

Pythonで観光スポット情報や口コミを取得し、ワードクラウドやデータ可視化を作成


みなさんこんにちは、ちぇしゅさんです!
よく言われるように、遠くから友達が来てくれたら嬉しいと思いませんか?友達が遊びに来てくれるのはとても嬉しいことなので、私たちも大家になって友達を遊びに連れて行ってあげられるように頑張らなければなりません!そこで問題は、いつ、どこに行くのが最適で、最も楽しい場所はどこなのかということです。
今日は、スレッド プールを使用してアトラクション情報をクロールし、同じ旅行のデータを確認し、ワード クラウドとデータの視覚化を行う方法を段階的に説明します。 ! !さまざまな都市の観光スポット情報をお知らせします。
データのクロールを始める前に、まずスレッドについて理解しましょう。
スレッド
プロセス: プロセスは、データ収集に対するコードの実行アクティビティであり、システム内のリソース割り当てとスケジューリングの基本単位です。
スレッド: 軽量プロセスであり、プログラム実行の最小単位であり、プロセスの実行パスです。
プロセス内には少なくとも 1 つのスレッドがあり、プロセス内の複数のスレッドがプロセスのリソースを共有します。
スレッド ライフ サイクル
複数のスレッドを作成する前に、次の図に示すように、まずスレッド ライフ サイクルについて学習しましょう。
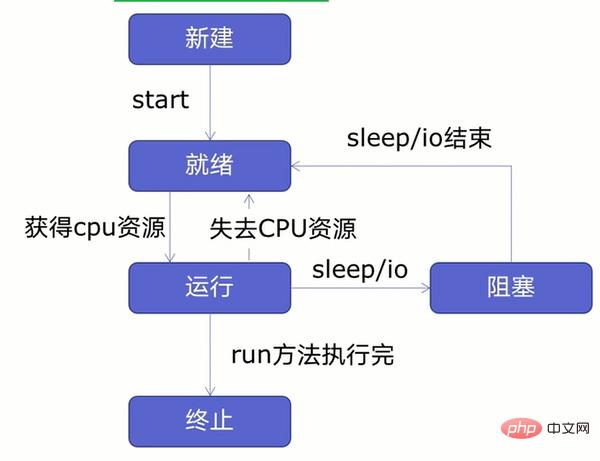
図からわかるように、スレッドは、新規、準備完了、実行中、ブロック、終了の 5 つの状態に分類できます。
まず、新しいスレッドを作成し、スレッドを開始します。スレッドが準備完了状態になった後、準備完了状態のスレッドはすぐには実行されません。CPU リソースを取得した後でのみ実行状態になります。実行状態では、スレッドは CPU を失う可能性があります。リソースがスリープまたは IO 操作 (読み取り、書き込みなど) に遭遇すると、スレッドは準備完了状態またはブロック状態になります。スリープまたは IO 操作が終了した後にのみ実行状態に入ります。または CPU リソースが回復され、操作が完了すると終了状態になります。
注: 新しいスレッド システムの作成にはリソースの割り当てが必要で、スレッド システムの終了にはリソースのリサイクルが必要です。では、スレッドの作成/終了に伴うシステム オーバーヘッドを軽減するにはどうすればよいでしょうか? 現時点では、スレッド プールを作成して、スレッドを再利用することで、システムのオーバーヘッドを削減できます。
スレッド プールを作成する前に、まず複数のスレッドを作成する方法を学びましょう。
マルチスレッドの作成
マルチスレッドの作成は、次の 4 つのステップに分けることができます:
- 関数の作成;
- スレッドの作成;
- スレッドを開始;
- 最後まで待つ;
関数を作成
デモンストレーションの便宜上、次を使用します。 Blog Park の Web ページをクローラー関数として使用します。具体的なコードは次のとおりです。
import requests
urls=[
f'https://www.cnblogs.com/#p{page}'
for page in range(1,50)
]
def get_parse(url):
response=requests.get(url)
print(url,len(response.text))まず、リクエスト ネットワーク リクエスト ライブラリをインポートし、クロールするすべての URL をリストに保存してから、 get_parse 関数を使用してネットワーク要求を送信し、要求された URL と応答の文字長を出力します。
スレッドの作成
前の手順でクローラー関数を作成しましたが、今度はスレッドを作成します。具体的なコードは次のとおりです:
import threading #多线程 def multi_thread(): threads=[] for url in urls: threads.append( threading.Thread(target=get_parse,args=(url,)) )
まず、スレッド モジュールをインポートし、multi_thread 関数をカスタマイズし、スレッド タスクを保存する空のリスト スレッドを作成し、threading.Thread() メソッドを通じてスレッドを作成します。その中で:
- target は実行中の関数、
- args は関数の実行に必要なパラメータです。
args のパラメータはタプルとして渡され、.append() メソッドを通じてスレッドの空のリストにスレッドを追加する必要があることに注意してください。
スレッドの開始
スレッドが作成されました。次にスレッドが開始されます。スレッドの開始は非常に簡単で、具体的なコードは次のとおりです:
for thread in threads: thread.start()
まず、for ループを通じてスレッド リスト内のスレッド タスクを取得し、.start() を通じてスレッドを開始します。
終了を待つ
スレッドを開始した後、次のステップはスレッドが終了するのを待つことになります。具体的なコードは次のとおりです:
for thread in threads: thread.join()
スレッドの開始と同じように、まず for ループを通じてスレッド リスト内のスレッド タスクを取得し、次に .join() メソッドを使用してスレッドが終了するのを待ちます。
マルチスレッドが作成されました。次に、マルチスレッドの速度をテストします。具体的なコードは次のとおりです:
if __name__ == '__main__': t1=time.time() multi_thread() t2=time.time() print(t2-t1)
実行結果は以下のとおりです:
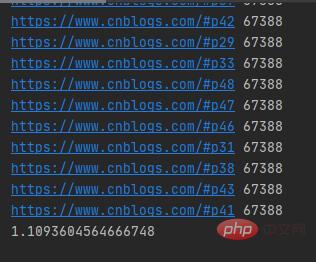
複数のスレッドを使用して 50 のブログ ガーデン Web ページをクロールするのに 1 秒以上かかります。ネットワーク リクエストに対してマルチスレッドによって送信される URL はランダムです。
単一スレッドの実行時間をテストしてみましょう。具体的なコードは次のとおりです:
if __name__ == '__main__': t1=time.time() for i in urls: get_parse(i) t2=time.time() print(t2-t1)
実行結果は次のとおりです:
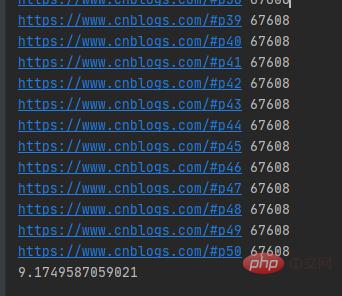
単一のスレッドが 50 個のブログ パーク Web ページをクロールするのに 9 秒以上かかりました。単一のスレッドはネットワーク リクエストの URL を順番に送信しました。
上で述べたように、新しいスレッド システムの作成にはリソースの割り当てが必要であり、スレッド システムの終了にはリソースのリサイクルが必要です。システムのオーバーヘッドを削減するために、スレッド プールを作成できます。
线程池原理
一个线程池由两部分组成,如下图所示:
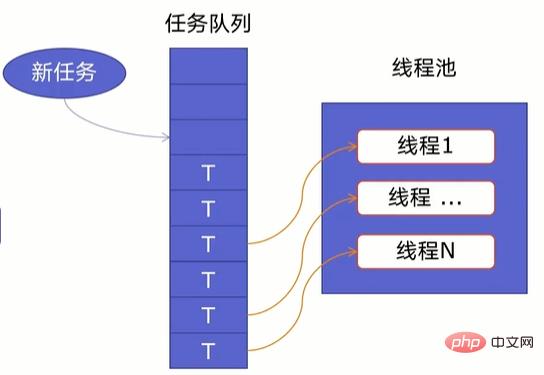
- 线程池:里面提前建好N个线程,这些都会被重复利用;
- 任务队列:当有新任务的时候,会把任务放在任务队列中。
当任务队列里有任务时,线程池的线程会从任务队列中取出任务并执行,执行完任务后,线程会执行下一个任务,直到没有任务执行后,线程会回到线程池中等待任务。
使用线程池可以处理突发性大量请求或需要大量线程完成任务(处理时间较短的任务)。
好了,了解了线程池原理后,我们开始创建线程池。
线程池创建
Python提供了ThreadPoolExecutor类来创建线程池,其语法如下所示:
ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
其中:
- max_workers:最大线程数;
- thread_name_prefix:允许用户控制由线程池创建的threading.Thread工作线程名称以方便调试;
- initializer:是在每个工作者线程开始处调用的一个可选可调用对象;
- initargs:传递给初始化器的元组参数。
注意:在启动 max_workers 个工作线程之前也会重用空闲的工作线程。
在ThreadPoolExecutor类中提供了map()和submit()函数来插入任务队列。其中:
map()函数
map()语法格式为:
map(调用方法,参数队列)
具体示例如下所示:
import requestsimport concurrent.futuresimport timeurls=[f'https://www.cnblogs.com/#p{page}'for page in range(1,50)]def get_parse(url):response=requests.get(url)return response.textdef map_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20) as pool:htmls=pool.map(get_parse,urls)htmls=list(zip(urls,htmls))for url,html in htmls:print(url,len(html))if __name__ == '__main__':t1=time.time()map_pool()t2=time.time()print(t2-t1)首先我们导入requests网络请求库、concurrent.futures模块,把所有的URL放在urls列表中,然后自定义get_parse()方法来返回网络请求返回的数据,再自定义map_pool()方法来创建代理池,其中代理池的最大max_workers为20,调用map()方法把网络请求任务放在任务队列中,在把返回的数据和URL合并为元组,并放在htmls列表中。
运行结果如下图所示:
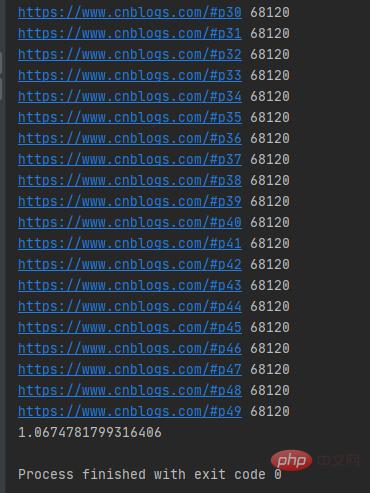
可以发现map()函数返回的结果和传入的参数顺序是对应的。
注意:当我们直接在自定义方法get_parse()中打印结果时,打印结果是乱序的。
submit()函数
submit()函数语法格式如下:
submit(调用方法,参数)
具体示例如下:
def submit_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20)as pool:futuress=[pool.submit(get_parse,url)for url in urls]futures=zip(urls,futuress)for url,future in futures:print(url,len(future.result()))
运行结果如下图所示:
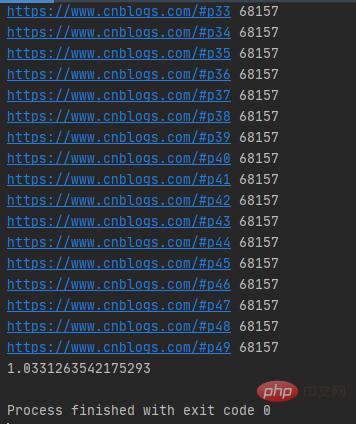
注意:submit()函数输出结果需需要调用result()方法。
好了,线程知识就学到这里了,接下来开始我们的爬虫。
爬前分析
首先我们进入同程旅行的景点网页并打开开发者工具,如下图所示:
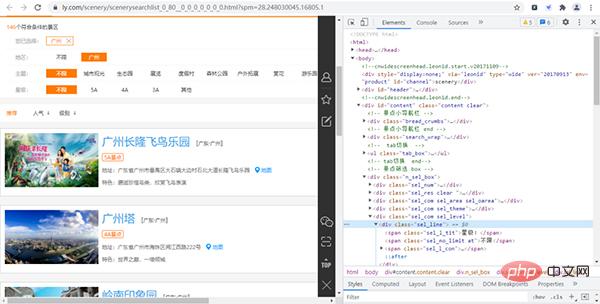
经过寻找,我们发现各个景点的基础信息(详情页URL、景点id等)都存放在下图的URL链接中,
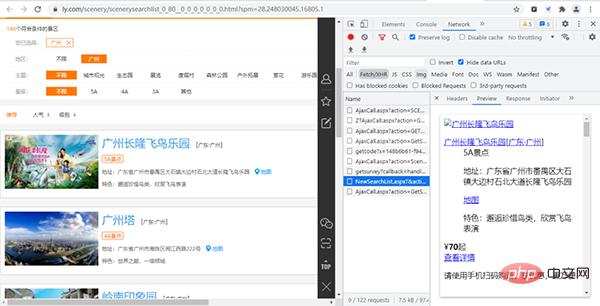
其URL链接为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=2&kw=&pid=6&cid=80&cyid=0&sort=&isnow=0&spType=&lbtypes=&IsNJL=0&classify=0&grade=&dctrack=1%CB%871629537670551030%CB%8720%CB%873%CB%872557287248299209%CB%870&iid=0.6901326566387387
经过增删改查操作,我们可以把该URL简化为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=1&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0
其中page为我们翻页的重要参数。
打开该URL链接,如下图所示:
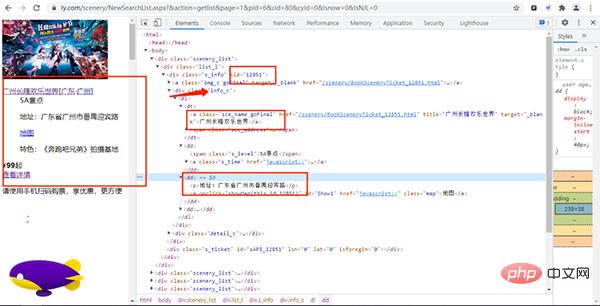
通过上面的URL链接,我们可以获取到很多景点的基础信息,随机打开一个景点的详情网页并打开开发者模式,经过查找,评论数据存放在如下图的URL链接中,
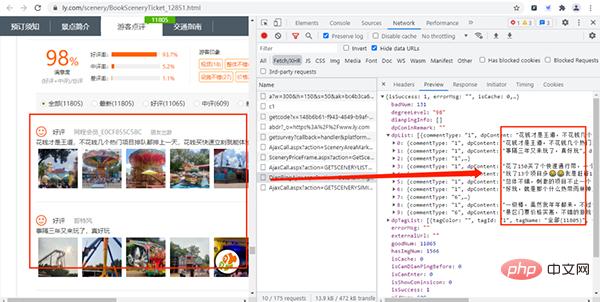
其URL链接如下所示:
https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid=12851&page=1&pageSize=10&labId=1&sort=0&iid=0.48901069375088
其中:action、labId、iid、sort为常量,sid是景点的id,page控制翻页,pageSize是每页获取的数据量。
在上上步中,我们知道景点id的存放位置,那么构造评论数据的URL就很简单了。
实战演练
这次我们爬虫步骤是:
- 获取景点基本信息
- 获取评论数据
- 创建MySQL数据库
- 保存数据
- 创建线程池
- 数据分析
获取景点基本信息
首先我们先获取景点的名字、id、价格、特色、地点和等级,主要代码如下所示:
def get_parse(url):response=requests.get(url,headers=headers)Xpath=parsel.Selector(response.text)data=Xpath.xpath('/html/body/div')for i in data:Scenery_data={'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(),'sid':i.xpath('//div[@]/div/@sid').extract_first(),'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''),'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(),'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(),'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8]}首先自定义方法get_parse()来发送网络请求后使用parsel.Selector()方法来解析响应的文本数据,然后通过xpath来获取数据。
获取评论数据
获取景点基本信息后,接下来通过景点基本信息中的sid来构造评论信息的URL链接,主要代码如下所示:
def get_data(Scenery_data):for i in range(1,3):link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832'response=requests.get(link,headers=headers)Json=response.json()commtent_detailed=Json.get('dpList')# 有评论数据if commtent_detailed!=None:for i in commtent_detailed:Comment_information={'dptitle':Scenery_data['title'],'dpContent':i.get('dpContent'),'dpDate':i.get('dpDate')[5:7],'lineAccess':i.get('lineAccess')}#没有评论数据elif commtent_detailed==None:Comment_information={'dptitle':Scenery_data['title'],'dpContent':'没有评论','dpDate':'没有评论','lineAccess':'没有评论'}首先自定义方法get_data()并传入刚才获取的景点基础信息数据,然后通过景点基础信息的sid来构造评论数据的URL链接,当在构造评论数据的URL时,需要设置pageSize和page这两个变量来获取多条评论和进行翻页,构造URL链接后就发送网络请求。
这里需要注意的是:有些景点是没有评论,所以我们需要通过if语句来进行设置。
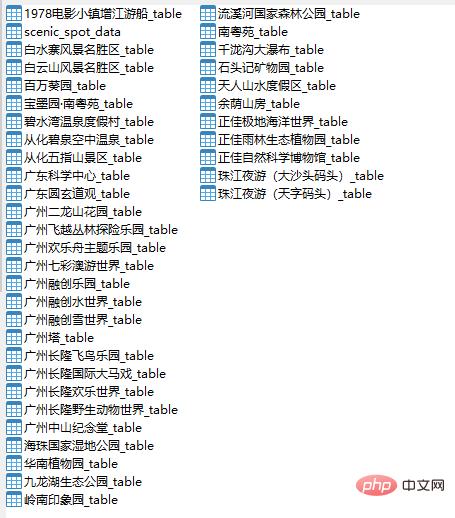
创建MySQL数据库
这次我们把数据存放在MySQL数据库中,由于数据比较多,所以我们把数据分为两种数据表,一种是景点基础信息表,一种是景点评论数据表,主要代码如下所示:
#创建数据库def create_db():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port)cursor=db.cursor()sql='create database if not exists commtent default character set utf8'cursor.execute(sql)db.close()create_table()#创建景点信息数据表def create_table():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent')cursor=db.cursor()sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)'cursor.execute(sql)db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接,最后调用自定义方法create_table()来创建景点信息数据表。
这里我们只给出了创建景点信息数据表的代码,因为创建数据表只是sql这条语句稍微有点不同,其他都一样,大家可以参考这代码来创建各个景点评论数据表。
保存数据
创建好数据库和数据表后,接下来就要保存数据了,主要代码如下所示:
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,使用了try-except语句,当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
#保存景点数据到景点数据表中def saving_scenery_data(srr):db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent')cursor = db.cursor()sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)'try:cursor.execute(sql, srr)db.commit()except:db.rollback()db.close()
注意:srr是传入的景点信息数据。
创建线程池
好了,单线程爬虫已经写好了,接下来将创建一个函数来创建我们的线程池,使单线程爬虫变为多线程,主要代码如下所示:
urls = [f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0'for i in range(1, 6)]def multi_thread():with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool:h=pool.map(get_parse,urls)if __name__ == '__main__':create_db()multi_thread()创建线程池的代码很简单就一个with语句和调用map()方法
运行结果如下图所示:
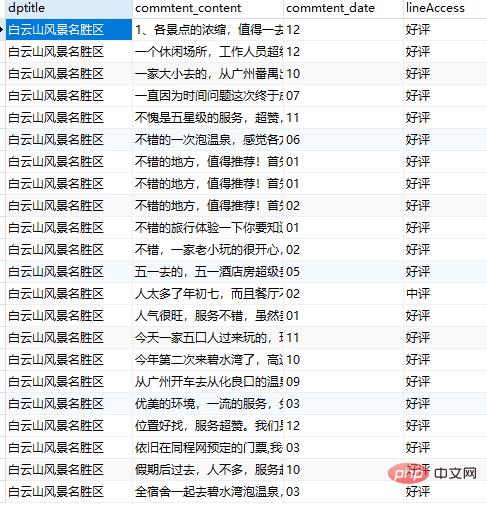
好了,数据已经获取到了,接下来将进行数据分析。
数据可视化
首先我们来分析一下各个景点那个月份游玩的人数最多,这样我们就不用担心去游玩的时机不对了。
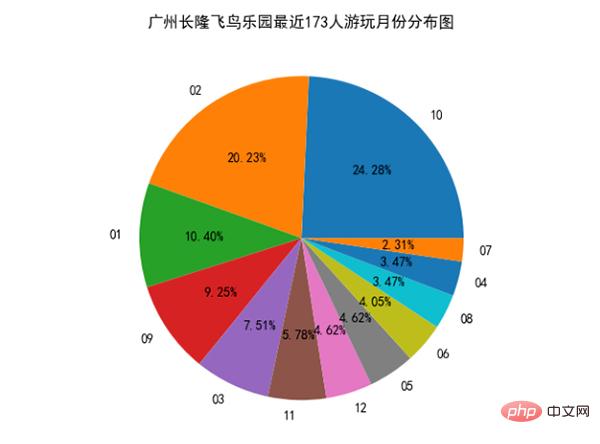
我们发现10月、2月、1月去广州长隆飞鸟乐园游玩的人数占总体比例最多。分析完月份后,我们来看看评论情况如何:
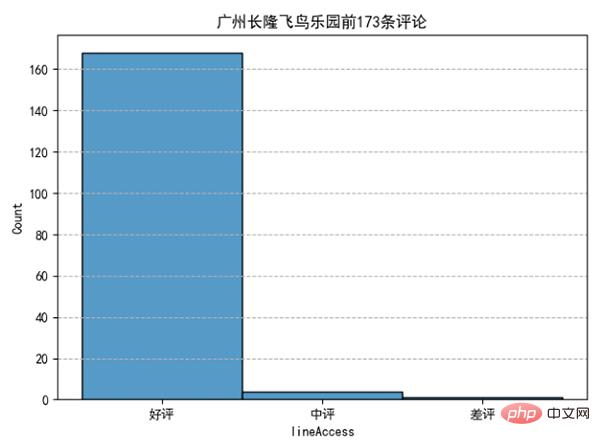
可以发现去好评占了绝大部分,可以说:去长隆飞鸟乐园玩耍,去了都说好。看了评论情况,评论内容有什么:

好了,获取旅游景点信息及评论并做词云、数据可视化就讲到这里了。
以上がPythonで観光スポット情報や口コミを取得し、ワードクラウドやデータ可視化を作成の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1663
1663
 14
1419
52
1313
25
1264
29
1237
24
14
1419
52
1313
25
1264
29
1237
24

 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。
 PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。
 PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPは1994年に発信され、Rasmuslerdorfによって開発されました。もともとはウェブサイトの訪問者を追跡するために使用され、サーバー側のスクリプト言語に徐々に進化し、Web開発で広く使用されていました。 Pythonは、1980年代後半にGuidovan Rossumによって開発され、1991年に最初にリリースされました。コードの読みやすさとシンプルさを強調し、科学的コンピューティング、データ分析、その他の分野に適しています。
 Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。
 Sublime Code Pythonを実行する方法
Apr 16, 2025 am 08:48 AM
Sublime Code Pythonを実行する方法
Apr 16, 2025 am 08:48 AM
PythonコードをSublimeテキストで実行するには、最初にPythonプラグインをインストールし、次に.pyファイルを作成してコードを書き込み、Ctrl Bを押してコードを実行する必要があります。コードを実行すると、出力がコンソールに表示されます。
 vscodeでコードを書く場所
Apr 15, 2025 pm 09:54 PM
vscodeでコードを書く場所
Apr 15, 2025 pm 09:54 PM
Visual Studioコード(VSCODE)でコードを作成するのはシンプルで使いやすいです。 VSCODEをインストールし、プロジェクトの作成、言語の選択、ファイルの作成、コードの書き込み、保存して実行します。 VSCODEの利点には、クロスプラットフォーム、フリーおよびオープンソース、強力な機能、リッチエクステンション、軽量で高速が含まれます。
 Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
VSコードはPythonの書き込みに使用でき、Pythonアプリケーションを開発するための理想的なツールになる多くの機能を提供できます。ユーザーは以下を可能にします。Python拡張機能をインストールして、コードの完了、構文の強調表示、デバッグなどの関数を取得できます。デバッガーを使用して、コードを段階的に追跡し、エラーを見つけて修正します。バージョンコントロールのためにGitを統合します。コードフォーマットツールを使用して、コードの一貫性を維持します。糸くずツールを使用して、事前に潜在的な問題を発見します。
 メモ帳でPythonを実行する方法
Apr 16, 2025 pm 07:33 PM
メモ帳でPythonを実行する方法
Apr 16, 2025 pm 07:33 PM
メモ帳でPythonコードを実行するには、Python実行可能ファイルとNPPEXECプラグインをインストールする必要があります。 Pythonをインストールしてパスを追加した後、nppexecプラグインでコマンド「python」とパラメーター "{current_directory} {file_name}"を構成して、メモ帳のショートカットキー「F6」を介してPythonコードを実行します。
