

超完成度! Python で構成ファイルを記述する一般的な方法


構成ファイルを記述する理由
この修正ファイルは、settings.py や config.py などの .py ファイルに直接書き込むことができます。同じプロジェクト内にある場合は、インポートを通じてその一部を直接インポートできますが、他の非 Python プラットフォームで構成ファイルを共有する必要がある場合、単一の .py を記述するのは良い選択ではありません。現時点では、これらの固定部分を保存するために共通の構成ファイルの種類を選択する必要があります。現在、一般的に使用されている一般的な構成ファイル形式のタイプには、主に ini、json、toml、yaml、xml などが含まれます。これらのタイプの構成ファイルは、標準ライブラリまたはサードパーティ ライブラリを通じて解析できます。
ini
ini とは Initialize の意味で、初期の頃は Windows 上の設定ファイルの保存形式でした。 ini ファイルの記述方法は理解しやすく、比較的単純なことが多く、通常は次のようなセクション、キー、値で構成されます:
[localdb] host = 127.0.0.1 user = root password = 123456 port = 3306 database = mysql
Python 独自の組み込み configparser 標準ライブラリを直接使用できます。 ini ファイルを解析するために使用します。たとえば、上記のコンテンツを db.ini という名前のファイルに保存し、次に read() メソッドを使用して解析および読み取りを行い、最後に items() メソッドを使用して指定されたノードの下にあるすべてのキーと値のペアを取得します。
>>> from configparser import ConfigParser
>>> cfg = ConfigParser()
>>> cfg.read("/Users/Bobot/db.ini")
['/Users/Bobot/db.ini']
>>> cfg.items("localdb")
[('host', '127.0.0.1'), ('user', 'root'), ('password', '123456'), ('port', '3306'), ('database', 'mysql')]configparser はデフォルトで値を文字列の形式で提示することに注意してください。そのため、db.ini ファイルに引用符を追加せず、上記のリテラルを直接記述します。
キーと値のペアを取得した後、実際にそれを辞書に直接変換し、コードを単純にするためにパラメーターを解凍しました。
#!pip install pymysql
import pymysql
from configparser import ConfigParser
cfg = ConfigParser()
cfg.read("/Users/Bobot/db.ini")
db_cfg = dict(cfg.items("localdb"))
con = pymysql.connect(**db_cfg)json
json形式は私たちにとって一般的なファイル形式と言え、インターネット上でよく使われるデータ交換形式でもあります。さらに、json は設定ファイルの一種である場合もあります。
たとえば、npm (Python の pip に似た JavaScript パッケージ管理ツール) と、広く使用されている Microsoft 製の VSCode エディターはすべて、json を使用して構成パラメーターを記述します。
configparser と同様に、Python にも組み込みの json 標準ライブラリがあり、load() メソッドとloads() メソッドを通じてファイルと文字列の json コンテンツをインポートできます。
{
"localdb":{
"host": "127.0.0.1",
"user": "root",
"password": "123456",
"port": 3306,
"database": "mysql"
}
}上記の内容を db.json として保存し、読み取って解析します。json ライブラリが json ファイルを読み込むのは比較的シンプルで簡単で、Python 辞書オブジェクトに解析するのも簡単です。
>>> import json
>>> from pprint import pprint
>>>
>>> with open('/Users/Bobot/db.json') as j:
... cfg = json.load(j)['localdb']
...
>>> pprint(cfg)
{'database': 'mysql',
'host': '127.0.0.1',
'password': '123456',
'port': 3306,
'user': 'root'}json ファイル構成を使用する欠点は、構文標準が厳しく制限されていることです。批判の 1 つは、json タイプの他のスーパーセットが代替として使用されない限り、コメントを書き込むことができないことです (コメントは可能です) VSCode の json パラメータ設定ファイルに書き込むことも代替案の 1 つです); 同時に、ネストが深すぎるという問題があり、簡単にエラーが発生する可能性があるため、長くて複雑なパラメータ設定情報を書き込むのには使用しないでください。
toml
toml 形式 (または tml 形式) は、Github の共同創設者 Tom Preston-Werner によって提案された構成ファイル形式です。 Wikipedia によると、toml は 7 年前の 2013 年 7 月に最初に提案されました。また、いくつかの点で後で説明する yaml ファイルに似ていますが、yaml の仕様を知っていれば、仕様が数十ページにも及ぶ場合 (そうです、それは本当に数十ページあります...)、実際にはそのような複雑な設定ファイルを書きたくないかもしれないので、toml 形式が良い選択です。
toml の形式はおおよそ次のとおりです。
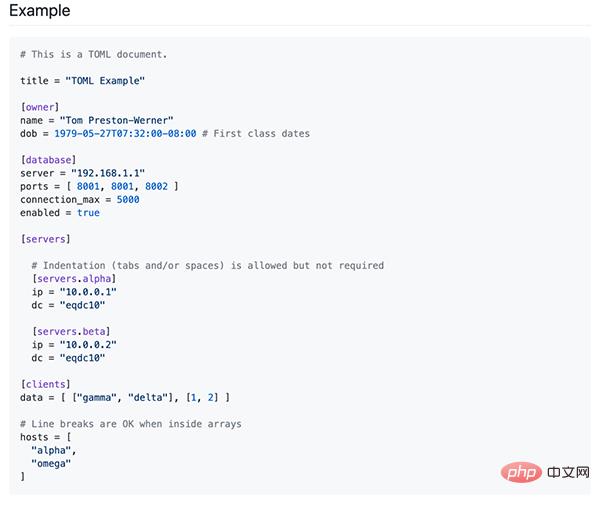
ここから、toml が前述の ini ファイルに似ていることがわかります。しかし、それはiniよりもはるかに拡張されます。
サンプル画像では、基本的な文字列に加えて、タイムスタンプ、ブール値、配列などがさらにサポートされており、そのスタイルが Python のネイティブの記述に非常に似ていることがわかります。
もちろん、toml 形式の仕様についてはここではあまり紹介しませんが、公式の仕様書は既に翻訳されている方がいますので、興味のある方は直接確認してみてください。
開発者は、Python メソッドに適合する構成ファイル タイプに対応する「ホイール」を作成しました。現在、Github では uiri/toml バージョンに最も多くの星が付いていますが、このバージョンは v0.5 バージョンの toml 仕様にのみ合格しています。 pip コマンド
pip install toml
を使用してインストールできます。このライブラリの解析方法は非常に単純で、json ライブラリの解析方法と似ています。解析にはload()またはloads()を使用し、同様に変換とエクスポートも同様に使用されます。
たとえば、次のコンテンツを config.toml に書き込みます:
[mysql] host = "127.0.0.1" user = "root" port = 3306 database = "test" [mysql.parameters] pool_size = 5 charset = "utf8" [mysql.fields] pandas_cols = [ "id", "name", "age", "date"]
その後、Toml ライブラリのload() メソッドを通じてそれを読み取ることができます:
>>> import toml
>>> import os
>>> from pprint import pprint
>>> cfg = toml.load(os.path.expanduser("~/Desktop/config.toml"))
>>> pprint(cfg)
{'mysql': {'database': 'test',
'fields': {'pandas_cols': ['id', 'name', 'age', 'date']},
'host': '127.0.0.1',
'parameters': {'charset': 'utf8', 'pool_size': 5},
'port': 3306,
'user': 'root'}}toml ファイルが間接的に辞書型に変換されていることがわかります。もちろん、これは json バージョンの記述方法 (一重引用符を二重引用符に置き換えるだけです) であり、これにより後続の呼び出しやパラメーター転送が容易になります。
yaml
yaml 格式(或 yml 格式)是目前较为流行的一种配置文件,它早在 2001 由一个名为 Clark Evans 的人提出;同时它也是目前被广泛使用的配置文件类型,典型的就是 Docker 容器里的 docker-compose.yml 配置文件,如果经常使用 Docker 进行部署的人对此不会陌生。
yaml 文件的设计从 Python、XML 等地方获取灵感,所以在使用时能很清楚地看到这些部分的影子。
在上一节 toml 内容里我曾提到,yaml 的规范内容可以说是冗长和复杂,足足有80页之多。
所以感兴趣的朋友可以再自行了解相关用法。
YAML 官方早已经提供了相应的 Python 库进行支持,即 PyYAML;当然也同样需要我们事先进行安装:
pip install pyyaml
同 json 库和 toml 库一样,通过 load() 方法来进行加载。
需要注意的是,使用 load() 方法会存在一定的安全隐患,从思科 Talos 的这份报告中我们可以看到,如果加载了未知或不信任的 yaml 文件,那么有可能会存在被攻击的风险和网络安全隐患,因为它能够直接调用相应的 Python 函数来执行为攻击者所需要的命令,比如说在 yaml 文件中写入这么一段:
# 使用Linux和macOS的朋友不要轻易尝试 !!python/object/apply:os.system ["rm -rf /"]
因此最好是使用 safe_load() 来代替 load() 方法。
这和 Python 内置的 string 标准库中 Template 类的 substitute() 模板方法一样存在着同样的安全隐患,所以使用 safe_substitute() 来替代是一样的道理。
如我们现在将之前的一些配置信息写入 config.yaml 文件中:
mysql: host: "127.0.0.1" port: 3306 user: "root" password: "123456" database: "test" parameter: pool_size: 5 charset: "utf8" fields: pandas_cols: - id - name - age - date
然后我们通过 safe_load() 方法进行解析:
>>> import os
>>> from pprint import pprint
>>>
>>> with open(os.path.expanduser("~/config.yaml"), "r") as config:
... cfg = yaml.safe_load(config)
...
>>> pprint(cfg)
{'mysql': {'database': 'test',
'fields': {'pandas_cols': ['id', 'name', 'age', 'date']},
'host': '127.0.0.1',
'parameter': {'charset': 'utf8', 'pool_size': 5},
'password': '123456',
'port': 3306,
'user': 'root'}}可以看到最后结果和前面的 toml 库的解析结果基本一致。
结尾
本文列举了一些主流且常见的配置文件类型及其 Python 的读取方法,可能有的读者会发现当中没有 xml 格式类型的内容。对于 xml 配置文件可能与 Java 系语言打交道的朋友遇见得会多一些,但 xml 文件的可读性实在是让人望而生畏;对 xml 文件不了解的朋友可以使用 Chrome 浏览器随便进入一个网站然后按下 F12 进入开发者后查看那密密麻麻的 html 元素便是 .xml 的缩影。
除了这些主流的配置文件类型之外,像一些 .cfg、.properties 等都可以作为配置文件,甚至和开头提到的那样,你单独用一个 .py 文件来书写各类配置信息作为配置文件进行导入都是没问题,只是在跨语言共享时可能会有些障碍。因此本文就不过多介绍,感兴趣的朋友可以进一步自行了解。
在本文里列举的配置文件类型其复杂性由上到下依次增加:ini
以上が超完成度! Python で構成ファイルを記述する一般的な方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7484
7484
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 mysqlはインターネットが必要ですか?
Apr 08, 2025 pm 02:18 PM
mysqlはインターネットが必要ですか?
Apr 08, 2025 pm 02:18 PM
MySQLは、基本的なデータストレージと管理のためにネットワーク接続なしで実行できます。ただし、他のシステムとのやり取り、リモートアクセス、または複製やクラスタリングなどの高度な機能を使用するには、ネットワーク接続が必要です。さらに、セキュリティ対策(ファイアウォールなど)、パフォーマンスの最適化(適切なネットワーク接続を選択)、およびデータバックアップは、インターネットに接続するために重要です。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 hadidb:pythonの軽量で水平方向にスケーラブルなデータベース
Apr 08, 2025 pm 06:12 PM
hadidb:pythonの軽量で水平方向にスケーラブルなデータベース
Apr 08, 2025 pm 06:12 PM
hadidb:軽量で高レベルのスケーラブルなPythonデータベースHadIDB(HadIDB)は、Pythonで記述された軽量データベースで、スケーラビリティが高くなっています。 PIPインストールを使用してHADIDBをインストールする:PIPINSTALLHADIDBユーザー管理CREATEユーザー:CREATEUSER()メソッド新しいユーザーを作成します。 Authentication()メソッドは、ユーザーのIDを認証します。 fromhadidb.operationimportuseruser_obj = user( "admin"、 "admin")user_obj。
 MySQLワークベンチはMariadBに接続できますか
Apr 08, 2025 pm 02:33 PM
MySQLワークベンチはMariadBに接続できますか
Apr 08, 2025 pm 02:33 PM
MySQLワークベンチは、構成が正しい場合、MariadBに接続できます。最初にコネクタタイプとして「mariadb」を選択します。接続構成では、ホスト、ポート、ユーザー、パスワード、およびデータベースを正しく設定します。接続をテストするときは、ユーザー名とパスワードが正しいかどうか、ポート番号が正しいかどうか、ファイアウォールが接続を許可するかどうか、データベースが存在するかどうか、MariadBサービスが開始されていることを確認してください。高度な使用法では、接続プーリングテクノロジーを使用してパフォーマンスを最適化します。一般的なエラーには、不十分な権限、ネットワーク接続の問題などが含まれます。エラーをデバッグするときは、エラー情報を慎重に分析し、デバッグツールを使用します。ネットワーク構成を最適化すると、パフォーマンスが向上する可能性があります
