

階層的クラスタリングを 1 つの記事で理解する (Python コード)


まず、クラスタリングは機械学習の教師なし学習に属し、有名なK-meansなど多くの手法があります。階層クラスタリングもクラスタリングの一種で、非常に一般的に使用されます。次に、K 平均法の基本原理を簡単に確認してから、誰にとっても理解しやすいように、階層的クラスタリングの定義と階層的な手順をゆっくりと紹介します。
階層的クラスタリングと K 平均法の違いは何ですか?
K 平均法の動作原理は、次のように簡単に要約できます。
- クラスターの数 (k) を決定します。
- データから k 点をランダムに選択します。 centroids
- すべてのポイントを最も近いクラスターの重心に割り当てます
- 新しく形成されたクラスターの重心を計算します
- 手順 3 と 4 を繰り返します
これは新しく形成されたクラスターの重心が変わらないか、最大反復回数に達するまでの反復プロセスです。
しかし、K 平均法にはいくつかの欠点があります。アルゴリズムを開始する前に、クラスターの数 K を決定する必要があります。しかし、実際には、クラスターの数がいくつあるべきかわかりません。そのため、通常は自分自身の理解に基づいて決定します。 . 最初に値を設定すると、理解と実際の状況に多少の誤差が生じる可能性があります。
階層的クラスタリングはまったく異なります。最初にクラスタの数を指定する必要はありません。代わりに、最初に階層的クラスタリング全体を完全に形成し、次に適切な距離を決定することによって、対応するクラスタ番号を決定します。および合計は自動的に見つけることができます。
階層的クラスタリングとは何ですか?
階層的クラスタリングがどのようなものかを浅いものから深いものまで紹介しましょう。簡単な例から始めましょう。
次の点があり、それらをグループ化したいとします。

これらの各点を別個のクラスター、つまり 4 つのクラスターに割り当てることができます ( 4 色):

次に、これらのクラスターの類似性 (距離) に基づいて、最も類似した (最も近い) 点がグループ化され、クラスターが 1 つだけ残るまでこのプロセスを繰り返します。 :
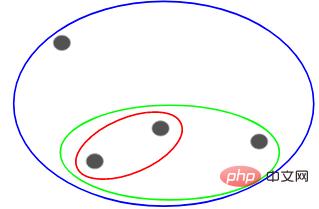
上記は基本的に階層を構築することです。まずこれを理解してください。後でその階層化手順を詳しく紹介します。
階層的クラスタリングのタイプ
階層的クラスタリングには主に 2 つのタイプがあります:
- 凝集型階層的クラスタリング
- 分割型階層的クラスタリング
凝集型階層クラスタリング
まず、すべてのポイントを個別のクラスターにし、最終的にクラスターが 1 つだけになるまで、類似性によってそれらを結合し続けます。これが凝集型階層クラスタリングです。プロセスは次のとおりです。上で述べたことと一致します。
分割階層クラスタリング
分割階層クラスタリングはその逆で、単一のクラスターから開始して、分割できなくなるまで徐々に分割します (つまり、各ポイントがクラスターになります)。
したがって、データ ポイントが 10、100、または 1000 個あるかどうかは問題ではありません。これらのポイントはすべて、最初は同じクラスターに属しています。 #次に、反復ごとにクラスター内の最も遠い 2 つのポイントを分割し、各クラスターに 1 つのポイントのみが含まれるまでこのプロセスを繰り返します。
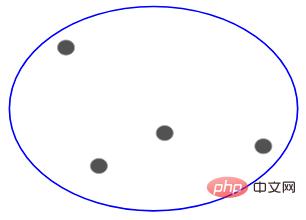
#上記のプロセスは階層クラスタリングを分割しています。 。
階層的クラスタリングを実行する手順
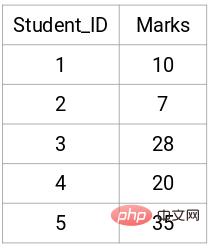
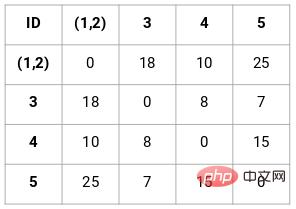
近接行列の作成
まず、n 正方行列の形状を取得できるように、各点間の距離を保存する近接行列を作成する必要があります。 Xnの。
この場合、次の 5 x 5 の近接行列が得られます。
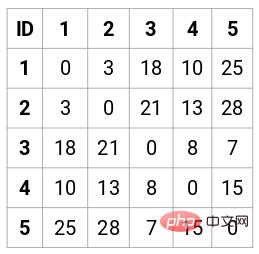
行列には 2 つの注意点があります。
- 点からの点までの距離が常に 0 であるため、行列の対角要素は常に 0 になります。
- ユークリッド距離公式を使用して非対角要素の距離を計算します
たとえば、点 1 と点 2 の間の距離を計算したいとします。計算式は次のとおりです。
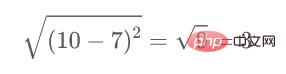
同様に、この計算方法を完了した後、近接行列の残りの要素。
階層クラスタリングの実行
これは、凝集型階層クラスタリングを使用して実装されます。
ステップ 1: まず、すべてのポイントを 1 つのクラスターに割り当てます。

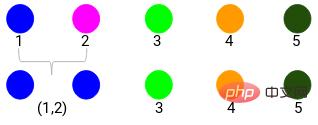
ここでは、異なる色が異なるクラスターを表しており、そのうちの 5 つはデータ ポイントにあります。つまり、5 つの異なるクラスターが存在します。
ステップ 2: 次に、近接行列で最小距離を見つけて、最小距離の点を結合する必要があります。次に、近接行列を更新します。
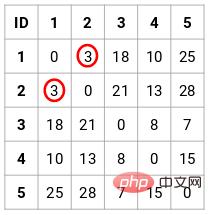
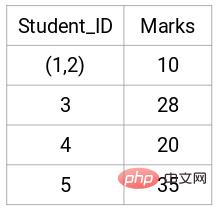
最小距離は 3 なので、ポイント 1 と 2 をマージします。
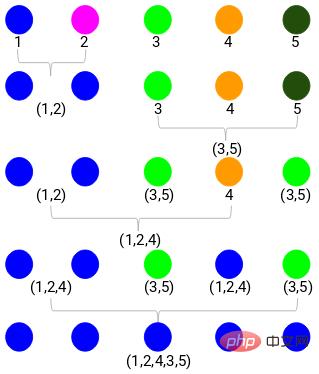
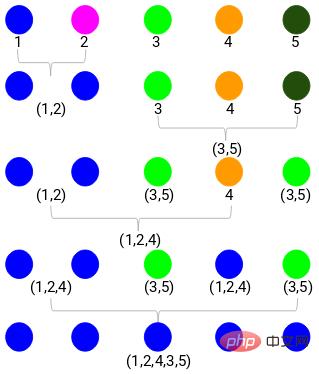
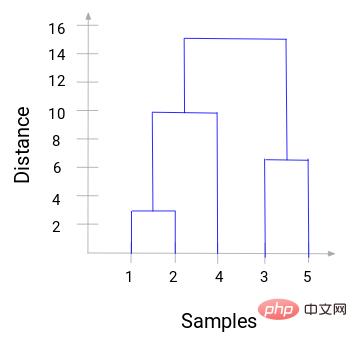
樹状図を使用すると、階層的クラスタリングのステップを明確に視覚化できます。樹形図の垂直線の間隔が離れるほど、クラスター間の距離は長くなります。
この樹状図を使用すると、クラスターの数を決定するのがはるかに簡単になります。
これで、距離のしきい値を設定し、水平線を描くことができます。たとえば、しきい値を 12 に設定し、次のように水平線を引きます。
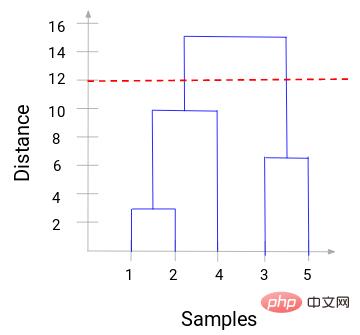
交点からわかるように、クラスターの数は、水平線のしきい値と垂直線の量 (赤い線は 2 本の垂直線と交差します。クラスターは 2 つになります)。横軸に対応して、1 つのクラスターにはサンプル セット (1、2、4) があり、もう 1 つのクラスターにはサンプル セット (3、5) があります。
このようにして、樹状図を通じて階層的クラスタリングにおけるクラスターの数を決定する問題を解決します。
Python コードの実践例
上記は理論的な基礎であり、数学的な基礎が少しあれば誰でも理解できます。 Python コードを使用してこのプロセスを実装する方法は次のとおりです。ここでは、表示する顧客セグメンテーション データを示します。
データセットとコードは私の GitHub リポジトリにあります:
https://github.com/xiaoyusmd/PythonDataScience
役に立ったと思われる場合は、星を付けてください。
このデータは、UCI 機械学習ライブラリから取得したものです。私たちの目的は、牛乳、食料品、地域などのさまざまな製品カテゴリーに対する年間支出に基づいて、卸売業者の顧客をセグメント化することです。
まずデータを標準化して、同じディメンション内のすべてのデータを計算しやすくし、次に階層的クラスタリングを適用して顧客をセグメント化します。
from sklearn.preprocessing import normalize
data_scaled = normalize(data)
data_scaled = pd.DataFrame(data_scaled, columns=data.columns)
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(data_scaled, method='ward'))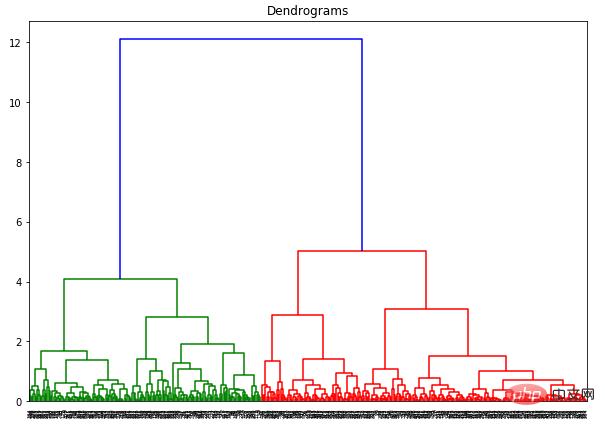
X 軸にはすべてのサンプルが含まれ、Y 軸はこれらのサンプル間の距離を表します。最大距離の垂直線は青い線です。しきい値 6 で樹状図を切り取ることにしたとします:
plt.figure(figsize=(10, 7))
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(data_scaled, method='ward'))
plt.axhline(y=6, color='r', linestyle='--')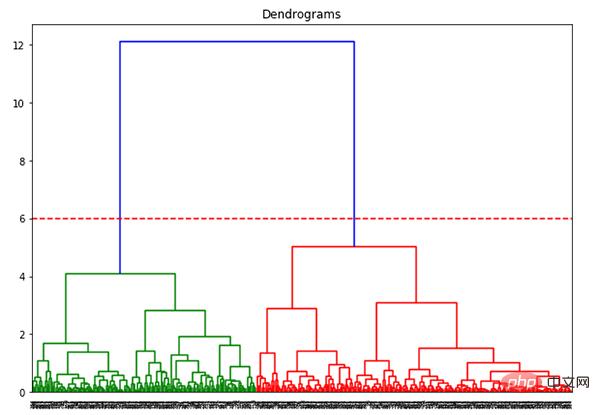
2 つのクラスターがあるので、次のことが必要です。クラスターに階層クラスタリングを適用するには:
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward') cluster.fit_predict(data_scaled)

2 つのクラスターを定義したため、出力には 0 と 1 の値が表示されます。 0 は最初のクラスターに属する点を表し、1 は 2 番目のクラスターに属する点を表します。
plt.figure(figsize=(10, 7)) plt.scatter(data_scaled['Milk'], data_scaled['Grocery'], c=cluster.labels_)
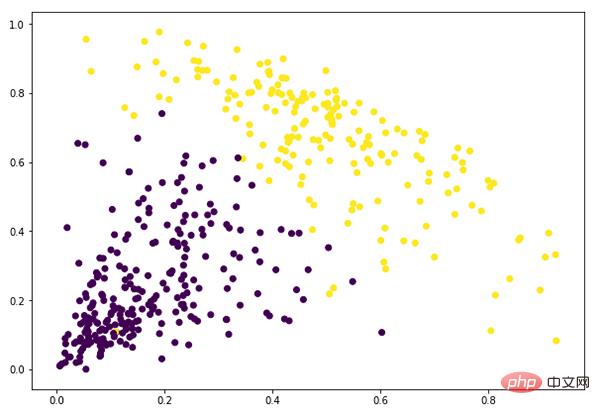
この時点で、クラスタリングは正常に完了しました。
以上が階層的クラスタリングを 1 つの記事で理解する (Python コード)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7680
7680
 15
1393
52
1209
24
91
11
15
1393
52
1209
24
91
11

 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。
 PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。
 Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。
 Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
VSコードはPythonの書き込みに使用でき、Pythonアプリケーションを開発するための理想的なツールになる多くの機能を提供できます。ユーザーは以下を可能にします。Python拡張機能をインストールして、コードの完了、構文の強調表示、デバッグなどの関数を取得できます。デバッガーを使用して、コードを段階的に追跡し、エラーを見つけて修正します。バージョンコントロールのためにGitを統合します。コードフォーマットツールを使用して、コードの一貫性を維持します。糸くずツールを使用して、事前に潜在的な問題を発見します。
 VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSコード拡張機能は、悪意のあるコードの隠れ、脆弱性の活用、合法的な拡張機能としての自慰行為など、悪意のあるリスクを引き起こします。悪意のある拡張機能を識別する方法には、パブリッシャーのチェック、コメントの読み取り、コードのチェック、およびインストールに注意してください。セキュリティ対策には、セキュリティ認識、良好な習慣、定期的な更新、ウイルス対策ソフトウェアも含まれます。
 Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
VSコードはWindows 8で実行できますが、エクスペリエンスは大きくない場合があります。まず、システムが最新のパッチに更新されていることを確認してから、システムアーキテクチャに一致するVSコードインストールパッケージをダウンロードして、プロンプトとしてインストールします。インストール後、一部の拡張機能はWindows 8と互換性があり、代替拡張機能を探すか、仮想マシンで新しいWindowsシステムを使用する必要があることに注意してください。必要な拡張機能をインストールして、適切に動作するかどうかを確認します。 Windows 8ではVSコードは実行可能ですが、開発エクスペリエンスとセキュリティを向上させるために、新しいWindowsシステムにアップグレードすることをお勧めします。
 PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPは1994年に発信され、Rasmuslerdorfによって開発されました。もともとはウェブサイトの訪問者を追跡するために使用され、サーバー側のスクリプト言語に徐々に進化し、Web開発で広く使用されていました。 Pythonは、1980年代後半にGuidovan Rossumによって開発され、1991年に最初にリリースされました。コードの読みやすさとシンプルさを強調し、科学的コンピューティング、データ分析、その他の分野に適しています。
 ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
VSコードでは、次の手順を通じて端末でプログラムを実行できます。コードを準備し、統合端子を開き、コードディレクトリが端末作業ディレクトリと一致していることを確認します。プログラミング言語(pythonのpython your_file_name.pyなど)に従って実行コマンドを選択して、それが正常に実行されるかどうかを確認し、エラーを解決します。デバッガーを使用して、デバッグ効率を向上させます。
