

BERT は CNN でも使用できますか? ByteDance の研究結果が ICLR 2023 スポットライトに選出

畳み込みニューラル ネットワークで BERT を実行するにはどうすればよいですか?
ByteDance 技術チームによって提案された SparK - Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling を直接使用できます。最近、これはスポットライト フォーカス ペーパーとして含まれています。トップ人工知能カンファレンスによる :

##紙のリンク:
https://www. php.cn/link/e38e37a99f7de1f45d169efcdb288dd1
オープンソースコード:
##https://www.php.cn/link/9dfcf16f0adbc5e2a55ef02db36bac7f #これは、畳み込みニューラル ネットワーク (CNN) における BERT の最初の成功でもあります
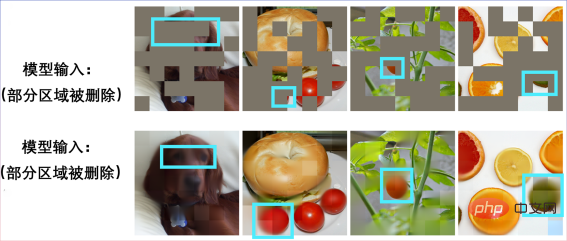
#。まずは事前トレーニングでSparKの性能を感じてみましょう。 未完成の画像を入力してください:

別の切断された写真:

#ベーグルサンドイッチであることが判明しました:

他のシーンでも画像の復元を行うことができます:

BERT と Transformer の完璧な組み合わせ

「素晴らしい行動や考えはすべて、
” BERT 事前トレーニング アルゴリズムの背後には、シンプルかつ奥深い設計があります。 BERT は「cloze」を使用します。つまり、文内のいくつかの単語をランダムに削除し、モデルに復元を学習させます。
BERT は、NLP 分野の
コア モデルである Transformerに大きく依存しています。 #####。 Transformer はもともと可変長シーケンス データ (英語の文章など) の処理に適しているため、BERT の「ランダムな削除」にも簡単に対応できます。クローズ」。
映像分野の CNN も BERT を楽しみたいと考えています。2 つの課題は何ですか?
コンピュータ ビジョンの開発の歴史を振り返ると、畳み込みニューラル ネットワーク モデルには、並進等分散などの多くの古典的なモデルのエッセンスが凝縮されています。マルチスケール構造など、CV の世界の根幹とも言える。しかし、Transformer と大きく異なるのは、CNN が本質的に、クローゼによって「くり抜かれ」、「ランダムな穴」でいっぱいのデータに適応できないため、一見したところでは BERT の事前トレーニングの恩恵を享受できないことです。
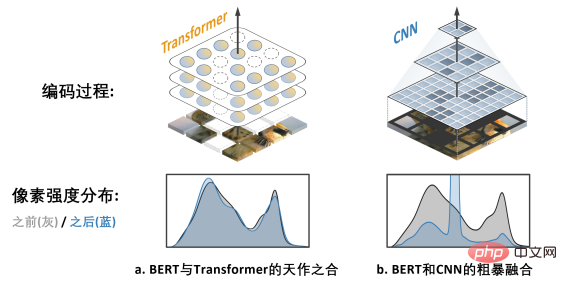
右の図 b. は、BERT モデルと CNN モデルを融合する大まかな方法を示しています。つまり、すべての空の領域を「黒く」します。この「黒いモザイク」画像が CNN に入力されると、深刻なピクセル強度分布シフトの問題が発生し、パフォーマンスの低下につながる結果が想像できます (後で検証します)。これは、CNN での BERT の適用の成功を妨げる
課題 です。 #加えて、著者チームは、NLP の分野に由来する BERT アルゴリズムには、当然のことながら「マルチスケール」の特性がないことも指摘しています。 、マルチスケールのピラミッド構造は、コンピュータービジョンの長い歴史の中で「ゴールドスタンダード」と呼ぶことができます。シングルスケール BERT と自然なマルチスケール CNN の間の競合は、
課題 2 です。 ソリューション SparK: スパースおよび階層マスク モデリング
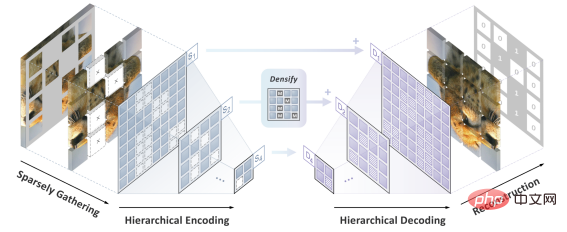 ##著者チームは、前述の 2 つの課題を解決するために SparK (スパースおよび階層マスク モデリング) を提案しました。
##著者チームは、前述の 2 つの課題を解決するために SparK (スパースおよび階層マスク モデリング) を提案しました。
まず、3次元点群データ処理にヒントを得て、著者チームはマスキング操作(くり抜き操作)後の断片化された画像をスパース点として扱うことを提案しました。雲は部分多様体スパース畳み込みを使用してエンコードされます。これにより、畳み込みネットワークはランダムに削除された画像を簡単に処理できるようになります。
第 2 に、UNet のエレガントな設計に触発されて、著者チームは水平接続を備えたエンコーダ/デコーダ モデルを自然に設計し、複数の間でマルチスケール機能をフローできるようにしました。これにより、BERT はコンピューター ビジョンのマルチスケール ゴールド スタンダードを完全に受け入れることができます。
この時点で、畳み込みネットワーク (CNN) 向けに調整されたスパースなマルチスケール マスク モデリング アルゴリズムである SparK が誕生しました。
SparK は
一般:できる構造を変更したり追加コンポーネントを導入したりすることなく、畳み込みネットワークで直接使用できます。よく知られた古典的な ResNet であっても、最近の高度なモデル ConvNeXt であっても、SparK の恩恵を直接受けられます。 ResNet から ConvNeXt へ: 3 つの主要なビジュアル タスクにおけるパフォーマンスの向上
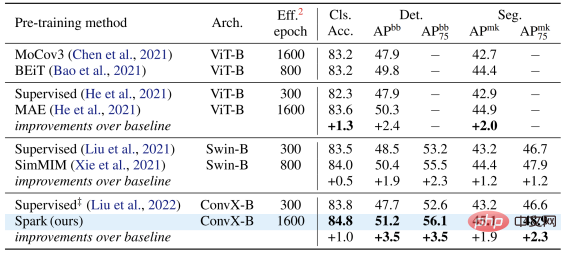
著者チームは、ResNet と ConvNeXt という 2 つの代表的な畳み込みモデル ファミリを選択し、画像分類、ターゲット検出、インスタンス セグメンテーション タスクのパフォーマンス テストを実施しました。
古典的な ResNet-50 モデルでは、SparK は唯一の生成的事前トレーニングとして機能します。最先端レベルを達成:
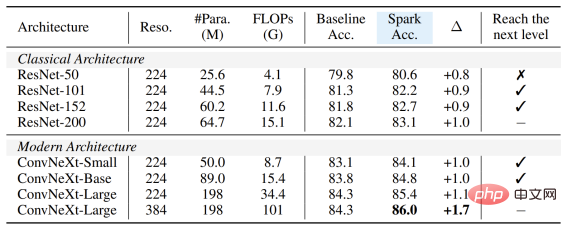
ConvNeXt モデルでは、SparK が依然として をリードしています。事前トレーニング前は、ConvNeXt と Swin-Transformer は互角でしたが、事前トレーニング後は、ConvNeXt が次の 3 つのタスクで Swin-Transformer を圧倒的に上回りました。 #小規模から大規模までの完全なモデル ファミリで SparK を検証すると、次のことがわかります。 最後に、著者チームは確認のためのアブレーション実験も設計しました。そこから次のことがわかります# #Sparse Mask 階層構造 行 3 と 4 行) は非常に重要なデザインです。一度欠落すると重大なパフォーマンスに影響します。劣化: 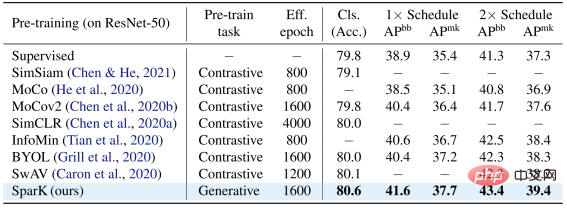
 #and
#and
以上がBERT は CNN でも使用できますか? ByteDance の研究結果が ICLR 2023 スポットライトに選出の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7643
7643
 15
1392
52
91
11
33
151
15
1392
52
91
11
33
151

 ByteDance のビデオ編集アプリ CapCut の世界的なユーザー支出が 1 億米ドルを超える
Sep 14, 2023 pm 09:41 PM
ByteDance のビデオ編集アプリ CapCut の世界的なユーザー支出が 1 億米ドルを超える
Sep 14, 2023 pm 09:41 PM
CapCut は ByteDance が所有するクリエイティブなビデオ編集ツールで、中国、米国、東南アジアに多くのユーザーがいます。このツールは Android、iOS、PC プラットフォームをサポートしており、市場調査機関 data.ai の最新レポートでは、2023 年 9 月 11 日の時点で、CapCut の iOS と Google Play に対するユーザーの総支出額が 1 億米ドルを超えていると指摘しています (このサイトの注記:現在約 72 億 8,000 万)、Splice(2022 年下半期に 1 位)を上回ることに成功し、2023 年上半期には世界で最も収益性の高いビデオ編集アプリケーションとなり、2022 年下半期と比較して 180% 増加しました。 2023 年 8 月の時点で、世界中の 4 億 9,000 万人が iPhone および Android スマートフォンを通じて CapCut を使用しています。だ
 バイトダンスモデル大規模展開実戦
Apr 12, 2023 pm 08:31 PM
バイトダンスモデル大規模展開実戦
Apr 12, 2023 pm 08:31 PM
1. 背景紹介 ByteDance では、ディープラーニングに基づくアプリケーションがあらゆるところで開花しています。エンジニアはモデルの効果に注意を払うだけでなく、オンライン サービスの一貫性とパフォーマンスにも注意を払う必要があります。初期の頃は、通常、これにはアルゴリズムの専門家とエンジニアリングの専門家が必要でしたこのモードでは、差分のトラブルシューティングや検証などのコストが比較的高くなります。 PyTorch/TensorFlow フレームワークの人気により、深層学習モデルのトレーニングとオンライン推論が統合されました。開発者は、特定のアルゴリズム ロジックに注意を払い、フレームワークの Python API を呼び出すだけでトレーニング検証プロセスを完了できます。モデルは簡単にシリアル化してエクスポートでき、推論作業は統合された高性能 C++ エンジンによって完了します。トレーニングから展開までの開発者エクスペリエンスの向上
 拡散モデルを加速し、最速の 1 ステップで SOTA レベルのイメージを生成、Byte Hyper-SD はオープンソースです
Apr 25, 2024 pm 05:25 PM
拡散モデルを加速し、最速の 1 ステップで SOTA レベルのイメージを生成、Byte Hyper-SD はオープンソースです
Apr 25, 2024 pm 05:25 PM
最近、DiffusionModel は画像生成の分野で大きな進歩を遂げ、画像生成およびビデオ生成タスクに前例のない開発機会をもたらしました。素晴らしい結果にもかかわらず、拡散モデルの推論プロセスに固有のマルチステップ反復ノイズ除去特性により、計算コストが高くなります。最近、拡散モデルの推論プロセスを高速化する一連の拡散モデル蒸留アルゴリズムが登場しました。これらの方法は、大きく 2 つのカテゴリに分類できます: i) 軌道保存蒸留、ii) 軌道再構築蒸留。ただし、これら 2 種類の方法は、効果の上限や出力領域の変更によって制限されます。これらの問題を解決するために、ByteDance 技術チームは Hyper-SD と呼ばれる軌跡セグメンテーションの一貫した方法を提案しました。
 Xiaomi Byteが力を合わせます! Xiao Ai の Doubao へのアクセスの大規模モデル: 携帯電話と SU7 にすでにインストールされています
Jun 13, 2024 pm 05:11 PM
Xiaomi Byteが力を合わせます! Xiao Ai の Doubao へのアクセスの大規模モデル: 携帯電話と SU7 にすでにインストールされています
Jun 13, 2024 pm 05:11 PM
6月13日のニュースによると、Byteの「Volcano Engine」公開アカウントによると、Xiaomiの人工知能アシスタント「Xiao Ai」はVolcano Engineとの協力に達し、両社はbeanbao大型モデルに基づいて、よりインテリジェントなAIインタラクティブ体験を実現するとのこと。 。 ByteDance が作成した大規模な豆包モデルは、毎日最大 1,200 億のテキスト トークンを効率的に処理し、3,000 万個のコンテンツを生成できると報告されています。 Xiaomi は、Doubao 大型モデルを使用して、独自モデルの学習能力と推論能力を向上させ、ユーザーのニーズをより正確に把握するだけでなく、より速い応答速度とより包括的なコンテンツ サービスを提供する新しい「Xiao Ai Classmate」を作成しました。たとえば、ユーザーが複雑な科学的概念について質問する場合、&ldq
 深センバイトダンス后海センターの総建設面積は77,400平方メートルで、主要な構造物は上棟されています
Jan 24, 2024 pm 05:27 PM
深センバイトダンス后海センターの総建設面積は77,400平方メートルで、主要な構造物は上棟されています
Jan 24, 2024 pm 05:27 PM
南山区政府のWeChat公式アカウント「イノベーション南山」によると、深センバイトダンス后海センタープロジェクトは最近重要な進展を遂げたという。中国建設第一工程局建設開発会社によると、プロジェクトの主要構造物は予定より3日早くキャップが完成したという。このニュースは、南山后海の中心エリアに新しいランドマークの建物が誕生することを意味します。深センバイトダンス后海センタープロジェクトは、南山区后海の中核エリアに位置し、深センの頭条科技有限公司の本社オフィスビルです。総建築面積は7万7,400平方メートル、高さ約150メートル、地下4階、地上32階。深センバイトダンス后海センタープロジェクトは、オフィス、エンターテイメント、ケータリングなどの機能を統合した革新的な超高層ビルになると報じられている。このプロジェクトは、深セン市がインターネット産業の統合を促進するのに役立ちます。
 NUS と Byte は業界を超えて協力し、モデルの最適化を通じて 72 倍高速なトレーニングを実現し、AAAI2023 の優秀論文を受賞しました。
May 06, 2023 pm 10:46 PM
NUS と Byte は業界を超えて協力し、モデルの最適化を通じて 72 倍高速なトレーニングを実現し、AAAI2023 の優秀論文を受賞しました。
May 06, 2023 pm 10:46 PM
このほど、人工知能のトップ国際会議AAAI2023が選考結果を発表した。シンガポール国立大学 (NUS) と ByteDance Machine Learning Team (AML) が共同で作成した CowClip 技術論文が、Distinguished Papers (Distinguished Papers) の最終候補に選ばれました。 CowClip は、モデルの精度を確保しながら、単一の GPU でモデル トレーニングの速度を 72 倍向上させることができるモデル トレーニングの最適化戦略であり、関連するコードは現在オープンソースです。論文アドレス: https://arxiv.org/abs/2204.06240 オープンソース アドレス: https://github.com/bytedance/LargeBatchCTR AAA
 PICO 4の売上は予想をはるかに下回っており、ByteDanceが次世代VRヘッドセットPICO 5をキャンセルするとのニュースが報じられている
Dec 15, 2023 am 09:34 AM
PICO 4の売上は予想をはるかに下回っており、ByteDanceが次世代VRヘッドセットPICO 5をキャンセルするとのニュースが報じられている
Dec 15, 2023 am 09:34 AM
12月13日の当サイトのニュースによると、The Informationによると、バイトダンスは現行のPICO4の売上が予想をはるかに下回っているため、PICOの新世代VRヘッドセットPICO5を廃止する準備を進めているという。今年10月のEqualOceanの記事によると、ByteDanceはPICOを段階的に閉鎖し、メタバース分野を放棄すると言われている。記事は、ByteDanceは、PICOが属するハードウェア分野は自社の専門分野ではなく、過去数年の実績が期待に応えておらず、将来にも希望が持てないと考えていると指摘し、当時の担当者はこう述べた。 「PICO事業を段階的に放棄する」という噂に対し、バイトダンスの同社は、このニュースは真実ではないと反論した。彼らは、PICOの事業は依然として正常に運営されており、同社は拡張現実に長期的に投資すると述べた。
 ファーウェイやバイトダンスなどの有名企業におけるGo言語の適用事例を分析
Mar 07, 2024 pm 03:51 PM
ファーウェイやバイトダンスなどの有名企業におけるGo言語の適用事例を分析
Mar 07, 2024 pm 03:51 PM
Go 言語は効率的で簡潔なプログラミング言語として、近年多くの有名企業で広く使用されています。この記事では、有名な 2 社である Huawei と Bytedance を例として取り上げ、Go 言語分野でのアプリケーション ケースを分析し、具体的なコード例を示します。ファーウェイ ファーウェイは、情報通信技術ソリューションの世界有数のプロバイダーとして、常に技術革新と製品の研究開発に取り組んできました。ソフトウェア開発の面でも、ファーウェイのエンジニアは積極的に新しい技術を試しており、Go言語はますます重要な選択肢の1つとなっています。 1.プロメス
