

Zuoyebang 音声技術の実践

ゲスト | Wang Qiangqiang
コンピレーション | Liu Yuyao
51CTO が主催した前回の AISummit グローバル人工知能技術カンファレンスで、Zuoyebang 音声チームの責任者である Wang Qiangqiang 氏は、基調講演「Zuoyebang Speech Technology Practice」では、Zuoyebang の音声技術実践を音声合成、音声評価、音声認識の 3 つの側面から解説し、音声認識のエンドツーエンド実装、効率的なデータについて説明します。同時シナリオでの音声発音エラーを修正し、モデルの因子微分と耐干渉機能を向上させます。
音声技術に興味のあるより多くの学生が音声技術の現在の発展傾向と最先端の技術実践を理解できるようにするために、王強強教師のスピーチの内容を次のように整理しました。インスピレーションをあなたに。
1. 音声合成
データ量の少ない音声合成
従来の音声合成技術では、人の声を完全に合成するのに 10 時間以上かかり、長時間の録音セッションが必要でした。これはリコーダーにとって大きな挑戦であり、これほど長い間良好な発音を維持できる人はほとんどいません。少量のデータ量の音声合成技術により、数十の文とレコーダーが話した数分間の音声を使用するだけで、完全な音声合成効果を実現できます。
低データ量音声合成技術は大きく2つに分類されます。 1 つはアノテーションと音声が一致しない場合で、主に 2 つの処理方法があり、1 つは自己教師あり学習で、モデリング単位と音声の対応関係を取得し、アノテーションを使用する自己教師あり学習です。コーパスは、より良い合成効果を達成するために Finetune です; 2 つ目は、ASR を通じてラベルのないコーパスを識別し、TTS を使用して二重関数と二重学習方法を合成して、TTS の合成効果を徐々に向上させることです。
テキストとオーディオのマッチングの場合、主な処理方法は 2 つのタイプに分けられます。1 つは、注釈付きコーパスを使用して多言語事前トレーニング モデルを構築する方法です。もう 1 つはこのソリューションに基づいており、同じ言語の複数の話者が注釈付きデータで事前トレーニングされ、目的の話者のデータを使用して Finetune が実行されて、目的の効果が得られます。
音声合成技術フレームワーク
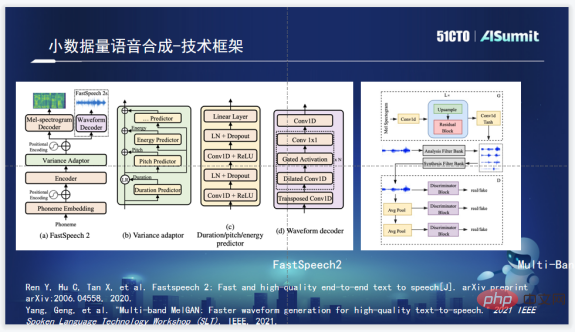
Zuoyebang の音声合成技術フレームワークは、音素部分に FastSpeech2 を使用しています。 FastSpeech2 には、合成速度が速いという主な利点がありますが、同時に、Duration、Pitch、および Energy Predictor も統合されているため、より大きな操作スペースが提供されます。ボコーダーの選択については、音声チームの選択に宿題が役立ちます。 Multi-Band MelGAN は合成効果が高く、非常に高速であるため、Multi-Band MelGAN が使用されます。
マルチスピーカー音声合成
基本的な枠組みを決めたら、次に行うのはマルチスピーカー音声合成です。マルチ話者音声合成の一般的なアイデアは、エンコーダに話者埋め込み情報を追加し、特定の話者の情報を学習し、そのモデルを使用してマルチ話者音声合成モデルをトレーニングすることです。最後に、特定のスピーカーを使用して簡単な微調整を実行します。このソリューションにより、10 時間の記録ニーズを約 1 時間に圧縮できますが、実際には、モデルのトレーニング基準を満たす 1 時間の記録を収集することは依然として困難です。小規模データの音声合成の目的は、基本的に、より少ないサウンドを使用して比較的良好なサウンドを合成することです。
したがって、Zuoyebang 音声チームは、M2VOC コンペティションの優勝ソリューションから学び、最終的に D-Vector と ECAPA ベースのスピーカー エンベディングの組み合わせを選択し、スピーカー エンベディングのアップグレードを含む 3 つのアップグレードを実行しました。 ; FastSpeech2 を使用すると、Transformer が Conformer にアップグレードされ、Speaker 情報が LayerNorm に追加されます。
2. 音声評価
音声評価テクノロジー フレームワーク

Zuoyebang の音声評価用の基本テクノロジー フレームワークは、基本的に GOP スコアリングを使用します。ユーザーが単語または文章を発音します。しかし、モデルに関しては、Conformer および CGC アテンションベース、つまり完全なエンドツーエンドのモデル トレーニング プロセスにアップグレードされました。 GOP は音と音素、つまりモデリング単位の整合度に大きく依存するため、モデルの学習時に GMM モデルを通じて取得したコーパスの整合情報を追加しました。完全に認証されたモデルと対応する情報を調整することで、非常に効果的なモデルをトレーニングでき、両方の長所を組み合わせることで、GOP のスコアが比較的正確になることが保証されます。
評価システムの問題点と問題点
評価シナリオは当然遅延の影響を受けやすいため、遅延とネットワークが GOP 評価システムの実装における 2 つの主要な問題になります。遅延が長く、リアルタイム パフォーマンスが低い場合、全体的なユーザー エクスペリエンスは大きな影響を受けます。さらに、ネットワークに問題が発生し、ユーザーのネットワーク環境が変動すると、ネットワークの遅延と相まって、ユーザーの知覚的な着色時間が 1 秒を超えやすくなり、非常に明らかな停滞感を引き起こし、深刻な影響を及ぼします。コース全体の効果。
解決の方向性 - アルゴリズム
上記の問題については、遅延と過剰なメモリの問題は、チャンク マスクを通じてアルゴリズム的に解決できます。チャンクは最大 2 フレーム前方、最大 5 フレーム後方を検索し、遅延の問題は解決されます。
実際のアルゴリズムを実際にテストすると、そのハード遅延はわずか約 50 ミリ秒であり、これは単語が基本的に 50 ミリ秒でアクティブ化されることを意味します。50 ミリ秒は人間の知覚では非常に速いです。したがって、少なくともアルゴリズム レベルでは、ハード遅延の問題は解決されます。これは私たちが行う最初のレベルの作業です。
ソリューションの方向性 - デバイスとクラウドの統合プラットフォーム
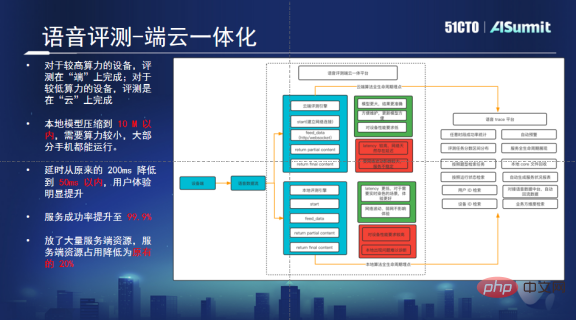
デバイスとクラウドの統合プラットフォームは、高い同時実行性とネットワーク送信によって引き起こされる問題を解決できます。このプラットフォームは、ユーザーの携帯電話に十分なコンピューティング能力があるかどうかを自動的に判断します。十分な数がある場合は、ローカルのレビューが優先されます。コンピューティング能力が十分でない場合、リクエストはクラウドに送信され、クラウドが評価を実行します。局所的に問題が発生した場合、そのライフサイクルも管理されます。
このソリューションを通じて、瞬間的な高い同時実行性によって引き起こされる問題を解決しました。コンピューティング能力の一部がエンドに転送されるため、クラウドは通常の動作を実現するために元のマシンの 20% を保持するだけで済みます。これにより資源が大幅に節約されます。さらに、アルゴリズムをローカライズした後、遅延の問題も解決されたため、大規模な評価タスクを適切にサポートし、ユーザーに優れたオーディオビジュアル体験をもたらすことができます。
発音誤りの修正
発音誤りの修正が求められる背景には、文脈上の問題や教育リソースの不足がありますが、同様に、この問題点も評価テクノロジーを使用することで解決できます。評価技術を最適化することで、発音が正しいかどうかを判定したり、発音に問題がある箇所を特定したりできます。
技術の選択に関して、評価システムは GOP に基づく安定した評価スキームですが、GOP スキームはオーディオ ユニットとモデリング ユニットの調整に大きく依存します。差別はさらに悪化するだろう。したがって、当初の計画はこの種の音声補正シナリオには適していません。さらに、GOP の考えは、専門知識を活用して発音を修正し、指導することですが、発音の修正において発音の欠落や追加は、GOP にとって対処するのに非常に苦痛であり、多大な手動サポートを必要とします。これには、より柔軟なソリューションが必要であるため、最終的に発音エラー修正に ASR ソリューションを選択しました。
ASR スキームの大きな利点は、トレーニング プロセスがシンプルであり、あまり多くのアライメント情報を必要としないことです。たとえ発音が間違っていたとしても、文脈音素の識別にはあまり影響を与えません。 ASR は追加の読み取りと読み取りの欠落を処理し、当然の理論的および技術的な利点があります。そこで私たちは最終的に、発音エラー修正の技術ベースとして純粋なエンドツーエンドの ASR モデルを選択しました。
同時に、Zuoyebang はこれに基づいて最適化と革新の作業も行いました。まず、アテンション モジュールを介してモデルのトレーニングにアプリオリなテキスト情報が追加されます。第 2 に、ランダム置換によってエラーがシミュレートされ、モデルがエラー修正機能を持つようにモデルがトレーニングされます。第 3 に、モデルが十分に区別されていないため、エラーが階層化されます。 , 多少の誤差は間違っているとは判断されません。上記の解決策により、最終的に誤報率が大幅に減少し、再現率の損失が特に大きくないことが保証され、診断の精度も向上しました。
3. 音声認識
音声認識技術フレームワーク
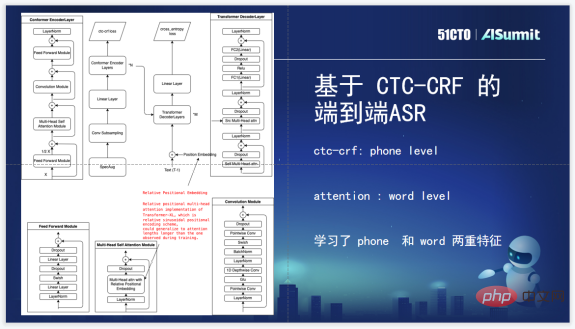
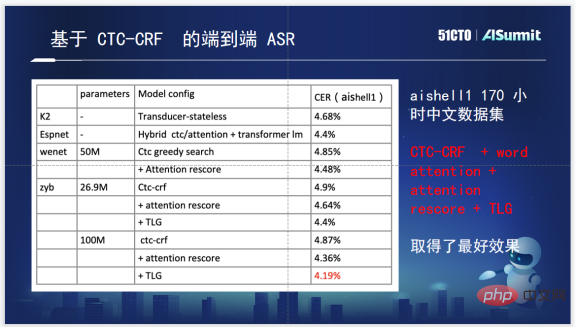
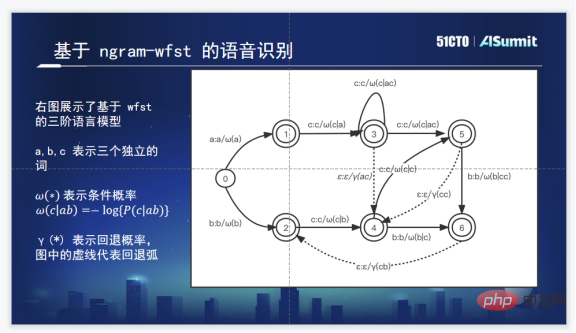
Zuoyebang の音声認識技術フレームワークは、オリジナルの HMM と比較して、エンドツーエンドの音声認識フレームワークです。 GMM/DNN このソリューションには非常に明白な利点があります: まず、多くの複雑なクラスタリング操作と位置合わせ操作が回避されます。第 2 に、トレーニング プロセスがわずかに単純です。第 3 に、エンドツーエンドのフレームワークでは発音辞書の手動生成が必要ありません。音素情報と系列情報は、音響モデルと言語モデルを一緒に学習することに相当します。
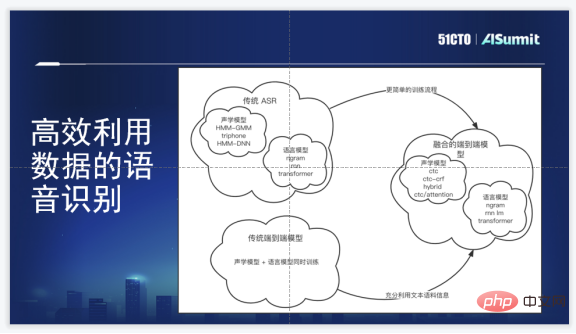
もちろん、その欠点も明らかであり、エンドツーエンド モデルでは、最初により多くの音声データやテキスト データを利用することが難しく、コストがかかります。ラベリングコーパスは非常に高いです。私たちの要件は、内部選択がエンドツーエンドの生成モデルを持ち、最新のアルゴリズムに対応し、コーパス モデル情報を融合できるという目標を達成する必要があるということです。
音声認識システムのアルゴリズム
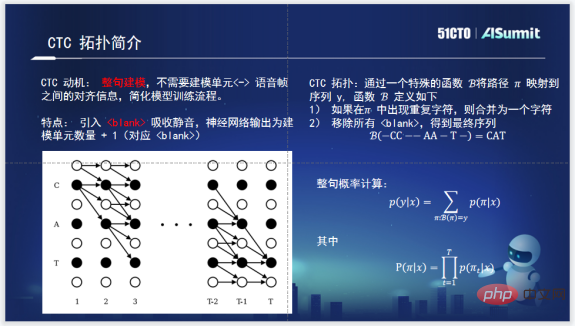
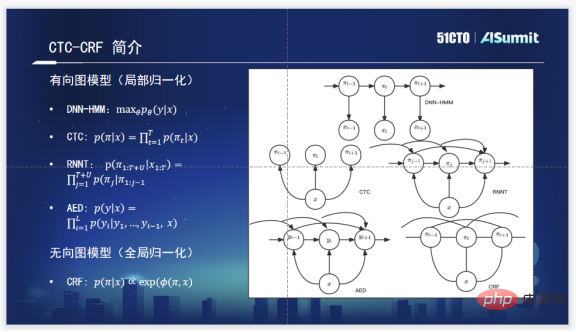
CTC-CRF については、まず CTC について知る必要があります。 CTC は文全体をモデリングするために生まれましたが、CTC の登場後は、文全体の音響モデルをトレーニングする際に音素と音声の調整は必要なくなりました。一方、CTC のトポロジでは、沈黙を吸収するためのブランクが導入され、実際の効果的なモデリング ユニットの外側の沈黙を吸収できます。一方、文全体の確率を計算する場合は、π に基づく動的計画法アルゴリズムを使用して、文全体のパスを比較的妥当なスケール内に保つため、計算量を大幅に削減できます。これは CTC による非常に画期的な取り組みです。

Zuoyebang が内部で使用する CTC-CRF 音声認識システム。公式を理解し、CRF を通じて文全体の確率を当てはめます。文全体の確率は入力がX、出力がπ(πは上記のCTCのトポロジーで表される)となる系列となるため、CTC-CRFと呼ばれます。
CRF で最も重要なことは、ポテンシャル関数とポテンシャル関数の計画全体です。ポテンシャル関数は、入力が X、出力が πt である条件付き確率に文全体の確率を加えたもので、実際には CRF のノードとエッジに対応します。

4. まとめ
上記は主に 3 方向、各方向 1 ~ 2 点で行われますが、この技術的な復号方法は、Zuoyebang の音声技術の実装と実装時の実装プロセスを整理します。に遭遇し、最終的にビジネス側のニーズを比較的満たせるソリューションをどのように出力するか。
しかし、これら 3 つのポイントに加えて、音声グループは音声の原子的な能力も数多く蓄積してきました。評価レベルは非常に細かく、増読、欠読、連読、濁音、アクセント、音の上昇下降まで行われ、さらに中国語と英語の混合認識、声紋、ノイズリダクション、年齢判別も追加されています。
これらのアトミック機能により、アルゴリズム レベルはビジネス側のサポートとサービスをより快適に行うことができます。
ゲスト紹介:
Zuoyebang の音声テクノロジー チームの責任者、Wang Qiangqiang 氏。 Zuoyebang に入社する前は、清華大学電子工学部の音声処理および機械知能研究室に勤務し、音声認識アルゴリズムの実装と産業グレードのソリューションの構築を担当していました。 2018 年に Zuoyebang に入社し、音声関連アルゴリズムの研究と実装を担当し、Zuoyebang での音声認識、評価、合成、その他のアルゴリズムの実装を主導し、同社に音声テクノロジー ソリューションの完全なセットを提供してきました。
以上がZuoyebang 音声技術の実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7518
7518
 15
1378
52
81
11
21
67
15
1378
52
81
11
21
67

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
8月1日の本サイトのニュースによると、SKハイニックスは本日(8月1日)ブログ投稿を発表し、8月6日から8日まで米国カリフォルニア州サンタクララで開催されるグローバル半導体メモリサミットFMS2024に参加すると発表し、多くの新世代の製品。フューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) の紹介。以前は主に NAND サプライヤー向けのフラッシュ メモリ サミット (FlashMemorySummit) でしたが、人工知能技術への注目の高まりを背景に、今年はフューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) に名前が変更されました。 DRAM およびストレージ ベンダー、さらに多くのプレーヤーを招待します。昨年発売された新製品SKハイニックス
