

知能運転知覚システムの試験技術を詳しく解説した記事

はじめに
人工知能とそのソフトウェアおよびハードウェア技術の進歩により、自動運転は近年急速に発展しています。自動運転システムは、民間車両運転支援システム、自律物流ロボット、ドローンなどの分野で活用されています。認識コンポーネントは自動運転システムの中核であり、車両が内部および外部の交通環境に関する情報を分析および理解できるようにします。しかし、他のソフトウェア システムと同様に、自動運転認識システムもソフトウェアの欠陥に悩まされています。さらに、自動運転システムは安全性が重要なシナリオで動作するため、そのソフトウェアの欠陥が壊滅的な結果を招く可能性があります。近年、自動運転システムの不具合による死傷事故が多発しています。自動運転システムの試験技術は、学界や産業界から広く注目を集めています。企業や研究機関は、仮想シミュレーションテスト、現実の路上テスト、仮想と現実の組み合わせテストなど、一連の技術と環境を提案してきました。しかし、入力データの種類の特殊性と自動運転システムの動作環境の多様性により、この種のテスト技術の実装には過剰なリソースが必要となり、より大きなリスクが伴います。この記事では、自動運転知覚システムのテスト方法の現在の研究と応用状況を簡単に分析します。
1 自動運転認識システムのテスト
自動運転認識システムの品質保証はますます重要になっています。認識システムは、車両が道路状況情報を自動的に分析して理解するのに役立つ必要があり、その構成は非常に複雑であり、多くの交通シナリオでテストされるシステムの信頼性と安全性を十分にテストする必要があります。現在の自動運転知覚テストは主に 3 つのカテゴリーに分類されます。どのようなテスト手法であっても、テストデータに強く依存するという従来のテストとは異なる重要な特徴が見られます。
最初のタイプのテストは、主にソフトウェア工学理論や形式的手法などに基づいており、知覚システム実装のモデル構造メカニズムをエントリポイントとします。このテスト方法は、自動運転知覚の動作メカニズムとシステム特性の高度な理解に基づいています。この偏った知覚システム ロジック テストの目的は、システム開発の初期段階で知覚モジュールの設計上の欠陥を発見し、初期のシステム反復におけるモデル アルゴリズムの有効性を確認することです。研究者らは、自動運転アルゴリズムモデルの特性に基づいて、一連のテストデータ生成、テスト検証指標、テスト評価手法および技術を提案した。
2 番目のタイプのテスト仮想シミュレーション方法では、コンピューターを使用して実際の交通システムを抽象化し、事前設定された仮想環境でのシステム テストや知覚コンポーネントの独立したテストなどのテスト タスクを完了します。仮想シミュレーションテストの効果は、仮想環境の実態、テストデータの品質、具体的なテスト実行技術に依存し、シミュレーション環境の構築手法、データ品質評価、テスト検証技術の有効性を十分に検討する必要があります。自動運転環境認識およびシーン分析モデルは、トレーニングとテスト検証のために大規模で効果的な交通シーン データに依存しています。交通シーンとそのデータ構造生成技術については、国内外の研究者が多くの研究を行ってきました。データ突然変異、シミュレーション エンジンの生成、ゲーム モデルのレンダリングなどの方法を使用して仮想テスト シーン データを構築し、高品質のテスト データを取得し、生成されたさまざまなテスト データを自動運転モデルやデータの増幅と強化に使用します。テストシナリオとデータ生成は重要なテクノロジーです。テスト ケースは、テスト サンプルの状態空間をカバーできるほど豊富である必要があります。これらの境界使用例の下でシステムの意思決定出力モデルの安全性をテストするには、極端な交通状況下でテスト サンプルを生成する必要があります。仮想テストでは、既存のテスト理論とテクノロジーを組み合わせて、テストの効果を評価および検証するための効果的な方法を構築することがよくあります。
3 番目のカテゴリは、プリセットのクローズドシーンテストや実際の道路状況テストなど、自動運転認識システムを備えた実車の路上テストです。このタイプのテストの利点は、実際の環境でテストすることで結果の妥当性を完全に保証できることです。しかし、このタイプの方法には、多様なニーズを満たすのが難しいテストシナリオ、関連する交通シーンのデータサンプルの入手の困難、実際の道路収集データの手動アノテーションの高コスト、不均一なアノテーションの品質、過剰なテスト走行距離の要件などの困難があります。データ収集サイクルが長すぎるなど。危険なシナリオでの手動運転には安全上のリスクがあり、現実の世界でテスターがこれらの問題を解決することは困難です。同時に、交通現場のデータは、単一のデータソースやデータの多様性が不十分であるなどの問題も抱えており、ソフトウェア工学における自動運転研究者のテストと検証の要件を満たすには不十分です。それにもかかわらず、路上テストは従来の自動車テストに不可欠な部分であり、自動運転知覚テストにおいて非常に重要です。
テストの種類の観点から見ると、知覚システムテストは車両開発ライフサイクルごとに異なるテスト内容を持ちます。自動運転テストは、モデルインザループ(MiL)テスト、ソフトウェアインザループ(SiL)テスト、ハードウェアインザループ(HiL)テスト、ビークルインザループテストに分類できます。 (ViL) テストなどこの記事では、自動運転認識システム テストの SiL および HiL 関連部分に焦点を当てます。 HiL には、カメラ、ライダー、人間とコンピューターの相互作用の認識モジュールなどの認識ハードウェア デバイスが含まれています。 SiL は、ソフトウェア シミュレーションを使用して、実際のハードウェアによって生成されたデータを置き換えます。両方のテストの目的は、自動運転システムの機能、性能、堅牢性、信頼性を検証することです。特定のテスト対象については、認識システム開発の各段階でさまざまなタイプのテストがさまざまなテスト技術と組み合わされて、対応する検証要件が完了します。現在の自動運転知覚情報は主に、画像 (カメラ)、点群 (ライダー)、融合知覚システムなど、数種類の主要データの分析から得られます。この記事では主にこれら 3 種類のデータの知覚テストを分析します。
2 自動運転画像システム テスト
複数のタイプのカメラによって収集された画像は、自動運転の認識にとって最も重要な入力データ タイプの 1 つです。 。画像データは、車両の走行中にフロントビュー、サラウンドビュー、リアビュー、サイドビューの環境情報を提供し、自動運転システムが道路測距、目標認識と追跡、自動車線変更分析などの機能を実現するのに役立ちます。 。画像データには、RGB 画像、セマンティック画像、深度画像など、さまざまな形式があります。これらの画像形式には独自の特性があります。たとえば、RGB 画像にはより豊富な色情報が含まれ、被写界深度画像にはより多くのシーン深度情報が含まれ、セマンティック画像はピクセル分類に基づいて取得されるため、ターゲットの検出や追跡タスクに有利です。 。
画像ベースの自動運転認識システムのテストは、トレーニングとテストの検証のために大規模で効果的な交通現場の画像に依存しています。しかし、実際の道路収集データを手動でラベル付けするコストは高く、データ収集サイクルは長すぎ、危険な場面での手動運転に関する法規制は不完全で、ラベル付けの品質は不均一です。同時に、交通現場のデータは、単一のデータソースや自動運転研究のテストと検証の要件を満たすには不十分なデータの多様性などの要因にも影響されます。
国内外の研究者は、データ突然変異、敵対的生成ネットワーク、シミュレーションエンジン生成、ゲームモデルなどの方法を使用して、交通現場データの構築と生成技術について多くの研究を行ってきました。仮想テストを構築するためのレンダリング、高品質のテスト データを取得するためのシナリオ データ、および自動運転モデルとデータ拡張に生成されたさまざまなテスト データを使用します。ハードコーディングされた画像変換を使用してテスト イメージを生成することは効果的な方法です。さまざまな数学的変換と画像処理技術を使用して元の画像を変更し、さまざまな環境条件下での自動運転システムの潜在的な誤った動作をテストできます。
Zhang らは、画像スタイル変換に敵対的生成ネットワークベースの手法を使用し、指定された環境条件下で車両の運転シーンをシミュレートしました。一部の研究では、物理シミュレーション モデルからの 3D モデルを使用して交通シーンを構築し、それらを知覚システムへの入力として 2D 画像にレンダリングして、仮想環境で自動運転テストを実行しています。テスト画像は合成によって生成することもでき、低次元画像の部分空間で変更可能なコンテンツをサンプリングし、画像合成を実行します。画像の直接突然変異と比較して、合成シーンはより豊富で、画像摂動操作はより自由です。 Fremontらは、自動運転ドメイン固有のプログラミング言語Scenicを使用してテストシナリオを事前設計し、ゲームエンジンインターフェイスを使用して特定の交通シーンの画像を生成し、レンダリングされた画像をターゲット検出モデルのトレーニングと検証に使用しました。
Pei らは、自動運転ステアリング モデルの一貫性のない出力を見つけるために差分テストのアイデアを使用し、またニューロン カバレッジ、つまりニューラル領域内のニューロンを使用することを提案しました。ネットワークが事前に設定された所定の活性化しきい値を超えていることを確認して、テストサンプルの有効性を測定します。研究者らは、ニューロン カバレッジに基づいて、ニューロン境界カバレッジ、強力なニューロン カバレッジ、階層ニューロン カバレッジなど、多くの新しいテスト カバレッジの概念も提案しています。また、ヒューリスティック検索技術を利用して対象のテストケースを見つけることも有効な手法ですが、その際の最大の難点は、その検索の指針となるテスト評価指標の設計にあります。自動運転画像システムのテストには、特殊な運転シナリオ用のラベル付きデータが不足しているなどの一般的な問題があります。このチームは、自動運転知覚におけるディープ ニューラル ネットワーク テスト データのラベル付けの高い人的コストを解決するために、ソフトウェア テスト分野における適応ランダム テストのアイデアに触発された、適応型ディープ ニューラル ネットワーク テスト ケース選択方法 ATS を提案しました。システム、この問題。

3 自動運転ライダーシステムテスト
ライダーは自動運転システムにとって重要なセンサーであり、センサー送信機とターゲット間の距離を測定することができます。物体の伝播距離を測定し、物体の表面での反射エネルギー量、反射波スペクトルの振幅、周波数、位相などの情報を解析します。収集された点群データは、運転シーン内のさまざまな物体の 3 次元スケールと反射強度情報を正確に表しており、カメラのデータ形式と精度の不足を補うことができます。 LiDAR は自動運転の目標検出や位置マッピングなどのタスクで重要な役割を果たしており、単一のビジョンだけで置き換えることはできません。
#典型的な複雑なインテリジェント ソフトウェア システムである自動運転は、ライダーによって取得された周囲の環境情報を入力として受け取り、認識モジュール内の人工知能モデルを通じて判断し、制御されます。システム計画 最後に、さまざまな運転タスクを完了します。人工知能モデルの複雑さは自動運転システムに認識機能を与えますが、既存の従来のテスト技術は点群データの手動収集と注釈に依存しており、コストが高く非効率的です。一方で、点群データは乱れており、明らかな色情報が欠如しており、気象要因による干渉を受けやすく、信号が減衰しやすいため、テスト プロセスでは点群データの多様性が特に重要になります。 LIDAR に基づく自動運転システムのテストはまだ準備段階です。実走行試験もシミュレーション試験も、コストが高い、試験効率が低い、試験の妥当性が保証されていないなどの問題を抱えています。自動運転システムが直面する、変更可能なテストシナリオ、大規模かつ複雑なソフトウェアシステム、莫大なテストコストなどの課題を考慮すると、ドメイン知識に基づいたテストデータ生成技術を提案できることは、自動運転システムの保証にとって非常に重要です。 。 レーダー点群データの生成に関して、Sallab らはサイクル整合性生成敵対的ネットワークを構築することでレーダー点群データをモデル化し、シミュレートされたデータの特徴分析を行って新しいデータを生成しました。点群データ。 Yue らは,自動運転シーン用の点群データ生成フレームワークを提案した.このフレームワークは,アノテーションが付けられたオブジェクトに基づいてゲームシーン内の点群データを正確に変異させ,新しいデータを取得する.この方法を使用して得られた変異は,点群を再学習したデータである自動運転システムのデータ処理モジュールを搭載し、さらなる精度向上を実現しました。 このチームは、LIDAR 自動テスト ツール LiRTest を設計および実装しました。これは主に自動運転車両ターゲット検出システムの自動テストに使用され、システムの堅牢性を向上させるためにさらに再トレーニングできます。 LiRTest は、まずドメインの専門家によって物理モデルと幾何モデルを設計し、次にそのモデルに基づいて変換演算子を構築します。開発者は、実世界のデータから点群シードを選択し、点群処理ユニットを使用してそれらを識別および処理し、変換オペレータベースの突然変異アルゴリズムを実装して、自動運転 3D ターゲット検出モデルの堅牢性を評価するテストを生成します。最後に、LiRTest はテスト レポートを取得し、オペレーターの設計にフィードバックを提供することで、品質を反復的に向上させます。 自動運転システムは典型的な情報物理融合システムであり、その動作状態はユーザーの入力情報やソフトウェアシステムの内部状態だけでなく、次のような影響も受けます。物理的な環境。現在、さまざまな環境要因の影響を受ける点群データ生成の問題に焦点を当てた研究は少ないですが、点群データの特性により、生成されたデータの信頼性を走行テストデータと一致させることが困難です。追加のリソース消費を大幅に増やさずにこれを行うにはどうすればよいでしょうか? この場合、さまざまな実際の環境要因を説明できる点群データを自動的に生成することが、解決すべき重要な問題となります。 自動運転ソフトウェアの一般的なソフトウェア アーキテクチャでは、人工知能モデルは、運転の意思決定とシステムの動作に非常に重要な影響を与えます。影響する機能には、物体認識、経路計画、動作が含まれます。予報など点群データ処理に最も一般的に使用される人工知能モデルは、ディープ ニューラル ネットワークを使用して実装されるターゲット検出モデルです。この技術は、特定のタスクでは高い精度を達成できますが、結果の解釈可能性が欠如しているため、ユーザーや開発者がその動作を分析および確認することができず、テスト技術の開発やテストの適切性の評価に大きな困難をもたらしています。これらはすべて、将来の LIDAR モデルのテスターが直面する必要がある課題です。
自動運転システムには通常、環境情報を感知するためのさまざまなセンサーが装備されており、さまざまな自動運転タスクを実行するためのさまざまなソフトウェアとアルゴリズムが装備されています。センサーが異なれば物理的特性も異なり、アプリケーションシナリオも異なります。フュージョンセンシング技術は、単一のセンサーの環境適応性の低さを補い、複数のセンサーの連携によりさまざまな環境条件下でも自動運転システムの正常な動作を保証します。
情報記録方法が異なるため、異なるタイプのセンサー間には強い補完性があります。カメラの導入コストが低く、収集される画像データは高解像度で色や質感などの視覚情報が豊富です。ただし、カメラは環境の影響を受けやすいため、夜間、強い光、その他の光の変化時には信頼性が低くなる場合があります。一方、LiDAR は光の変化の影響を受けにくく、昼夜を問わず正確な 3 次元認識を提供します。しかし、LIDAR は高価であり、収集された点群データには色情報が不足しているため、形状が明らかでないターゲットを識別するのは困難です。各モーダルデータの利点を活用し、より深い意味情報をマイニングする方法は、融合センシング技術における重要な課題となっています。
研究者たちは、さまざまなデータ融合手法を提案してきました。深層学習に基づくライダーとカメラの融合センシング技術は、その精度の高さから主要な研究方向となっています。 Feng et al.は、融合方法を初期段階、中期段階、後期段階の融合の 3 つのタイプに簡単にまとめました。初期融合は元のデータまたは前処理されたデータのみを融合し、中間段階融合は各ブランチによって抽出されたデータ特徴をクロス融合し、後期融合は各ブランチの最終出力結果のみを融合します。ディープ ラーニング ベースのフューズド センシング テクノロジーは、既存のベンチマーク データセットで大きな可能性を示していますが、そのようなインテリジェント モデルは、複雑な環境を伴う現実世界のシナリオでは依然として誤った予期せぬ極端な動作を示し、致命的な損失につながる可能性があります。自動運転システムの安全性を確保するには、このような融合知覚モデルを徹底的にテストする必要があります。
現在、フュージョンセンシングのテスト技術はまだ準備段階にあり、テスト入力領域が巨大でデータ収集コストが高く、主な問題はテストデータの自動生成技術です。そのため、自動テストデータ生成技術が広く注目を集めています。 Wangらは、テストデータセットを生成するために幾何学的一貫性ルールに従って仮想オブジェクトを画像と点群に挿入するクロスモーダルデータ拡張アルゴリズムを提案した。 Zhangらは、点群と画像ピクセル間の正しいマッピングを維持するためにマルチモーダル変換フローを利用するマルチモーダルデータ強調方法を提案し、これに基づいてさらにマルチモーダルカットアンドペースト強調方法を提案した。
実際のシーンにおける複雑な環境がセンサーに及ぼす影響を考慮して、私たちのチームはマルチモーダルフュージョンセンシングシステム用のデータ増幅テクノロジーを設計しました。この方法には、各モーダル データの現実的なセマンティクスを備えた一連の突然変異ルールを策定するドメインの専門家が含まれます。また、実際のシナリオでセンサーに干渉するさまざまな要因をシミュレートするためのテスト データを自動的に生成し、ソフトウェア開発者による融合型センシング システムのテストと評価を支援します。この方法で使用される突然変異オペレーターには、信号ノイズ オペレーター、信号アラインメント オペレーター、および信号損失オペレーターの 3 つのカテゴリが含まれており、実際のシーンに存在するさまざまな種類の干渉をシミュレートします。ノイズ オペレーターは、センサー データ収集プロセス中の環境要因の影響により、収集されたデータにノイズが存在することを指します。たとえば、画像データの場合、スポットやブラーなどのオペレーターを使用して、カメラが強い光に遭遇して揺れたときの状況をシミュレートします。アライメント オペレーターは、特に時間のずれや空間のずれなど、マルチモーダル データ モードのずれをシミュレートします。前者の場合、1 つの信号をランダムに遅延させて、伝送の混雑または遅延をシミュレートします。後者の場合、車両の走行中の車両のジッターやその他の問題によるセンサー位置のわずかな変化をシミュレートするために、各センサーの校正パラメーターに微調整が行われます。信号損失オペレーターはセンサーの故障をシミュレートします。具体的には、1 つの信号をランダムに破棄した後、融合アルゴリズムが時間内に応答できるか、または正常に動作するかを観察します。
つまり、マルチセンサー融合知覚技術は、自動運転の開発において避けられないトレンドであり、システムが複雑な現実環境で正常に動作できることを確認するには、完全なテストが必要条件です。限られたリソースをどのように使用するか ネットワーク内での適切なテストは依然として差し迫った問題です。 ############結論は#########
自動運転知覚テストは自動運転ソフトウェア開発プロセスと密接に統合されており、さまざまなインループテストが徐々に自動運転の品質保証に必要な要素になるでしょう。産業用アプリケーションでは、実際のドライブのテストが依然として重要です。しかし、過度のコスト、不十分な効率、高い安全上の危険などの問題があり、自動運転インテリジェント知覚システムのテストと検証のニーズを満たすには程遠いです。複数の研究部門における形式的手法とシミュレーション仮想テストの急速な開発により、テストを改善する効果的な方法が提供され、研究者は仮想シミュレーション テスト手法をサポートするインテリジェント運転に適したモデル テスト指標と技術を探索しています。このチームは、高品質の自動運転知覚システムを確保するために、画像、点群データ、知覚融合テストに基づく 3 つの側面に関する詳細な研究に焦点を当て、自動運転知覚テスト データの生成、評価、最適化方法の研究に取り組んでいます。 。
以上が知能運転知覚システムの試験技術を詳しく解説した記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7494
7494
 15
1377
52
77
11
19
50
15
1377
52
77
11
19
50

 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 furmark についてどう思いますか? - furmark はどのように資格があるとみなされますか?
Mar 19, 2024 am 09:25 AM
furmark についてどう思いますか? - furmark はどのように資格があるとみなされますか?
Mar 19, 2024 am 09:25 AM
furmark についてどう思いますか? 1. メインインターフェイスで「実行モード」と「表示モード」を設定し、「テストモード」も調整して「開始」ボタンをクリックします。 2. しばらく待つと、グラフィックス カードのさまざまなパラメータを含むテスト結果が表示されます。ファーマークはどのように資格を取得しますか? 1. ファーマークベーキングマシンを使用し、約 30 分間結果を確認します。室温 19 度、ピーク値は 87 度で、基本的に 85 度前後で推移します。大型シャーシ、シャーシ ファン ポートが 5 つあり、前面に 2 つ、上部に 2 つ、背面に 1 つありますが、ファンは 1 つだけ取り付けられています。すべてのアクセサリはオーバークロックされていません。 2. 通常の状況では、グラフィックス カードの通常の温度は「30 ~ 85℃」である必要があります。 3. 周囲温度が高すぎる夏でも、通常の温度は「50〜85℃」です
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
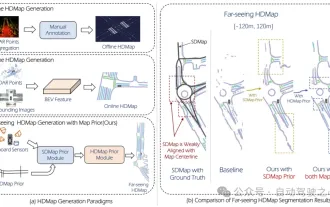 量産型キラー! P-Mapnet: 従来の低精度地図 SDMap を使用することで、マッピングのパフォーマンスが 20 ポイント近く大幅に向上しました。
Mar 28, 2024 pm 02:36 PM
量産型キラー! P-Mapnet: 従来の低精度地図 SDMap を使用することで、マッピングのパフォーマンスが 20 ポイント近く大幅に向上しました。
Mar 28, 2024 pm 02:36 PM
上で書いたように、高精度地図への依存を取り除くために現在の自動運転システムで使用されているアルゴリズムの 1 つは、長距離領域での知覚性能が依然として低いという事実を利用するものです。この目的を達成するために、私たちは P-MapNet を提案します。「P」はモデルのパフォーマンスを向上させるためにマップ事前分布を融合することに焦点を当てています。具体的には、SDMap と HDMap の事前情報を活用します。一方で、OpenStreetMap から弱く調整された SDMap データを抽出し、入力をサポートするためにそれを独立した用語にエンコードします。厳密に変更された入力と実際の HD+Map の間には調整が弱いという問題がありますが、クロスアテンション メカニズムに基づく構造は、SDMap スケルトンに適応的に焦点を合わせ、大幅なパフォーマンスの向上をもたらします。
