

Taifan Technology の Wang Lin: グラフ データベース - 認知知能への新しい方法

ゲスト | Wang Lin
編集者 | Zhang Feng
企画 | 徐潔成
人工知能には比較的大きな 2 つの派閥があります: 合理主義そして経験主義。しかし、実際の工業グレードの製品では、これら 2 つの派閥が互いに補完し合います。このモデルのブラック ボックスに、より多くの制御性とより多くの知識を導入するには、記号的な知識を運ぶナレッジ グラフを適用する必要があります。
最近、Taifan Technology CTO 51CTO が主催した WOT グローバル テクノロジー イノベーション カンファレンスでWang Lin 博士は、グラフ データベース モデルの歴史と進化に焦点を当て、「グラフ データベース: 認知知能への新たな道」というテーマの進化を出席者に紹介しました。また、グラフ データベースが認知知能を達成するための重要な方法にも焦点を当てました。グラフデータベースの設計とOpenGaussの実践経験として。
スピーチの内容は、皆さんにインスピレーションを与えることを願って、次のように構成されています。ある点 次元の観点から見ると、人工知能は 2 つのカテゴリに分類できます。1 つは 接続主義
で、これは私たちがよく知っている深層学習であり、人間の脳の構造をシミュレートして何らかの処理を実行します。知覚、認識、判断など。もう 1 つのタイプは 象徴主義 で、通常は人間の心をシミュレートします。認知プロセスは、記号表現に対する操作です。したがって、何らかの思考や推論に使用されることがよくあります。代表的な技術としてはナレッジグラフがある。
AI を強化する 4 つの方法
 1. 状況に応じた意思決定
1. 状況に応じた意思決定
ナレッジ グラフは本質的に、エンティティおよびエンティティ間の関係を表すグラフベースのセマンティック ネットワークです。高いレベルでは、ナレッジ グラフは相互に関連する知識の集合でもあり、人間が理解できる形式で現実世界とエンティティと物の間の関係を記述します。
ナレッジ グラフは、意思決定に役立つより多くのドメイン知識とコンテキスト情報をもたらします。アプリケーションの観点から見ると、ナレッジ グラフは 3 つのタイプに分類できます。
#1 つは  ドメイン関連するナレッジマップ。
ドメイン関連するナレッジマップ。
2 つ目は、外部知覚知識グラフです。外部データ ソースを集約し、対象の内部エンティティにマッピングします。典型的な用途はサプライチェーンのリスク分析で、サプライチェーンを通じてサプライヤー、その上流と下流、工場などの供給ラインに関する情報を確認し、どこに問題があるのか、中断のリスクがあるのかを分析できます。
3 つ目は、自然言語処理ナレッジ グラフです。自然言語処理には、自然言語クエリの作成に役立つ専門用語やその分野のキーワードが多数含まれています。
2. 操作効率の向上機械学習手法はテーブルに保存されたデータに依存することが多く、これらのデータのほとんどは実際にはリソースを大量に消費する操作です。関連するコンテンツを高効率の分野で提供し、データを接続し、関係における多段階の分離を実現することで、大規模な迅速な分析に役立ちます。この観点から見ると、グラフ自体が機械学習の効果を加速させます。
さらに、機械学習アルゴリズムは多くの場合、すべてのデータに対して計算する必要があります。単純なグラフ クエリを通じて、必要なデータのサブグラフを返すことができるため、操作効率が向上します。
3. 予測精度の向上
関係は多くの場合、行動の最も強力な予測因子であり、関係の特性はグラフから簡単に取得できます。
データと関係図を関連付けることで、関係の特徴をより直接的に抽出できます。しかし、従来の機械学習手法では、データを抽象化して単純化するときに多くの重要な情報が実際に失われることがあります。したがって、リレーショナル プロパティを使用すると、この情報を失うことなく分析できます。さらに、グラフ アルゴリズムにより、緊密なコミュニティなどの異常を発見するプロセスが簡素化されます。緊密なコミュニティ内のノードにスコアを付け、その情報を抽出して機械学習モデルのトレーニングに使用できます。最後に、グラフ アルゴリズムを使用して特徴の選択が実行され、モデルで使用される特徴の数が最も関連性の高いサブセットに減らされます。
4. 説明可能性
近年、「解釈可能性」についてよく耳にしますが、これも人工知能の応用において特に大きな課題です。人工知能がどのようにしてこの決定と結果に達するのかを理解すること、特に医療、金融、司法などの特定の応用分野では、説明可能性に対する多くの要求があります。
解釈可能性には 3 つの側面が含まれます:
(1) 解釈可能なデータ 。データが選択された理由、データのソースは何なのかを知る必要があります。データは解釈可能でなければなりません。
(2) 解釈可能な予測。解釈可能な予測とは、特定の予測にどの特徴が使用され、どの重みが使用されるかを知る必要があることを意味します。
(3) 解釈可能なアルゴリズム。解釈可能なアルゴリズムの現在の見通しは非常に魅力的ですが、まだ道のりは長く、現在研究分野では Tensor ネットワークが提案されており、この方法を使用してアルゴリズムに一定の解釈可能性を持たせることができます。
グラフは人工知能の応用と開発にとって非常に重要であるため、どのように作成すればよいでしょうか用途?毛織物?まず注意が必要なのは、グラフのストレージ管理、つまりグラフ データ モデルです。
現在、最も主流のグラフ データ モデルは、RDF グラフと属性グラフの 2 つです。
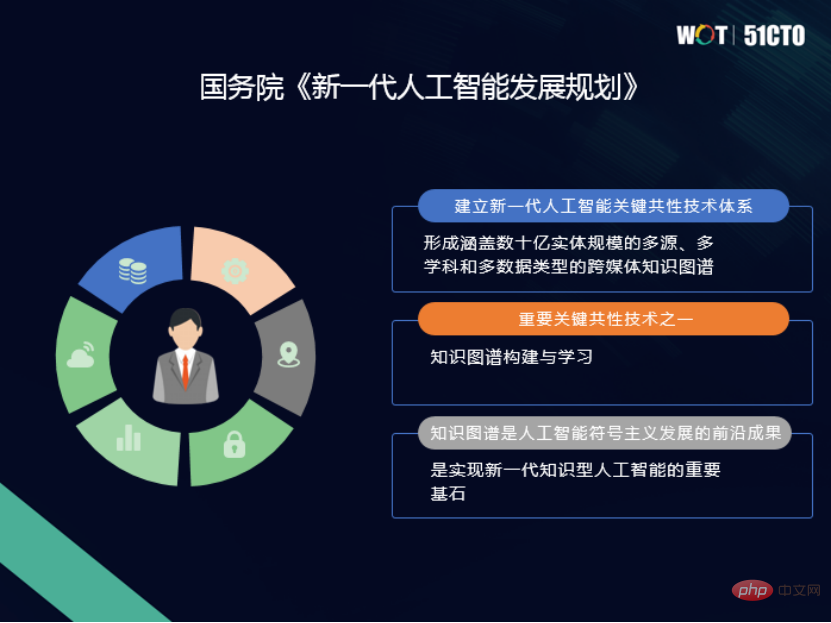
1. RDF 図RDF は Resource description Framework の略で、意味世界に関する機械が理解できる情報の交換を表すために W3C によって策定された標準データです。ワイドウェブモデル。 RDF グラフでは、各リソースが一意の ID の 1 つとして HTTP URL を持ちます。 RDF 定義は、事実の記述を表すトリプレットの形式であり、S は主語、P は述語、O は目的語を表します。この写真では、ボブは MonoLisa に興味を持っており、これが RDF 図であるという事実を述べています。

#RDF グラフに対応するデータ モデルには、独自のクエリ言語である SPARQL があります。 SPARQL は、W3C によって開発された RDF ナレッジ グラフの標準クエリ言語です。 SPARQL は構文に SQL の教訓を取り入れた宣言型クエリ言語であり、クエリの基本単位もトリプレット パターンです。
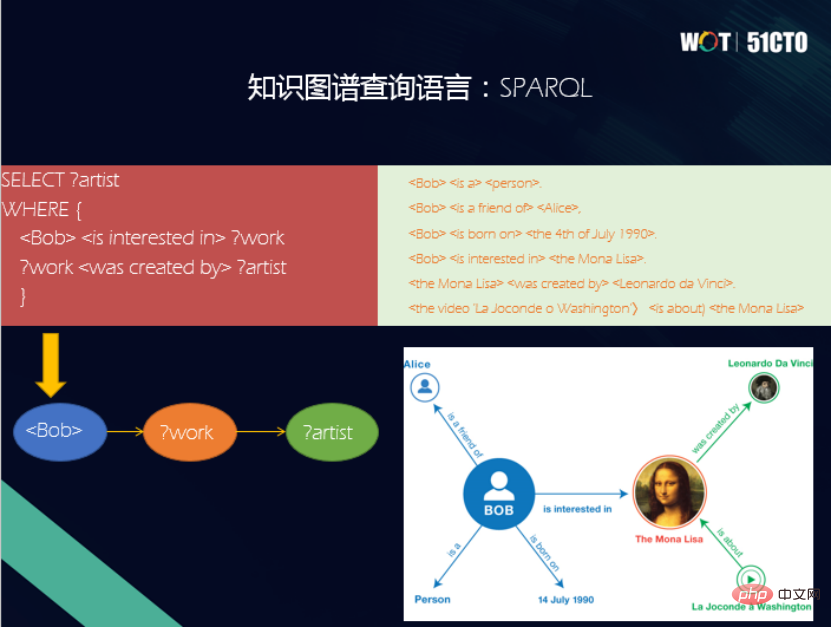
属性グラフ モデルの各頂点とエッジには一意の ID があり、頂点とエッジにはまた、一意のIDを持ち、RDFグラフのリソースタイプに相当するラベルが存在します。さらに、頂点とエッジも属性名と属性値で構成される属性のセットを持ち、属性グラフ モデルを形成します。
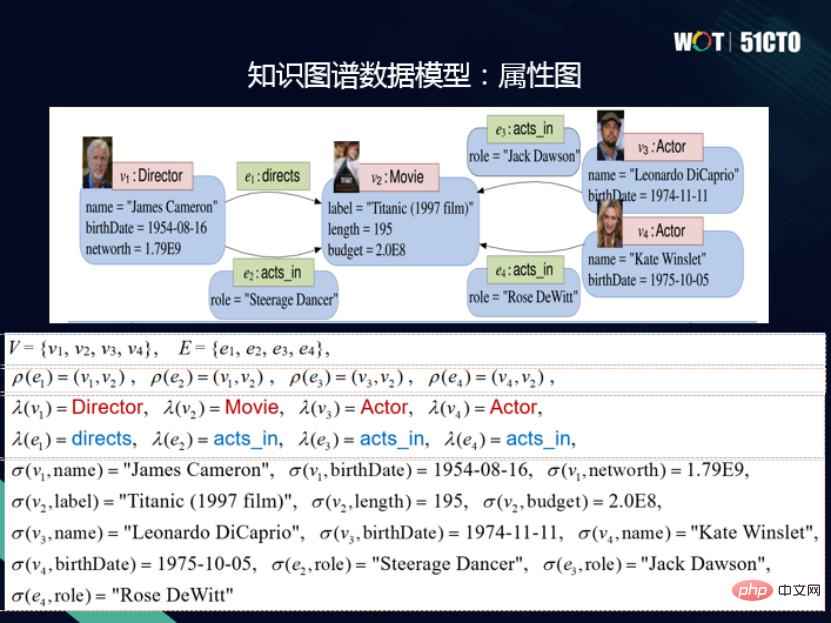
#属性グラフ モデルには、クエリ言語 Cypher もあります。 Cypher は宣言型クエリ言語でもあるため、ユーザーは検索したいものを宣言するだけでよく、検索方法を指定する必要はありません。 Cypher の主な特徴は、グラフ パターン マッチングを表現するために ASCII アーティスティックな構文を使用していることです。
人工知能の発展に伴い、認知知能の発展とナレッジグラフの応用が進んでいます。だんだん 。そのため、グラフデータベースは近年市場でますます注目を集めていますが、現在グラフが直面している重要な問題はデータモデルとクエリ言語の不一致であり、これは早急に解決する必要がある問題です。
OpenGauss グラフ データベースを学習する動機
OpenGauss グラフ データベースを学習するには、主に 2 つの出発点があります。
一方で、ナレッジ グラフ自体の特性を活用したいと考えています。たとえば、データベースでは、高パフォーマンス、高可用性、高セキュリティ、簡単な運用と保守の観点から、これらの機能をグラフ データベースに統合できることが非常に重要です。
一方、グラフ データ モデル について考えてみましょう。現在 2 つのデータ モデルと 2 つのクエリ言語があります。これら 2 つの異なるクエリ言語の背後にあるセマンティクス演算子 (リレーショナル データベースの射影、選択、結合など) を調整すると、SPARQL 言語と Cypher 言語の背後にあるセマンティクスを調整すると、次のことが提供されます。 2 つの異なる構文ビューを使用できるため、自然に相互運用性が実現します。つまり、内部セマンティクスを一貫させることができるため、Cypher を使用して RDF グラフをチェックすることができ、また SPARQL を使用して属性グラフをチェックすることもでき、これは非常に優れた機能を形成します。
最下層は OpenGauss を使用し、物理モデルを保存するためのグラフとしてリレーショナル モデルを使用します。アイデアは、RDF グラフを次のように変換することです。属性グラフに矛盾がある場合は、最大公約数を見つけて基礎となる物理ストレージを統合します。
この考え方に基づいて、OpenGauss-Graph のアーキテクチャの最下層はインフラストラクチャであり、その後にアクセス方法、統合属性グラフ、RDF グラフの処理および管理方法が続きます。次に、サブグラフ マッチング演算子、パス ナビゲーション演算子、グラフ分析演算子、キーワード クエリ演算子などの統合セマンティック演算子をサポートする統合クエリ処理実行エンジンです。さらに上位には、SPARQL インターフェイスと Cypher インターフェイスを提供する統合 API インターフェイスがあります。さらに、統合クエリ言語の言語標準と対話型クエリのビジュアル インターフェイスもあります。
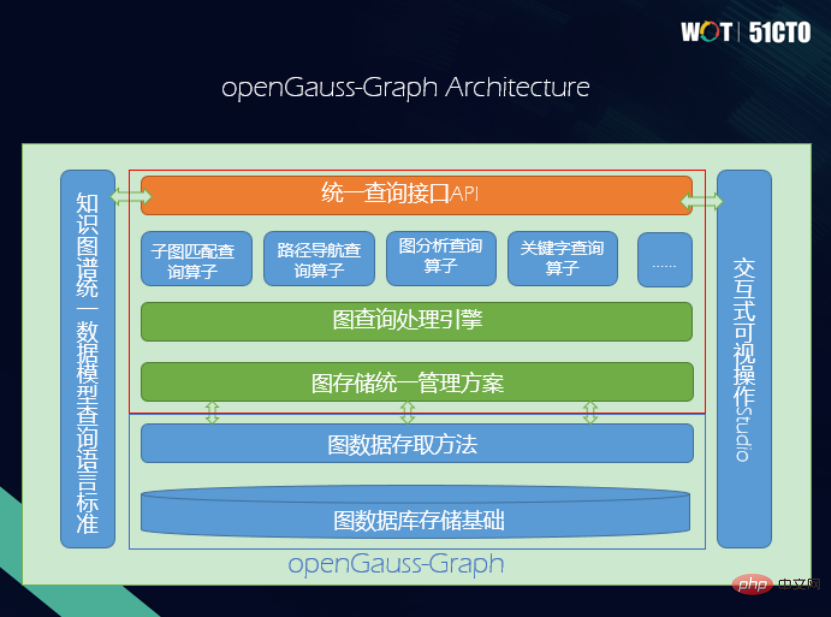
#ストレージ ソリューションの設計
(1) 複雑すぎるストレージ ソリューションの効率は高くなりすぎないため、複雑すぎることはできません。
(2) 2 つの異なるナレッジ グラフのデータ型にうまく対応できなければなりません。
したがって、ポイント テーブルとエッジ テーブル用のストレージ ソリューションがあります。プロパティと呼ばれる共通のポイント テーブルがあり、異なるポイントについては継承があり、エッジ テーブルには異なるエッジ テーブルからの継承もあります。さまざまなタイプのポイント テーブルとエッジ テーブルにはコピーが存在するため、ポイント テーブルとエッジ テーブルのコレクションのストレージ ソリューションが維持されます。
属性グラフの場合、異なるラベルを持つポイントは異なるポイント テーブルを見つけます。たとえば、教授は教授ポイント テーブルを見つけます。ポイントの属性は、ポイント テーブルの属性列にマップされます。エッジ テーブルにも同じことが当てはまり、作成者は作成者のエッジ テーブルにマップされ、エッジは、ID を持つエッジ テーブルの行にマップされます。開始ノードと終了ノード。
このように一見シンプルだが実は非常に汎用性の高い方法により、RDFグラフと属性グラフを物理層から統合することができます。しかし、実際のアプリケーションでは、型付けされていないエンティティが多数存在するため、現時点では、最も近い型付けされたテーブルに意味を分類する方法を採用しています。
#クエリ処理の実践
ストレージに加えて最も重要なのはクエリです。セマンティック レベルでは、操作を調整し、SPARQL と Cypher という 2 つのクエリ言語間の相互運用性を実現しました。
この場合、
文法と語彙という2つのレベルが関係しており、それらの解析が互いに競合してはなりません。ここにキーワードが引用されています。たとえば、SPARQL にチェックを入れると SPARQL の構文がオンになり、Cypher にチェックを入れると競合を避けるために Cypher の構文がオンになります。

#また、多くのクエリ演算子も実装しました。
(1) すべての作曲家、その音楽、作曲家の誕生日をクエリするサブグラフ マッチング クエリ
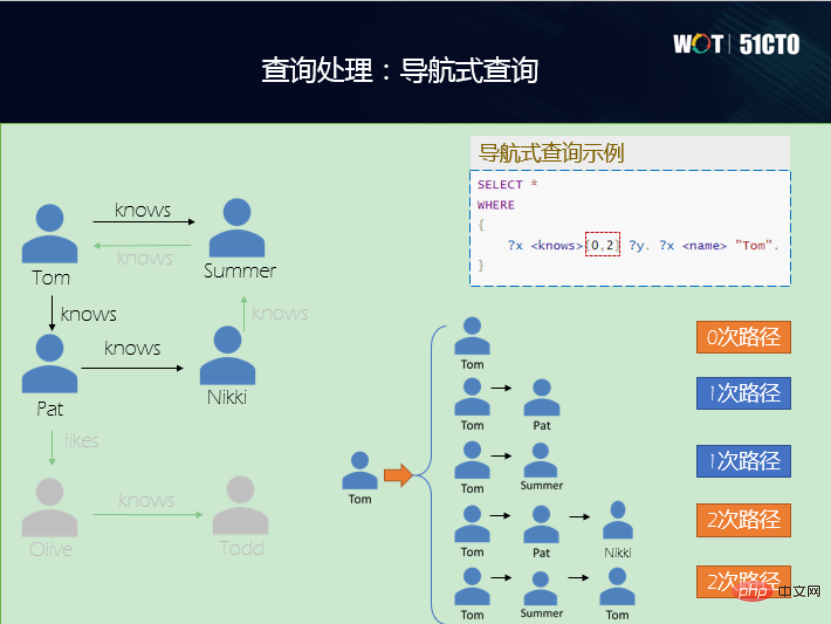
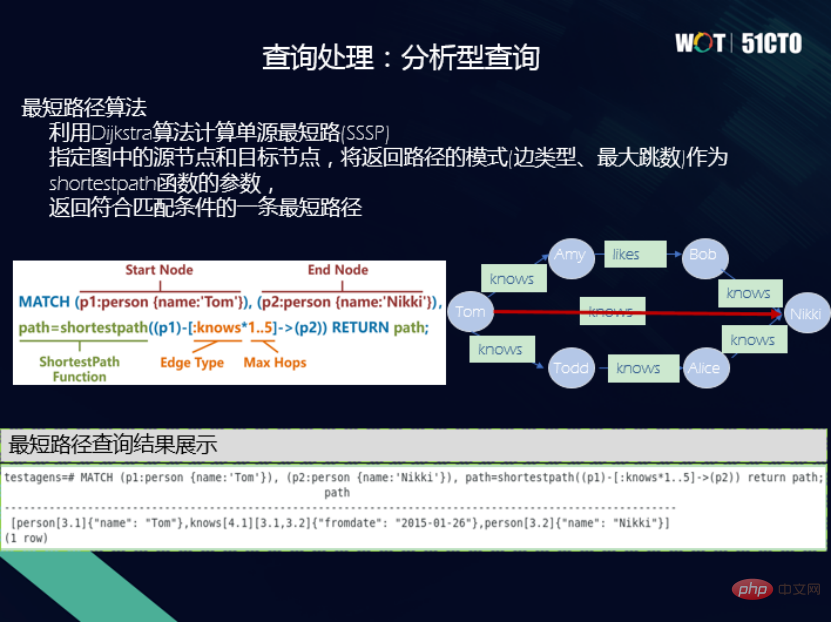
は、典型的なサブグラフ マッチング問題です。属性グラフとRDFグラフに分けられますが、大まかな処理の流れも同様です。たとえば、対応する点を結合リンク リストに追加し、プロパティ列に選択操作を追加し、先頭点パターンと末尾点パターンに対応する点テーブル間の接続に制約を課します。 RDF グラフは、エッジ テーブルの開始点と終了点で重要な操作を実行します。最終的には、射影制約が変数に追加され、最終結果が出力されます。プロセスは同様です。 サブグラフ マッチング クエリは、変数形式の制限、論理演算子、集計、算術演算子をサポートする FILTER 関数など、いくつかの組み込み関数もサポートしています。もちろん、この部分は継続することもできます。 (2) 従来のリレーショナル データベースとは異なるナビゲーション クエリ があります。ではそのようなことはありません。下の図の左側は小さなソーシャル ネットワーク グラフです。これは有向グラフです。知識が一方向であることがわかります。トムはパットを知っていますが、パットはトムを知りません。ナビゲーション クエリで 2 ホップ クエリを実行すると、トムを知っている人がわかります。ジャンプが 0 回であれば、トムは自分自身を知っています。最初のホップは、トムがパットを知っており、トムがサマーを知っているということです。 2 番目のジャンプは、トムがパットと知り合い、次にニッキーと知り合い、そして再びトムと知り合いになるときです。 (3) キーワード クエリ 、ここでは 2 つの例、tsvector と tsquery を示します。 。 1 つはドキュメントを用語のリストに変換すること、もう 1 つは指定された単語または語句がベクトル内に存在するかどうかをクエリすることです。ナレッジグラフ内のテキストが比較的長く、比較的長い属性を持っている場合、この機能を使用してキーワード検索機能を提供することができ、これも非常に便利です。 (4) 分析クエリには、グラフ データベース用の独自の機能があります。最短パス 、Pagerank などはすべてグラフベースのクエリ演算子であり、グラフ データベースに実装できます。たとえば、Tom から Nikki までの最短経路が何かを確認するには、Cypher を通じて最短経路演算子を実装し、最短経路を出力して結果を求めることができます。 #上記の機能に加えて、ビジュアルインタラクティブスタジオも実装しました。 Cypher と SPARQL を統合し、視覚的に直感的なグラフを取得し、グラフを維持、管理、適用できます。また、グラフ上で多くの操作を実行することもできます。将来的には、より多くの演算子とグラフ クエリが追加される予定です. より多くのアプリケーションの方向性とシナリオを実現するために、グラフ検索が追加されました。 最後に、どなたでも OpenGauss Graph コミュニティにアクセスしてください。OpenGauss Graph に興味のある友人もコミュニティに参加することを歓迎します。新しい貢献者として、私たちは OpenGauss Graph コミュニティを構築していきます一緒に。 Wang Lin、工学博士、OpenGauss Graph データベース コミュニティ メンテナー、Taifan Technology CTO、シニアエンジニア、中国コンピュータ連盟YOCSEF天津21-22副会長、CCF情報システム委員会執行委員、天津131人材プロジェクトに選出。 

以上がTaifan Technology の Wang Lin: グラフ データベース - 認知知能への新しい方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7318
7318
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
1. 背景の紹介 まず、Yunwen Technology の開発の歴史を紹介します。 Yunwen Technology Company ...2023 年は大規模モデルが普及する時期であり、多くの企業は大規模モデルの後、グラフの重要性が大幅に低下し、以前に検討されたプリセット情報システムはもはや重要ではないと考えています。しかし、RAG の推進とデータ ガバナンスの普及により、より効率的なデータ ガバナンスと高品質のデータが民営化された大規模モデルの有効性を向上させるための重要な前提条件であることがわかり、ますます多くの企業が注目し始めています。知識構築関連コンテンツへ。これにより、知識の構築と処理がより高いレベルに促進され、探索できる技術や方法が数多く存在します。新しいテクノロジーの出現によってすべての古いテクノロジーが打ち破られるわけではなく、新旧のテクノロジーが統合される可能性があることがわかります。
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
