

研究によると、強化学習モデルはメンバーシップ推論攻撃に対して脆弱であることが示されています

翻訳者 | Li Rui
レビュアー | Sun Shujuan
機械学習が人々が毎日使用する多くのアプリケーションの一部となるにつれて、人々はますます注目を集めています。機械学習モデルに対するセキュリティとプライバシーの脅威を特定して対処する方法。
ただし、機械学習のパラダイムが異なれば、直面するセキュリティの脅威も異なり、機械学習のセキュリティの一部の領域は依然として研究が不十分です。特に、強化学習アルゴリズムの安全性は、近年あまり注目されていません。
マギル大学、機械学習研究所 (MILA)、カナダのウォータールー大学の研究者は、深層強化学習アルゴリズムのプライバシーの脅威に焦点を当てた新しい研究を実施しました。研究者らは、メンバーシップ推論攻撃に対する強化学習モデルの脆弱性をテストするためのフレームワークを提案しています。
研究結果によると、攻撃者は深層強化学習 (RL) システムを効果的に攻撃でき、モデルのトレーニングに使用される機密情報を取得する可能性があります。強化学習技術が現在、産業用および民生用アプリケーションに浸透しているため、彼らの発見は重要です。
メンバー推論攻撃
メンバー推論攻撃は、ターゲットの機械学習モデルの動作を観察し、そのトレーニングに使用される例を予測します。 。
すべての機械学習モデルは、一連の例に基づいてトレーニングされます。場合によっては、トレーニングの例には、健康データや財務データ、その他の個人を特定できる情報などの機密情報が含まれます。
メンバー推論攻撃は、機械学習モデルにトレーニング セット データを強制的に漏洩させようとする一連の手法です。敵対的な例 (機械学習に対するよりよく知られたタイプの攻撃) は、機械学習モデルの動作の変更に焦点を当てており、セキュリティ上の脅威とみなされますが、メンバーシップ推論攻撃は、モデルからの情報の抽出に焦点を当てており、プライバシーの脅威としてより重要です。
メンバーシップ推論攻撃は、ラベル付きサンプルでモデルがトレーニングされる教師あり機械学習アルゴリズムでよく研究されています。
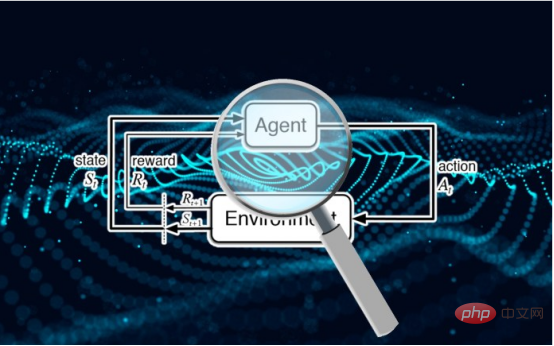
教師あり学習とは異なり、深層強化学習システムはラベル付きサンプルを使用しません。強化学習 (RL) エージェントは、環境との相互作用から報酬またはペナルティを受け取ります。これらの相互作用や強化信号を通じて、徐々に学習し、その行動を発展させます。
論文の著者らは書面によるコメントで、「強化学習における報酬は必ずしもラベルを表すわけではない。したがって、他の学習におけるメンバーシップ推論攻撃の設計でよく使用される予測として機能することはできない」と述べた。
研究者らは論文の中で、「深層強化学習エージェントのトレーニングに直接使用されたデータのメンバーが漏洩する可能性に関する研究は現時点では行われていない。」と書いています。
研究が不足している理由の 1 つは、強化学習の実世界への応用が限られていることです。
研究論文の著者らは次のように述べています。「Alpha Go、Alpha Fold、GT Sophy などの深層強化学習の分野では大きな進歩があったにもかかわらず、深層強化学習モデルは依然として「産業規模では利用できません。広く採用されています。その一方で、データプライバシーは非常に広く使用されている研究分野です。実際の産業応用における深層強化学習モデルの欠如により、この基礎的かつ重要な研究分野の研究が大幅に遅れています。」 「その結果、強化学習システムに関する研究が不足しています。攻撃は十分に研究されていません。」
現実世界のシナリオで強化学習アルゴリズムを産業規模で適用する需要が高まる中、強化学習アルゴリズムのプライバシーの側面に敵対的およびアルゴリズムの観点から取り組む必要があり、フレームワークの焦点と厳格な要件がますます明らかになり、関連性が高まっています。
深層強化学習におけるメンバーシップ推論の課題
#研究論文の著者らは次のように述べています。プライバシー保護の世代深層強化学習アルゴリズムに対する私たちの取り組みにより、プライバシーの観点から、従来の機械学習アルゴリズムと強化学習アルゴリズムの間には基本的な構造の違いがあることがわかりました。」
さらに重要なことに、研究者らは、深層強化学習と他の学習パラダイムの根本的な違いが、潜在的なプライバシーへの影響を考慮すると、深層強化学習モデルを実際のアプリケーションに展開する際に深刻な課題を引き起こしていることを発見しました。
彼らはこう言いました、「この認識に基づいて、私たちにとって大きな疑問は、深層強化学習アルゴリズムがメンバーシップ推論攻撃などのプライバシー攻撃に対してどの程度脆弱かということです。現在、推論攻撃の攻撃モデルは次のとおりです。」他の学習パラダイム向けに特別に設計されているため、そのような攻撃に対する深層強化学習アルゴリズムの脆弱性はほとんど知られていません。世界中での展開によるプライバシーへの深刻な影響を考えると、未知のものに対する好奇心と、研究と業界の意識を高める必要性は、
トレーニング プロセス中、強化学習モデルは複数のフェーズを通過し、各フェーズはアクションと状態の軌跡またはシーケンスで構成されます。したがって、強化学習のメンバーシップ推論攻撃アルゴリズムを成功させるには、モデルのトレーニングに使用されるデータ ポイントと軌跡を学習する必要があります。これにより、強化学習システムのメンバーシップ推論アルゴリズムの設計がより困難になる一方で、そのような攻撃に対する強化学習モデルの堅牢性の評価も困難になります。
著者らは、「メンバーシップ推論攻撃 (MIA) は、トレーニング中に使用されるデータ ポイントが連続的で時間に依存する性質を持っているため、他のタイプの機械学習と比較して強化学習では困難です。」と述べています。トレーニング データ ポイントと予測データ ポイントの間の多対多の関係は、他の学習パラダイムとは根本的に異なります。」
強化学習と他の機械学習パラダイムの基本的な関係この違いが重要です深層強化学習のためのメンバーシップ推論攻撃を設計および評価する際に、新しい方法で考えることができます。
強化学習システムに対するメンバーシップ推論攻撃の設計
研究者らは、研究の中で、データ収集とモデルのトレーニング プロセスが行われる非ポリシー強化学習アルゴリズムに焦点を当てました。別。強化学習では、「リプレイ バッファー」を使用して入力軌跡の相関を取り除き、強化学習エージェントが同じデータ セットから多くの異なる軌跡を探索できるようにします。
非ポリシー強化学習は、トレーニング データが事前に存在し、強化学習モデルをトレーニングしている機械学習チームに提供される多くの実世界のアプリケーションにとって特に重要です。非ポリシー強化学習は、メンバーシップ推論攻撃モデルを作成する場合にも重要です。
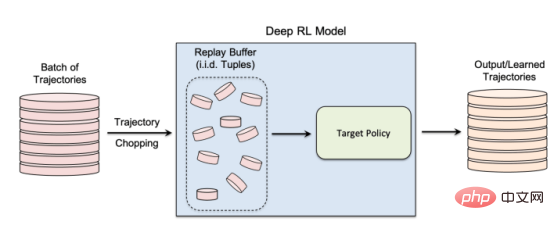
#非ポリシー強化学習では、「再生バッファー」を使用して、モデルのトレーニング中に以前に収集されたデータを再利用します
著者らは、「真の非ポリシー強化学習モデルでは探索フェーズと悪用フェーズが分離されている。したがって、ターゲットポリシーはトレーニング軌道に影響を与えない。このセットアップは、メンバー推論攻撃フレームワークを設計する場合に特に適している」と述べている。ブラック ボックス環境。攻撃者はターゲット モデルの内部構造も、トレーニング トラジェクトリの収集に使用される探索戦略も知らないからです。」
ブラック ボックス メンバーシップ推論攻撃では、攻撃者は、トレーニングされた強化学習モデルの動作を観察することしかできません。この特定のケースでは、攻撃者は、ターゲット モデルがプライベート データのセットから生成された軌跡でトレーニングされていると想定します。これが、非ポリシー強化学習の仕組みです。
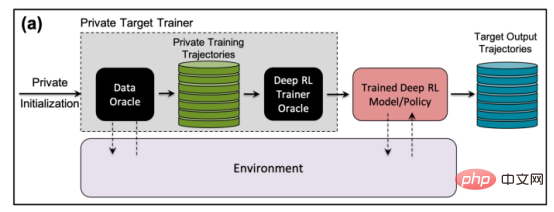
研究では、研究者らは高度な非ポリシー強化学習アルゴリズムである「バッチ制約ディープ Q ラーニング」(BCQ) を選択しました。制御タスクで優れたパフォーマンスを発揮します。ただし、彼らは、メンバーシップ推論攻撃手法が他の非ポリシー強化学習モデルにも拡張できることを示しています。
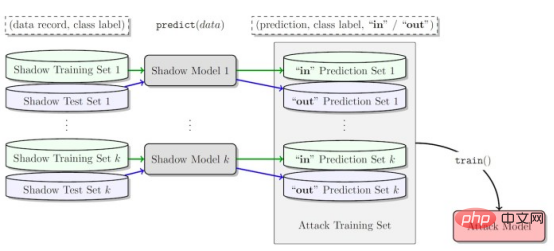
攻撃者がメンバーシップ推論攻撃を実行できる方法の 1 つは、「シャドウ モデル」を開発することです。これは、ターゲット モデルのトレーニング データなどと同じ分布からのデータの混合物でトレーニングされた分類器機械学習モデルです。トレーニング後、シャドウ モデルは、ターゲットの機械学習モデルのトレーニング セットに属するデータ ポイントと、モデルがこれまでに見たことのない新しいデータを区別できます。ターゲット モデルのトレーニングは逐次的に行われる性質があるため、強化学習エージェント用のシャドウ モデルの作成は困難です。研究者らはいくつかの段階を経てこれを達成した。
まず、強化学習モデル トレーナーに新しい非プライベート データ トラジェクトリのセットを供給し、ターゲット モデルによって生成されたトラジェクトリを観察します。次に、攻撃トレーナーは、トレーニングおよび出力軌跡を使用して機械学習分類器をトレーニングし、ターゲットの強化学習モデルのトレーニングに使用された入力軌跡を検出します。最後に、分類子には、トレーニング メンバーまたは新しいデータ例として分類するための新しい軌跡が提供されます。
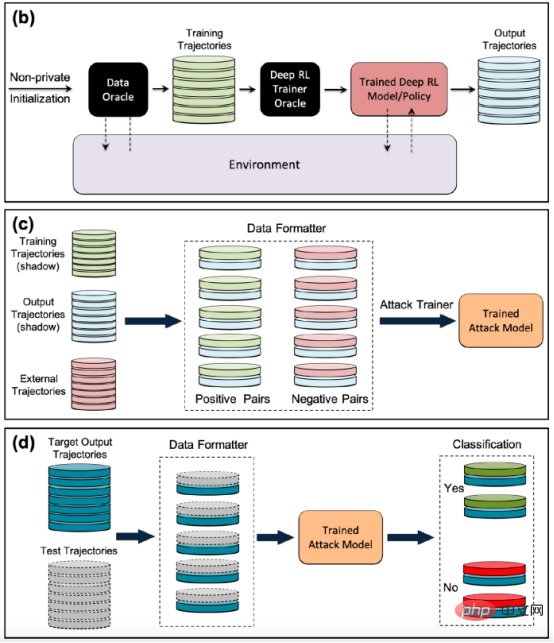
#強化学習モデルに対するメンバー推論攻撃をトレーニングするためのシャドウ モデル
強化学習システムに対するメンバー推論攻撃のテスト研究者らは、異なる軌道長、単一軌道と複数軌道、相関軌道と無相関軌道など、さまざまなモードでメンバーシップ推論攻撃をテストしました。
研究者らは論文の中で次のように述べています。「結果は、私たちが提案した攻撃フレームワークが強化学習モデルのトレーニング データ ポイントの推論において非常に効果的であることを示しています...得られた結果は、There を使用することを示しています。
彼らの結果は、複数の軌道による攻撃が単一の軌道による攻撃よりも効果的であり、軌道が長くなるほど、それぞれの軌道と相関があることを示しています。その他、攻撃の精度も上がります。
著者らは、「自然環境はもちろん個人のモデルであり、攻撃者はターゲットの強化を訓練するために使用される訓練セット内の特定の個人の存在を識別することに興味を持っています」と述べています。ただし、集団モードでのメンバーシップ推論攻撃 (MIA) のパフォーマンスが向上したことは、トレーニング ポリシーの特徴によって捕捉された時間的相関に加えて、攻撃者が学習ポリシーを悪用できることを示しています。
研究者らは、これは、攻撃者が性別間の相互相関を悪用するには、より複雑な学習アーキテクチャとより洗練されたハイパーパラメータ調整を必要とすることも意味すると述べています。トレーニングの軌跡と軌跡の時間の相関関係。
「これらのさまざまな攻撃モードを理解することで、何が起こるかをより深く理解できるため、データのセキュリティとプライバシーへの影響をより深く理解できるようになります」と研究者らは述べています。さまざまな攻撃角度とプライバシー漏洩への影響度。」
現実世界における強化学習システムに対するメンバー推論攻撃
研究者らは、Open AIGym および MuJoCo 物理エンジンに基づく 3 つのタスクでトレーニングされた強化学習モデルに対する攻撃をテストしました。
研究者らは、「私たちの現在の実験は、ホッパー、ハーフチーター、アントという 3 つの高次元運動タスクをカバーしています。これらのタスクはすべてロボット シミュレーション タスクであり、主に実験を促進します。アプリケーション メンバーが攻撃を推測するためのもう 1 つの興味深い方向性は、Amazon Alexa、Apple の Siri、Google アシスタントなどの会話システムです。これらのアプリケーションでは、データ ポイントはチャットボットとエンド ユーザー間の完全な対話トレースによって表示されます。この設定では、チャットボットはトレーニングされた強化学習ポリシーであり、ユーザーとロボットの対話が入力軌跡を形成します。
著者らは、「この場合、集合的なパターンは自然環境です。言い換えれば、攻撃者がユーザーを表す一連の軌跡を正しく推測した場合に限ります」と述べています。
チームは、そのような攻撃が強化学習システムに影響を与える可能性がある他の実用的なアプリケーションを検討しています。また、これらの攻撃が他の状況での強化学習にどのように適用できるかについても研究する可能性があります。
著者らは、「この研究領域の興味深い拡張は、ターゲットポリシーの内部構造が異なるホワイトボックス環境で深層強化学習モデルに対するメンバー推論攻撃を研究することです」と述べています。
研究者らは、自分たちの研究が現実世界の強化学習アプリケーションにおけるセキュリティとプライバシーの問題に光を当て、機械学習コミュニティの意識を高めることを期待しています。さらなる研究を。
元のタイトル:
強化学習モデルはメンバーシップ推論攻撃を受けやすい以上が研究によると、強化学習モデルはメンバーシップ推論攻撃に対して脆弱であることが示されていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7468
7468
 15
1376
52
77
11
19
27
15
1376
52
77
11
19
27

 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ では、機械学習アルゴリズムの実装には以下が含まれます。 線形回帰: 連続変数を予測するために使用されるステップには、データの読み込み、重みとバイアスの計算、パラメーターと予測の更新が含まれます。ロジスティック回帰: 離散変数の予測に使用されます。このプロセスは線形回帰に似ていますが、予測にシグモイド関数を使用します。サポート ベクター マシン: サポート ベクターの計算とラベルの予測を含む強力な分類および回帰アルゴリズム。
 Java フレームワークのセキュリティ アーキテクチャ設計は、ビジネス ニーズとどのようにバランスをとる必要がありますか?
Jun 04, 2024 pm 02:53 PM
Java フレームワークのセキュリティ アーキテクチャ設計は、ビジネス ニーズとどのようにバランスをとる必要がありますか?
Jun 04, 2024 pm 02:53 PM
Java フレームワーク設計では、セキュリティ ニーズとビジネス ニーズのバランスをとることでセキュリティを実現し、主要なビジネス ニーズを特定し、関連するセキュリティ要件に優先順位を付けます。柔軟なセキュリティ戦略を策定し、脅威に階層的に対応し、定期的に調整します。アーキテクチャの柔軟性を考慮し、ビジネスの進化をサポートし、抽象的なセキュリティ機能を考慮します。効率と可用性を優先し、セキュリティ対策を最適化し、可視性を向上させます。
 画期的な CVM アルゴリズムが 40 年以上の計数の問題を解決します。コンピューター科学者がコインを投げて「ハムレット」を表す固有の単語を割り出す
Jun 07, 2024 pm 03:44 PM
画期的な CVM アルゴリズムが 40 年以上の計数の問題を解決します。コンピューター科学者がコインを投げて「ハムレット」を表す固有の単語を割り出す
Jun 07, 2024 pm 03:44 PM
数を数えるのは簡単そうに思えますが、実際にやってみるととても難しいです。あなたが野生動物の個体数調査を実施するために自然のままの熱帯雨林に運ばれたと想像してください。動物を見かけたら必ず写真を撮りましょう。デジタル カメラでは追跡された動物の総数のみが記録されますが、固有の動物の数に興味がありますが、統計はありません。では、このユニークな動物群にアクセスする最善の方法は何でしょうか?この時点で、今すぐ数え始めて、最後に写真から各新種をリストと比較すると言わなければなりません。ただし、この一般的なカウント方法は、数十億エントリに達する情報量には適さない場合があります。インド統計研究所、UNL、およびシンガポール国立大学のコンピューター科学者は、新しいアルゴリズムである CVM を提案しました。長いリスト内のさまざまな項目の計算を近似できます。
 Golang 機械学習アプリケーション: インテリジェントなアルゴリズムとデータ駆動型ソリューションの構築
Jun 02, 2024 pm 06:46 PM
Golang 機械学習アプリケーション: インテリジェントなアルゴリズムとデータ駆動型ソリューションの構築
Jun 02, 2024 pm 06:46 PM
Golang で機械学習を使用して、インテリジェントなアルゴリズムとデータ駆動型ソリューションを開発します。機械学習アルゴリズムとユーティリティ用の Gonum ライブラリをインストールします。 Gonum の LinearRegression モデル、教師あり学習アルゴリズムを使用した線形回帰。入力変数とターゲット変数を含むトレーニング データを使用してモデルをトレーニングします。新しい特徴に基づいて住宅価格を予測し、モデルはそこから線形関係を抽出します。
