

各開発言語の DNS キャッシュ構成の推奨事項

著者: Zhai Helong
1. 背景
コンピュータ分野では、パフォーマンスに関して考慮すべき最初の原則の 1 つです。最適化アクションは、キャッシュを使用すると、合理的なデータ キャッシュ メカニズムによって次の利点がもたらされます:
1. データ取得パスを短縮し、その後の迅速な読み取りのためにホットスポット データを近くにキャッシュすることで、処理が大幅に向上します。効率;
2. リモート データ取得の頻度を減らし、バックエンド データ サービスへの負担を軽減し、フロントエンドとバックエンド間のネットワーク帯域幅のコストを削減します。 ;
CPU ハードウェアのマルチレベル キャッシュ設計から、ブラウザによるページの高速表示、CDN やクラウド ストレージ ゲートウェイなどの一般的な商用製品に至るまで、キャッシュの概念は次のとおりです。どこにでも適用されます。
パブリック ネットワークの分野では、オペレーティング システム、ブラウザ、モバイル APP などの成熟した製品のキャッシュ メカニズムにより、チャイナ テレコム、チャイナ モバイルなどのネットワーク プロバイダーが直面する問題が大幅に解消されました。 、チャイナユニコム、およびコンテンツプロバイダー。大手ポータルプラットフォームやCDNベンダーなどのプロバイダーはサービスのプレッシャーに直面しています。オペレーターのDNSだけが毎秒数億のDNS解決に平然と直面でき、ネットワーク機器クラスターはTビットレベルのインターネットに簡単に耐えることができます1 秒あたりの帯域幅が大きく、CDN プラットフォームは 1 秒あたり数十億のリクエストを迅速に処理できます。
同社の現在の巨大かつ成長を続けるドメイン名アクセス規模に直面して、著者のチームは継続的にクラスター アーキテクチャを最適化し、DNS ソフトウェアのパフォーマンスを向上させています。また、さまざまな最適化を緊急に推進する必要もあります。クライアントのような環境でのドメイン名解決要求メカニズムを強化するため、当社は、企業のフロントエンド開発および運用担当者、顧客、パートナーに合理的な提案を提供するために、このガイド記事を調査および執筆するために特別にチームメンバーを組織しました。 DNS リクエストのプロセス全体を最適化し、ビジネス効率を向上させます。
この記事では、主に、さまざまなビジネス言語および開発言語の背景の下でクライアント上でローカルに DNS 解決レコード キャッシュを実装する方法について説明します。同時に、著者のチームの DNS 自体とその理解に基づいています。企業のネットワーク環境にいくつかの追加措置を講じ、最終的にはクライアント側での DNS 解決要求の正規化に向けて取り組んでいます。
2. 用語の説明
1. クライアント
この記事で言及されているクライアントとは、一般に、ネットワーク リクエストをアクティブに開始するすべてのオブジェクトを指します。ただし、サーバー、PC、モバイル端末、オペレーティングシステム、コマンドラインツール、スクリプト、サービスソフトウェア、ユーザーAPPなどに限定されません。
2. DNS
ドメイン ネーム システム (サーバー/サービス)、ドメイン ネーム システム (サーバー/サービス) は、データベース サービスの一種として理解できます。
クライアントは、サーバーと通信するときに互いを識別するために IP アドレスに依存します。クライアントのユーザーとして、人間が多数の IP アドレスを記憶することは困難です。 www.jd.com などの覚えやすいドメイン名は、クライアントのクエリのためにドメイン名と IP アドレスの間のマッピング関係を DNS に保存します。
クライアントは IP のみを取得できます。 DNS へのドメイン名解決要求を開始することにより、サーバーのアドレスを取得します。アドレスを取得した後、IP アドレスへのネットワーク通信要求を開始して、ドメイン名によって提供されるサービスまたはコンテンツを実際に取得できます。
参考: ドメイン ネーム システム ドメイン名解決プロセス
3. LDNS
ローカル DNS、ローカル ドメイン名サーバー; パブリック ネットワーク アクセス環境は通常、ネットワーク プロバイダーによって自動的に割り当てられます (プロバイダーは制御権を持っており、DNS ハイジャック、つまりドメイン名解決から取得した IP の改ざんを実行することさえできます)、イントラネット環境はネットワーク プロバイダーによって自動的に割り当てられます。 IT 部門;
通常、Unix、Unix 系、および MacOS システムは、/etc/resolv.conf を通じて独自の LDNS を確認できます。ネームサーバーの後に、このファイルもサポートしていると記載されています。パブリック ネットワークで一般的な LDNS を指定するためのユーザー自身の編集と変更 Google DNS、114DNS などのパブリック DNS、純粋なイントラネット環境では、IT 部門に相談せずに変更することは通常推奨されませんサービスが利用できなくなる可能性があります。man resolv.conf コマンドの結果を参照してください。
ドメイン名解決が異常な場合は、LDNS サービス異常や解決ハイジャックの可能性も考慮する必要があります。
参考: Windows システムでの TCP/IP 設定 (DNS を含む) の変更;
4. ホスト
DNS システムドメイン名と IP 間のマッピング関係を動的に提供できます。さまざまなオペレーティング システムで一般的な hosts ファイルは、ドメイン名と IP 間のマッピング関係の静的なレコード ファイルです。通常、ホスト レコードは DNS 解決よりも優先されます。 、ローカル キャッシュがない場合、またはキャッシュ ミスがある場合、対応するドメイン名レコードが最初にホストを通じて照会されます。ホストに関連するマッピングがない場合、DNS リクエストは引き続き開始されます。 Linux 環境でのこのロジックの制御については、以下の C/C 言語 DNS キャッシュの概要のセクションを参照してください。
実際の作業では、上記のデフォルト機能は、特定のドメイン名と特定の IP の間のマッピング関係をホスト ファイル (一般に「固定ホスト」として知られています) に書き込むためによく使用されます。 DNS 解決プロセスをバイパスし、ターゲット IP をマッピングします (ターゲット アクセスの場合) (効果は、curl の -x オプション、または wget の -e 指定プロキシ オプションと同じです);
5. TTL
Time-To-Live、生存時間の値、この概念は多くの分野に適用でき、異なる意味を持つ場合があります。
この記事に含まれる TTL の説明はすべてデータ キャッシュに関するものです。キャッシュされたデータの「有効期間」として直接理解できます。データがキャッシュされた時点から始まります。 TTL で指定された期間を超えてキャッシュ内に存在するデータは期限切れデータとみなされ、データが再度呼び出された場合は、直ちに正当性が確認されるか、信頼できるデータ ソースから再取得されます。
キャッシュ メカニズムは通常、受動的にトリガーされ、更新されるため、クライアントのキャッシュ有効期間中にバックエンドの元の信頼できるデータが変更されても、クライアントはそれを認識せず、パフォーマンスが低下します。キャッシュされたデータと信頼できるデータの間には、ある程度のデータ更新の遅延や一時的な不一致が発生します。
クライアント側の DNS レコードのキャッシュ TTL については、テストやビジネスなどの機密性の低いビジネスの場合は、60 秒の値を推奨します。ドメイン名解決の調整を頻繁に行わない場合は、時間や日のレベルにまで拡張することができます。
3. DNS 解決の最適化に関する提案
1. DNS 解決のサポートに関する調査各言語ネットワーク ライブラリによる DNS キャッシュ
開発者が自社開発のクライアント DNS キャッシュを実装するために、次の調査結果を参照することをお勧めします。開発言語ごとに DNS キャッシュのサポートが異なる場合があるので、ここで 1 つずつ分析してみましょう。
C/C 言語
(1) glibc の getaddrinfo 関数
Linux 環境の glibc ライブラリは 2 つのドメイン名を提供します解決関数: gethostbyname 関数と getaddrinfo 関数 gethostbyname は以前は一般的に使用されていた関数でしたが、IPv6 およびスレッド プログラミング モデルへの移行に伴い、getaddrinfo は IPv6 アドレスを解析するだけでなくスレッドセーフであるため、さらに便利になりました。 getaddrinfo 関数を使用することをお勧めします。
関数プロトタイプ:
int getaddrinfo( const char *node, const char *service, const struct addrinfo *hints, struct addrinfo **res);
getaddrinfo 関数は、比較的低レベルの基本ライブラリ関数であり、開発言語の多くのドメイン名解決関数です。そのため、ここではこの関数の処理ロジックを紹介します。 strace コマンドを使用して、この関数システム コールをトレースします。
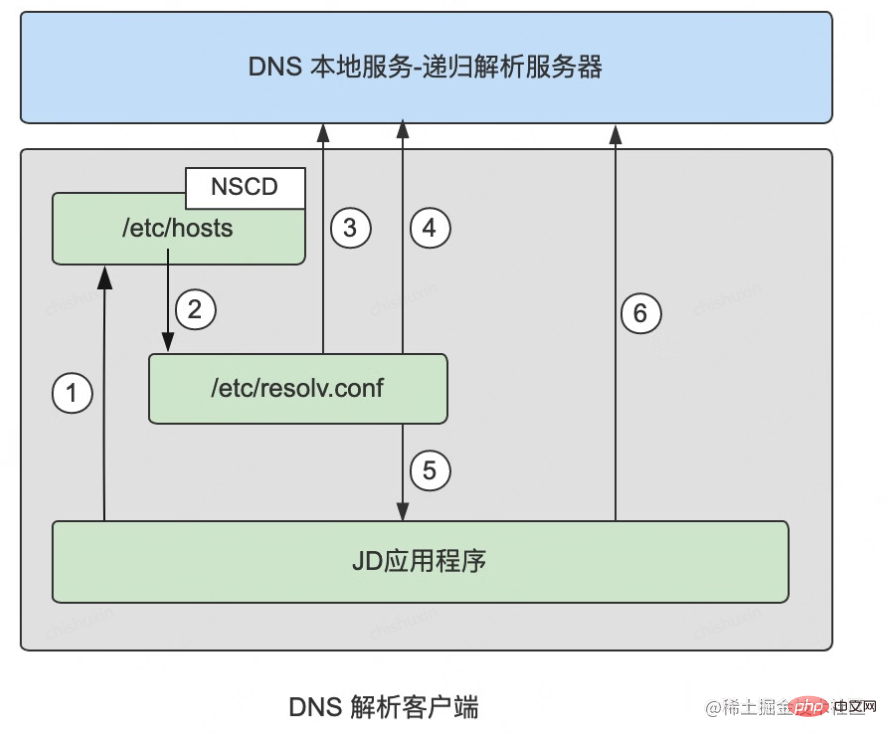
1) nscd キャッシュを見つけます (nscd の概要については以下を参照してください)
私たちはLinux 環境の場合 strace コマンドを使用すると、次のシステム コールが表示されます。
//连接nscd
socket(PF_LOCAL, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3
connect(3, {sa_family=AF_LOCAL, sun_path="/var/run/nscd/socket"}, 110) = -1 ENOENT (No such file or directory)
close(3)nscd サービスに接続し、UNIX ソケット インターフェイス「/var/run/」を通じて DNS キャッシュをクエリします。 nscd/ソケット」。
2) /etc/hosts ファイルをクエリします。
nscd サービスが開始されていないか、キャッシュが見つからない場合は、ホストのクエリを続けます。ファイルを作成すると、次のシステム コールが表示されるはずです。
//读取 hosts 文件
open("/etc/host.conf", O_RDONLY)= 3
fstat(3, {st_mode=S_IFREG|0644, st_size=9, ...}) = 0
...
open("/etc/hosts", O_RDONLY|O_CLOEXEC)= 3
fcntl(3, F_GETFD) = 0x1 (flags FD_CLOEXEC)
fstat(3, {st_mode=S_IFREG|0644, st_size=178, ...}) = 03) DNS サービスのクエリ
/ から DNS サーバーにクエリを実行します。 etc/resolv.conf 設定 (ネームサーバー) を参照し、DNS クエリを実行して解決結果を取得します。次のシステム コール
//获取 resolv.conf 中 DNS 服务 IP
open("/etc/resolv.conf", O_RDONLY)= 3
fstat(3, {st_mode=S_IFREG|0644, st_size=25, ...}) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fef2abee000
read(3, "nameserver 114.114.114.114nn", 4096) = 25
...
//连到 DNS 服务,开始 DNS 查询
connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("114.114.114.114")}, 16) = 0
poll([{fd=3, events=POLLOUT}], 1, 0)= 1 ([{fd=3, revents=POLLOUT}])がわかります。クライアントが最初に /etc/hosts ファイルを検索するか、クエリとクエリのために /etc/resolv.conf から DNS サーバーを最初に取得するかについてです。解決策は、/etc/nsswitch.conf によって制御されます:
#/etc/nsswitch.conf 部分配置 ... #hosts: db files nisplus nis dns hosts:files dns ...
システムが nscd ソケットを呼び出した後、/etc/resolv.conf を読み取る前に、strace コマンドを通じて実際に確認できます。このファイルが読み込まれます
newfstatat(AT_FDCWD, "/etc/nsswitch.conf", {st_mode=S_IFREG|0644, st_size=510, ...}, 0) = 0
...
openat(AT_FDCWD, "/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 34) 検証
#include <sys/socket.h>
#include <netdb.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <arpa/inet.h>
#include <unistd.h>
int gethostaddr(char * name);
int main(int argc, char *argv[]){
if (argc != 2)
{
fprintf(stderr, "%s $host", argv[0]);
return -1;
}
int i = 0;
for(i = 0; i < 5; i++)
{
int ret = -1;
ret = gethostaddr(argv[1]);
if (ret < 0)
{
fprintf(stderr, "%s $host", argv[0]);
return -1;
}
//sleep(5);
}
return 0;
}
int gethostaddr(char* name){
struct addrinfo hints;
struct addrinfo *result;
struct addrinfo *curr;
int ret = -1;
char ipstr[INET_ADDRSTRLEN];
struct sockaddr_in*ipv4;
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_family = AF_INET;
hints.ai_socktype = SOCK_STREAM;
ret = getaddrinfo(name, NULL, &hints, &result);
if (ret != 0)
{
fprintf(stderr, "getaddrinfo: %sn", gai_strerror(ret));
return ret;
}
for (curr = result; curr != NULL; curr = curr->ai_next)
{
ipv4 = (struct sockaddr_in *)curr->ai_addr;
inet_ntop(curr->ai_family, &ipv4->sin_addr, ipstr, INET_ADDRSTRLEN);
printf("ipaddr:%sn", ipstr);
}
freeaddrinfo(result);
return 0;
}要約すると、getaddrinfo 関数と nscd を組み合わせることで DNS キャッシュを実現できます。
(2) libcurlライブラリのドメイン名解決機能
libcurlライブラリは、C/C言語でクライアントが共通に利用するネットワーク送信ライブラリです。 、curl コマンドはこのライブラリに基づいて実装されます。このライブラリは、getaddrinfo ライブラリ関数を呼び出して DNS ドメイン名解決を実装し、nscd DNS キャッシュもサポートします。
int
Curl_getaddrinfo_ex(const char *nodename,
const char *servname,
const struct addrinfo *hints,
Curl_addrinfo **result)
{
...
error = getaddrinfo(nodename, servname, hints, &aihead);
if(error)
return error;
...
}Java
Java 言語は、多くの企業でビジネス システムの開発に使用される主な言語です。簡単な HTTP クライアント プログラムを作成することで、次のことをテストして検証できます。 Java ネットワーク ライブラリは DNS キャッシュをサポートします。このテストでは、Java 標準ライブラリの 2 つのコンポーネント HttpURLConnection と Apache httpcomponents-client を検証します。
(1) Java標準ライブラリ HttpURLConnection
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpUrlConnectionDemo {
public static void main(String[] args) throws Exception {
String urlString = "http://example.my.com/";
int num = 0;
while (num < 5) {
URL url = new URL(urlString);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setDoOutput(true);
OutputStream os = conn.getOutputStream();
os.flush();
os.close();
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream is = conn.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
StringBuilder sb = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
sb.append(line);
}
System.out.println("rsp:" + sb.toString());
} else {
System.out.println("rsp code:" + conn.getResponseCode());
}
num++;
}
}
}测试结果显示 Java 标准库 HttpURLConnection 是支持 DNS 缓存,5 次请求中只有一次 DNS 请求。
(2)Apache httpcomponents-client
import java.util.ArrayList;
import java.util.List;
import org.apache.hc.client5.http.classic.methods.HttpGet;
import org.apache.hc.client5.http.entity.UrlEncodedFormEntity;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.CloseableHttpResponse;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.NameValuePair;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.message.BasicNameValuePair;
public class QuickStart {
public static void main(final String[] args) throws Exception {
int num = 0;
while (num < 5) {
try (final CloseableHttpClient httpclient = HttpClients.createDefault()) {
final HttpGet httpGet = new HttpGet("http://example.my.com/");
try (final CloseableHttpResponse response1 = httpclient.execute(httpGet)) {
System.out.println(response1.getCode() + " " + response1.getReasonPhrase());
final HttpEntity entity1 = response1.getEntity();
EntityUtils.consume(entity1);
}
}
num++;
}
}
}测试结果显示 Apache httpcomponents-client 支持 DNS 缓存,5 次请求中只有一次 DNS 请求。
从测试中发现 Java 的虚拟机实现一套 DNS 缓存,即实现在 java.net.InetAddress 的一个简单的 DNS 缓存机制,默认为缓存 30 秒,可以通过 networkaddress.cache.ttl 修改默认值,缓存范围为 JVM 虚拟机进程,也就是说同一个 JVM 进程中,30秒内一个域名只会请求DNS服务器一次。同时 Java 也是支持 nscd 的 DNS 缓存,估计底层调用 getaddrinfo 函数,并且 nscd 的缓存级别比 Java 虚拟机的 DNS 缓存高。
# 默认缓存 ttl 在 jre/lib/security/java.security 修改,其中 0 是不缓存,-1 是永久缓存 networkaddress.cache.ttl=10 # 这个参数 sun.net.inetaddr.ttl 是以前默认值,目前已经被 networkaddress.cache.ttl 取代
Go
随着云原生技术的发展,Go 语言逐渐成为云原生的第一语言,很有必要验证一下 Go 的标准库是否支持 DNS 缓存。通过我们测试验证发现 Go 的标准库 net.http 是不支持 DNS 缓存,也是不支持 nscd 缓存,应该是没有调用 glibc 的库函数,也没有实现类似 getaddrinfo 函数的功能。这个跟 Go语言的自举有关系,Go 从 1.5 开始就基本全部由 Go(.go) 和汇编 (.s) 文件写成的,以前版本的 C(.c) 文件被全部重写。不过有一些第三方 Go 版本 DNS 缓存库,可以自己在应用层实现,还可以使用 fasthttp 库的 httpclient。
(1)标准库net.http
package main
import (
"flag"
"fmt"
"io/ioutil"
"net/http"
"time"
)
var httpUrl string
func main() {
flag.StringVar(&httpUrl, "url", "", "url")
flag.Parse()
getUrl := fmt.Sprintf("http://%s/", httpUrl)
fmt.Printf("url: %sn", getUrl)
for i := 0; i < 5; i++ {
_, buf, err := httpGet(getUrl)
if err != nil {
fmt.Printf("err: %vn", err)
return
}
fmt.Printf("resp: %sn", string(buf))
time.Sleep(10 * time.Second)# 等待10s发起另一个请求
}
}
func httpGet(url string) (int, []byte, error) {
client := createHTTPCli()
resp, err := client.Get(url)
if err != nil {
return -1, nil, fmt.Errorf("%s err [%v]", url, err)
}
defer resp.Body.Close()
buf, err := ioutil.ReadAll(resp.Body)
if err != nil {
return resp.StatusCode, buf, err
}
return resp.StatusCode, buf, nil
}
func createHTTPCli() *http.Client {
readWriteTimeout := time.Duration(30) * time.Second
tr := &http.Transport{
DisableKeepAlives: true,//设置短连接
IdleConnTimeout: readWriteTimeout,
}
client := &http.Client{
Timeout: readWriteTimeout,
Transport: tr,
}
return client
}从测试结果来看,net.http 每次都去 DNS 查询,不支持 DNS 缓存。
(2)fasthttp 库
fasthttp 库是 Go 版本高性能 HTTP 库,通过极致的性能优化,性能是标准库 net.http 的 10 倍,其中一项优化就是支持 DNS 缓存,我们可以从其源码看到
//主要在fasthttp/tcpdialer.go中
type TCPDialer struct {
...
// This may be used to override DNS resolving policy, like this:
// var dialer = &fasthttp.TCPDialer{
//Resolver: &net.Resolver{
//PreferGo: true,
//StrictErrors: false,
//Dial: func (ctx context.Context, network, address string) (net.Conn, error) {
//d := net.Dialer{}
//return d.DialContext(ctx, "udp", "8.8.8.8:53")
//},
//},
// }
Resolver Resolver
// DNSCacheDuration may be used to override the default DNS cache duration (DefaultDNSCacheDuration)
DNSCacheDuration time.Duration
...
}可以参考如下方法使用 fasthttp client 端
func main() {
// You may read the timeouts from some config
readTimeout, _ := time.ParseDuration("500ms")
writeTimeout, _ := time.ParseDuration("500ms")
maxIdleConnDuration, _ := time.ParseDuration("1h")
client = &fasthttp.Client{
ReadTimeout: readTimeout,
WriteTimeout:writeTimeout,
MaxIdleConnDuration: maxIdleConnDuration,
NoDefaultUserAgentHeader:true, // Don't send: User-Agent: fasthttp
DisableHeaderNamesNormalizing: true, // If you set the case on your headers correctly you can enable this
DisablePathNormalizing:true,
// increase DNS cache time to an hour instead of default minute
Dial: (&fasthttp.TCPDialer{
Concurrency:4096,
DNSCacheDuration: time.Hour,
}).Dial,
}
sendGetRequest()
sendPostRequest()
}(3)第三方DNS缓存库
这个是 github 中的一个 Go 版本 DNS 缓存库
可以参考如下代码,在HTTP库中支持DNS缓存
r := &dnscache.Resolver{}
t := &http.Transport{
DialContext: func(ctx context.Context, network string, addr string) (conn net.Conn, err error) {
host, port, err := net.SplitHostPort(addr)
if err != nil {
return nil, err
}
ips, err := r.LookupHost(ctx, host)
if err != nil {
return nil, err
}
for _, ip := range ips {
var dialer net.Dialer
conn, err = dialer.DialContext(ctx, network, net.JoinHostPort(ip, port))
if err == nil {
break
}
}
return
},
}Python
(1)requests 库
#!/bin/python
import requests
url = 'http://example.my.com/'
num = 0
while num < 5:
headers={"Connection":"close"} # 开启短连接
r = requests.get(url,headers = headers)
print(r.text)
num +=1(2)httplib2 库
#!/usr/bin/env python
import httplib2
http = httplib2.Http()
url = 'http://example.my.com/'
num = 0
while num < 5:
loginHeaders={
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.0 Chrome/30.0.1599.101 Safari/537.36',
'Connection': 'close'# 开启短连接
}
response, content = http.request(url, 'GET', headers=loginHeaders)
print(response)
print(content)
num +=1(3)urllib2 库
#!/bin/python
import urllib2
import cookielib
httpHandler = urllib2.HTTPHandler(debuglevel=1)
httpsHandler = urllib2.HTTPSHandler(debuglevel=1)
opener = urllib2.build_opener(httpHandler, httpsHandler)
urllib2.install_opener(opener)
loginHeaders={
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.0 Chrome/30.0.1599.101 Safari/537.36',
'Connection': 'close' # 开启短连接
}
num = 0
while num < 5:
request=urllib2.Request('http://example.my.com/',headers=loginHeaders)
response = urllib2.urlopen(request)
page=''
page= response.read()
print response.info()
print page
num +=1Python 测试三种库都是支持 nscd 的 DNS 缓存的(推测底层也是调用 getaddrinfo 函数),以上测试时使用 HTTP 短连接,都在 python2 环境测试。
总结
针对 HTTP 客户端来说,可以优先开启 HTTP 的 keep-alive 模式,可以复用 TCP 连接,这样可以减少 TCP 握手耗时和重复请求域名解析,然后再开启 nscd 缓存,除了 Go 外,C/C++、Java、Python 都可支持 DNS 缓存,减少 DNS查询耗时。
这里只分析了常用 C/C++、Java、Go、Python 语言,欢迎熟悉其他语言的小伙伴补充。
2. Unix/类 Unix 系统常用 dns 缓存服务:
在由于某些特殊原因,自研或非自研客户端本身无法提供 DNS 缓存支持的情况下,建议管理人员在其所在系统环境中部署DNS缓存程序;
现介绍 Unix/类 Unix 系统适用的几款常见轻量级 DNS 缓存程序。而多数桌面操作系统如 Windows、MacOS 和几乎所有 Web 浏览器均自带 DNS 缓存功能,本文不再赘述。
P.S. DNS 缓存服务请务必确保随系统开机启动;
nscd
name service cache daemon 即装即用,通常为 linux 系统默认安装,相关介绍可参考其 manpage:man nscd;man nscd.conf
(1)安装方法:通过系统自带软件包管理程序安装,如 yum install nscd
(2)缓存管理(清除):
1.service nscd restart 重启服务清除所有缓存;
2.nscd -i hosts 清除 hosts 表中的域名缓存(hosts 为域名缓存使用的 table 名称,nscd 有多个缓存 table,可参考程序相关 manpage)
dnsmasq
较为轻量,可选择其作为 nscd 替代,通常需单独安装
(1)安装方法:通过系统自带软件包管理程序安装,如 yum install dnsmasq
(2)核心文件介绍(基于 Dnsmasq version 2.86,较低版本略有差异,请参考对应版本文档如 manpage 等)
(3)/etc/default/dnsmasq 提供六个变量定义以支持六种控制类功能
(4)/etc/dnsmasq.d/ 此目录含 README 文件,可参考;目录内可以存放自定义配置文件
(5)/etc/dnsmasq.conf 主配置文件,如仅配置 dnsmasq 作为缓存程序,可参考以下配置
listen-address=127.0.0.1#程序监听地址,务必指定本机内网或回环地址,避免暴露到公网环境 port=53 #监听端口 resolv-file=/etc/dnsmasq.d/resolv.conf#配置dnsmasq向自定义文件内的 nameserver 转发 dns 解析请求 cache-size=150#缓存记录条数,默认 150 条,可按需调整、适当增大 no-negcache #不缓存解析失败的记录,主要是 NXDOMAIN,即域名不存在 log-queries=extra #开启日志记录,指定“=extra”则记录更详细信息,可仅在问题排查时开启,平时关闭 log-facility=/var/log/dnsmasq.log #指定日志文件 #同时需要将本机 /etc/resolv.conf 第一个 nameserver 指定为上述监听地址,这样本机系统的 dns 查询请求才会通过 dnsmasq 代为转发并缓存响应结果。 #另 /etc/resolv.conf 务必额外配置 2 个 nameserver,以便 dnsmasq 服务异常时支持系统自动重试,注意 resolv.conf 仅读取前 3 个 nameserver
(6)缓存管理(清除):
1.kill -s HUP `pidof dnsmasq` 推荐方式,无需重启服务
2.kill -s TERM `pidof dnsmasq` 或 service dnsmasq stop
3.service dnsmasq force-reload 或 service dnsmasq restart
(7)官方文档:https://thekelleys.org.uk/dnsmasq/doc.html
3. 纯内网业务取消查询域名的AAAA记录的请求
以 linux 操作系统为例,常用的网络请求命令行工具常常通过调用 getaddrinfo() 完成域名解析过程,如 ping、telnet、curl、wget 等,但其可能出于通用性的考虑,均被设计为对同一个域名每次解析会发起两个请求,分别查询域名 A 记录(即 IPV4 地址)和 AAAA 记录(即 IPV6 地址)。
因目前大部分公司的内网环境及云上内网环境还未使用 ipv6 网络,故通常 DNS 系统不为内网域名添加 AAAA 记录,徒劳请求域名的 AAAA 记录会造成前端应用和后端 DNS 服务不必要的资源开销。因此,仅需请求内网域名的业务,如决定自研客户端,建议开发人员视实际情况,可将其设计为仅请求内网域名 A 记录,尤其当因故无法实施本地缓存机制时。
4. 规范域名处理逻辑
客户端需严格规范域名/主机名的处理逻辑,避免产生大量对不存在域名的解析请求(确保域名从权威渠道获取,避免故意或意外使用随机构造的域名、主机名),因此类请求的返回结果(NXDOMAIN)通常不被缓存或缓存时长较短,且会触发客户端重试,对后端 DNS 系统造成一定影响。
以上が各開発言語の DNS キャッシュ構成の推奨事項の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7514
7514
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64

 e からの NameResolutionError(self.host, self, e) の理由とその解決方法
Mar 01, 2024 pm 01:20 PM
e からの NameResolutionError(self.host, self, e) の理由とその解決方法
Mar 01, 2024 pm 01:20 PM
エラーの理由は、urllib3 ライブラリの例外タイプである NameResolutionError(self.host,self,e)frome です。このエラーの理由は、DNS 解決が失敗したこと、つまり、ホスト名または IP アドレスが試みられたことです。解決できるものが見つかりません。これは、入力された URL アドレスが間違っているか、DNS サーバーが一時的に利用できないことが原因である可能性があります。このエラーを解決する方法 このエラーを解決するにはいくつかの方法があります。 入力された URL アドレスが正しいかどうかを確認し、アクセス可能であることを確認します。 DNS サーバーが利用可能であることを確認します。コマンド ラインで「ping」コマンドを使用してみてください。 DNS サーバーが利用可能かどうかをテストします。プロキシの背後にある場合は、ホスト名の代わりに IP アドレスを使用して Web サイトにアクセスしてみてください。
 Linux で DNS キャッシュを表示および更新する方法
Mar 07, 2024 am 08:43 AM
Linux で DNS キャッシュを表示および更新する方法
Mar 07, 2024 am 08:43 AM
DNS (DomainNameSystem) は、ドメイン名を対応する IP アドレスに変換するためにインターネットで使用されるシステムです。 Linux システムでは、DNS キャッシュはドメイン名と IP アドレス間のマッピング関係をローカルに保存するメカニズムです。これにより、ドメイン名解決の速度が向上し、DNS サーバーの負担が軽減されます。 DNS キャッシュを使用すると、システムはその後同じドメイン名にアクセスするときに、毎回 DNS サーバーにクエリ要求を発行する必要がなく、IP アドレスを迅速に取得できるため、ネットワークのパフォーマンスと効率が向上します。この記事では、Linux で DNS キャッシュを表示および更新する方法、関連する詳細およびサンプル コードについて説明します。 DNS キャッシュの重要性 Linux システムでは、DNS キャッシュが重要な役割を果たします。その存在
 win11でDNSアドレスを変更すると何の役に立つのですか?
Feb 29, 2024 pm 05:22 PM
win11でDNSアドレスを変更すると何の役に立つのですか?
Feb 29, 2024 pm 05:22 PM
ネットワークが何らかの理由で遅れていると感じているユーザーはたくさんいると思いますが、検索したところ、DNS を変更した多くのユーザーが遅れが解消されたと述べていることがわかりました。それでは記事をご覧ください。 win11 で DNS アドレスを変更すると何の用途がありますか? 回答: 合計 4 つの利点があります。 1. ネットワークアクセス速度が速くなります。 2. ユーザーがアクセスする Web サイトが安全であることを確認するのに役立ちます。 3. ユーザーが DNS のハイジャックを防ぐのにも役立ちます。 4. 一部のユーザーが特定の Web サイトにアクセスできない場合、DNS を変更することでその Web サイトに直接リンクできます。
 PHP APCu の高度な使用法: 隠された力を解き放つ
Mar 01, 2024 pm 09:10 PM
PHP APCu の高度な使用法: 隠された力を解き放つ
Mar 01, 2024 pm 09:10 PM
PHPAPCu (php キャッシュの代替) は、PHP アプリケーションを高速化するオペコード キャッシュおよびデータ キャッシュ モジュールです。その可能性を最大限に活用するには、その高度な機能を理解することが重要です。 1. バッチ操作: APCu は、多数のキーと値のペアを同時に処理できるバッチ操作メソッドを提供します。これは、大規模なキャッシュのクリアまたは更新に役立ちます。 //キャッシュキーをバッチで取得 $values=apcu_fetch(["key1","key2","key3"]); //キャッシュキーをバッチでクリア apcu_delete(["key1","key2","key3"]) ;2 .キャッシュの有効期限を設定する: APCu を使用すると、キャッシュ項目の有効期限を設定して、指定した時間が経過すると自動的に期限切れになるようにできます。
 動画ファイルをブラウザのキャッシュからローカルに保存する方法
Feb 23, 2024 pm 06:45 PM
動画ファイルをブラウザのキャッシュからローカルに保存する方法
Feb 23, 2024 pm 06:45 PM
ブラウザキャッシュビデオをエクスポートする方法 インターネットの急速な発展に伴い、ビデオは人々の日常生活に欠かせないものになりました。 Web を閲覧しているときに、保存または共有したいビデオ コンテンツに遭遇することがよくありますが、ビデオ ファイルがブラウザのキャッシュにのみ存在するため、ビデオ ファイルのソースが見つからないことがあります。では、ブラウザのキャッシュからビデオをエクスポートするにはどうすればよいでしょうか?この記事では、いくつかの一般的な方法を紹介します。まず、ブラウザキャッシュという概念を明確にする必要があります。ブラウザー キャッシュは、ユーザー エクスペリエンスを向上させるためにブラウザーによって使用されます。
 PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発では、キャッシュ メカニズムにより、頻繁にアクセスされるデータがメモリまたはディスクに一時的に保存され、データベース アクセスの数が削減され、パフォーマンスが向上します。キャッシュの種類には主にメモリ、ファイル、データベース キャッシュが含まれます。キャッシュは、組み込み関数またはサードパーティのライブラリ (cache_get() や Memcache など) を使用して PHP に実装できます。一般的な実用的なアプリケーションには、データベース クエリ結果をキャッシュしてクエリ パフォーマンスを最適化したり、ページ出力をキャッシュしてレンダリングを高速化したりすることが含まれます。キャッシュ メカニズムにより、Web サイトの応答速度が効果的に向上し、ユーザー エクスペリエンスが向上し、サーバーの負荷が軽減されます。
 エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest
Apr 11, 2024 pm 08:52 PM
エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest
Apr 11, 2024 pm 08:52 PM
大規模モデルの継続的な最適化に基づいて、LLM エージェント - これらの強力なアルゴリズム エンティティは、複雑な複数ステップの推論タスクを解決する可能性を示しています。自然言語処理から深層学習に至るまで、LLM エージェントは徐々に研究や業界の焦点になりつつあります。LLM エージェントは、人間の言語を理解して生成するだけでなく、戦略を策定し、多様な環境でタスクを実行し、API 呼び出しやコーディングを使用して構築することもできます。ソリューション。この文脈において、AgentQuest フレームワークの導入はマイルストーンであり、LLM エージェントの評価と進歩のためのモジュール式ベンチマーク プラットフォームを提供するだけでなく、研究者にこれらのエージェントのパフォーマンスを追跡および改善するための強力なツールも提供します。より細かいレベル
 APCu のベスト プラクティス: アプリケーションの効率の向上
Mar 01, 2024 pm 10:58 PM
APCu のベスト プラクティス: アプリケーションの効率の向上
Mar 01, 2024 pm 10:58 PM
キャッシュ サイズとクリーンアップ戦略の最適化 適切なキャッシュ サイズを APCu に割り当てることが重要です。キャッシュが小さすぎるとデータを効果的にキャッシュできず、キャッシュが大きすぎるとメモリが無駄に消費されます。一般に、キャッシュ サイズを使用可能なメモリの 1/4 ~ 1/2 に設定するのが妥当な範囲です。さらに、効果的なクリーンアップ戦略を採用することで、古いデータや無効なデータがキャッシュに保持されないようにすることができます。 APCu の自動クリーニング機能を使用することも、カスタム クリーニング メカニズムを実装することもできます。サンプルコード: //キャッシュサイズを256MBに設定 apcu_add("cache_size",268435456); //60分ごとにキャッシュをクリア apcu_add("cache_ttl",60*60); 圧縮を有効にする
