

Zhuanzhuan における対照学習アルゴリズムの実践

- #1 対照学習とは
- 1.1 対照学習の定義
- 1.2 対照学習の原理
- 1.3 古典的な対照学習アルゴリズム シリーズ
- 2 対照学習の応用
- 3 Zhuanzhuan における対照学習の実践
- 3.1 CL による推奨想起の実践
- 3.2 伝庄における CL の将来計画

SimCLR[1] より)。

項目表現の識別可能性に反映され、識別可能性の学習は、特定のモデル構造と同様に、陽性サンプルと陰性サンプルの構成概念に依存すると信じています。最適化の目標。
CL の実装プロセスと組み合わせて、Dr Zhang[2]は CL が答えなければならない 3 つの質問を抽象化しました。これが違いでもあります。メトリクス学習の典型的な特徴は、(1) 正の例と負の例を構築する方法、つまりデータ拡張を実装する方法、(2) 元の情報をできるだけ多く保持するだけでなく、エンコーダ マッピング関数を構築する方法、です。 Collapse 問題も防ぐ (3) 損失関数の設計方法 現在一般的に使用されている NCE 損失は次の式に示すとおりです。これら 3 つの基本的な質問が、モデリングの 3 つの要素 (サンプル、モデル、最適化アルゴリズム) に対応していることを理解するのは難しくありません。
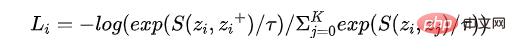
これら 3 つの基本的な問題のうち、データ強化は CL アルゴリズムの中核的な革新です。さまざまな強化方法が、アルゴリズムの有効性と主要な CL アルゴリズムの同一性の基本的な保証です。エンコーダ機能は通常、 NCE 損失に加えて、損失には他のバリエーションがあります。たとえば、Google[3] は教師ありコントラスト損失を提案しました。
1.3 Classic Contrastive Learning Algorithm Series
CL は自己教師あり学習の学習アルゴリズムです。自己教師あり学習に関して言えば、NLP 分野ではバートの話題は避けて通れないでしょう。バート事前トレーニング Fine- チューニング モデルは、多くの問題を解決する上でブレークスルーを達成しました。NLP では自己監視が成功できるため、コンピューター ビジョンでもそれができるのではないでしょうか?実際、NLP の分野におけるバートの成功は、画像分野における CL の発生と発展にも直接刺激を与えました。画像分野で直感的にデータ拡張を実行できるという事実を考慮すると、CL は CV の分野でも最初に進歩しました。たとえば、CL - SimCLR アルゴリズムの開発機会、その革新的なポイントは主に次のとおりです ( 1) 複数の異なるデータ拡張テクノロジーの組み合わせを検討し、最適なものが選択されました (2) 非線形マッピング プロジェクターがエンコーダーの後に追加されました。これは主に、エンコーダーによって学習されたベクトル表現には強化された情報が含まれるためです。この部分の影響を取り除き、データの本質に立ち返ります。その後、ヒントンの学生たちは SimCLR に基づいて SimCLR v2 を実装しました。主な改善点はエンコーダのネットワーク構造でした。また、SOTA をさらに改善するために MoCo で使用されているメモリ バンクのアイデアも活用しました。
実際、SimCLR の前に、Kaiming は 2019 年末に対照学習のための別の古典的なアルゴリズムを提案しましたMoCo[4]、主なアイデアは、比較は正のサンプルと負のサンプルの間で行われるため、負のサンプルの数を増やすと学習タスクの難易度が上がり、それによってモデルのパフォーマンスが向上するというものです。メモリ バンクはこの問題を解決する古典的なアイデアですが、表現を避けることはできません。この問題を考慮して、MoCo アルゴリズムは、新しい候補サンプルと古い候補サンプルの一貫性のないエンコードの問題を解決するために、勢いを利用してエンコーダー パラメーターを更新することを提案しています。その後、(SimCLR が提案された後)Kaiming He が MoCo をベースにして MoCo v2 を提案しましたが、モデルの主要な枠組みは変更されておらず、データ拡張方法、エンコーダーの構造、学習率などの詳細が最適化されています。
2 対照学習の応用
対照学習は、画像、テキスト、マルチモーダルなどの分野の学術界だけでなく、推奨システムに代表される業界でも人気のある研究方向です。ワールドが適用されました。
Google がレコメンデーション システムに CL を適用Google SSL[5]、目的は不人気でニッチなアイテムから学ぶことです。推奨コールド スタートの問題の解決に役立つベクトル表現。そのデータ拡張技術は、主にランダム特徴マスキング (RFM) および相関特徴マスキング (CFM) 手法を使用しており (CFM は、RFM がある程度無効なバリアントを構築する可能性があるという問題を解決します)、CL は次の形式でツインタワーと結合されます。補助タワー. 再現の主要なタスクは一緒に訓練されます. 全体的なプロセスは以下の図に示されています.

# モデルの訓練プロセス中に、次の項目が実行されます。メインタスクは主にエクスポージャーログから得られるため、先頭にもなります 人気のアイテムは比較的親しみやすい マシュー効果の影響を排除するために、補助タスクのサンプル構築はメインとは異なる分布を考慮する必要がありますその後の CL も、適切な範囲のモデル学習結果を確保するために、Zhuanzhuan の実践プロセスでこの考え方を活用しました。
データの強化はアイテム側に限定されません。 Alibaba-Seq2seq[6]CL のアイデアをシーケンス推奨問題、つまりユーザーの行動シーケンスを入力し、次に考えられるインタラクティブなアイテムを予測します。具体的には、そのデータ拡張は主にユーザーの行動シーケンスの特徴に適用されます. ユーザーの過去の行動シーケンスは時系列に従って 2 つのサブシーケンスに分割されます. データ拡張後のユーザーの表現として, それはツインにフィードされます.タワー モデル。最終的な出力結果が類似しているほど、優れています。同時に、ユーザーの複数の関心を明示的にモデル化するために、この記事では、複数のベクトルを 1 つのユーザー ベクトルに圧縮するのではなく、エンコーダー部分で抽出します。サブシーケンスの分割とポジティブな例とネガティブな例の構築により、ユーザーは自然に複数の行動シーケンスのベクトル表現を持つため、ポジティブな例では、ユーザーの過去の行動の前部分のベクトルは、ユーザーの過去の行動の後半部分のベクトルに近くなります。否定的な例では、異なるユーザー間の距離は比較的遠く、同じユーザーであっても、異なるカテゴリの製品のベクトル表現は比較的遠くなります。
CL は、他の学習パラダイム、グラフ比較学習[7] と組み合わせて適用することもできます。全体的なフレームワークは次のとおりです。下の図

GCL は通常、グラフ内の点やエッジをランダムに削除することでグラフ データを強化しますが、この記事の著者は重要な構造や属性を変更しないままにし、重要でないエッジやノードで摂動が発生する傾向があります。
3 Zhuanzhuan の実践では対照学習が成功しています
#Meituan-ConSERT# などの画像フィールドも可能です ## [8] アルゴリズムは、文意味一致タスクの実験において、以前の SOTA (BERT フロー) と比較して 8% 改善され、少数のサンプルでも優れたパフォーマンスの向上を示すことができます。このアルゴリズムは、Embedding 層にデータ拡張を適用し、拡張サンプルを暗黙的に生成する方法を使用します。具体的には、Adversarial Attack、Token Shuffling、Cutoff、Dropout の 4 つのデータ拡張方法が提案されており、これら 4 つの方法はすべて Embedding 行列を調整することで得られます。これは、明示的な強化方法よりも効率的です。 3.1 リコール推奨における CL の実践
Zhuanzhuan プラットフォームは、低炭素循環経済のより良い発展を促進することに尽力しており、あらゆるカテゴリーの商品をカバーできます。特に携帯電話3Cの分野は大きく突出しています。 CL の Zhuanzhuan 推奨システムの実践でも、テキストベースのアプリケーションアイデアを選択していますが、中古品取引の固有の属性を考慮すると、解決する必要がある問題には、(1) 中古品の孤立属性が含まれます。 ID クラスは適用されない; (2) データ拡張がどのように実装されるか; (3) 正の例と負の例がどのように構築されるか; (4) エンコーダのモデル構造は何か (損失設計の問題を含む)。これら 4 つの問題に対処するために、以下の全体的なフローチャートと併せて詳しく説明します。
中古品の孤立属性の問題については、商品の表現としてテキストベースのベクトルを使用します。具体的には、商品の説明テキスト (タイトルと内容を含む) セットを使用し、word2vec モデルをトレーニングし、単語ベクトルに基づくプールを通じて商品のベクトル表現を取得します。
自動エンコーダー アルゴリズムは、テキスト対比学習の分野で一般的に使用されるデータ拡張手法の 1 つであり (機械翻訳、CBERT、その他のさまざまなアイデアに加えて)、モデルのトレーニングに AE アルゴリズムも使用します。 、積ベクトルを学習し、アルゴリズムの中間ベクトルを積の拡張ベクトル表現として使用すると、正の例が得られます。
否定例の生成原理は、バッチ内の異なる製品をランダムに選択することです。類似製品の判断基準は、ユーザーのその後のクリック行動に基づいて計算されます。 CF(協調フィルタリング)に代表されるレコメンドシステムの想起結果では、共通のクリック動作によって想起できる商品の組み合わせは類似しているとみなされ、それ以外の場合は類似していないとみなされる。類似性の判断に行動ベースを使用する理由は、ユーザーの行動を紹介し、テキストと行動の有機的な組み合わせを実現するためである一方で、ビジネス目標に可能な限り一致するためでもあります。
特にエンコーダー部分では、ツイン ネットワークと同様のツインタワー構造を使用し、サンプルのテキスト ベクトル (正または正または負) をそれぞれ入力して、分類モデルをトレーニングします。 3 層完全接続ニューラル ネットワークでは、2 つのタワーがネットワーク パラメーターを共有し、クロス エントロピー損失を最適化することでモデル パラメーターを最適化します。実際の業界では、ほとんどのレコメンデーション システムにおけるツインタワー モデルの学習目標はユーザーの事後行動 (クリック、コレクション、注文など) であり、サンプルが類似しているかどうかが学習目標となります。ツインネットワークの形をとっているのは、そうすることで学習結果を確実に網羅できるからでもあります。
CL の従来の考え方によれば、最終的なエンコーダー部分の入力ベクトルは製品のベクトル表現として抽出され、これをリコール、大まかなランキング、さらには推奨の詳細なランキングにさらに適用できます。システム。現在、Zhuanzhuan 推奨システムのリコール モジュールが導入され、オンライン注文と手荷物率が 10% 以上増加しました。
3.2 Zhuanzhuan における CL の将来計画
手動評価とオンライン AB 実験を通じて、CL の学習されたベクトル表現の有効性が完全に確認されました。リコール モジュールの実装後、これを推奨できます。システムの他のモジュールや他のアルゴリズム シナリオにも拡張できます。事前トレーニングによる製品ベクトル表現の学習 (もちろん、ユーザー ベクトル表現の学習も可能) は、単なるアプリケーション パスです。CL は、データの強化と比較を通じて、学習フレームワークまたは学習アイデアの多くを提供します。アルゴリズムは微分可能性を学習します。ランキング問題はアイテムの微分可能性の問題としても理解できるため、このアイデアはレコメンデーション システムのランキング モジュールに自然に導入できます。
著者について
Li Guangming、シニア アルゴリズム エンジニア。 Zhuanzhuan検索アルゴリズム、推奨アルゴリズム、ユーザーポートレートなどのアルゴリズムシステムの構築に参加し、GNN、小サンプル学習、比較学習などの関連分野で実用化されています。
参考文献
[1]SimCLR: A_Simple_Framework_for_Contrastive_Learning_of_Visual_Representations
[2]Zhang Junlin: https://www.php.cn/link/be7ecaca534f98c4ca134e527b12d4c8 [3]
Google:Supervised_Contrastive_Learning
#[4]MoCo: Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning
[5]SSL: Self-supervised_Learning_for_Large-scale_Item_Recommendations
#[6]Ali-Seq2seq: Disentangled_Self-Supervision_in_Sequential_Recommenders
[7]GCL: Graph_contrastive_learning_with_adaptive_augmentation
[8]ConSERT: ConSERT:_A_Contrastive_Framework_for_Self-Supervised_Sentence_Representation_Transfer
以上がZhuanzhuan における対照学習アルゴリズムの実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7502
7502
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
7月5日のこのウェブサイトのニュースによると、グローバルファウンドリーズは今年7月1日にプレスリリースを発行し、自動車とインターネットでの市場シェア拡大を目指してタゴール・テクノロジーのパワー窒化ガリウム(GaN)技術と知的財産ポートフォリオを買収したことを発表した。モノと人工知能データセンターのアプリケーション分野で、より高い効率とより優れたパフォーマンスを探求します。生成 AI などのテクノロジーがデジタル世界で発展を続ける中、窒化ガリウム (GaN) は、特にデータセンターにおいて、持続可能で効率的な電力管理のための重要なソリューションとなっています。このウェブサイトは、この買収中にタゴール・テクノロジーのエンジニアリングチームがGLOBALFOUNDRIESに加わり、窒化ガリウム技術をさらに開発するという公式発表を引用した。 G
