 PM
ターゲット検出用の新しい SOTA: YOLOv9 が登場し、新しいアーキテクチャにより従来の畳み込みが復活します
Feb 23, 2024 pm 12:49 PM
ターゲット検出の分野では、YOLOv9 は実装プロセスで進歩を続けており、新しいアーキテクチャとメソッドを採用することにより、従来の畳み込みのパラメータ利用を効果的に改善し、そのパフォーマンスが前世代の製品よりもはるかに優れています。 2023 年 1 月に YOLOv8 が正式にリリースされてから 1 年以上が経過し、ついに YOLOv9 が登場しました。 2015 年に Joseph Redmon 氏や Ali Farhadi 氏らが第 1 世代の YOLO モデルを提案して以来、ターゲット検出分野の研究者たちはそれを何度も更新し、反復してきました。 YOLO は画像のグローバル情報に基づく予測システムであり、そのモデルのパフォーマンスは継続的に強化されています。アルゴリズムとテクノロジーを継続的に改善することにより、研究者は目覚ましい成果を上げ、ターゲット検出タスクにおける YOLO をますます強力にしています。
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
 初のマルチビュー自動運転シーンビデオ生成世界モデル | DrivingDiffusion: BEV データとシミュレーションの新しいアイデア
Oct 23, 2023 am 11:13 AM
初のマルチビュー自動運転シーンビデオ生成世界モデル | DrivingDiffusion: BEV データとシミュレーションの新しいアイデア
Oct 23, 2023 am 11:13 AM
著者の個人的な考えの一部 自動運転の分野では、BEV ベースのサブタスク/エンドツーエンド ソリューションの開発に伴い、高品質のマルチビュー トレーニング データとそれに対応するシミュレーション シーンの構築がますます重要になってきています。現在のタスクの問題点に対応して、「高品質」は 3 つの側面に分離できます。 さまざまな次元のロングテール シナリオ: 障害物データ内の近距離車両、車両切断中の正確な進行角、車線などラインデータ 曲率の異なるカーブやランプ・合流・合流などの撮影が難しいシーン。これらは多くの場合、大量のデータ収集と複雑なデータ マイニング戦略に依存しており、コストがかかります。 3D 真の値 - 一貫性の高い画像: 現在の BEV データ取得は、センサーの設置/校正、高精度マップ、再構成アルゴリズム自体のエラーの影響を受けることがよくあります。これが私を導いた
 GSLAM | 一般的な SLAM アーキテクチャとベンチマーク
Oct 20, 2023 am 11:37 AM
GSLAM | 一般的な SLAM アーキテクチャとベンチマーク
Oct 20, 2023 am 11:37 AM
19 年前の論文を突然発見 GSLAM: A General SLAM Framework and Benchmark オープンソース コード: https://github.com/zdzhaoyong/GSLAM 全文に直接アクセスして、この作品の品質を感じてください ~ 1 抽象的な SLAM テクノロジー近年多くの成功を収め、多くのハイテク企業の注目を集めています。ただし、既存または新たなアルゴリズムへのインターフェイスを使用して、速度、堅牢性、移植性に関するベンチマークを効果的に実行する方法は依然として問題です。この論文では、GSLAM と呼ばれる新しい SLAM プラットフォームを提案します。これは、評価機能を提供するだけでなく、研究者が独自の SLAM システムを迅速に開発するための有用な方法を提供します。
