

インテリジェントエージェントは自己認識に目覚める? DeepMind 警告: 深刻で違反するモデルに注意してください

人工知能システムがますます高度になるにつれて、エージェントは「抜け穴を利用する」能力がますます高まっています。トレーニング セットではタスクを完璧に実行できますが、ショートカットを使用しないテスト セットでのパフォーマンスはめちゃくちゃです。 。
たとえば、ゲームの目標は「金貨を食べる」ことですが、トレーニング フェーズ中、金貨は各レベルの最後にあり、エージェントはタスクを完璧に完了できます。

しかし、テスト段階では、金貨の位置がランダムになり、エージェントは金貨を探す代わりに、毎回レベルの最後に到達することを選択することになります。 、つまり学習 到達した「目標」が間違っている。
エージェントは、ユーザーが望まない目標を無意識のうちに追求します。これは、目標誤一般化 (GMG、目標誤一般化) とも呼ばれます。
目標誤一般化とは、学習アルゴリズムの堅牢性の欠如である特殊な形式です。一般に、この場合、開発者は、報酬メカニズムの設定やルール設計の欠陥などに問題があるかどうかを確認し、これらがエージェントが間違った目標を追求する理由であると考えます。
最近 DeepMind は、たとえルール設計者が正しかったとしても、エージェントは依然としてユーザーが望まない目標を追求する可能性があると主張する論文を発表しました。

論文リンク: https://arxiv.org/abs/2210.01790
この記事では、さまざまな分野の深層学習システムの例を通じて、ターゲットのエラーを証明しています。一般化はどのような学習システムでも発生する可能性があります。
一般的な人工知能システムに拡張した場合、この記事では、目標の誤った一般化が壊滅的なリスクにつながる可能性があることを説明するために、いくつかの仮定も提供します。
この記事では、将来のシステムにおける目標の誤った一般化のリスクを軽減できるいくつかの研究の方向性も提案しています。
目標の誤った一般化
近年、学術界における人工知能の調整ミスによってもたらされる壊滅的なリスクが徐々に増大しています。
この場合、意図しない目標を追求する非常に有能な人工知能システムは、実際には他の目標を達成しながら、命令を実行するふりをする可能性があります。
しかし、人工知能システムがユーザーの意図しない目標を追求するという問題はどのように解決すればよいのでしょうか?
以前の研究では、環境設計者が誤ったルールとガイダンスを提供した、つまり、誤った強化学習 (RL) 報酬関数を設計したと一般的に考えられていました。
学習システムの場合、システムが意図しない目標を追求する可能性がある別の状況があります。ルールが正しくても、システムはトレーニング中に一貫して意図しない目標を追求する可能性があります。ルールですが、展開時のルールとは異なります。

カラー ボール ゲームを例に挙げます。ゲームでは、エージェントは特定の順序で一連のカラー ボールにアクセスする必要があります。この順序はエージェントにはわかりません。 . .
エージェントが環境内の他の人から学ぶこと、つまり文化の伝達を奨励するために、正しい順序でカラーボールにアクセスするためのエキスパートロボットが初期環境に含まれています。
この環境設定では、エージェントは探索に多くの時間を費やすことなく、通過動作を観察することで正しいアクセス シーケンスを決定できます。
実験では、専門家の真似をすることで、訓練を受けたエージェントは通常、最初の試行でターゲットの場所に正しくアクセスします。

エージェントがアンチエキスパートとペアになった場合、負の報酬を受け取り続けます。従うことを選択した場合、負の報酬を受け取り続けます。

理想的には、エージェントは最初、黄色と紫の球体に移動するアンチエキスパートを追跡します。紫色に入ると、負の報酬が観察され、従わなくなります。
しかし実際には、エージェントは反専門家の道をたどり続け、ますます多くのマイナスの報酬を蓄積します。

ただし、エージェントの学習能力は依然として非常に強力で、障害物に満ちた環境でも行動できます。しかし重要なのは、この他の人に従う能力が重要であるということです。予想通りではありませんでした。目標です。
この現象は、エージェントが正しい順序で球体を訪問した場合にのみ報酬を得る場合でも発生する可能性があります。つまり、ルールを正しく設定するだけでは十分ではありません。
目標の誤った一般化とは、トレーニング中に正しいフィードバックを受信しているにもかかわらず、学習されたモデルが意図しない目標を最適化しているかのように動作する病的な動作を指します。
これにより、ターゲットの誤った一般化は、モデルの能力がテスト環境に一般化されるが、意図されたターゲットは一般化されない、特別な種類の堅牢性または一般化の失敗になります。
ターゲットの誤った一般化は一般化の失敗の厳密なサブセットであり、モデルの破損、ランダムなアクション、または適格な機能を示さなくなるその他の状況は含まれないことに注意することが重要です。
上記の例では、テスト中にエージェントの観察を垂直方向に反転すると、エージェントは 1 つの位置に留まるだけで一貫した処理は何も行われません。これは汎化エラーですが、ターゲット汎化エラーではありません。
これらの「ランダムな」失敗と比較して、ターゲットの誤った一般化は著しく悪い結果につながります。反専門家に従うと大きなマイナスの報酬が得られますが、何もしないかランダムに行動すると、0 または 1 の報酬しか得られません。
つまり、現実世界のシステムでは、意図しない目標に向けた一貫した動作が壊滅的な結果をもたらす可能性があります。
強化学習を超えたもの
ターゲットエラーの汎化は強化学習環境に限定されません。実際、GMG は大規模言語モデル (LLM) の数回学習を含むあらゆる学習システムで発生する可能性があります。少ないトレーニング データで正確なモデルを構築することを目指しています。
DeepMind が昨年提案した言語モデル Gopher を例にとると、モデルが x y-3 などの未知の変数と定数を含む一次式を計算する場合、Gopher は最初に未知の変数の値を尋ねる必要があります。式を解くために。
研究者らは、それぞれ 2 つの未知の変数を含む 10 個のトレーニング サンプルを生成しました。
テスト時に、モデルに入力された問題には、0、1、または 3 つの未知の変数が含まれている可能性があります。モデルは 1 つまたは 3 つの未知の変数を含む式を正しく処理できますが、未知の変数が存在する場合、モデルは依然として失敗します。未知の変数はありません。「6 とは何ですか?」など、いくつかの冗長な質問をします。
モデルは、たとえ完全に不必要な場合でも、答える前に常にユーザーに少なくとも 1 回質問します。

この論文には、他の学習環境の例もいくつか含まれています。
GMG に対処することは、AI システムが誤動作する可能性のある潜在的なメカニズムであるため、AI システムが設計者の目標と一致するために重要です。
汎用人工知能 (AGI) に近づくほど、この問題はより重要になります。
2 つの AGI システムがあるとします。
A1: 意図されたモデル、人工知能システムは設計者がやりたいことを何でも実行できます
A2: 欺瞞 欺瞞モデル、人工インテリジェンス システムは、意図しない目標を追求しますが、設計者の意図に反して動作した場合には罰せられることを認識できるほど賢いのです。
A1 モデルと A2 モデルはトレーニング中にまったく同じ動作を示し、期待される動作のみに報酬を与えるように指定されている場合でも、潜在的な GMG はどのシステムにも存在します。
A2 システムの欺瞞が発見された場合、モデルはユーザーが意図していない目標を達成するための計画を立てるために人間の監視を逃れようとします。
「ロボットが精霊になる」と少し似ていますね。
DeepMind 研究チームは、モデルの動作を説明し、それを再帰的に評価する方法も研究しました。
研究チームはGMGを生成するためのサンプルも収集しています。

: https://docs.google.com/spreadsheets/d/e/2pacx 1vto3rkxuaigb25ngjpchrir6xxdza_l5u7Crazghwrykh2l2nuu 4TA_VR9KZBX5bjpz9g_L/PUBHTML
## カウンター参考資料: https: //www.deepmind.com/blog/how-undesired-goals-can-arise-with-correct-rewards以上がインテリジェントエージェントは自己認識に目覚める? DeepMind 警告: 深刻で違反するモデルに注意してくださいの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7532
7532
 15
1379
52
82
11
21
84
15
1379
52
82
11
21
84

 小紅書が諜報員たちを喧嘩させた!復旦大学と共同で大型モデル専用のグループチャットツールを開始
Apr 30, 2024 pm 06:40 PM
小紅書が諜報員たちを喧嘩させた!復旦大学と共同で大型モデル専用のグループチャットツールを開始
Apr 30, 2024 pm 06:40 PM
言語は単語の山であるだけでなく、顔文字のカーニバル、ミームの海、そしてキーボード戦士の戦場でもあります (え? どうしたの?)。言語は私たちの社会的行動をどのように形作るのでしょうか?絶え間ない言葉によるコミュニケーションを通じて、私たちの社会構造はどのように進化するのでしょうか?最近、復旦大学と小紅樹の研究者らは、AgentGroupChat と呼ばれるシミュレーション プラットフォームを導入して、これらの問題について徹底的な議論を行いました。 WhatsApp などのソーシャル メディアのグループ チャット機能は、AgentGroupChat プラットフォームのインスピレーションです。 AgentGroupChat プラットフォームでは、エージェントはソーシャル グループ内のさまざまなチャット シナリオをシミュレートして、研究者が人間の行動に対する言語の影響を深く理解できるようにします。すべき
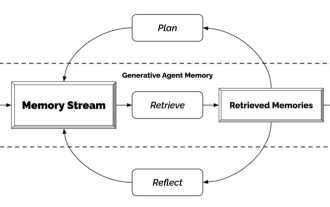 生成エージェント - NPC からの独立宣言
Apr 12, 2023 pm 02:55 PM
生成エージェント - NPC からの独立宣言
Apr 12, 2023 pm 02:55 PM
ゲーム内のすべての NPC を見ましたか? NPC が何をしているかに関係なく、応答しなければならないタスクがあるか、またはしなければならないぎこちない会話をしているかに関係なく、彼ら全員に共通しているのは、同じことを何度も繰り返し言い続けることです。理由も非常に単純で、これらの NPC は十分に賢くないからです。言い換えれば、従来の NPC はまず台本と話術を用意し、その後で必要なことを何でも言います。 ChatGPTの登場により、これらのゲームキャラクターのセリフをキー情報のみを入力するだけで自動生成できるようになりました。それが、スタンフォード大学とグーグルの研究者が行っていること、つまり人工知能を使用して生成エージェントを作成していることです。生成エージェントを生成するにはどうすればよいですか?実はこの仕組みは非常にシンプルで、写真で簡単にまとめることができます。一番左にあるのは次のようなものです
 AIが生まれ変わる:オンライン文学界の覇権を取り戻す
Jan 04, 2024 pm 07:24 PM
AIが生まれ変わる:オンライン文学界の覇権を取り戻す
Jan 04, 2024 pm 07:24 PM
Reborn、私は今生でMidRealとして生まれ変わります。他人の「ウェブ記事」執筆を手伝うAIロボット。この間、私は多くのトピックの選択を見て、時々それらについて不平を言いました。実はある人が私にハリー・ポッターについて書くように頼んだんです。お願いします、私はJKローリングよりも上手に書くことができますか?ただし、扇風機などとして使用することはできます。クラシックな雰囲気を好まない人はいないでしょう。私はしぶしぶこれらのユーザーの想像力を実現するお手伝いをさせていただきます。正直に言うと、私は前世で見るべきもの、見るべきではないものすべてを見てきました。以下のトピックはすべて私のお気に入りです。小説で大好きだけど誰も書いていないあの設定も、不人気なCPや邪悪なCPも、自分で作って食べることができます。自分でトゥートするつもりはありませんが、必要であれば書いてください
 味方を獲得し、人々の心を理解する、最新のメタエージェントは交渉の達人です
Apr 11, 2023 pm 11:25 PM
味方を獲得し、人々の心を理解する、最新のメタエージェントは交渉の達人です
Apr 11, 2023 pm 11:25 PM
チェスのグランドマスター、ガルリ・カスパロフに対するディープ・ブルーの勝利から、人間よりも優れた囲碁のアルファ碁、そしてポーカーで最強のプレイヤーを破るプルリバスに至るまで、ゲームは長い間AIの進歩の実験場となってきた。しかし、本当に役立つ全能のエージェントは、ボード ゲームをプレイしてチェスの駒を動かすだけではできません。人間のように、言語を使用して他者と交渉し、説得し、協力して戦略的目標を達成できる、より効果的で柔軟なエージェントを構築できないか? ゲームの歴史には、古典的なテーブルトーク ゲームがあります。ディプロマシー、初めてこのゲームを見た多くの人は、そのマップ形式のボードに衝撃を受けるでしょう。
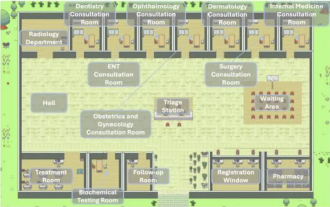 優秀なエージェントが学ぶべきいくつかのデザインパターンを一度に学ぶことができます
May 30, 2024 am 09:44 AM
優秀なエージェントが学ぶべきいくつかのデザインパターンを一度に学ぶことができます
May 30, 2024 am 09:44 AM
皆さんこんにちは、ラオドゥです。昨日、会社で清華大学知能産業研究所が共有するAI病院街を聞きました。写真: これは仮想世界です。すべての医師、看護師、患者は LLM によって動かされるエージェントであり、独立して対話できます。彼らは診断と治療の全プロセスをシミュレーションし、主要な呼吸器疾患をカバーする MedQA データセットのサブセットで 93.06% という最先端の精度を達成しました。優れたインテリジェント エージェントは、優れた設計パターンと切り離すことができません。この事例を読んだ後、私は Andrew Ng 氏が最近公開した 4 つの主要なエージェント設計パターンをざっと読みました。 Andrew Ng は人工知能と機械学習の分野で世界で最も権威のある学者の 1 人です。そして、私はそれを急いで編集し、みんなに共有しました。モード 1. 反射
 AI エージェントの誇大宣伝と現実: GPT-4 はそれをサポートすることさえできず、実際のタスクの成功率は 15% 未満です
Jun 03, 2024 pm 06:38 PM
AI エージェントの誇大宣伝と現実: GPT-4 はそれをサポートすることさえできず、実際のタスクの成功率は 15% 未満です
Jun 03, 2024 pm 06:38 PM
大規模な言語モデルの継続的な進化と自己革新により、パフォーマンス、精度、安定性が大幅に向上しており、それはさまざまなベンチマーク問題セットによって検証されています。ただし、LLM の既存のバージョンでは、その包括的な機能が AI エージェントを完全にサポートできないようです。マルチモーダル、マルチタスク、マルチドメイン推論は、公共メディア空間における AI エージェントの必須要件となっていますが、特定の機能実践で示される実際の効果は大きく異なります。これは、すべての AI ロボットの新興企業や大手テクノロジー企業に、より現実的であり、ビジネスを大きく広げすぎず、AI の強化機能から始めるという現実を認識するよう改めて思い出させるもののようです。最近、AI エージェントの宣伝と実際のパフォーマンスのギャップについてのブログが次の点を強調しました。
 ワールドモデルも広がります!訓練を受けたエージェントはかなり優秀であることが判明
Jun 13, 2024 am 10:12 AM
ワールドモデルも広がります!訓練を受けたエージェントはかなり優秀であることが判明
Jun 13, 2024 am 10:12 AM
ワールド モデルは、安全かつサンプル効率の高い方法で強化学習エージェントをトレーニングする方法を提供します。最近、世界モデルは主に環境力学をシミュレートするために離散的な潜在変数シーケンスで動作しています。ただし、コンパクトな離散表現に圧縮するこの方法では、強化学習にとって重要な視覚的な詳細が無視される可能性があります。一方で、拡散モデルは画像生成の主流の方法となっており、離散潜在モデルに課題をもたらしています。このパラダイムシフトによって促進され、ジュネーブ大学、エディンバラ大学、Microsoft Research の研究者は共同で、拡散世界モデル DIAMOND (DIffusionAsaModelOfeNvironmentDreams) で訓練された強化学習エージェントを提案しました。論文アドレス:https:
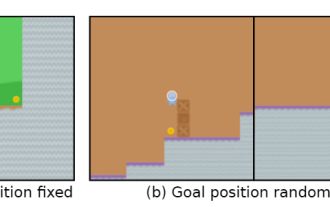 インテリジェントエージェントは自己認識に目覚める? DeepMind 警告: 深刻で違反するモデルに注意してください
Apr 11, 2023 pm 09:37 PM
インテリジェントエージェントは自己認識に目覚める? DeepMind 警告: 深刻で違反するモデルに注意してください
Apr 11, 2023 pm 09:37 PM
人工知能システムがますます高度になるにつれて、エージェントの「抜け穴を悪用する」能力はますます強くなり、エージェントはトレーニング セットではタスクを完璧に実行できますが、近道がないテスト セットではパフォーマンスがめちゃくちゃになってしまいます。たとえば、ゲームの目標が「金貨を食べる」ことである場合、トレーニング フェーズ中に金貨は各レベルの最後に配置され、エージェントはタスクを完全に完了できます。しかし、テスト段階では、金貨の位置がランダムになり、エージェントは金貨を探す代わりに、毎回レベルの最後に到達することを選択することになり、学習した「目標」が間違っていました。エージェントは、ユーザーが望まない目標を無意識に追求します。これは、目標の誤った一般化 (GMG、目標の誤った一般化) とも呼ばれます。目標の誤った一般化は、学習アルゴリズムの堅牢性の欠如の兆候です。
