

ゼロから構築された DeepMind の新しい論文では、擬似コードを使用して Transformer を詳細に説明しています

Transformer は 2017 年に誕生し、Google の論文「attention is all you need」で紹介されました。このペーパーでは、以前の深層学習タスクで使用されていた CNN と RNN を放棄します。この画期的な研究は、シーケンス モデリングと RNN を同一視するというこれまでの考えを覆し、現在では NLP で広く使用されています。人気のある GPT、BERT などはすべて Transformer 上に構築されています。
トランス その導入以来、研究者は多くのバリエーションを提案してきました。しかし、Transformer についての皆さんの説明は、言語形式や図による説明などでアーキテクチャを紹介しているようです。 Transformer の疑似コードの説明について利用できる情報はほとんどありません。
次の文章で表現されているように: AI の分野で非常に有名な研究者が、有名な複雑性理論家に、非常によく書かれていると思われる論文を送ったことがあります。そして理論家の答えは次のとおりです。論文には定理が見つかりません。論文が何について書いているのかわかりません。
論文は実務家にとっては十分に詳細なものかもしれませんが、理論家が要求する精度は通常より高くなります。何らかの理由で、DL コミュニティはニューラル ネットワーク モデルの疑似コードを提供することに消極的であるようです。
現在、DL コミュニティには次の問題があるようです。
DL 出版物には科学的な正確さと詳細が欠けています。ディープラーニングは過去 5 ~ 10 年にわたって大きな成功を収めており、毎年数千の論文が発表されています。多くの研究者は、以前のモデルをどのように変更したかを非公式に説明するだけで、100 ページを超える論文には非公式のモデルの説明が数行しか含まれていません。せいぜい、いくつかの高レベルの図があり、疑似コードや方程式はなく、モデルの正確な解釈についての言及もありません。有名な Transformer とそのエンコーダ/デコーダのバリアントの疑似コードを提供する人さえいません。
ソースコードと疑似コード。オープンソースのソース コードは非常に便利ですが、実際のソース コードが数千行あるのに比べ、適切に設計された疑似コードは通常 1 ページ未満であり、それでも本質的には完成しています。それは誰もやりたくない大変な仕事のように思えました。
トレーニング プロセスの説明も同様に重要ですが、論文ではモデルの入力と出力が何であるか、潜在的な副作用が何であるかさえ言及されていないことがあります。論文の実験セクションでは、アルゴリズムに何がどのように入力されるかが説明されていないことがよくあります。 「方法」セクションに何らかの説明がある場合、「実験」セクションで説明されている内容と乖離していることがよくあります。これはおそらく、異なる著者が異なるセクションを書いたためと考えられます。
「疑似コードは本当に必要ですか? 疑似コードは何に使うのですか?」と疑問に思う人もいるかもしれません。
DeepMind の研究者は、疑似コードの提供には多くの用途があると考えています。記事を読んだり、1000 行の実際のコードをスクロールしたりするのと比較して、疑似コードはすべての重要なコンテンツを 1 ページに凝縮しています。新しいバリアントの開発が容易になります。この目的を達成するために、彼らは最近、完全かつ数学的に正確な方法で Transformer アーキテクチャを説明する論文「Formal Algorithms for Transformers」を発表しました。
論文の紹介
この記事では、Transformer とは何か、Transformer のトレーニング方法、Transformer の用途、Transformer の主要なアーキテクチャ コンポーネント、およびプレビューについて説明します。より有名なモデルの。

論文アドレス: https://arxiv.org/pdf/2207.09238.pdf ##ただし、この記事を読むには、読者は基本的な ML 用語と単純なニューラル ネットワーク アーキテクチャ (MLP など) に精通している必要があります。読者は、記事の内容を理解した後、Transformer をしっかりと理解し、疑似コードを使用して独自の Transformer バリアントを実装できるようになります。
この文書の主要部分は第 3 章から 8 章で、Transformer とその典型的なタスク、トークン化、Transformer のアーキテクチャ構成、Transformer のトレーニングと推論、および実際のアプリケーションを紹介します。
 論文内の基本的に完全な疑似コードの長さは約 50 行ですが、実際の実際のソース コードの長さは数千行です。論文内のアルゴリズムを説明する擬似コードは、コンパクトで完全かつ正確な式を必要とする理論研究者、Transformer を最初から実装する実験研究者に適しており、また、正式な Transformer アルゴリズムを使用して論文や教科書を拡張する場合にも役立ちます。
論文内の基本的に完全な疑似コードの長さは約 50 行ですが、実際の実際のソース コードの長さは数千行です。論文内のアルゴリズムを説明する擬似コードは、コンパクトで完全かつ正確な式を必要とする理論研究者、Transformer を最初から実装する実験研究者に適しており、また、正式な Transformer アルゴリズムを使用して論文や教科書を拡張する場合にも役立ちます。

論文内の疑似コードの例
基本的な ML 用語と簡単なニューラルに精通している人向けネットワーク アーキテクチャ 初心者 (MLP など) 向けに、このペーパーは強固な Transformer の基礎をマスターし、疑似コード テンプレートを使用して独自の Transformer モデルを実装するのに役立ちます。
著者紹介
この論文の筆頭著者は、今年 3 月に DeepMind に正式に入社した研究者、Mary Phuong です。彼女はオーストリア科学技術大学で博士号を取得し、主に機械学習の理論研究に従事しました。

この論文のもう一人の著者は、DeepMind の上級研究員である Marcus Hutter です。オーストラリア国立大学 (ANU) コンピューターサイエンス研究所 (RSCS) の名誉教授。

Marcus Hutter は、多くの人のために人工知能の数学理論の研究に従事してきました。年。この研究分野は、強化学習、確率理論、アルゴリズム情報理論、最適化、検索、計算理論など、いくつかの数学および計算科学の概念に基づいています。彼の著書『General Artificial Intelligence: Sequential Decision-Making Based on Algorithmic Probability』は 2005 年に出版された、非常に技術的かつ数学的な本です。
2002 年、Marcus Hutter は、Jürgen Schmidhuber および Shane Legg とともに、理想化されたエージェントと報酬強化学習に基づいた人工知能 AIXI の数学理論を提案しました。 2009 年に、Marcus Hutter は特徴強化学習理論を提案しました。
###以上がゼロから構築された DeepMind の新しい論文では、擬似コードを使用して Transformer を詳細に説明していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7533
7533
 15
1379
52
82
11
21
86
15
1379
52
82
11
21
86

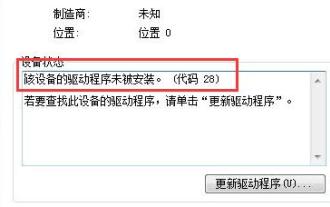 win7ドライバーコード28を解決する方法
Dec 30, 2023 pm 11:55 PM
win7ドライバーコード28を解決する方法
Dec 30, 2023 pm 11:55 PM
一部のユーザーは、デバイスのインストール時にエラー コード 28 を表示するエラーに遭遇しました。実際、これは主にドライバーが原因です。Win7 ドライバー コード 28 の問題を解決するだけで済みます。何をすべきかを見てみましょう。それ。 win7 ドライバー コード 28 で何をするか: まず、画面の左下隅にあるスタート メニューをクリックする必要があります。次に、ポップアップメニューで「コントロールパネル」オプションを見つけてクリックします。このオプションは通常、メニューの下部またはその近くにあります。クリックすると、システムは自動的にコントロール パネル インターフェイスを開きます。コントロールパネルでは、システムの各種設定や管理操作を行うことができます。これはノスタルジックな掃除レベルの最初のステップです。お役に立てば幸いです。次に、続行してシステムに入り、
 ブルースクリーンコード0x0000001が発生した場合の対処方法
Feb 23, 2024 am 08:09 AM
ブルースクリーンコード0x0000001が発生した場合の対処方法
Feb 23, 2024 am 08:09 AM
ブルー スクリーン コード 0x0000001 の対処法。ブルー スクリーン エラーは、コンピューター システムまたはハードウェアに問題がある場合の警告メカニズムです。コード 0x0000001 は、通常、ハードウェアまたはドライバーの障害を示します。ユーザーは、コンピュータの使用中に突然ブルー スクリーン エラーに遭遇すると、パニックになり途方に暮れるかもしれません。幸いなことに、ほとんどのブルー スクリーン エラーは、いくつかの簡単な手順でトラブルシューティングして対処できます。この記事では、ブルー スクリーン エラー コード 0x0000001 を解決するいくつかの方法を読者に紹介します。まず、ブルー スクリーン エラーが発生した場合は、再起動を試みることができます。
 DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
でももしかしたら公園の老人には勝てないかもしれない?パリオリンピックの真っ最中で、卓球が注目を集めています。同時に、ロボットは卓球のプレーにも新たな進歩をもたらしました。先ほど、DeepMind は、卓球競技において人間のアマチュア選手のレベルに到達できる初の学習ロボット エージェントを提案しました。論文のアドレス: https://arxiv.org/pdf/2408.03906 DeepMind ロボットは卓球でどれくらい優れていますか?おそらく人間のアマチュアプレーヤーと同等です: フォアハンドとバックハンドの両方: 相手はさまざまなプレースタイルを使用しますが、ロボットもそれに耐えることができます: さまざまなスピンでサーブを受ける: ただし、ゲームの激しさはそれほど激しくないようです公園の老人。ロボット、卓球用
 C++ コードの「エラー: 'datatype' の前に初期化子が必要です」問題を解決する
Aug 25, 2023 pm 01:24 PM
C++ コードの「エラー: 'datatype' の前に初期化子が必要です」問題を解決する
Aug 25, 2023 pm 01:24 PM
C++ コードの「error:expectedinitializerbefore'datatype'」問題を解決します。C++ プログラミングでは、コードを作成するときにコンパイル エラーが発生することがあります。一般的なエラーの 1 つは、「error:expectedinitializerbefore'datatype'」です。このエラーは通常、変数宣言または関数定義で発生し、プログラムが正しくコンパイルされなかったり、
 コンピューターが頻繁にブルー スクリーンになり、コードが毎回異なります
Jan 06, 2024 pm 10:53 PM
コンピューターが頻繁にブルー スクリーンになり、コードが毎回異なります
Jan 06, 2024 pm 10:53 PM
win10 システムは非常に優れた高インテリジェンス システムであり、その強力なインテリジェンスはユーザーに最高のユーザー エクスペリエンスをもたらすことができ、通常の状況では、ユーザーの win10 システム コンピューターに問題はありません。しかし、優れたコンピューターにはさまざまな障害が発生するのは避けられず、最近、友人が win10 システムで頻繁にブルー スクリーンが発生したと報告しています。今日、エディターは、Windows 10 コンピューターで頻繁にブルー スクリーンを引き起こすさまざまなコードに対する解決策を提供します。毎回異なるコードが表示される頻繁なコンピューターのブルー スクリーンの解決策: さまざまな障害コードの原因と解決策の提案 1. 0×000000116 障害の原因: グラフィック カード ドライバーに互換性がないことが考えられます。解決策: 元の製造元のドライバーを置き換えることをお勧めします。 2、
 コード0xc000007bエラーを解決する
Feb 18, 2024 pm 07:34 PM
コード0xc000007bエラーを解決する
Feb 18, 2024 pm 07:34 PM
終了コード 0xc000007b コンピューターを使用しているときに、さまざまな問題やエラー コードが発生することがあります。その中でも最も厄介なのが終了コード、特に終了コード0xc000007bです。このコードは、アプリケーションが正常に起動できず、ユーザーに迷惑がかかっていることを示しています。まずは終了コード0xc000007bの意味を理解しましょう。このコードは、32 ビット アプリケーションを 64 ビット オペレーティング システムで実行しようとしたときに通常発生する Windows オペレーティング システムのエラー コードです。それはそうすべきだという意味です
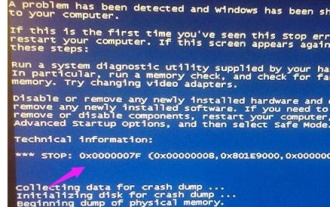 0x0000007fブルースクリーンコードの原因と解決策を詳しく解説
Dec 25, 2023 pm 02:19 PM
0x0000007fブルースクリーンコードの原因と解決策を詳しく解説
Dec 25, 2023 pm 02:19 PM
システムを使用しているときによく遭遇するブルースクリーンの問題ですが、エラーコードに応じて、さまざまな原因と解決策が異なります。たとえば、stop: 0x0000007f の問題が発生した場合、ハードウェアまたはソフトウェアのエラーである可能性があるため、エディタに従って解決策を見つけてみましょう。 0x000000c5 ブルー スクリーン コードの理由: 回答: メモリ、CPU、グラフィック カードが突然オーバークロックされているか、ソフトウェアが正しく実行されていません。解決策 1: 1. 起動時に F8 キーを押し続け、セーフ モードを選択し、Enter キーを押してに入ります。 2. セーフ モードに入ったら、win+r を押して実行ウィンドウを開き、「cmd」と入力して Enter を押します。 3. コマンド プロンプト ウィンドウで「chkdsk /f /r」と入力し、Enter キーを押して、y キーを押します。 4.
 あらゆるデバイス上の GE ユニバーサル リモート コード プログラム
Mar 02, 2024 pm 01:58 PM
あらゆるデバイス上の GE ユニバーサル リモート コード プログラム
Mar 02, 2024 pm 01:58 PM
デバイスをリモートでプログラムする必要がある場合は、この記事が役に立ちます。あらゆるデバイスをプログラミングするためのトップ GE ユニバーサル リモート コードを共有します。 GE リモコンとは何ですか? GEUniversalRemote は、スマート TV、LG、Vizio、Sony、Blu-ray、DVD、DVR、Roku、AppleTV、ストリーミング メディア プレーヤーなどの複数のデバイスを制御するために使用できるリモコンです。 GEUniversal リモコンには、さまざまな機能を備えたさまざまなモデルがあります。 GEUniversalRemote は最大 4 台のデバイスを制御できます。あらゆるデバイスでプログラムできるトップのユニバーサル リモート コード GE リモコンには、さまざまなデバイスで動作できるようにするコードのセットが付属しています。してもいいです
